
【社内ドキュメントをAI検索に】Grok Collections APIとは?検索の仕組みと使い方をわかりやすく解説

- Grok Collections APIとは、Grokが必要な情報を検索して答えるための専用ナレッジベース
- 難しいインフラ構築(ベクトルDBや検索エンジンの用意)がいらず、API経由で手軽に使える
- ファイル作成と保存は最初の1週間のみ無料で、検索は1,000回につき2.5ドルの定額料金がかかる
2025年12月22日、xAIはGrok Collections APIをリリースしました。
Grok Collections API は、xAIが提供する「Grok」という大規模言語モデル向けの機能で、PDF・Excel・スライドなどのファイルをまとめてアップロードし、それらをもとにGrokが賢く答えてくれるようにするためのAPIです。
イメージとしては、「Grok専用のクラウド上の本棚&検索システム」を簡単に用意できるようになるものだと考えると分かりやすいかもしれません。
この記事では、生成AIにまだあまり詳しくない方でも理解できるように、Grok Collections APIの概要や仕組み、使い方まで徹底解説します。
最後までお読みいただくと、自社のドキュメントを活かした生成AIを作るイメージがつかめ、社内外の問い合わせ対応を効率化するヒントが得られます。
ぜひ最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
Grok Collections APIの概要
Grok Collections APIは、Grokに自分専用のナレッジベースを持たせるためのAPIです。
PDF・Excel・スライド・コードなどのファイルをオンライン上の「コレクション」として登録しておくことで、Grokがそれらを理解し、質問に応じて最適な情報を探して答えてくれます。
従来の方法でナレッジベースを構築しようとすると、ベクトルデータベースの用意やRAG(検索拡張生成)という仕組みを自前で実装する必要があるため、生成AI初心者ではとても対応しきれません。
一方、Grok Collections APIなら開発者がベクトルデータベースや検索基盤を自前で構築する必要がなく、「ファイルをアップロードして、コレクションを指定して問い合わせる」というシンプルな流れでRAGアプリを構築できます。
なお、Grokについて詳しく知りたい方は、以下の記事もご覧ください。

Grok Collections APIの仕組み
