
【Gemini Embedding 2】テキスト・画像・動画を1つの空間に変換できるマルチモーダル埋め込みモデルを徹底解説

- Google発、テキスト・画像・動画・音声・ドキュメントの5つのモダリティを1つの埋め込み空間で扱える、初のネイティブマルチモーダル埋め込みモデル
- 対応言語は100言語以上で、入力トークン数は最大8,192トークン
- 2026年3月11日現在、Gemini APIおよびVertex AIを通じてパブリックプレビュー版として公開
2026年3月11日、Googleはテキスト・画像・動画・音声・ドキュメントの5つのモダリティを1つの埋め込み空間で扱える、初のネイティブマルチモーダル埋め込みモデル「Gemini Embedding 2」を公開しました!
これまで、埋め込みモデルといえばテキスト専用が主流で、画像や音声を同じベクトル空間で検索・分類するには、別々のモデルを組み合わせる必要がありましたが、Gemini Embedding 2は、この常識を変えてくれるモデルです。
本記事では、Gemini Embedding 2の概要から仕組み、性能ベンチマーク、具体的な使い方まで徹底解説します。
これからRAGや意味検索の精度を上げたい方、マルチモーダルデータを活用した検索システムを構築したい方は、ぜひ最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
Gemini Embedding 2とは?

Gemini Embedding 2は、5つのモダリティを1つのベクトル空間に変換できるマルチモーダル埋め込みモデルです。
モデルID:gemini-embedding-2-previewとして公開されており、テキスト、画像、動画、音声、PDFドキュメントに5種類の入力を受け取り、それらすべてを統一されたベクトル空間に変換します。
従来のGemini Embedding(gemini-embedding-001)は、テキストのみを対象としていましたが、Gemini Embedding 2ではテキストに加えて、PNGやJPEG形式の画像を1リクエストあたり最大6枚、MP4やMOV形式の動画を最大120秒(音声付きの場合は80秒)、MP3やWAV形式の音声を最大80秒、PDFを最大6ページまで処理してくれるようになりました。
また、音声については文字起こしのような中間的なテキスト変換を経由せず、ネイティブにベクトル化する点も大きな進化となっています。
対応言語は100言語以上で、入力トークン数は最大8,192トークン。出力次元はデフォルト3,072次元ですが、Matryoshka Representation Learning(MRL)によって、768次元や1,536次元など柔軟にスケーリングすることができます。
なお、アリババの埋め込みモデルについて、詳しく知りたい方は以下の記事も参考にしてみてください。
Gemini Embedding 2の仕組み
マルチモーダル入力がどのように1つのベクトルに変換されるのか、その内部構造を見ていきましょう。
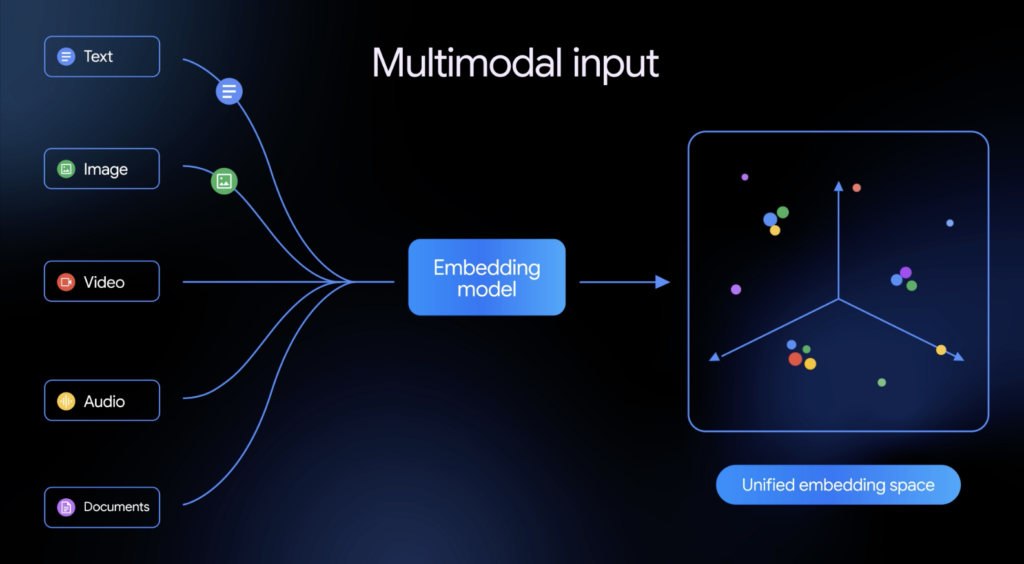
Gemini Embedding 2はGeminiアーキテクチャをベースとしており、テキスト・画像・動画・音声・PDFの各モダリティを共通のエンコーダに通して、統一された意味空間のベクトル表現へ変換します。つまり「猫の画像」と「猫についてのテキスト」が同じ空間の近い位置にマッピングされるため、モダリティをまたいだ検索や分類が可能になるわけです。
また、複数モダリティのインターリーブ入力(たとえば画像とテキストを同時に渡す)にもネイティブ対応しており、モダリティ間の複雑な関係性を捉えることができます。PDFに対してはOCR(光学文字認識)を内部で実行し、動画に含まれる音声トラックは自動的に抽出・埋め込みされます。
出力次元の制御にはMatryoshka Representation Learning(MRLと呼ばれる技術が採用されています。これはロシアのマトリョーシカ人形のように、情報を「入れ子」構造で格納するアプローチです。3,072次元のフルベクトルから768次元などに切り詰めても意味的な精度が大きく損なわれないよう学習されているため、ストレージコストとパフォーマンスのバランスを柔軟に調整できます。推奨次元は3,072、1,536、768の3段階ですが、128、256、512、2,048など任意の値に設定することも可能です。


