
【Surya】英語・日本語の正確な文字起こしができる無料のマルチリンガルAIOCRツール!使い方~実践まで

WEELメディア事業部LLMライターのゆうやです。
Suryaは、あらゆる言語での正確な行レベルのテキスト検出と認識(OCR)を行うマルチリンガル文書OCRツールキットです。
Suryaでは以下のことができます。
- 正確な行レベルのテキスト検出
- テキスト認識
- 表とチャートの検出
現在は、正確な行レベルのテキスト検出のみ利用可能で、以下の画像のようにドキュメントから行レベルでテキストを検出できます。

Suryaの高度なORC技術は、映画「ブレードランナー」で登場するレプリカント識別技術のような高度で正確な識別が可能です。
今回は、Suryaの概要や使ってみた感想をお伝えします。
是非最後までご覧ください!

目次
Suryaの概要
Suryaは、あらゆる言語での正確な行レベルのテキスト検出と認識(OCR)を行うマルチリンガル文書OCRツールキットです。
Suryaでは以下のことができます。
- 正確な行レベルのテキスト検出:画像、PDF、または画像/PDFのフォルダ内のテキストラインを検出し、検出された境界ボックス(bboxes)のJSONファイルを作成し、必要に応じてページの画像と境界ボックスを保存します。
- テキスト認識(近日中に提供予定):今後のアップデートでテキスト認識機能が追加される予定です。
- 表とチャートの検出(近日中に提供予定):表とチャートを検出する機能も開発中です。
現在は、正確な行レベルのテキスト検出のみ利用可能で、ドキュメントから行レベルでテキストを検出できます。
Suryaはマルチリンガル文章ORCツールキットなので、このように日本語のドキュメントもちゃんとテキスト検出できます。
このように高い精度でテキスト検出が可能なSuryaですが、その機能は文書OCRに特化しており、写真やその他の画像、手書きテキストには適していません。
また、広告のような画像や、通常は無視されるドキュメントの他の部分ではうまく機能しないようです。
Suryaのベンチマーク結果も紹介します。
以下のグラフと表は、同じOCRツールであるTesseractとの比較結果です。

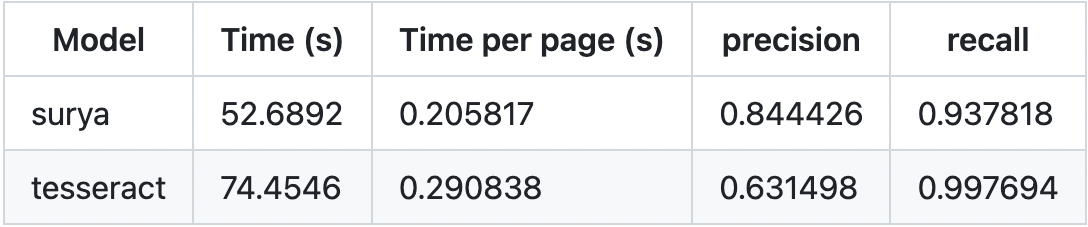
この結果を見ると、SuryaはTesseractより短い時間で高い精度のテキスト検出できることが分かります。
このように、高い能力を持っているSuryaですが、テキスト検出モデルに関しては0から構築されたもののため、商用利用も可能だとアナウンスされています。
ここからは、Suryaを実際に使用してその性能を確かめていきます。
まずは使い方から紹介します。
なお、Metaが開発したOCRツールのNougatついて詳しく知りたい方は、下記の記事を合わせてご確認ください。
→【Nougat】PDF上の画像や数式をOCRしてくれる神ツールが登場
Suryaの使い方
Suryaのインストールと使用方法は非常に簡単で、前提条件としてPython 3.9以降とPyTorchのインストールが必要です。
また、SuryaはGPU使用時デフォルト設定で約9GBのVRAMを使用します。
インストールするには、以下のコマンドを実行します。
pip install surya-ocrインストールはこれだけで完了で、surya/settings.pyで設定を確認、変更できます。
suryaを実行するには以下のコードを実行します。
surya_detect DATA_PATH --imagesまた、実行には様々なオプションがあります。
DATA_PATH画像、PDF、または画像/PDFのパスを指定できます。--imagesページの画像と検出されたテキスト行を保存します。--maxすべてを処理したくない場合は、処理する最大ページ数を指定できます。--results_dirデフォルトの代わりに結果を保存するディレクトリを指定します。
以上がSuryaの使い方です。
早速使っていきましょう!