Grok Collections APIは、ハイブリッド検索で長く複雑な文書から必要な一文を正確に引き出す仕組みです。
意味ベースのセマンティック検索と、完全一致のキーワード検索を組み合わせることで、金融レポートの数値・表・契約書の条文・巨大なコードベースの関連箇所を取りこぼしにくくしています。
公式ベンチマークでは、金融・法律・コーディングといった難しいRAGタスクで、GoogleやOpenAIと同等かそれ以上の検索精度を記録しており、グラフでもその優位性が示されています。
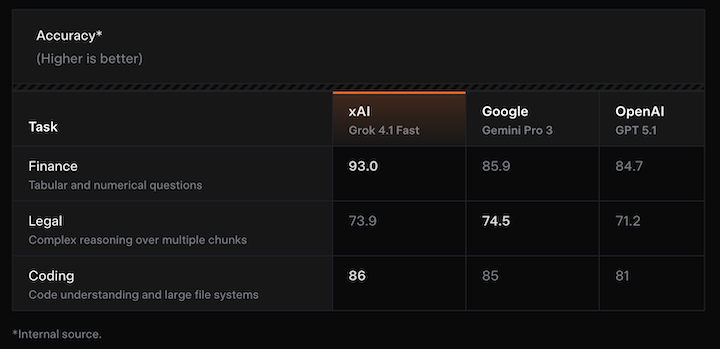
Grokはこの高精度な検索結果を前提に推論するため、ハルシネーション(幻覚)を減らし、根拠のある回答を返しやすくなるのが特徴です。


Grok Collections APIの特徴
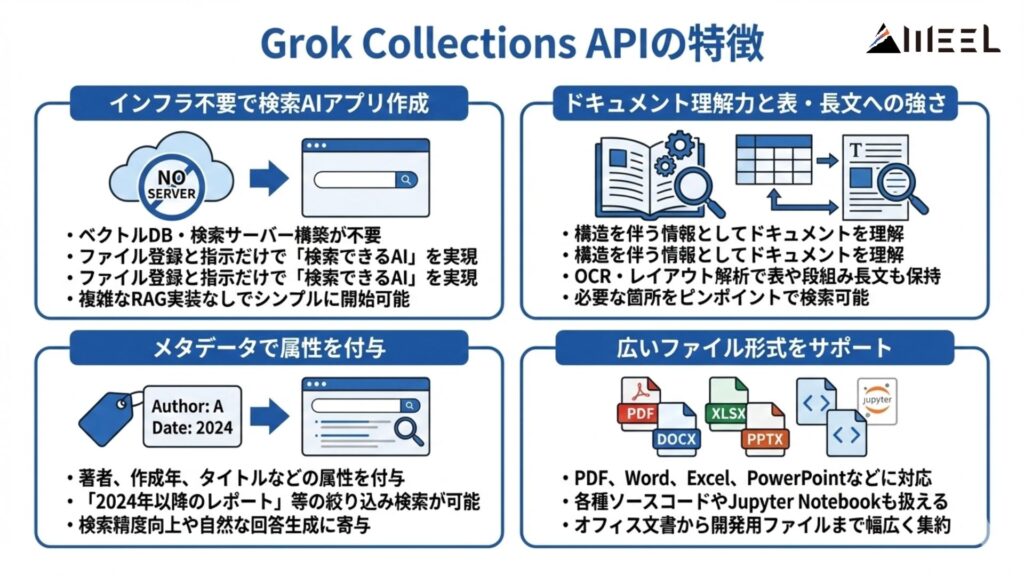
Grok Collections APIには、RAGの仕組みをよく知らなくても扱いやすくするための工夫がいくつも用意されています。
ここでは、その中でも代表的な4つの特徴を紹介します。
インフラなしで「検索できるAIアプリ」を作れる
Grok Collections APIを使うと、ベクトルDBや検索サーバーなどのインフラを自分で用意しなくても、「検索できるAIアプリ」を作れます。
PDFやExcelなどのファイルをコレクションとして登録しておくだけで、あとはGrokに「このコレクションを使って答えて」と指示するだけでOKです。
難しいRAGの実装を自前で組む必要がなく、「ファイルを入れる→質問する」というシンプルな構成で始められます。
ドキュメント理解力が高く表や長文にも強い
Grok Collections APIは、ドキュメントの中身を「ただの文字列」としてではなく、構造を持った情報として理解できるのが強みです。
OCRやレイアウトを意識したパーサーによって、表や図、段組みされた長文などもできるだけ元の構造を保ったままインデックス化します。
そのおかげで、財務諸表の数値や契約書の条文、巨大なコードベースの一部など、「どこに何が書いてあるか」が大事なケースでも、必要な箇所をピンポイントで探しやすくなっています。
メタデータフィールドでドキュメントに属性を付与できる
Grok Collections APIでは、ドキュメントごとに「著者」「作成年」「タイトル」「部門」などのメタデータ(属性)を付けられます。
「2024年以降のレポートだけ」「法務部が作成した契約書だけ」といった絞り込み検索をしやすくなるのがメリットです。
