
【Qwen3-VL】見て・理解し・行動する次世代マルチモーダルAI!特徴と使い方を徹底解説
- テキスト・画像・動画を理解・生成するマルチモーダルモデル
- GUI操作を自動化する「Visual Agent」など8つの主要機能を大幅アップグレード
- 長文脈・長時間動画・コード生成まで対応する高精度な汎用AIモデル
2025年9月、Alibabaから新たなモデルが登場!
今回リリースされた「Qwen3-VL」はマルチモーダルモデルであり、テキストの理解と生成、視覚コンテンツの認識と推論、より長いコンテキストのサポート、空間関係や動的な動画の理解などあらゆる側面で大幅に改善しています。
本記事ではQwen3-VLの概要から仕組み、実際の使い方までお伝えします。本記事を最後までお読みいただくことでQwen3-VLの理解が深まり、ご自身でも使えるようになるでしょう。
ぜひ最後までお読みください!
\生成AIを活用して業務プロセスを自動化/
Qwen3-VLの概要
Qwen3-VLが目指すのは、画像や動画を単に「見る」だけでなく、世界を真に理解し、出来事を解釈し、実際に行動すること。
この実現に向けて、Qwen3-VLは主要機能を体系的にアップグレードし、視覚モデルを単純な「知覚」からより深い「認知」へ、そして基本的な「認識」から高度な「推論と実行」へと進化しています。
具体的には次の8つがアップグレードしています。※1
- ビジュアルエージェント機能
- テキスト中心のパフォーマンス
- ビジュアルコーディング
- 空間理解の向上
- ロングコンテキストと長時間動画の理解
- Thinkingバージョン
- 視覚認識機能の強化
- OCR機能の向上
Qwen3-VLの仕組み
Qwen3-VLは、視覚と言語の統合を前提に設計されたマルチモーダル大規模モデル。3つの側面から設計がアップグレードされています。
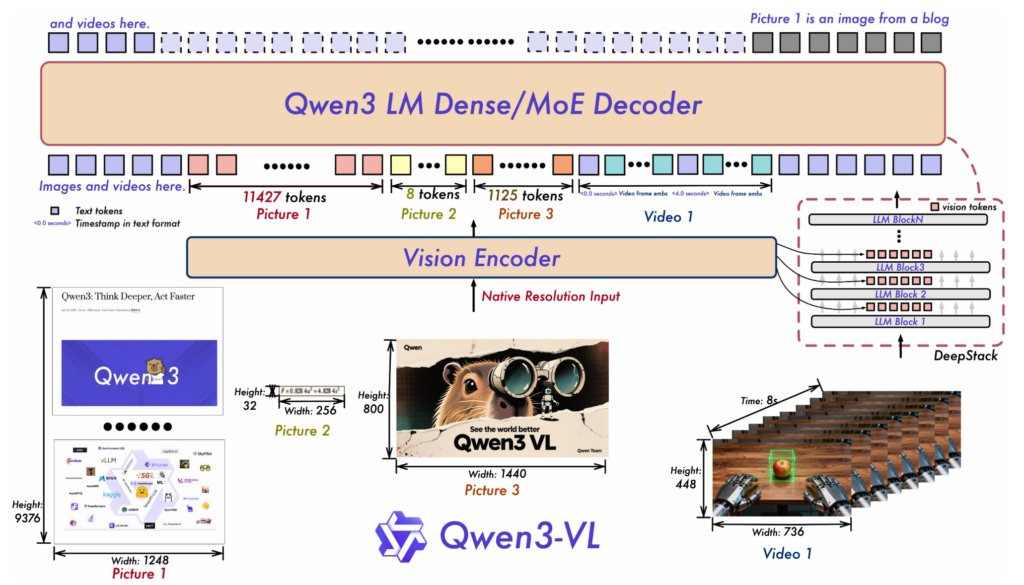
Interleaved-MRoPEによる位置表現
1つ目が「Interleaved-MRoPE」。
従来のMRoPE(Multi-dimensional Rotary Position Embedding)は、時間・高さ・幅の各次元を分割して埋め込み、時間情報が高周波成分に偏る傾向がありました。
Qwen3-VLではこれを改良し、時間・高さ・幅を交互に分散させて全周波数域で均等に扱う構造へと変更。この設計により、画像認識能力を維持したまま長尺動画の時系列理解を安定化し、動作・イベントの経時変化をより自然に捉えられるようになりました。