Suryaを実際に使ってみた
実際に以下のLlama2の論文のイントロダクション部分を入力してみます。

以下のコマンドを実行します。
surya_detect 'image1.png' --images結果はこのようになりました。

この通り、行単位でテキストを完璧に検出できています。
日本語でも試してみます。
以下のLLM勉強会の趣旨説明の一部のスクリーンショットを入力します。

結果はこのようになりました。

部分的に赤枠がずれているところがありますが、テキスト行は認識できています。
ここからは、ベンチマークでも比較されていたTesseractと同じ画像を入力して、実際のテキスト検出の精度を比較していきます。
Suryaの推しポイントである高精度のテキスト検出は本当なのか検証してみた
まずは先ほどSuryaでも試したLLM勉強会の趣旨説明の一部をTesseractにも入力してみます。
結果はこのようになりました。

結果は、テキスト検出は漏れなくできており、Suryaと比較して文章をより細かく区切って検出しています。
Tesseractではテキスト認識もできるので、そちらの結果も示します。

問題なくテキスト認識もできているので、今のところSuryaと同等かそれ以上の性能を持ってると感じます。
続いて、以下の表付きの画像を入力してどうなるか検証します。
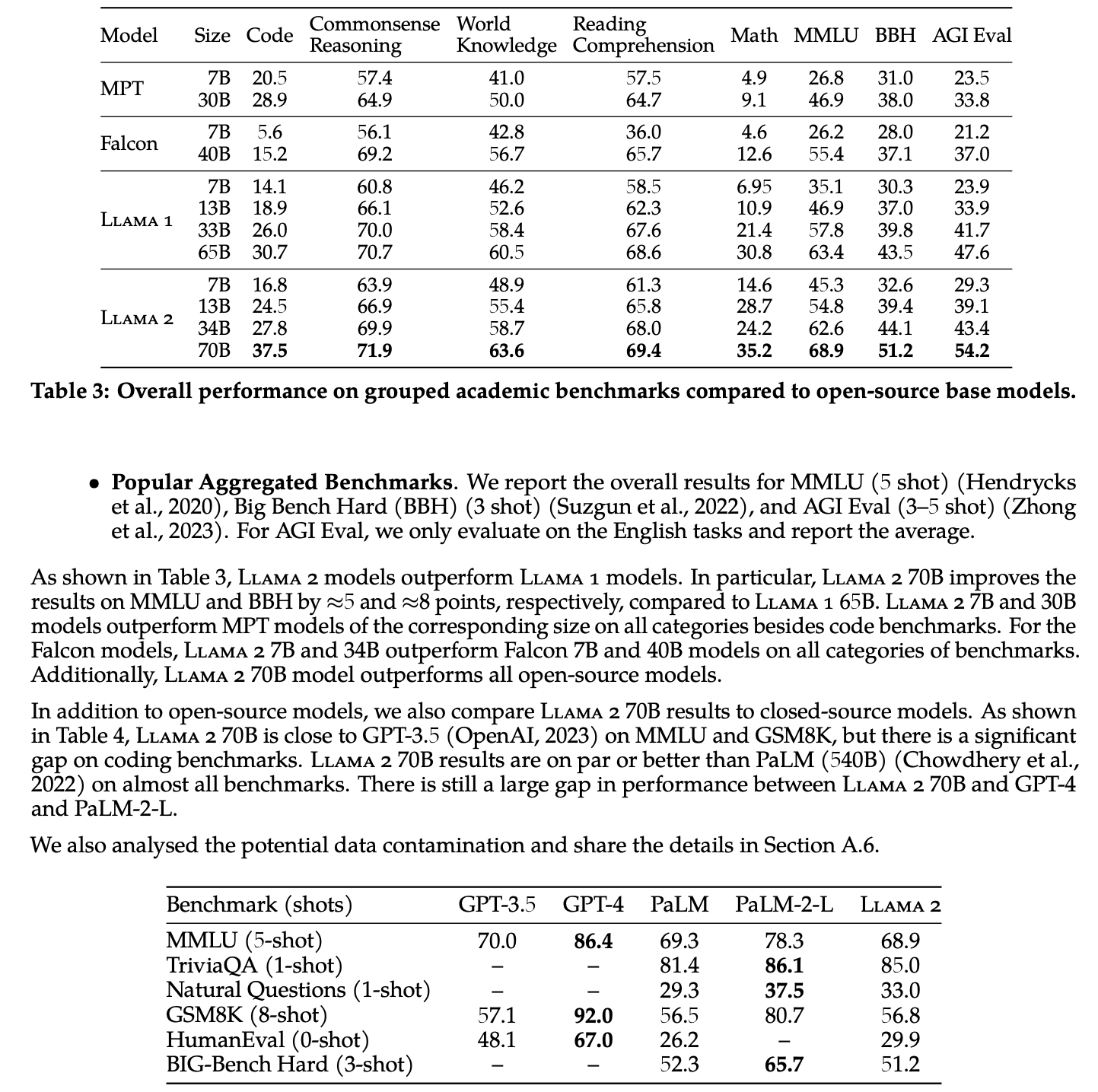
結果はこのようになりました。
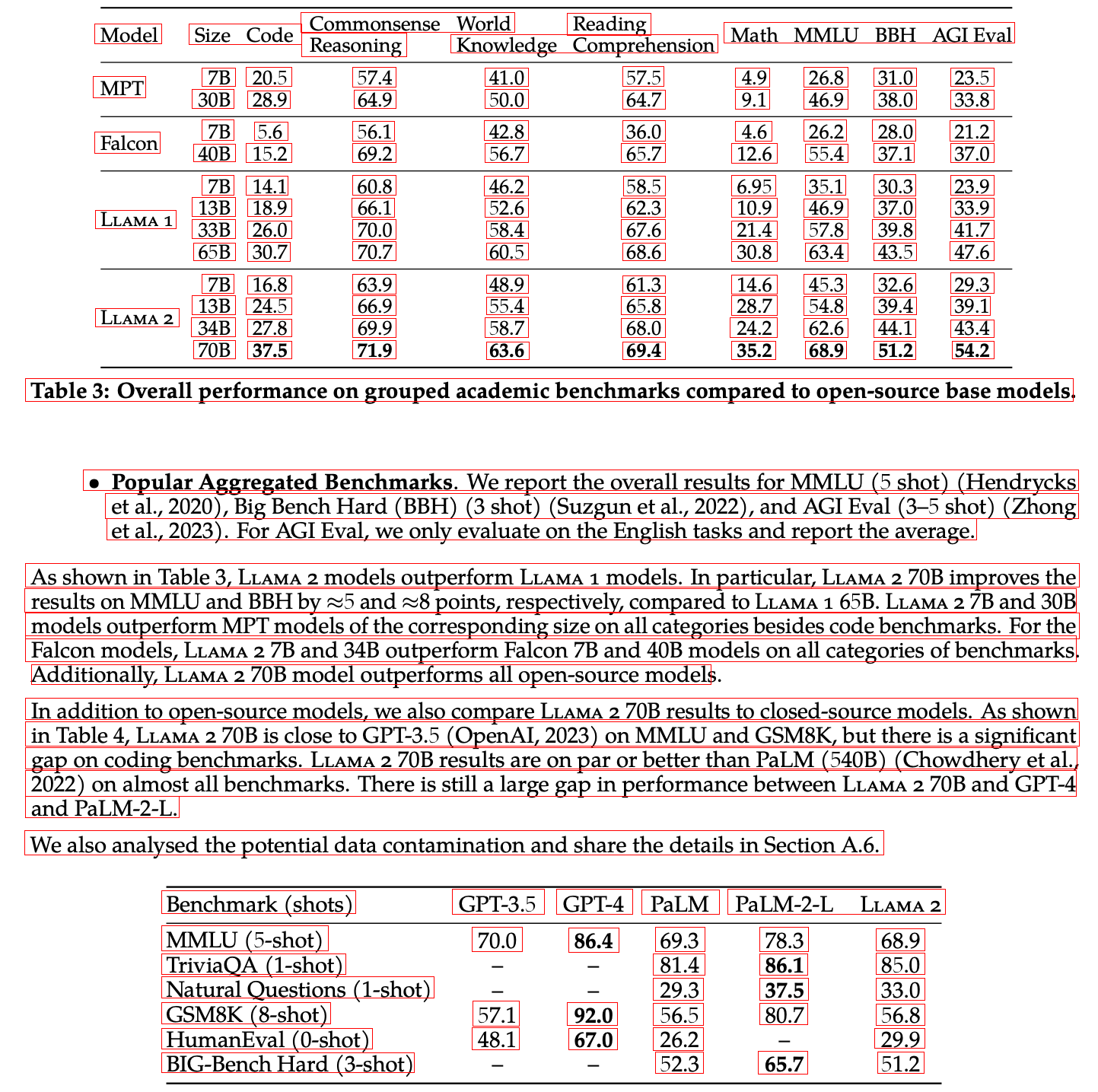
Surya
Tesseract
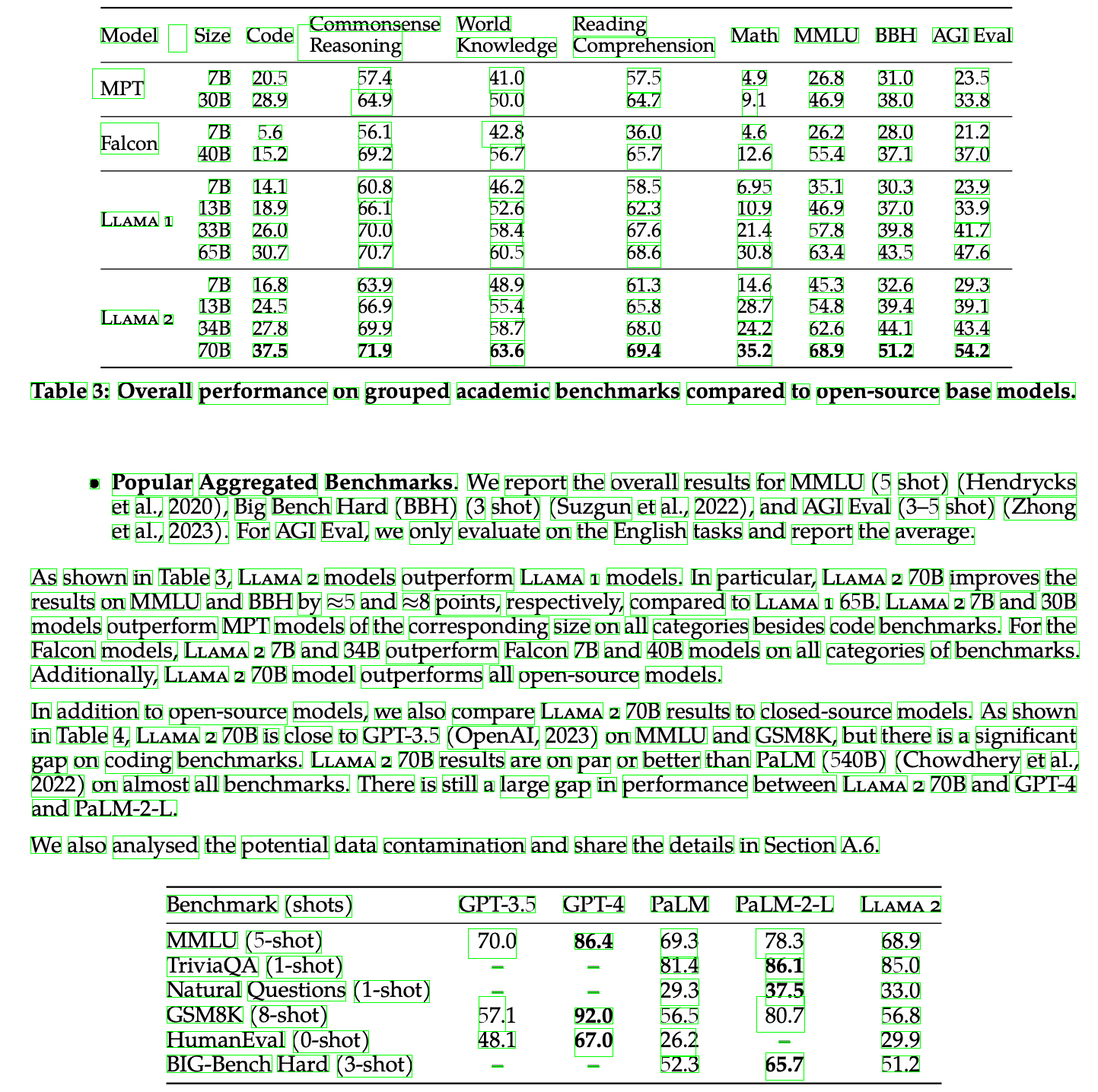
どちらも素晴らしい精度でテキストを検出してくれています。
ただ、Tesseractは左上のModelの横の空白をテキストと認識しており、そこだけ唯一誤って検出してしまっています。
また、生成時間に関してもSuryaの方が数秒ではありますが速かったです。
