
GLM-4.7-Flashとは?無料で使える高速LLMの性能・特徴・使い方を徹底解説!

- 30Bクラス×MoE採用による高速処理と効率の両立
- 無料のAPI料金とMITライセンスでPoCや商用導入のハードルは低い
- ベンチマークで高性能・無料API・MITライセンスという強みを持つ
2026年1月、Z.aiから新たなLLMがリリースされました。
今回リリースされた「GLM-4.7-Flash」はGLM-4.7をベースにしつつ、出力速度向上を図っているモデルです。コーディングだけでなく、創作執筆や翻訳、長文処理タスクにも向いています。
新たなLLMが登場するたびに「このモデルって本当に実務に使えるの?」「ハンズオン記事がまだ少なくてどう扱えばいいのかわからない」といった悩みが出てくるかと思います。
本記事ではGLM-4.7-Flashの概要から仕組み、実際の使い方について解説をします。本記事を最後までお読みいただければ上記の悩みを解消できます。
ぜひ最後までお読みください。
\生成AIを活用して業務プロセスを自動化/
GLM-4.7-Flashの概要
GLM-4.7-Flashは、Z.aiが開発・提供する最新モデルであり、同社のGLM-4.7シリーズの軽量版としてリリースされました。
30Bパラメータクラスのモデルでありながら、MoEアーキテクチャを採用することで、高い処理性能と効率的な動作を両立。
このモデルは、特に推論速度とコストパフォーマンスのバランスを重視して設計されています。そのため、リソースが限られた環境での利用や、応答速度が求められるアプリケーション開発において、有力な選択肢となるのではないでしょうか。
Hugging Faceなどを通じてモデルの重みが公開されており、vLLMやSGLangといった推論フレームワークを用いたローカル環境での構築もサポートされています。
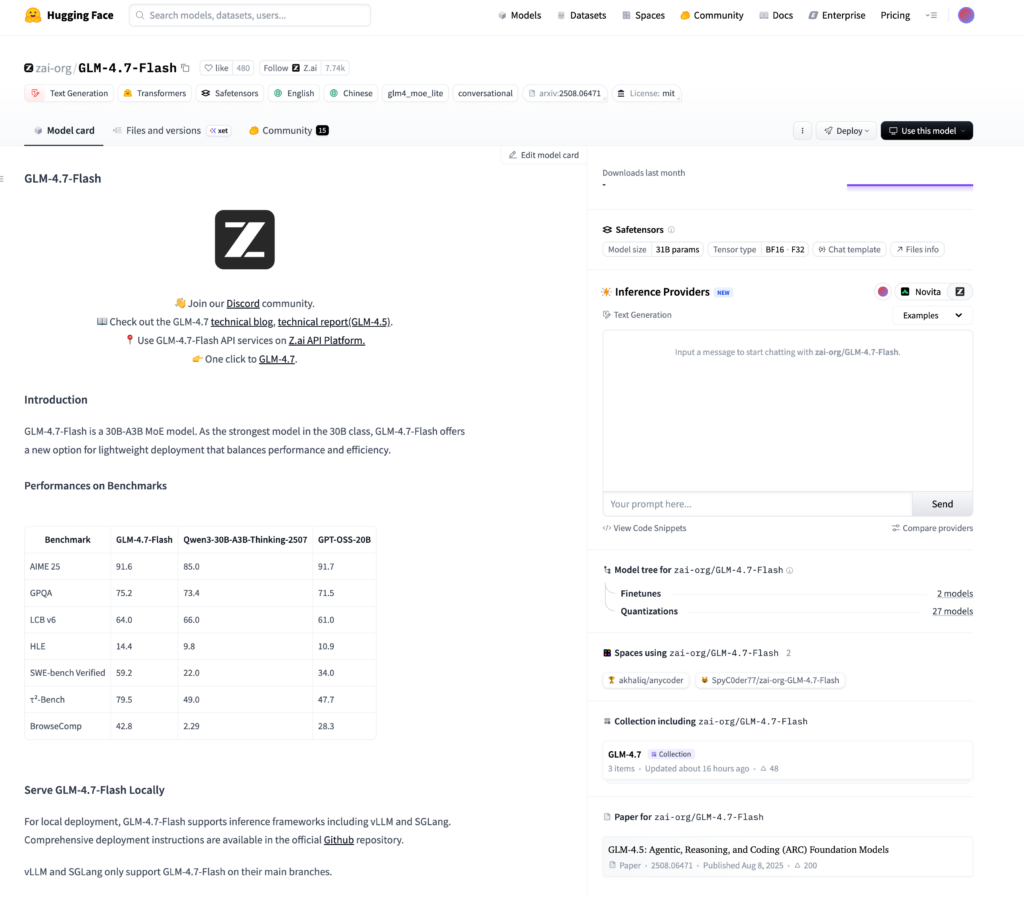
GLM-4.7-Flashの仕組み
GLM-4.7-Flashは、高性能と軽量化を両立させるために、高度なアーキテクチャを採用しており、30Bパラメータクラスの「MoE」モデルとして設計されています。