また、重要なメタデータをチャンク(分割されたテキスト)側に埋め込んでおくことで、検索精度を高めたり、回答文の中に自然な形で情報を含めたりできるのもポイントです。
広いファイル形式サポート
Grok Collections APIは、テキストだけでなく、さまざまな形式のファイルをまとめて扱えるようになっています。
対応例としては、次のようなものがあります。
- PDF資料(提案書・マニュアル・レポートなど)
- Wordやその他のテキストドキュメント
- Excelなどのスプレッドシート
- PowerPointなどのスライド資料
- 各種プログラミング言語のソースコードやJupyter Notebook
日常的に使うオフィス文書から、開発現場で使うコードやノートブックまで、そのままコレクションに登録して検索対象にできるのが便利なポイントです。
Grok Collections APIの安全性
Grok Collections APIでは、アップロードしたファイルやインデックスはサーバー側で暗号化されて保存され、第三者から直接中身を見られないように配慮されています。
また、コレクションに登録したデータは、ユーザーが同意しない限りモデルの再学習には使われないことも公式に明記されています。※1
ただし、安全だからといって何でも入れてよいわけではありません。社内規程や契約上のルールに沿って、アクセス権の管理や個人情報・機密情報の取り扱いには注意しながら利用しましょう。
Grok Collections APIの料金
| 項目 | 内容 |
|---|---|
| ドキュメント検索(Collections Search / Documents Search) | 2.50ドル / 1,000 リクエスト ※最初の1週間は無料 |
| モデル利用(Grok など) | 使うモデルごとのトークン単価に従う |
Grok Collections APIの料金は、大きく分けて「ドキュメント検索のAPIコール料金」と、「Grok本体のモデル利用料金(トークン課金)」の2つに分かれます。
Collections APIでコレクションを検索するときにリクエスト単位で課金され、その後の回答生成に使われるトークン分が、利用するGrokモデルの料金として別途かかるイメージです。
なお、Grok Collections APIによるインデックス作成と保存は、最初の1週間のみ無料で利用できます。
Grok Collections APIのライセンス
| 利用用途 | 可否 |
|---|---|
| 商用利用 | 可能 |
| 改変 | 不可 |
| 配布 | 不可 |