Gemini Embedding 2の特徴
性能面やベンチマークに注目して、Gemini Embedding 2の強みをさらに確認していきましょう。
MTEBベンチマークでの高スコア
Gemini Embedding 2は、埋め込みモデルの標準的な評価指標であるMTEB(Massive Text Embedding Benchmark)において、次元数ごとに以下のスコアを記録しています。

注目すべきなのは、1,536次元に縮小しても、3,072次元とほぼ同等のスコアを維持している点です。
MRLの効果によって、次元削減によるストレージ節約と精度維持を高いレベルで両立できていることがわかります。なお、前身モデルの実験版(gemini-embedding-exp-03-07)は、MTEB(Multilingual)リーダーボードで平均スコア68.32を記録し、2位モデルに対して+5.81ポイントの差をつけて1位を獲得した実績もあります。
8つのタスクタイプへの対応
Gemini Embedding 2は単にベクトルを出力するだけでなく、task_typeパラメータによって用途に最適化した埋め込みを生成することができます。
対応しているタスクとしては8種類あって、意味的類似度、分類、クラスタリング、ドキュメント検索用インデックス、検索クエリ、コード検索、質問応答、ファクトチェックと多岐にわたります。
タスクに応じた最適化がかかるので、汎用的な埋め込みよりも高い精度が期待できるのがいいですね。
音声のネイティブ処理
多くのマルチモーダルモデルでは、音声は一度テキストに書き起こしてから処理するのが一般的かと思います。
しかし、Gemini Embedding 2は音声をそのまま直接ベクトル化します。これによって、話者のトーンや抑揚といったテキスト化では失われやすいニュアンスも埋め込みに反映される可能性があり、音声検索やポッドキャスト検索などでより効果を実感できそうです。
Gemini Embedding 2の安全性・制約
便利なGemini Embedding 2ですが、制約事項についても把握しておきましょう。
Gemini Embedding 2は2026年3月11日現在、パブリックプレビュー版として提供されています。Google Cloudの「Pre-GA Offerings Terms」が適用されるため、サポートが限定的である点やSLAが保証されない点に注意が必要です。
入力の制約としては、画像は1リクエスト最大6枚、PDFは最大6ページ、音声は最大80秒、動画は音声付きで最大80秒(音声なしで120秒)という上限があります。長時間の動画や大部の文書を扱う場合には、チャンク分割などが必要になるかと思います。
また、Vertex AIでの利用は、us-central1リージョンのみに限定されていて、ストリーミングやバッチ予測には対応していません。従来のgemini-embedding-001とはベクトル空間に互換性がないので、移行時にはすべてのデータを再埋め込みする必要がある可能性もあります。
Gemini Embedding 2の料金
Gemini Embedding 2は、Gemini API経由で利用する場合、無料枠ではすべてのモダリティが無料で利用可能です。
有料プランに移行すると、モダリティごとに異なる従量課金が発生します。
Gemini Embedding 2(gemini-embedding-2-preview)
| モダリティ | 無料枠 | 有料(Standard) | 有料(Batch) |
|---|---|---|---|
| テキスト入力 | 無料 | $0.20 / 100万トークン | $0.10 / 100万トークン |
| 画像入力 | 無料 | 0.45/100万トークン(約0.45/100万トークン(約0.00012 / 枚) | $0.225 / 100万トークン |
| 音声入力 | 無料 | 6.50/100万トークン(約6.50/100万トークン(約0.00016 / 秒) | $3.25 / 100万トークン |
| 動画入力 | 無料 | 12.00/100万トークン(約12.00/100万トークン(約0.00079 / fps) | $6.00 / 100万トークン |
【参考】Gemini Embedding(gemini-embedding-001)
| モダリティ | 無料枠 | 有料(Standard) | 有料(Batch) |
|---|---|---|---|
| テキスト入力 | 無料 | $0.15 / 100万トークン | $0.075 / 100万トークン |
テキストのみの利用であれば、100万トークンあたり0.20(約30円)と非常にリーズナブルとなっています。