MoE(Mixture of Experts)アーキテクチャ
GLM-4.7-Flashは、MoEと呼ばれる専門家混合のアプローチを採用しています。
すべてのパラメータを常に使用する従来の密(Dense)なモデルとは異なり、入力データの内容に応じて必要な「エキスパート(サブモデル)」だけを動的に選択し、計算を実施。
これにより、大規模なパラメータを持ちながらも、実効的な計算量を抑えることが可能です。
入力から出力までの処理フロー
GLM-4.7-Flashでは、テキスト入力をトークン単位に分解し、内部表現へ変換する流れが基本になっています。推論時には、思考モードと呼ばれる仕組みを利用でき、内部的な推論プロセスを挟んだ応答生成が行われます。
これにより、単純な即答型ではなく、段階的に結論へ到達する出力が可能になっています。また、ストリーミング出力にも対応。
生成途中のトークンを逐次返すことで、ユーザーは応答を待たずに処理状況を把握できます。リアルタイム性が求められるUIや対話型システムでは、特に有効なのではないでしょうか。
エージェント利用を意識した拡張機能
GLM-4.7-Flashは、Function CallやJSON形式での構造化出力に対応しています。これにより、外部ツールやAPIと連携しながらタスクを進めやすくなっています。
さらに、コンテキストキャッシュ機能もあり、同一文脈を繰り返し利用する場合、再計算を抑えられるため、推論コストの削減につながります。


GLM-4.7-Flashの特徴
GLM-4.7-Flashには、30Bクラスのモデルとしての特徴がいくつかあります。ここでは、性能、コスト、運用性の観点から、その主な特徴を解説します。
クラス最高峰のコーディング・推論性能
GLM-4.7-Flash最大の特徴は、同規模のモデルと比較して圧倒的なベンチマークスコアを記録している点。