| 特許使用 | 不明 |
| 私的使用 | 可能 |
Grok Collections APIは、xAIが提供するクラウドAPIサービスとして提供されているため、xAIの利用規約やプライバシーポリシーなどに従って利用する必要があります。
基本的には、API経由で得た結果を業務やサービスに組み込むこと自体は可能ですが、APIキーの共有や禁止用途への利用などは規約違反となるため、実利用前に公式の利用規約を確認しておくことが重要です。
Grok Collections APIの使い方
Grok Collections APIを使うためには、APIキーの取得をはじめとした事前準備が必要です。
ここでは、APIキーの取得から実際にコレクションを作成して検索するまでの手順を解説します。
xAI ConsoleでAPI KeyとManagement API Keyを入手する
Grok Collections APIを使うためには、API KeyとManagement API Keyの2つが必要です。
- API Key→Collections検索やGrokを呼び出すための鍵
- Management API Key→Collections管理やファイル追加をコードで実行する際に必要な管理用の鍵
まずはxAI Consoleにアクセスして、GoogleアカウントやXのアカウントでログインします。
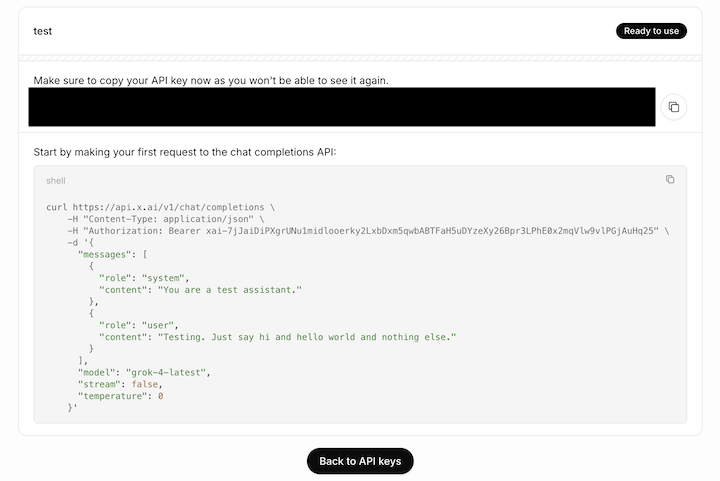
左側にあるサイドバーの「API Keys」を選択して、「Create API Key」をクリックしてください。
Nameの部分に任意の名前をつけ、下の「Create API Key」をクリックします。
上記画像の黒枠部分にAPIキーが表示されるので、実際にAPIキーを入力するときにコピーして使ってください。
続いて、Management API Keyを取得します。
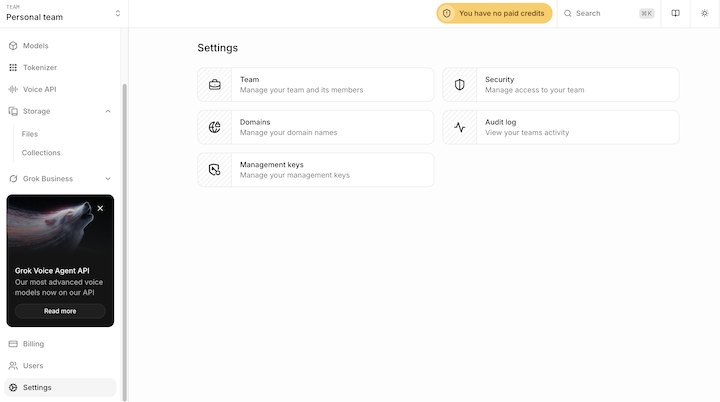
Management API Keyは、サイドバーの「Settings」→「Management API Key」から取得できます。
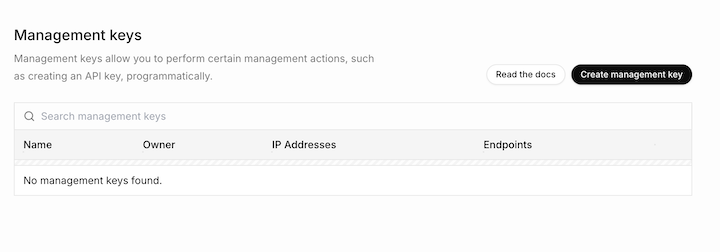
右上の「Create Management API Key」をクリックしてください。
任意の名前をつけ、それぞれのアクセスレベルを指定します。
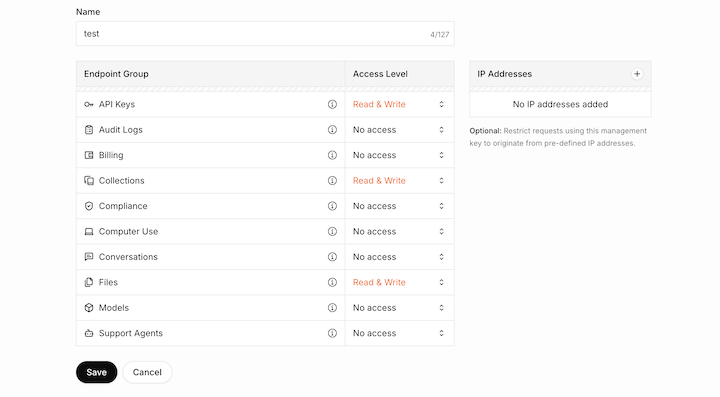