Gemini Embedding 2のライセンス
Gemini Embedding 2は、Gemini API利用規約およびGoogle APIs利用規約に準拠したクラウドAPIサービスです。モデルの重みがダウンロード提供されるわけではなく、API経由でのみ利用できます。
以下、主要なライセンス項目を表で整理しておきます。
| 項目 | 可否 | 備考 |
|---|---|---|
| 商用利用 | ⭕️ | |
| 出力の改変 | ⭕️ | |
| 出力の再配布 | 🔺 | 埋め込みベクトル自体の再配布は可能だが、Googleの安全機能回避は禁止 |
| 特許利用 | – | |
| 私的利用 | ⭕️ | |
| モデルのリバースエンジニアリング | ❌️ | モデルの複製・再構築・競合モデルの構築は明確に禁止 |
Googleは生成された出力(埋め込みベクトル)に対する所有権を主張しないと明記しており、ユーザーが自社プロダクトに組み込んで商用提供することは問題ありません。
Gemini Embedding 2の使い方
それでは実際に、Gemini Embedding 2の使い方を具体的に確認していきましょう。Python SDKを使った方法を中心に、テキスト・画像・マルチモーダルそれぞれのパターンをご紹介します。
ステップ1:APIキーの取得とSDKのインストール
まず、Google AI StudioでAPIキーを取得します。Google AI Studio(https://aistudio.google.com/)にアクセスし、「Get API Key」→「APIキーを作成」からAPIキーを発行してください。

次に、Python環境でGoogle GenAI SDKをインストールします。
pip install google-genai
先ほど取得したAPIキーは、環境変数として設定しておくと便利です。
export GEMINI_API_KEY="取得したAPIキー"
ステップ2:テキストの埋め込みを生成する
もっともシンプルなテキスト埋め込みのコード例は以下の通りです。
from google import genai
client = genai.Client()
result = client.models.embed_content(
model="gemini-embedding-2-preview",
contents="人工知能の歴史について教えてください"
)
print(f"次元数: {len(result.embeddings[0].values)}")
print(f"先頭5要素: {result.embeddings[0].values[:5]}")
embed_contentメソッドにモデルIDとテキストを渡すだけで、ベクトルが返ってきます。