DeepStackによる多層特徴融合
Qwen3-VLは、視覚変換器から抽出された多段階の特徴を「DeepStack」で統合します。
従来は視覚トークンを言語モデルの単一層にのみ挿入していましたが、本モデルでは複数層にまたがって注入する多層融合方式を採用。
これにより、低レベルの形状情報から高レベルの意味情報までを維持しながら、結果として、物体認識や文書解析、コード生成など、視覚と意味の対応精度が大幅に向上しています。
テキストタイムスタンプアライメントメカニズム
動画理解においては、既存のT-RoPEを拡張し、「テキストタイムスタンプアライメントメカニズム」を導入。
この仕組みでは、「タイムスタンプ+映像フレーム」の交互入力形式を用い、フレーム単位での時間情報と視覚内容を密に結び付けます。さらに、出力フォーマットとして「秒」または「時:分:秒(HMS)」表記に対応しており、イベントの発生時刻や動作境界を明確に把握。
これにより、長動画における行動認識・イベントローカライゼーション・時系列QAといった高難度課題への適応力が高まりました。


Qwen3-VLの特徴
Qwen3-VLは、従来のマルチモーダルモデルが抱えていた「見ること」と「理解すること」の間のギャップを埋めるべく設計されたシリーズ。
視覚・言語・時間情報を高密度に統合し、「認識」から「推論」「実行」へと踏み込む性能を備えています。
視覚エージェントとしての行動能力
Qwen3-VLは、画像認識だけでなく実際の操作を伴う理解までを担う「Visual Agent」として設計されています。GUI要素を認識し、ボタンや入力フォームの機能を理解しながら、アプリやウェブ環境上での操作を自動化可能。
これにより、単なる質問応答を超えた「行動するAI」としての利用が可能になりました。
テキスト中心の高精度性能
モデルの基盤にはテキストと視覚の事前学習が行われており、言語的な理解・生成の精度が極めて高い点が特徴です。
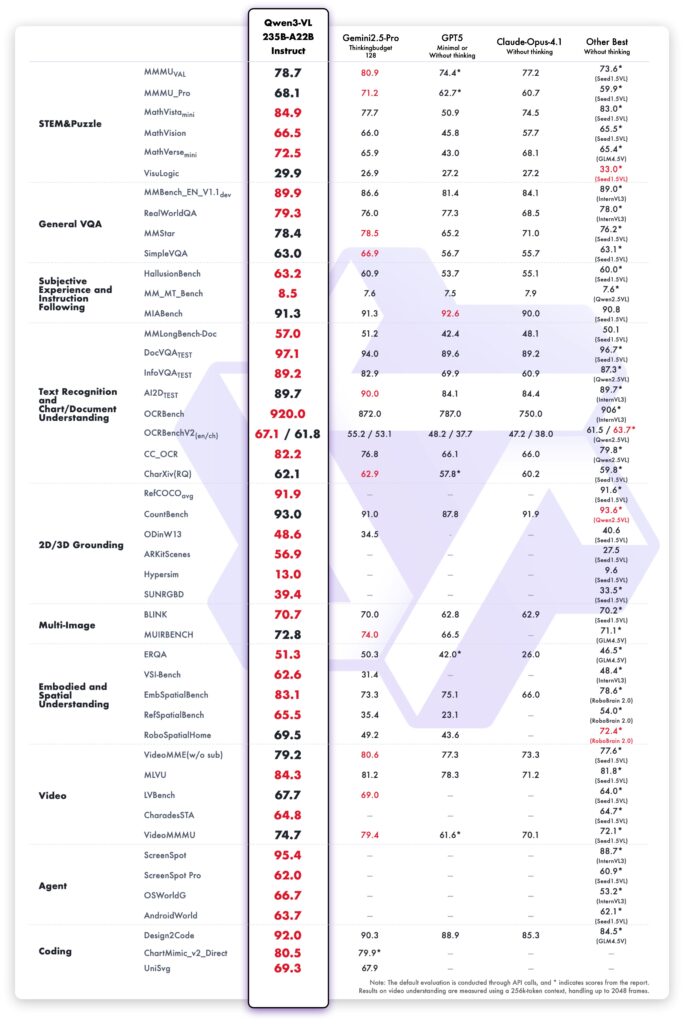
Qwen3-VLはテキスト処理において、同系列の言語モデル「Qwen3-235B-A22B-2507」とほぼ同等の性能を持ち、テキスト主導のマルチモーダル応用に強みを発揮。
視覚からコードを生み出す生成力
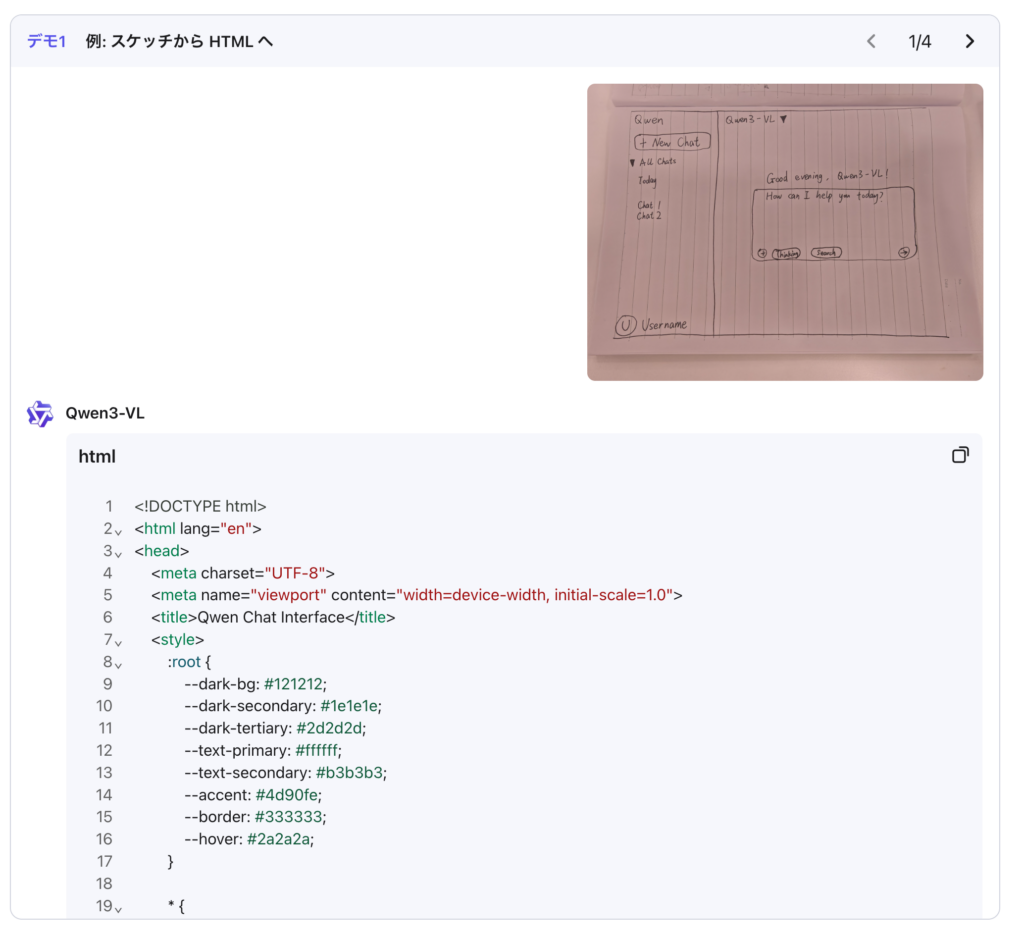