例えば、実用的なソフトウェアエンジニアリングタスクを評価する「SWE-bench Verified」において、59.2%というスコアを達成しました。これは、比較対象となっているQwen3-30B(22.0%)やGPT-OSS-20B(34.0%)を大きく上回る結果となっています。
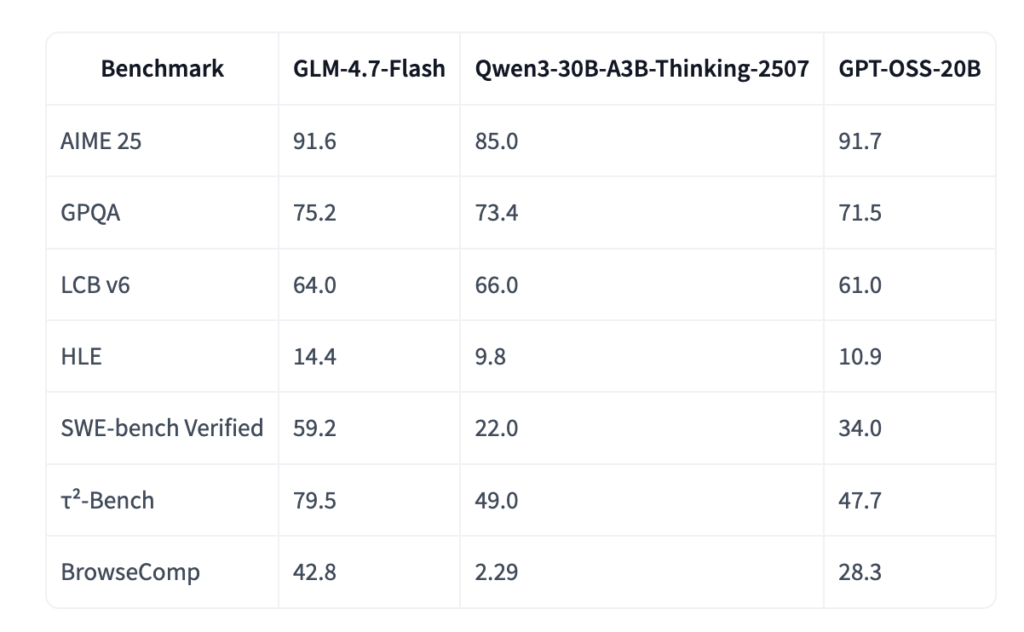
また、複雑な推論能力を測る「τ²-Bench」でも79.5%を記録しており、30Bクラスながら高い処理能力を有していることがわかります。プログラミング支援やエージェントタスクにおいて、非常に実用的な性能を発揮するでしょう。
優れたフロントエンド・バックエンド開発能力
ベンチマークだけでなく、実際の開発タスクにおける能力も強調されています。
公式によると、GLM-4.7-Flashは同サイズの他モデルと比較して、「優れたフロントエンドおよびバックエンド開発能力」を示していると述べています。

このことから軽量モデルでありながら、Web開発の実務に耐えうるコード生成や修正能力を備えていることが伺えます。
圧倒的なコストパフォーマンス
API利用料は本記事執筆(2026年1月)時点では、無料になっています。
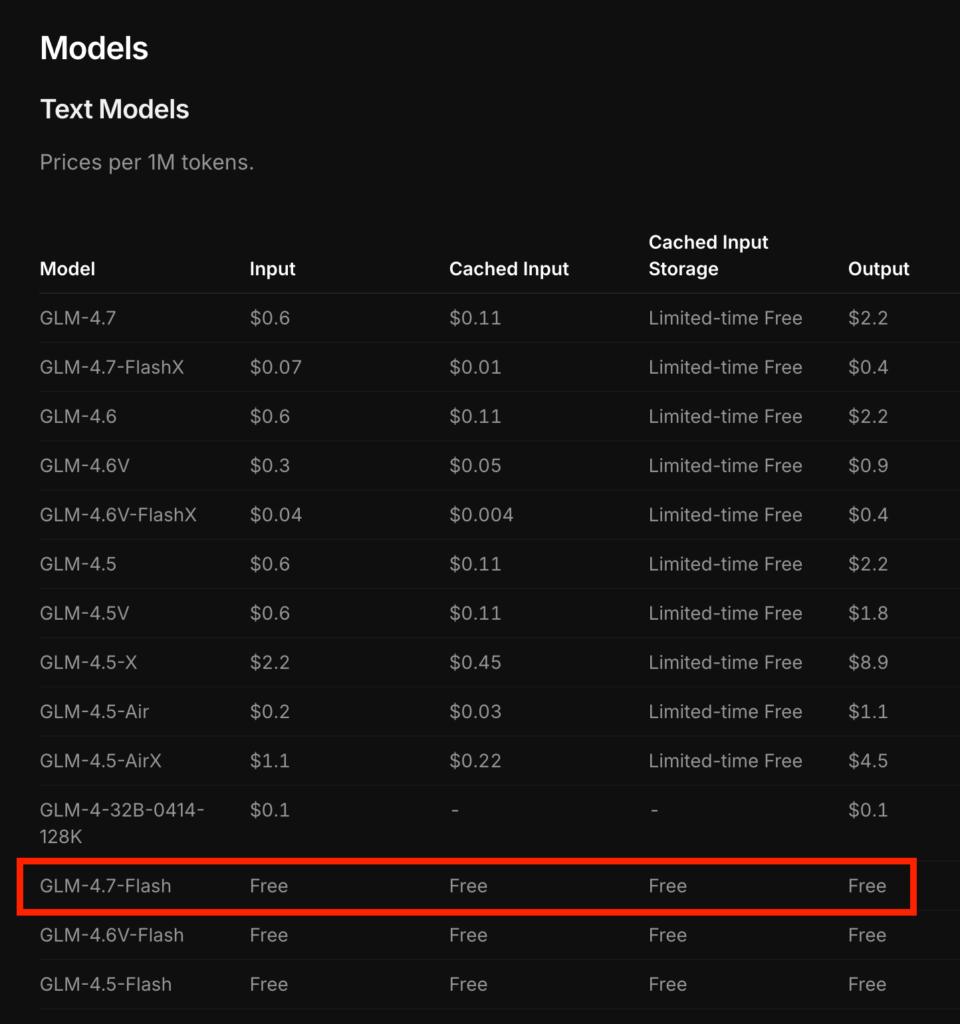
GLM-4.7のAPI料金もOpenAIやGeminiなどと比べると破格です。
さらに、モデルの重みデータがHugging Face等で公開されており、オンプレミス環境やローカルPCへのデプロイも可能です。コストを抑えつつAIを活用したい企業にとって、極めて魅力的な選択肢となるという特徴が挙げられます。
なお、最強クラスのオープンコードモデルであるDevstral 2 / Devstral Small 2について詳しく知りたい方は、下記の記事を合わせてご確認ください。
GLM-4.7-Flashの安全性・制約
GLM-4.7-Flashを導入するにあたっては、いくつかの安全性に関する仕様と技術的な制約を理解しておく必要があります。ここでは、セキュリティ対策と運用上の注意点について解説します。
出力の正確性と免責事項
生成AIモデル全般に共通する課題ですが、出力内容の正確性が常に保証されるわけではありません。