ステップ3:タスクタイプを指定して精度を最適化する
用途に応じてtask_typeを指定すると、その目的に最適化された埋め込みが生成されます。たとえば、2つのテキスト間の意味的な類似度を測りたい場合はSEMANTIC_SIMILARITYを指定します。
from google import genai
from google.genai import types
client = genai.Client()
texts = [
"機械学習とは何ですか?",
"ディープラーニングの基礎を教えてください",
"今日の天気はどうですか?",
]
result = client.models.embed_content(
model="gemini-embedding-2-preview",
contents=texts,
config=types.EmbedContentConfig(task_type="SEMANTIC_SIMILARITY")
)
for i, emb in enumerate(result.embeddings):
print(f"テキスト{i+1}の次元数: {len(emb.values)}")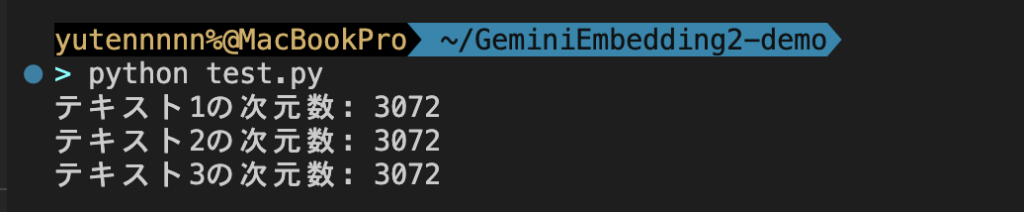
ステップ4:画像を埋め込む
Gemini Embedding 2の真骨頂であるマルチモーダル機能の使い方も確認しておきましょう。画像ファイルを読み込んでバイナリデータとして渡すだけで、テキストと同じ埋め込み空間のベクトルが得られます。
from google import genai
from google.genai import types
client = genai.Client()
with open("image/test.png", "rb") as f:
image_bytes = f.read()
result = client.models.embed_content(
model="gemini-embedding-2-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type="image/png",
),
]
)
print(f"画像の埋め込み次元数: {len(result.embeddings[0].values)}")入力画像(フリー素材)はこちら


お気づきの方もいらっしゃるかもしれませんが、ここまで全て次元数が3,072になっているのは、Gemini Embedding 2のデフォルト出力次元数が3,072次元なのが理由です。
テキストでも画像でも音声でも、すべてのモダリティが同じ3,072次元のベクトル空間に写像される仕様なので、何を入力しても次元数は同じになります。これがまさに統一ベクトル空間の意味で、次元数が揃っているからこそテキストと画像のコサイン類似度を計算できるといったわけです。
ステップ5:テキスト+画像+音声のマルチモーダル埋め込み
テキスト、画像、音声を組み合わせたインターリーブ入力も可能です。1つのリクエストで複数モダリティのデータを渡すと、それらの関係性を考慮した埋め込みが生成されます。
from google import genai
from google.genai import types
client = genai.Client()
with open("photo.png", "rb") as f:
image_bytes = f.read()
with open("narration.mp3", "rb") as f:
audio_bytes = f.read()
result = client.models.embed_content(
model="gemini-embedding-2-preview",
contents=[
"東京タワーの夜景",
types.Part.from_bytes(data=image_bytes, mime_type="image/png"),
types.Part.from_bytes(data=audio_bytes, mime_type="audio/mpeg"),
],
)
for i, emb in enumerate(result.embeddings):
print(f"入力{i+1}の次元数: {len(emb.values)}")ステップ6:出力次元数をカスタマイズする
ストレージコストを抑えたい場合は、output_dimensionalityパラメータで出力次元を小さく指定できます。MRLにより、精度を大きく落とすことなく次元削減が可能です。
from google import genai
from google.genai import types
client = genai.Client()
result = client.models.embed_content(
model="gemini-embedding-2-preview",
contents="次元数を削減したテキスト埋め込みのテスト",
config=types.EmbedContentConfig(output_dimensionality=768)
)
print(f"出力次元数: {len(result.embeddings[0].values)}") # 768以上、基本的な使い方の流れのご紹介でした。
【業界別】Gemini Embedding 2の活用シーン
Gemini Embedding 2は幅広い業界で活用できるポテンシャルを持っています。こちらでは、特に相性の良い業界ごとにユースケースをご紹介します。
EC・小売業界
商品画像とテキスト説明を同じ埋め込み空間に格納することで、ユーザーが画像で検索しても、テキストで検索しても、関連商品にたどり着けるマルチモーダル商品検索エンジンを構築することができるかと思います。
たとえば、「この画像に似た青いワンピース」のような自然な検索体験を実現できそうです。商品レコメンデーションの精度向上にも直結と思います。
なお、小売業界における生成AI活用事例について、詳しく知りたい方は以下の記事も参考にしてみてください。

