
【Qwen3-TTS】49種類のボイスと10言語対応の最新音声合成モデルを徹底解説!

- Alibaba発の音声合成(TTS)モデルで、Qwen3-TTS-Flashのアップデート版
- Qwen3-TTS-Flashの特徴を引き継ぎつつ、声色が49種類へと大幅に拡張
- リズムや間の自然さが一段と高まっている
2025年12月5日、アリババクラウドのQwenチームが新たな音声合成モデル「Qwen3-TTS」を公開しました!
これはテキストから自然な音声を生成する最先端の音声生成モデルで、なんと49種類以上の声色を使い分け、10言語に対応した多言語合成を実現しています。
さらに、中国語の主要な方言(閩南語、呉語、広東語、四川語、北京語など)にも対応し、地域のニュアンスまで表現可能となっています。
本記事では、このQwen3-TTSの特徴や性能、利用方法などを詳しく解説し、その実力に迫っていきます!
ぜひ最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
Qwen3-TTSの概要

Qwen3-TTSは、アリババクラウドが開発した次世代のフラッグシップ音声合成モデルです。
先行モデルのQwen3-TTS-Flash(2025年9月公開)と同様に、多彩な声色・多言語対応・多方言対応を特徴としますが、今回アップデートされたQwen3-TTSでは、各機能がさらに強化されています。
例えば、声質はかわいらしい少女から落ち着いた年配の声まで49種類以上が用意されていて、文章の内容や用途に応じて選ぶことができます。
言語も英語、中国語、日本語を含む10か国語に対応し、中国語の主要方言9種にもネイティブレベルで対応しています。
単にテキストを読み上げるだけでなく、文章のトーンや話者の感情、意図まで理解して喋り方に反映できるのも大きな特徴です。例えば同じ「こんにちは」という一言でも、フレンドリーな口調から厳粛な口調まで自在に表現し、文脈に合った抑揚や間の取り方で発話してくれます。
また、Qwen3-TTSには音声クローン(話者の声の複製)機能も導入されており、音声サンプルからその人の声色を学習して、合成音声に反映することも可能になっています。


Qwen3-TTSとQwen3-TTS-Flashの違い
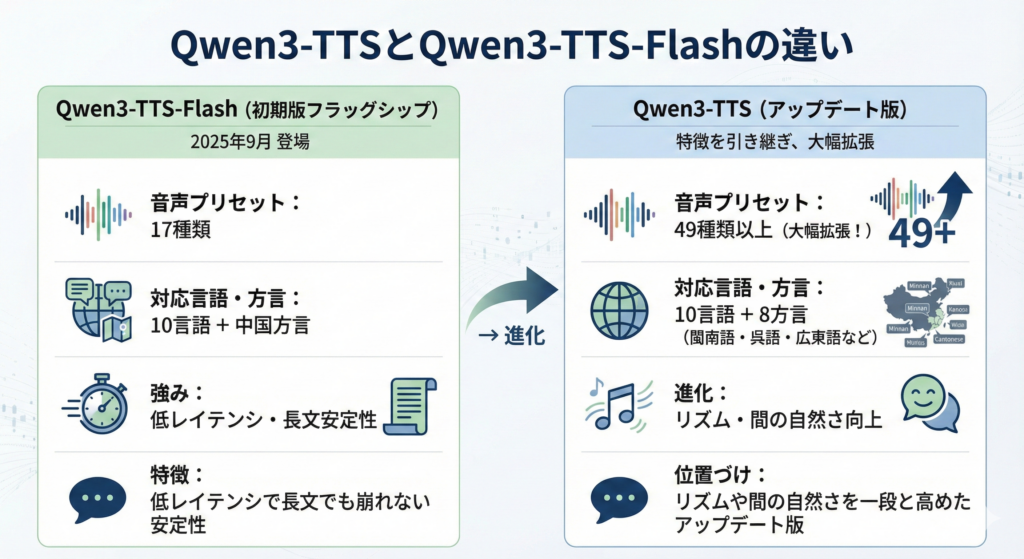
Qwen3-TTS-Flashは、2025年9月に登場した初期版のフラッグシップTTSで、17種類の音声プリセットと10言語対応+中国方言対応を備えており、「低レイテンシで長文でも崩れない安定性」を強みとしていました。
一方、今回発表されたQwen3-TTSは、Qwen3-TTS-Flashの特徴を引き継ぎつつ、声色が49種類以上へと大幅に拡張され、同じく10言語に加えて閩南語・呉語・広東語など8方言をサポートし、リズムや間の自然さを一段と高めたアップデート版という位置づけとなっています。