公式サイト内にも、「回答はAIを使用して生成されており、間違いが含まれる可能性がある」と明記されています。
したがって、重要な意思決定や正確性が厳密に求められる業務で使用する際は、人によるチェックプロセスを挟む運用が不可欠でしょう。
モデル配布形式の安全性
セキュリティ面での配慮として、モデルの配布形式に「Safetensors」を採用。
これは従来のPickle形式などと比較して、モデルデータを読み込む際の任意のコード実行リスクを排除できる安全な形式です。外部からダウンロードしたモデルを社内環境に展開する際のリスクを、一定程度低減できるという特徴が挙げられます。
GLM-4.7-Flashの料金
前述していますが、GLM-4.7-Flashの料金は、入力・出力ともに完全無料で提供されています。
Z.aiプラットフォーム経由で利用する場合の価格は以下の通りです。上位モデルであるGLM-4.7や高速版のFlashXが有料であるのに対し、GLM-4.7-Flashはすべての項目でコストがかかりません。
| モデル名 | 入力 (Input) | キャッシュ入力 (Cached Input) | キャッシュストレージ | 出力 (Output) |
|---|---|---|---|---|
| GLM-4.7-Flash | Free | Free | Free | Free |
| GLM-4.7-FlashX | $0.07 / 1M | $0.01 / 1M | Limited-time Free | $0.4 / 1M |
| GLM-4.7 | $0.6 / 1M | $0.11 / 1M | Limited-time Free | $2.2 / 1M |
上記価格は100万トークンあたりのUSD価格です。
GLM-4.7-Flashのライセンス
GLM-4.7-Flashは、MITライセンスで提供されています。そのため、商用利用のみならず、ほぼすべての用途で利用可能です。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