Grok Collections APIを利用するなら、「API Keys」「Collections」「Files」のアクセス許可が必要です。
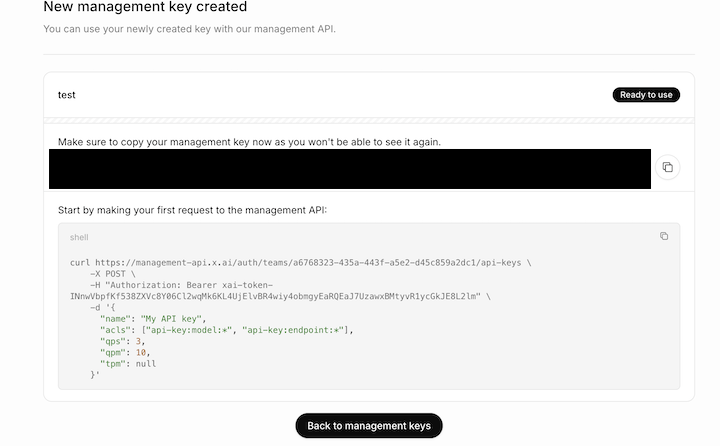
Management API Keyが発行されるので、Grok Collections APIを利用するときにコピーして使ってください。
なお、Grok Collections APIの利用にはクレジットが必要なため、支払い情報の登録とクレジットの購入も済ませておきましょう。
Management API Keyは、コードからコレクションの作成・削除やドキュメントのアップロードなど「管理まわり」を自動化したいときに必要になる鍵です。この記事で紹介しているように、コンソール上でコレクションを作成し、通常のAPIキーで検索・回答させるだけであれば、Management API Keyがなくても利用できます。
コレクションを作る
事前準備が完了したので、コレクションを作ります。
ここでいうコレクションとは、Grokに検索させるドキュメントを格納するための本棚みたいなものです。
コレクションを作る際は、サイドバー「Collections」内の「Create your first Collection」をクリックします。
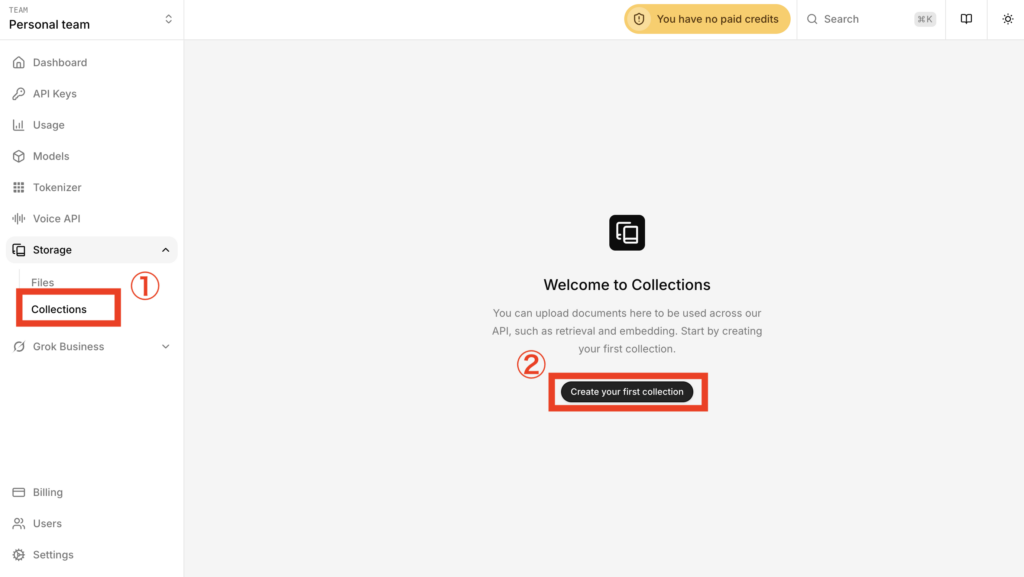
コレクションの名前や説明を入力し、メタデータ(属性)を付与する場合は、「Metadata settings」の各項目も入力します。
- Key→メタデータの項目名(author・department・year・languageなど)
- Inject→メタデータの値を、検索用のテキストチャンクの中に一緒に埋め込むかを決めるスイッチ
- Unique→メタデータがコレクション内で被らないかどうかを指定
- Description→メタデータの説明文
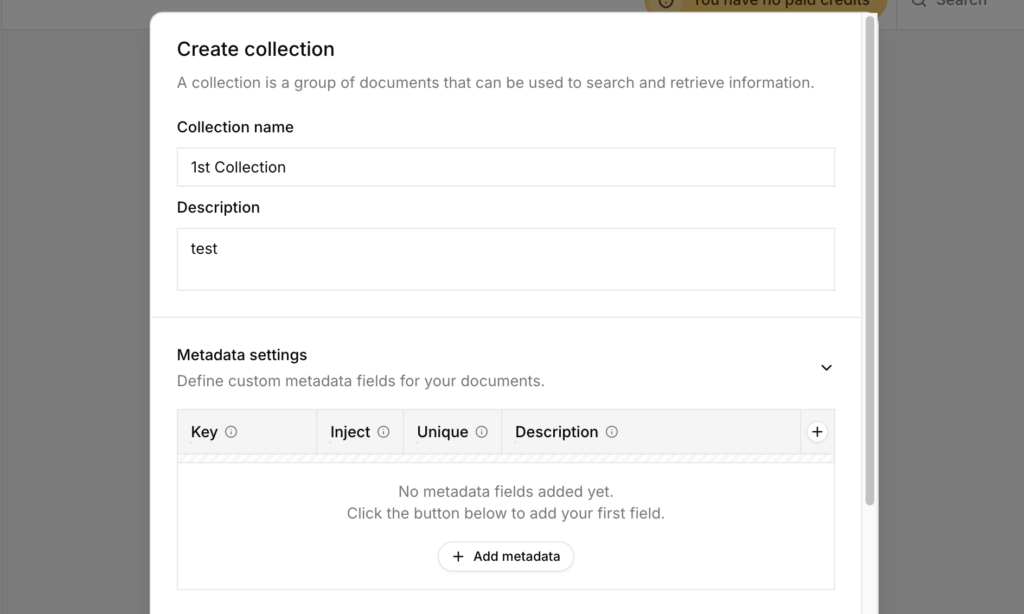
下部にあるEmbeddings(埋め込みとチャンク設定)は、「検索の質」と「処理コスト」に関わる部分です。
よくわからない方は初期設定で問題ありません。
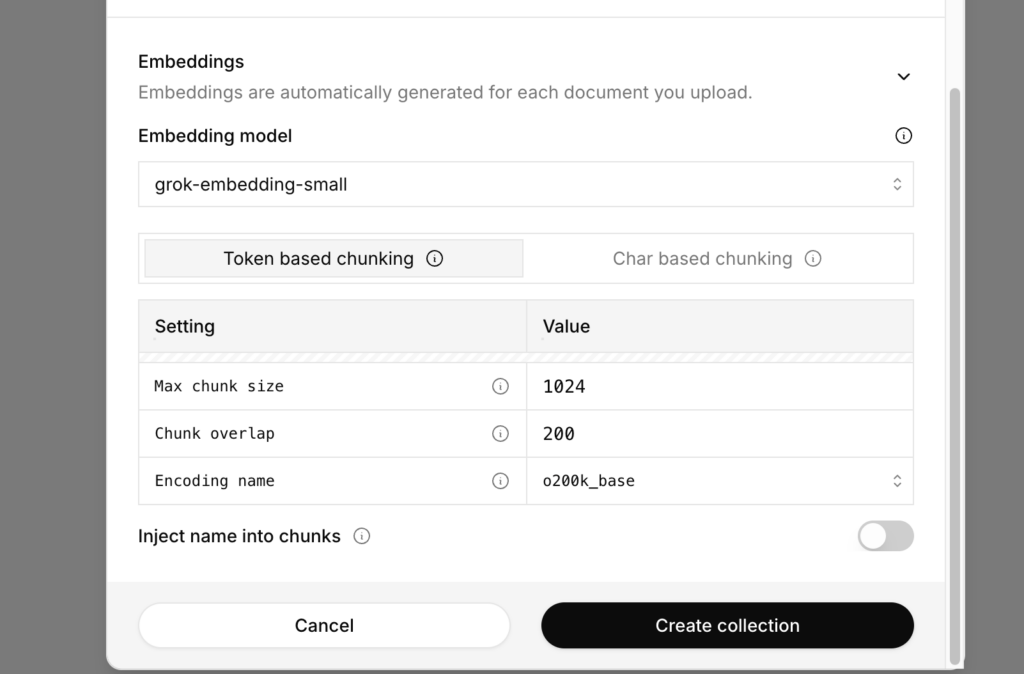
| 項目名 | 何か |
|---|---|
| Embedding model | ドキュメントをベクトル化するための埋め込みモデル |
| Token based chunking / Char based chunking | ドキュメントをどの単位で細切れ(チャンク)にするかを決める方式 |