なお、Qwen3-TTS-Flashについて詳しく知りたい方は、以下の記事も参考にしてみてください。

Qwen3-TTSの性能
Qwen3-TTSの性能は現行のオープンソース音声合成モデルの中でもトップクラスです。
まず、音声の自然さを評価する社内指標では、「あまりに人間らしく不気味に感じるほど」と表現されるほどで、プロソディ(韻律)や抑揚の再現性が飛躍的に向上しています。
品質の高さは数値ベースのベンチマークにも表れていて、例えば、多言語音声合成の評価指標であるMiniMax TTSベンチマークにおいて、Qwen3-TTSは「内容の一貫性」スコアで平均5.20/6というトップ級の評価を獲得しています。
この値は、商用で定評のあるElevenLabs社の最新モデル(Speech-02-HD-V2, スコア4.00/6)や、OpenAIの音声生成プレビュー版(GPT-4o Audio, スコア3.61/6)を大きく上回るもので、業界最高水準の精度と言えるでしょう。
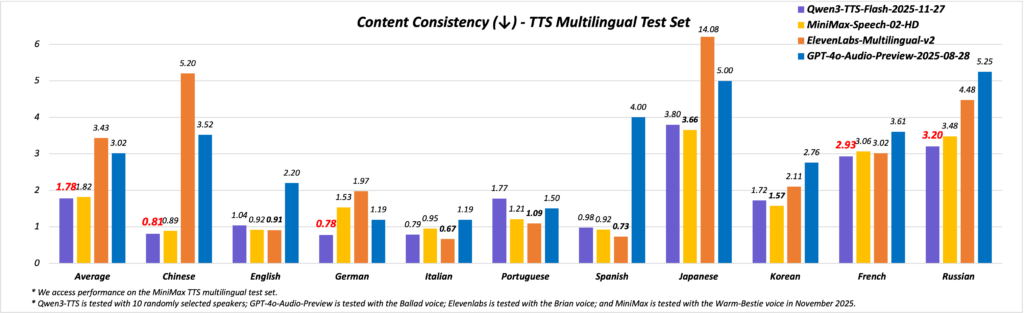
言語別に見ても、英語では5.22、スペイン語で4.48、フランス語で3.48と各言語で高い評価を得ており、特に英語・中国語においてはほぼ人間の話者に迫る品質とされています。
Qwen3-TTSのライセンス
Qwen3-TTSのモデル本体(学習済みウェイト)は、2025年12月8日時点で、オープンソースとして公開されておらず、利用は基本的にアリババクラウドの提供するAPIやサービス経由となります。
したがって、ソースコード付きで自由に改変・再配布できるモデルではなく、利用には定められた利用規約の範囲内でAPIを呼び出す形になります。
| 利用用途 | 可否 | 備考 |
|---|---|---|
| 商用利用 | ⭕️ | |
| 改変 | ❌️ | |
| 配布 | ❌️ | |
| 特許使用 | ❌️ | |
| 私的使用 | ⭕️ |
Qwen3-TTSの料金
Qwen3-TTSの料金体系は、基本的に、アリババクラウドのModel Studioにおける従量課金制となっています。ただし新規ユーザー向けの無料枠も用意されているので、一定の範囲内であれば無料で試すことができます。
2025年12月8日時点での、プランごとの料金詳細を以下の表で整理します。
| プラン | 料金・条件 |
|---|---|
| 従量課金 | $0.10(約15円)/ 10,000文字あたり ※漢字は2文字分とカウント |
| 無料トライアル | Model Studio有効化から90日間で合計10,000文字まで無料 ※2025年11月13日以前に有効化済みのアカウントは2,000文字まで無料 |
上記のように、日本語など漢字を含む言語では、漢字1文字を2文字分として計算する点に注意が必要です。