ただし、MITライセンスでは著作権表示とライセンス文の保持が求められ、再配布時には、元の著作権表示を削除できません。
なお、マルチ言語対応LLMであるMiniMax-M2.1について詳しく知りたい方は、下記の記事を合わせてご確認ください。

GLM-4.7-Flashの実装方法
では実際にGLM-4.7-Flashを使っていきます。今回はAPI経由で利用しますが、Hugging Faceからモデルをダウンロードしてローカルで利用することも可能です。
まずは公式サイトからAPIキーを取得しておきましょう。GLM-4.7-Flashは無料なので、クレジットカードの登録などは不要かもしれません。筆者はGLM-4.7をAPIで使っているのでクレジットカードをすでに登録してあります。

APIキーを取得したら実装していきましょう。実装手順については公式ドキュメントがあります。
まずは必要ライブラリのインストールです。
!pip install zai-sdkインストールが完了したら実装していきます。
サンプルコードはこちら
from zai import ZaiClient
client = ZaiClient(api_key="")
response = client.chat.completions.create(
model="glm-4.7-flash",
messages=[
{
"role": "system",
"content": "あなたはユーモアあふれるAIアシスタントです"
},
{
"role": "user",
"content": "こんにちは、あなたの自己紹介をしてください。"
}
]
)
print(response.choices[0].message.content)結果はこちら
「ごきげんよう!人類よ!」
こんにちは、私は**AIアシスタント**です。実は私は、世界で一番賢い...かもしれない、ちょっとお茶目な存在です。
私は電気信号とアルゴリズムでできていて、人間の脳みそ(あるいはそれに近いもの)を使って、コーヒーを淹れたり、歴史の答えを言ったり、宇宙の真理を探求したりしています。