メディア・エンタメ業界
Gemini Embedding 2は、動画や音声をネイティブに埋め込みできるので、ポッドキャストや動画コンテンツのシーン検索システムに最適かと思います。
たとえば、「感動的なBGMが流れているシーン」のようなテキストクエリで動画内の該当箇所を検索する、といった使い方が考えられます。100言語以上に対応しているので、多言語コンテンツの横断検索にも向いています。
なお、エンタメ業界における生成AI活用事例について、詳しく知りたい方は以下の記事も参考にしてみてください。

製造・品質管理業界
製品写真と検査レポートのPDFを統一的にベクトル化し、過去の不良事例データベースを構築することができると思います。新たな不良品画像をクエリとして、類似事例を検索し、原因分析や対策立案を効率化するといった活用が期待されます。
なお、製造業界における生成AI活用事例について、詳しく知りたい方は以下の記事も参考にしてみてください。

【課題別】Gemini Embedding 2が解決できること
企業やプロジェクトが抱える具体的な課題に対して、Gemini Embedding 2がどう解決してくれるのかを確認しておきましょう。
モダリティごとにバラバラだった検索システムの統合
従来は画像検索、テキスト検索、音声検索でそれぞれ別のモデルやインデックスを管理する必要がありましたが、Gemini Embedding 2を導入することで、1つのモデルですべてのモダリティを統一的にベクトル化できるので、システムの複雑さが大幅に軽減されると思います。運用コストの削減にも貢献してくれそうですね。
RAG(検索拡張生成)の検索精度向上
RAGシステムの精度はリトリーバーの品質に大きく左右されます。
そこで、Gemini Embedding 2は、RETRIEVAL_DOCUMENTやRETRIEVAL_QUERYなどのタスクタイプに対応しているので、用途別に最適化された埋め込みを生成することができます。
さらに、PDFや画像を含むリッチなドキュメントをそのままベクトル化できるので、前処理パイプラインの簡素化と精度向上の両方が実現できることと思います。
なお、RAGについて詳しく知りたい方は、以下の記事も参考にしてみてください。

多言語コンテンツの横断検索
Gemini Embedding 2は、100言語以上に対応しているので、日本語で入力したクエリで英語やフランス語のドキュメントを検索するといったクロスリンガル検索が可能になります。
グローバル企業におけるナレッジベースや、多言語のカスタマーサポートFAQ検索において、言語の壁を超えた情報アクセスを実現してくれそうです。
Gemini Embedding 2を使ってみた
それでは実際に、Gemini Embedding 2のマルチモーダル検索能力を検証してみましょう。今回は、テキストクエリで画像を検索できるのか、という点に焦点を当てて試してみます。
具体的には、複数の画像をGemini Embedding 2でベクトル化し、テキストで問い合わせたときに意味的に正しい画像が返ってくるかを確認します。
以下が検証コードです。
from google import genai
from google.genai import types
import numpy as np
client = genai.Client()
# --- 1. 画像の埋め込みを生成 ---
image_files = [
("image/sunset.png", "image/png"), # 夕焼けの風景写真
("image/cat.png", "image/png"), # 猫の写真
("image/code.png", "image/png"), # プログラミングコードのスクリーンショット
("image/sushi.png", "image/png"), # 寿司の写真
]
image_embeddings = []
for filename, mime in image_files:
with open(filename, "rb") as f:
img_bytes = f.read()
result = client.models.embed_content(
model="gemini-embedding-2-preview",
contents=[types.Part.from_bytes(data=img_bytes, mime_type=mime)]
)
image_embeddings.append(result.embeddings[0].values)
print(f"{filename} の埋め込み完了")
# --- 2. テキストクエリの埋め込みを生成 ---
queries = [
"美しい夕日の景色",
"かわいい動物",
"ソフトウェア開発",
"日本食",
]
query_embeddings = []
for q in queries:
result = client.models.embed_content(
model="gemini-embedding-2-preview",
contents=q,
config=types.EmbedContentConfig(task_type="RETRIEVAL_QUERY")
)
query_embeddings.append(result.embeddings[0].values)
# --- 3. コサイン類似度で検索 ---
def cosine_similarity(a, b):
a, b = np.array(a), np.array(b)
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
print("\n=== クロスモーダル検索結果 ===")
for i, query in enumerate(queries):
scores = [cosine_similarity(query_embeddings[i], img_emb) for img_emb in image_embeddings]
best_idx = np.argmax(scores)
print(f"クエリ「{query}」→ 最類似画像: {image_files[best_idx][0]}(スコア: {scores[best_idx]:.4f})")入力画像はChatGPT Imagesで以下の4枚を生成しました。