Qwen3-TTSの使い方
Qwen3-TTSの利用方法は、「Hugging Face Spaces上のデモ」と「Model Studio API」の2つがあります。
Hugging Face Spaces上のデモ
とにかくQwen3-TTSをてっとり早く使いたい方は、こちらの方法がベストです。
Hugging FaceのQwen3-TTSデモページにアクセスすると、テキスト入力欄と言語・声質を選択するUIが表示されます。
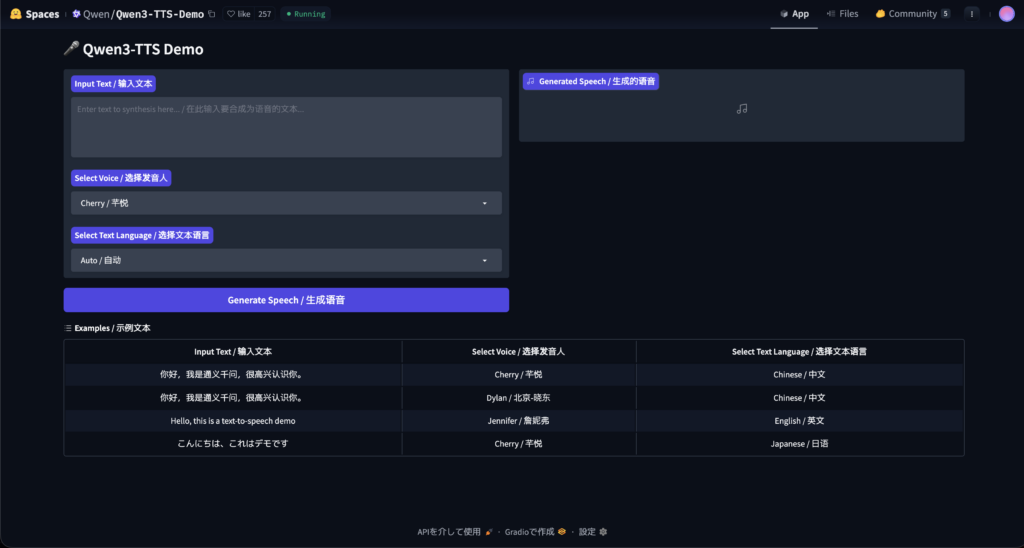
ちなみに、デモでは、Cherry(芊悦)というデフォルトの女性音声に加え、Ono Anna(小野アンナ?)といった日本語話者の音声プリセットも用意されています。
Model Studio API
開発者向けに、アリババクラウドのModel Studio APIを利用して、Qwen3-TTSを組み込む方法もあります。
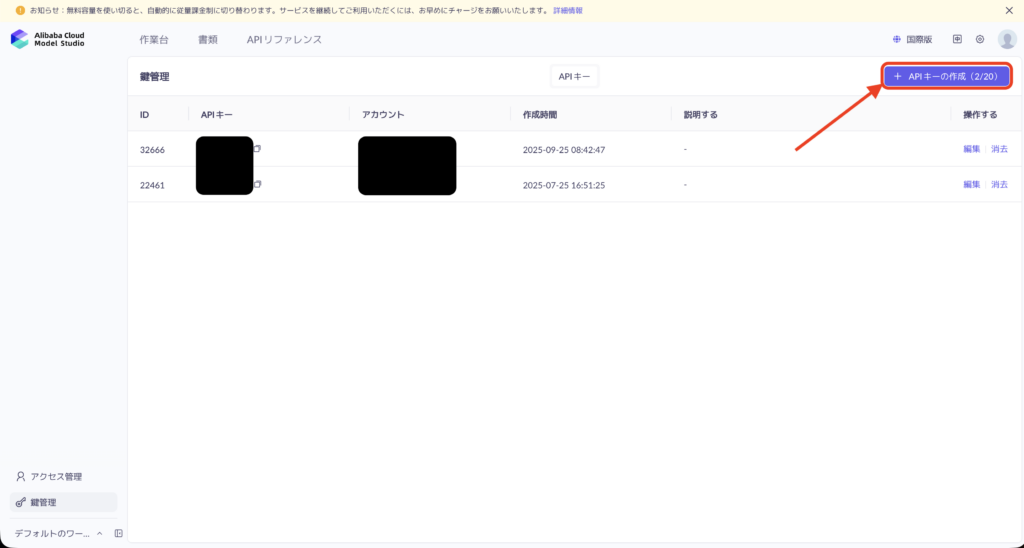
まずAlibaba Cloudにサインアップ/ログインしたら、Model Studioコンソールを開き、画面上部から「Key Management(API Key)」ページに移動します。
そこで「Create API Key」ボタンを押してキーを発行し、作成されたAPIキーを自分のPCの環境変数(例として DASHSCOPE_API_KEY)や設定ファイルに控えておきます。
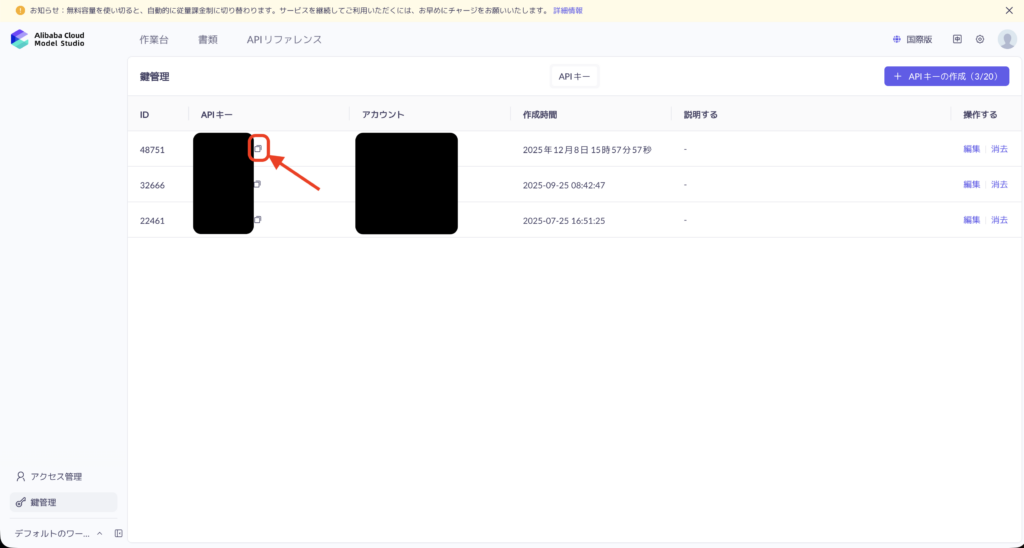
次に、同じModel Studio内でQwen3-TTSのモデルページを開くと、「API Example」「SDK Example」といったタブが用意されているので、ここからPythonやcurlのサンプルコードをそのままコピーします。
Pythonであれば、あらかじめターミナルで pip install dashscope requests python-dotenv のようにSDKとHTTPクライアントを入れておいて、 api_key に先ほど発行したAPIキーを渡し、model にドキュメントに記載されているQwen3-TTSのモデルID(qwen3-tts-flash-2025-11-27)を指定します。

あとは text に読み上げたい文字列、voice に利用したい話者名を設定してスクリプトを実行すれば、レスポンスとして音声ファイルのURLやバイナリデータが返ってきます。
import os
import requests
import dashscope
API_KEY_ENV = "DASHSCOPE_API_KEY"
def synthesize_with_qwen3_tts(
text: str,
save_path: str,
voice: str = "Ono Anna",