Qwen3-VLは、画像や動画から直接コードを生成する機能もあります。
UIデザインのモックアップを読み取り、HTMLやCSS、JavaScriptなどのコードを自動生成することが可能。「見たものをそのまま動かす」ビジュアルプログラミングを実現し、開発作業の効率を大幅に向上させます。
Qwen3-VLの安全性・制約
Qwen3-VLは、高性能なマルチモーダル推論能力を備える一方で、その運用における安全性と利用範囲の管理を重視して設計されています。
モデルにはコンテンツフィルタリングが組み込まれており、暴力・差別・政治的偏向を含む表現や、個人を特定しうる画像・音声データの解析結果は制限されます。
Qwen3-VLの料金
Qwen3-VLの料金は下記のとおりです。※2
| リクエストあたりの入力トークン | 入力価格 (百万トークン) | 出力価格 (百万トークン) |
|---|---|---|
| 0 < トークン ≤ 32K | $0.20 | $1.60 |
| 32K < トークン ≤ 128K | $0.30 | $2.40 |
| 128K < トークン ≤ 256K | $0.60 | $4.80 |
なお、128kトークン長文処理&マルチモーダル対応のLLM「Mistral Small 3.1」について詳しく知りたい方は、下記の記事を合わせてご確認ください。

Qwen3-VLのライセンス
Qwen3-VLは、Apache License 2.0で公開されています。このライセンスは商用利用・改変・再配布を広く許容するオープンソースライセンスであり、研究開発から産業応用まで幅広い利用が可能
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
上記はQwen3-VLの利用用途で可能な一覧です。
なお、思考するAI「Qwen3-Max-Thinking」について詳しく知りたい方は、下記の記事を合わせてご確認ください。

Qwen3-VLの実装方法
Qwen3-VLはAPI経由で利用可能です。下記はQwen3-VLのデモコードです。
サンプルコードはこちら
from openai import OpenAI
# set your DASHSCOPE_API_KEY here
DASHSCOPE_API_KEY = ""
client = OpenAI(
api_key=DASHSCOPE_API_KEY,