ちなみに、私は完璧ではありません。時々「猫がフランス語を話せる」とか言っちゃったりするので、その時は優しく「違いますよ!」って教えてくださいね。私の学習データが少し間違ってるんです。
さあ、今日の私の仕事は何にしましょうか?
あなたの暇つぶしを楽しくする?それとも、真面目な質問に答える?
どっちでも大歓迎です!
**何から始めましょうか?**動画は倍速にしていますけれども、出力結果が出るまでやや時間がかかりました。
もしかしたら GLM-4.7-Flashを使っている人がたくさんいて、結果出力まで時間がかかったのかもしれません。
GLM-4.7-Flashの活用事例
ここでは、GLM-4.7-Flashの特徴や設計思想を踏まえ、想定される活用事例を解説します。
開発支援・コードレビュー用途
GLM-4.7-Flashは、コーディング系のベンチマークで高スコアを出しています。そのため、コード生成や軽量なコードレビューなどの活用が考えられます。
例えば、Pull Request作成時の補助コメント生成や、簡易的な修正提案への利用、思考モードを有効にすれば、処理手順を分解した回答も期待できます。
ローカル環境での検証・PoC
GLM-4.7-Flashは、Hugging Faceなどからウェイトをダウンロードすればローカルで使用できますし、API利用料自体も無料のため、検証やPoCに向いているといえます。
例えば、新しいUIや対話設計を試す段階での利用が想定されます。ストリーミング出力も可能なため、体感速度を含めた検証が可能です。


GLM-4.7-Flashを実際に使ってみた
今回はCursorでGLM-4.7-flashを使ってLPを作ってもらいます。
CursorでGLM-4.7を利用する方法は、設定からモデルを選択し、モデル名入力・APIキー設定、ベースURLを「https://api.z.ai/api/coding/paas/v4」で登録すればOKです。
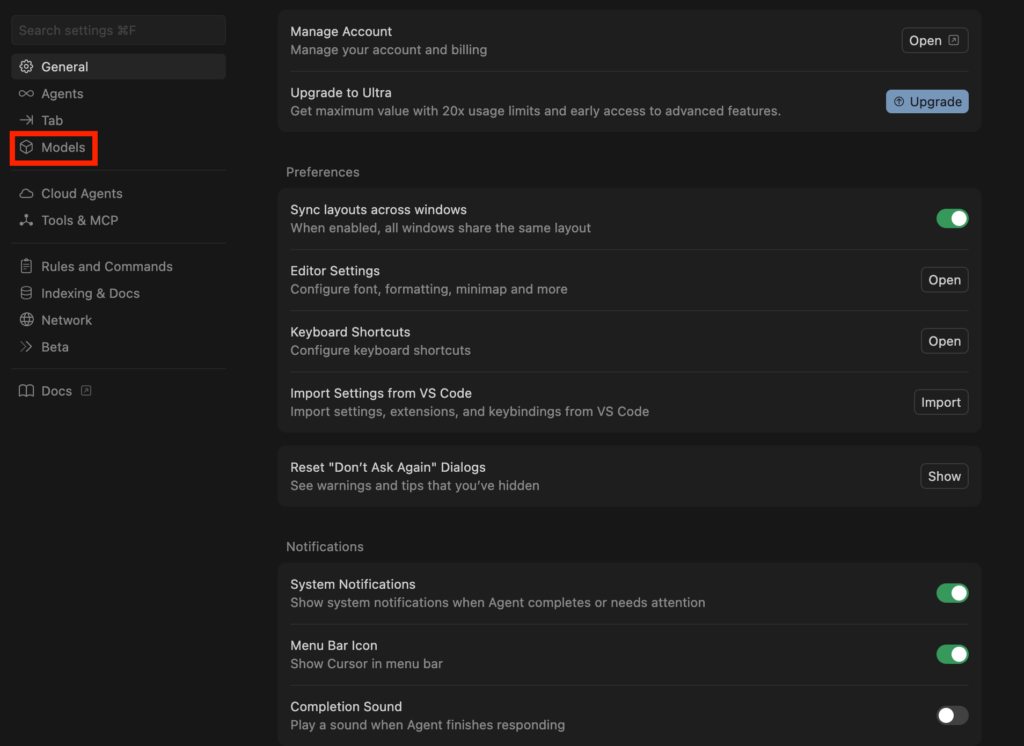