model_id: str = "qwen3-tts-flash-2025-11-27",
language_type: str = "Japanese",
) -> None:
"""Qwen3-TTS で音声を合成してローカルに保存する簡易ヘルパー"""
api_key = os.getenv(API_KEY_ENV)
if not api_key:
raise RuntimeError(f"{API_KEY_ENV} が設定されていません。")
# 必要に応じてリージョン指定(国際リージョンを使う場合はこれを指定)
dashscope.base_http_api_url = "https://dashscope-intl.aliyuncs.com/api/v1"
dashscope.api_key = api_key
response = dashscope.MultiModalConversation.call(
model=model_id,
api_key=api_key,
text=text,
voice=voice,
language_type=language_type,
stream=False,
)
audio = getattr(response.output, "audio", None)
if not audio or "url" not in audio:
raise RuntimeError("Qwen3-TTS API error: audio URL がレスポンスに含まれていません。")
audio_url = audio["url"]
# 実際の音声データをダウンロード
resp = requests.get(audio_url, timeout=10)
resp.raise_for_status()
with open(save_path, "wb") as f:
f.write(resp.content)
print(f"音声ファイルを {save_path} に保存しました。")
if __name__ == "__main__":
sample_text = "Qwen3-TTS を使った日本語の読み上げテストです。"
synthesize_with_qwen3_tts(sample_text, "qwen3_tts_sample.wav")処理が正常に完了すれば、同じディレクトリに qwen3_tts_sample.wav が生成されると思います。任意のメディアプレーヤーで再生すれば、Qwen3-TTS が生成した音声をすぐに確認できます。
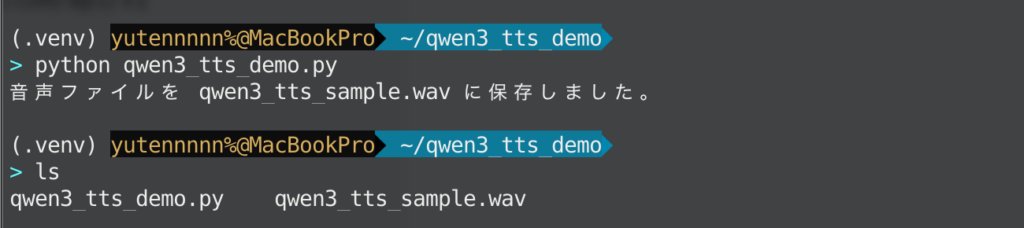
今回、言語は日本語、スピーカーは先程触れたOno Annaを指定しましたが、日本語部分についてはある程度自然な音声になっていることが分かります。