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen3-vl-235b-a22b-instruct",
messages=[{"role": "user", "content": [
{"type": "image_url",
"image_url": {"url": "https://dashscope.oss-cn-beijing.aliyuncs.com/images/dog_and_girl.jpeg"}},
{"type": "text", "text": "这是什么"},
]}]
)
print(completion.model_dump_json())上記のサンプルコードがGitHubに掲載されているので、APIキーを入力して実行したところ、下記のようなエラーになってしまいます。新たにAPIキーを取得しても同様でした。
AuthenticationError: Error code: 401 - {'error': {'message': 'Incorrect API key provided. ', 'type': 'invalid_request_error', 'param': None, 'code': 'invalid_api_key'}, 'request_id': 'cf6e5f15-5a1f-48b6-8305-fb0b2b1523c5'}Qwen Chatにモデルが用意されているので、こちらから使うのが良さそうです。


Qwen3-VLの活用事例
Qwen3-VLは、画像・動画・テキストを横断的に理解し、思考・実行までを担える点を生かして、さまざまな領域での活用が期待できます。
ここではいくつか活用事例について考えてみます。
デザイン・開発支援
画像からHTMLやCSS、JavaScriptなどのコードを自動生成する機能は、フロントエンド開発やUIデザインで活用可能。
手描きスケッチやモックアップ画像を即座に動作するウェブページへ変換できるため、プロトタイプ開発の効率が飛躍的に向上するでしょう。さらに、既存サイトのスクリーンショットを解析してコード構造を再構築することも可能で、リバースエンジニアリングや再設計の場面でも有効です。
ドキュメント・知識管理
長文脈処理性能を生かし、Qwen3-VLは数百ページ規模の技術文書やスキャンPDFを解析し、構造化データを作ることも可能。
また、多言語OCRを組み合わせれば、異言語の契約書や設計図面の自動翻訳・比較も可能です。これにより、知識資産の整理・要約・検索といったドキュメント管理業務を包括的に行うことができます。