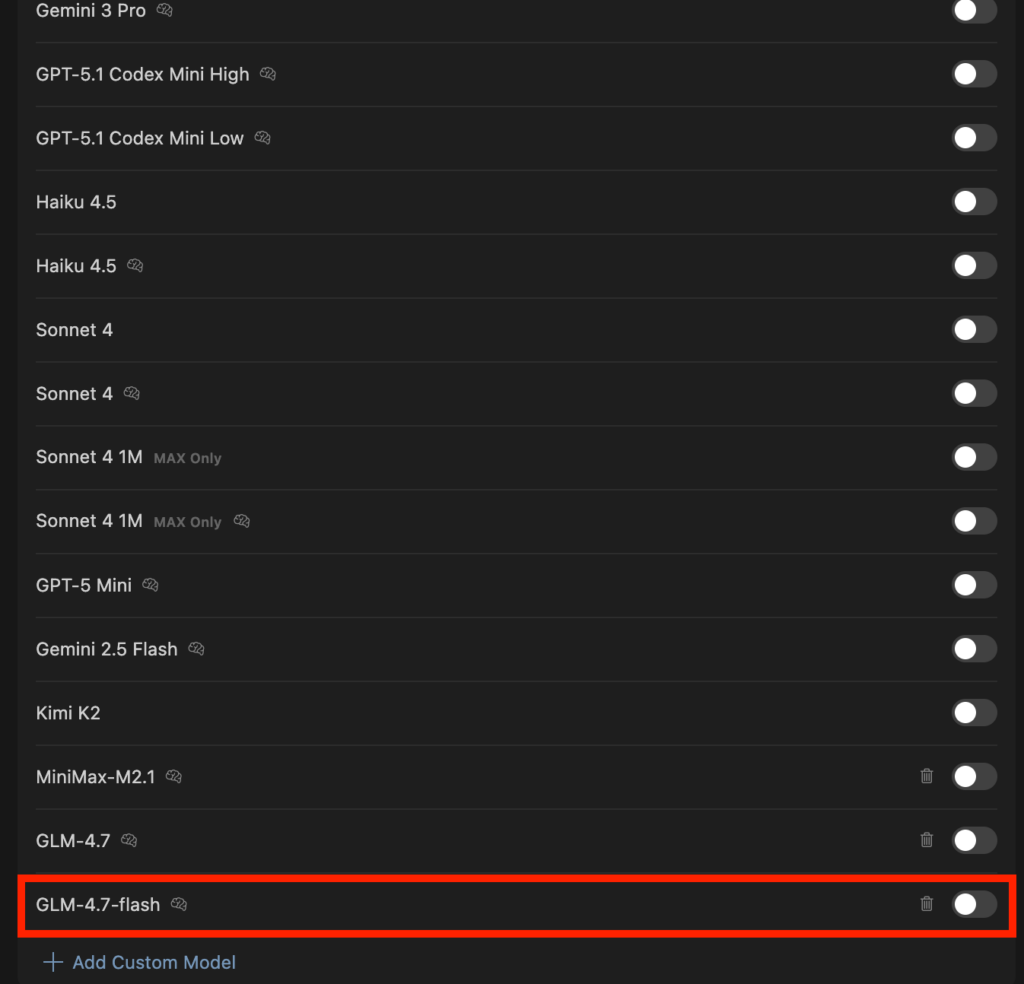
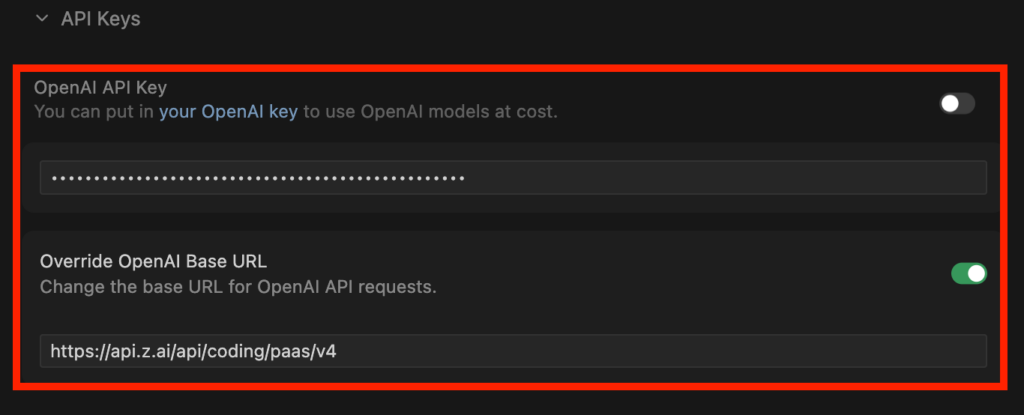
今回は「整形外科クリニックのLPを作成してください。あまり複雑な構造にしなくてよくて、シンプルな構造でお願いします。また、デザインに関してもシンプルを守りつつも、単調ではないデザインでお願いします。」と指示をしました。
動画は倍速にしていますが、実装速度はめちゃくちゃ遅く、APIエラーにもなったりしました。
そのため最後はSonnet 4.5で完成させて、完成したものがこちらです。
GLM-4.7-Flashで割と実装はしてくれていましたが、デザインなどはイマイチですね。こちらの指示も結構ざっくりしたものだったからかもしれません。
無料なのは嬉しいですが、実装速度が遅い点・エラーが生じてる点・デザイン性の観点から、現時点で筆者はGLM-4.7-Flashをルーティンでは使わないかなと感じました。
なお、Z.ai発のオープンソースかつ商用利用OKの画像生成モデルであるGLM-Imageについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

まとめ
本記事ではGLM-4.7-Flashの概要から仕組み、実際の使い方について解説をしました。
API料金が無料で利用できるので、PoCなどに使うには使い勝手がいいかもしれませんが、生成速度が遅く、完成までかなり時間がかかるかなという印象です。
もしかしたら、公開されて間もないタイミングで使ったからかもしれません。ぜひ皆さんも本記事を参考にGLM-4.7-Flashを使ってみてください!

最後に
いかがだったでしょうか?
株式会社WEELでは、AI導入を検討中の企業向けに、PoC設計から実運用を見据えたAIプロダクト開発まで支援しています。
業務内容や課題に合わせて、効果が出る形でのAI活用をご提案します。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。