みなさんも、お好きな方法・設定で試してみてください。


Qwen3-TTSの活用イメージ
ここでは、エンジニアやクリエイターが「自分のプロダクトにどう組み込めるか」をイメージしやすいように、代表的な活用パターンを整理してみます。
コンテンツ制作のナレーション/ボイスオーバー
1番わかりやすいのは、動画や資料コンテンツのナレーションです。
Qwen3-TTSは、ニュース読み上げのような落ち着いた声から、配信者風、やわらかい先生風の声まで、幅広いボイスプリセットを備えており、同じテキストでもキャラクターを切り替えて量産することができます。
YouTubeの解説動画、製品紹介ムービー、社内研修用eラーニング、PoCのデモムービーなど、とりあえず収録前に仮ナレを入れて雰囲気を確認したい、といったシーンでも重宝すると思います。
カスタマーサポート・ボイスボット
もうひとつ有効なのが、問い合わせ窓口やコールセンターのボイスボットです。
Qwen3-TTSはリアルタイム合成やSSMLにも対応していて、API経由で低レイテンシに音声を返せるように設計されています。
これを音声認識エンジンや、Qwen3-Omniのような対話モデルと組み合わせれば、「電話やWebの音声チャットで1次対応をしてくれるAIオペレーター」を比較的シンプルに実現できると思います。
問い合わせ内容に応じて声色を変えたり、丁寧さを調整したりすることで、いわゆる機械感を減らして、人間に近い体験を提供しやすくなります。
教育・学習コンテンツ/アクセシビリティ
教育分野との相性もかなり良さそうです。
教材の読み上げ、語学学習アプリの例文音声、プログラミング教材のコード説明などを、すべてQwen3-TTSでカバーすることもできると思います。
視覚障害のある学習者向けに、教科書や社内資料を自動で読み上げる仕組みを用意したり、子ども向けにはやわらかい声・ゆっくりめの速度で再生したりと、ボイスプリセットと話速調整の組み合わせで、聞き手に合わせた学習体験をつくりやすい点も魅力です。
なお、ボイスボットの事例で紹介した「Qwen3-Omni」について詳しく知りたい方は、以下の記事も参考にしてみてください。

まとめ
Qwen3-TTSは、2025年12月時点において、最高水準の音声合成モデルの1つです。
49種類もの個性的な話者音声を設定できて、10言語+方言まで自在に操る能力は、多言語社会におけるコミュニケーション支援やコンテンツ制作の現場で大きな価値を生み出してくれると思います。
気になる方はぜひ一度試してみてください!

最後に
いかがだったでしょうか?
弊社では、AI導入を検討中の企業向けに、業務効率化や新しい価値創出を支援する情報提供・導入支援を行っています。最新のAIを活用し、効率的な業務改善や高度な分析が可能です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