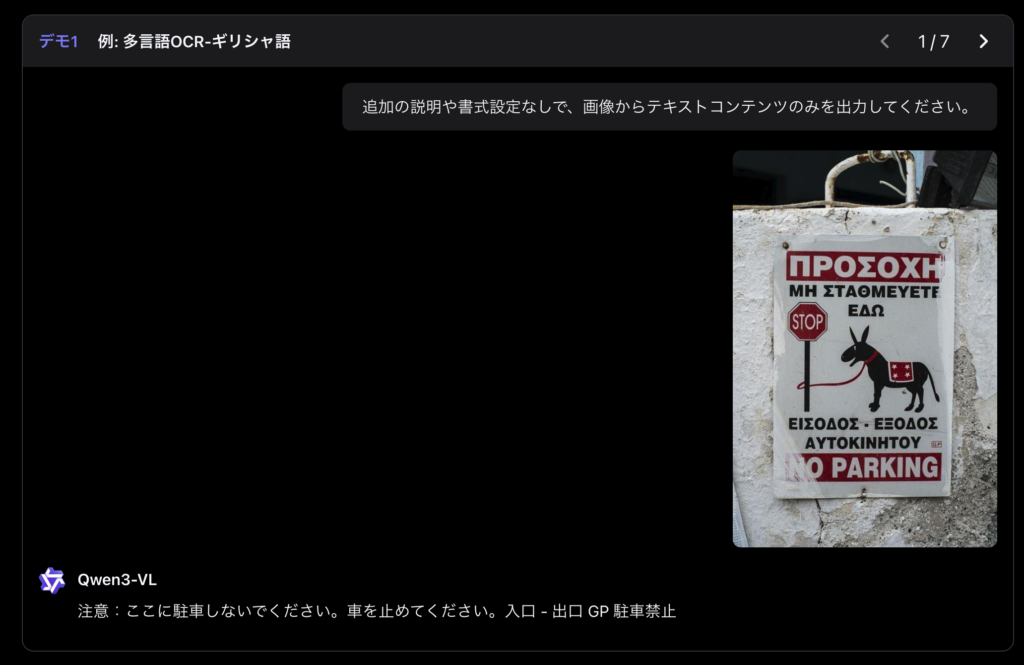
画像認識AIをOCR業務に活用したい方は、以下の記事もご覧ください。

Qwen3-VLを実際に使ってみた
Qwen3-VLにはエージェント機能も備わっており、指示に従って動作するようです。
上記デモ動画に倣って、私も実際に指示を与えてみました。
何かが違うようで、エージェントとして機能はしてくれませんでした。
Qwen3-VL can not only understand images but also operate smartphones and computers like a human, automating many daily tasks. For example, it can open apps, tap buttons, or fill in forms—enabling intelligent interaction and automation.
Qwen3-VL: Sharper Vision, Deeper Thought, Broader Action
日本語訳:Qwen3-VLは画像を理解できるだけでなく、人間のようにスマートフォンやコンピューターを操作し、多くの日常タスクを自動化できます。例えば、アプリを開いたり、ボタンをタップしたり、フォームに入力したりすることができ、知的なインタラクションと自動化を実現します。
上記のように公式ページに記載されているので、エージェント機能を使えるかなと思ったのですが。
なお、リアルタイム音声出力も可能なQwen3-Omniについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

まとめ
本記事ではQwen3-VLの概要から仕組み、実際の使い方を解説しました。これまでのマルチモーダルモデルに比べて性能は向上、さらにはエージェント機能も兼ね備えているということで、今後使い込んでみたいと思います。
ぜひ皆さんも本記事を参考にQwen3-VLを使ってください!

最後に
いかがだったでしょうか?
AIを活用した業務改善や価値創出をご検討中の企業様は、ぜひお問い合わせください。
貴社の課題に合わせて最適なソリューションをご提案します。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