| Max chunk size | 1チャンクに含める最大サイズ(トークン数) |
| Chunk overlap | チャンク同士をどれくらい重ねるか(オーバーラップさせるか)の量 |
| Encoding name | どのトークナイザー方式でテキストをトークンに分解するかを指定する項目 |
| Inject name into chunks | ドキュメント名などを各チャンクのテキストに埋め込むかどうかを決める設定 |
ここまで設定できたら、「Create Collection」をクリックしてコレクションの作成を完了しましょう。
ドキュメントをアップロードする
作成したコレクションに、Grokに検索させるためのドキュメントをアップロードします。
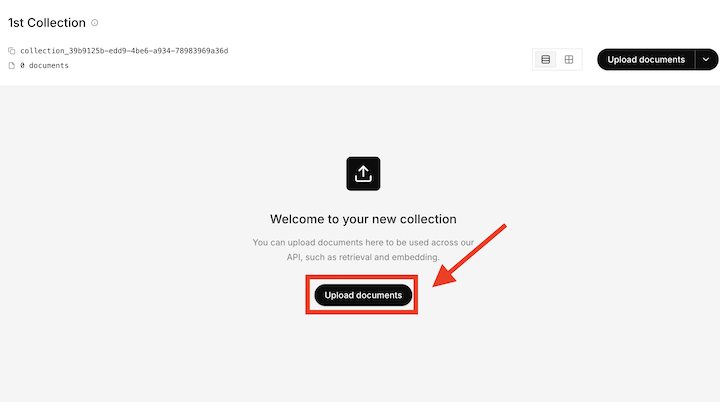
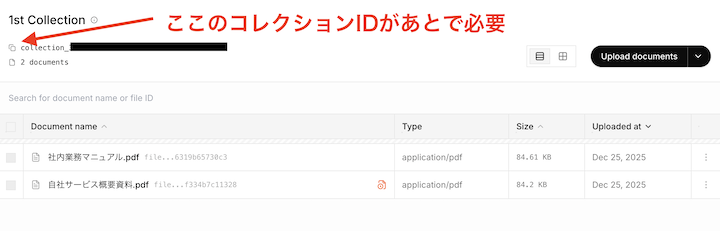
ドキュメントをアップロードするとコレクションIDが発行されるので、コピーしておきましょう。
Grokとコレクション検索を組み合わせて回答を生成する
コレクションにドキュメントを入れたら、次はGrokにそのコレクションを参照させて回答してもらいます。
やることはシンプルで、chat APIに「collections_search」ツールを渡し、「このコレクションの中だけを根拠に、この質問に答えて」というリクエストを送るイメージです。
筆者はMacを使用しているので、ターミナルでSDK(開発者向けのツールセット)をインストールするところから始めます。
pip install --upgrade xai-sdk次にAPIキーを入力して環境変数を設定します。
export XAI_API_KEY='ここにXAI_API_KEY'環境変数を設定したら、python3を立ち上げます。
python3プロンプト「>>>」の形になっていたら無事に立ち上がっているので、続けて以下のコードを入力してGrokにコレクション検索をしたうえで回答を要求します。
from xai_sdk import Client
from xai_sdk.chat import user, system
from xai_sdk.tools import collections_search
client = Client() # XAI_API_KEY は環境変数から読む想定
chat = client.chat.create(
model="grok-4-1-fast",
messages=[