Suryaは誤検出はありませんが、Tesseractではテキストとして検出されている下の表の‘-‘が検出されておらず、テキスト認識をするときにこれがどのように影響を及ぼすのか懸念されます。
これまでの検証結果から、SuryaとTesseractの実際の性能はベンチマークで示されていたほどの差はないと感じました。
今後、Suryaのテキスト認識機能が使えるようになった際は、またTesseractとの比較検証を行なって、真の性能に迫っていきます。
まとめ
Suryaは、あらゆる言語での正確な行レベルのテキスト検出と認識(OCR)を行うマルチリンガル文書OCRツールキットです。
Suryaでは以下のことができます。
- 正確な行レベルのテキスト検出
- テキスト認識
- 表とチャートの検出
現在は、正確な行レベルのテキスト検出のみ利用可能で、以下の画像のようにドキュメントから行レベルでテキストを検出できます。
Suryaは同じOCRツールであるTesseractより短い時間で高い精度のテキスト検出できることがベンチマークで検証されています。
実施に使用して、英語や日本語のドキュメントを入力しましたが、正確に行単位のテキスト検出をしてくれました。
しかし、Tesseractとの比較検証では、ベンチマークで示されていたほどの性能差は感じられませんでした。
将来的には、このようなOCRツールがさらに進化して人間を遥かに上回る認識能力を身につけ、まさにSF映画のような世界観になるかもしれませんね!

生成系AIの業務活用なら!
・生成系AIを活用したPoC開発
・生成系AIのコンサルティング
・システム間API連携
最後に
いかがだったでしょうか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。
生成AIを社内で活用していきたい方へ

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、弊社紹介資料もご用意しておりますので、併せてご確認ください。