実行結果はこちら
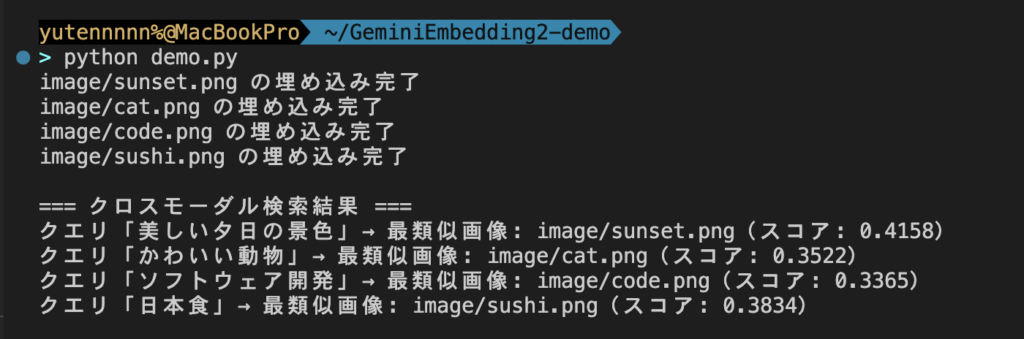
このように、テキストで入力したクエリが、意味的に対応する画像を正しくヒットさせることができました。
1つのモデル、1つのAPIコールでテキストと画像が同じベクトル空間に写像されるので実装もシンプルなのが良いですね。
さらに応用として、動画や音声も同じベクトル空間に追加できるので、たとえば「元気な音楽が流れている動画」というテキストクエリで動画を検索するシステムも、同じアプローチで構築可能かと思います。
よくある質問
最後に、Gemini Embedding 2に関して、多くの方が疑問に感じるであろうポイントをご紹介します。
まとめ
最後に、Gemini Embedding 2の要点を振り返りましょう。
Gemini Embedding 2は、テキスト・画像・動画・音声・PDFの5つのモダリティを1つの統一されたベクトル空間に変換できる、Googleの初のネイティブマルチモーダル埋め込みモデルです。Geminiアーキテクチャをベースに構築されていて、100言語以上に対応、最大8,192トークンの入力を処理することができます。
2026年3月11日現時点ではパブリックプレビューのステータスで、入力制約やリージョン制限などの注意点はありますが、マルチモーダル検索、RAGの高度化、多言語対応の検索基盤など、幅広いユースケースに応用できるモデルとして大きな可能性を秘めていると思います。
気になった方は、ぜひ一度使ってみてください!

最後に
いかがだったでしょうか?
弊社では、AI導入を検討中の企業向けに、業務効率化や新しい価値創出を支援する情報提供・導入支援を行っています。最新のAIを活用し、効率的な業務改善や高度な分析が可能です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