system("You are an assistant that answers ONLY based on the internal manual collection."),
user("探したい情報を入力"),
],
tools=[
collections_search(
collection_ids=["ここにコレクションID"], # ConsoleからコピペしたID
retrieval_mode="hybrid",
),
],
)
response = chat.sample()
print("=== モデルの回答 ===")
print(response.content)上記のように、Grokはコレクション内のドキュメントを検索したうえで、マニュアルの該当箇所を要約・整理して回答してくれます。
そのため、画面にはGrokの回答文をそのまま表示し、必要に応じて「この回答は社内マニュアルを元にしています」といった注釈や参照元リンクを添えて活用するとよいでしょう。
Grok Collections APIを実際に使ってみた
Grok Collections APIを実際に使って、いくつかアップロードした社内マニュアルの中から、有給休暇の申請ルールに関する情報を検索して回答してもらいます。
今回は以下のコードを入力してリクエストしました。
from xai_sdk import Client
from xai_sdk.chat import user, system
from xai_sdk.tools import collections_search
client = Client() # XAI_API_KEY は環境変数から読む想定
chat = client.chat.create(
model="grok-4-1-fast",
messages=[
system("You are an assistant that answers ONLY based on the internal manual collection."),
user("有給休暇の申請ルールを教えて"),
],
tools=[
collections_search(
collection_ids=["ここにコレクションID"], # ConsoleからコピペしたID
retrieval_mode="hybrid",
),
],
)
response = chat.sample()
print("=== モデルの回答 ===")
print(response.content)回答は以下のとおり。

ドキュメントの情報を引用しながら、知りたい情報を回答してくれました!
このように、複雑な社内規定を素早く検索する用途で活躍するので、社内の問い合わせ業務が煩雑化している企業は導入を検討してみてください。
Grok Collections APIの活用シーン
Grok Collections APIは、「社内に散らばったファイルをまとめて生成AIに読ませておき、あとから自然文で質問できるようにする」使い方が得意です。
ここでは、特にイメージしやすい4つのシーン(マニュアル・法務・財務・開発)に分けて、どんな場面で役立つかを紹介します。
社内マニュアルやFAQをまとめた問い合わせチャットボット
社内マニュアルやFAQ、手順書などをひとつのコレクションにまとめておけば、「勤怠の申請方法は?」「このツールのアカウント申請はどこ?」といった質問にGrokが答えるチャットボットを作れます。
担当者に毎回聞かなくても、社員が24時間いつでも自己解決できるのがメリットです。マニュアルの更新も、ファイルを差し替えるだけで反映されるので運用もシンプルです。
契約書・規程類から必要な条文だけをすぐ探せる法務アシスタント
利用規約・各種契約書・社内規程などをコレクション化しておくと、「この契約の解除条件は?」「秘密保持の範囲は?」といった質問に対して、関連する条文の抜粋をすぐに引き出せます。
長い契約書を頭から読むのではなく、必要な条文にジャンプできるので、一次チェックやドラフト検討の効率が上がります。最終的な判断は法務担当が行いつつ、その手前の「探すコスト」を大きく減らすイメージです。
財務レポートや予算シートを横断して分析できるレポート検索
決算資料・予算や実績のExcel・部門別レポートなどをコレクションとして登録すると、「今年の広告費の推移は?」「この事業の粗利率が下がった理由は?」といった質問から、関連する数値やグラフの説明部分を検索できます。
ハイブリッド検索により、数値や表の位置も考慮してヒットさせられるので、該当するシートやセルの周辺説明も素早く見つかるのが魅力です。そこからさらに「人が細かい分析を行う」という流れが取りやすくなります。
大規模コードベースの仕様や実装意図を聞ける開発者向けAI
リポジトリのソースコードや設計ドキュメントをコレクション化すれば、「この関数はどこから呼ばれている?」「この機能の仕様はどのドキュメントに書いてある?」といった質問に答えてくれる開発者向けアシスタントとして使えます。
新しくチームに入ったエンジニアが、コードベース全体の構造や変更履歴をキャッチアップするのにも役立つほか、既存メンバーにとっても「過去の自分たちの判断」をすぐ引き出せるナレッジベースになります。
Grok Collections APIでドキュメントの検索効率を上げよう!
Grok Collections APIは、「社内に散らばったPDFやExcel、コードなどをまとめて生成AIに読ませておき、自然文で検索できるようにする」ための土台として、とても使いやすいサービスです。
ベクトルDBやRAGの細かい仕組みを理解していなくても、コレクションとドキュメントを用意するだけで、かなり実用的な検索体験をつくれます。
今後は対応形式や連携機能、モデル性能の向上によって、さらに実用度が増していくはずです。
導入する際は、まず「社内マニュアル」など小さな範囲のコレクションから試し、使い勝手や運用ルールを固めてから、徐々に対象を広げていきましょう。

最後に
いかがだったでしょうか?
Grok Collections APIを業務に取り入れることで、自社ドキュメントを活用した社内チャットボットや検索システムをスピーディーに構築し、問い合わせ対応や情報収集の工数削減が期待できます。
しかし、RAGの設計やセキュリティを踏まえた運用設計を自社だけで進めるのは難しいケースも多いため、Grokや生成AIの実装実績を持つパートナー企業と一緒に検討するのも有効な選択肢です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。
「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、通勤時間に読めるメルマガを配信しています。
最新のAI情報を日本最速で受け取りたい方は、以下からご登録ください。
また、弊社紹介資料もご用意しておりますので、併せてご確認ください。
- ※1:xAI「コレクション」

