
HunyuanImage 3.0-Instructとは?Tencentの指示追従性の高い画像生成AIを徹底解説

- Tencent発の80億パラメータ級の最新画像生成モデル
- HunyuanImage 3.0を基盤モデルとし、インストラクション(指示)学習を加えたバージョンで、画像編集や複数画像の融合など高度な処理が可能
- ユーザーの指示を深く理解して、最適な画像を生成する能力を備える
2026年1月26日、Tencentは80億パラメータ級の最新画像生成モデル「HunyuanImage 3.0-Instruct」を公開しました!
基礎モデルとしてHunyuanImage 3.0をベースに、インストラクション(指示)学習を加えたバージョンで、画像編集や複数画像の融合など高度な処理が可能です。
本モデルは、画像編集と複数画像融合に対応しており、ユーザーの指示を深く理解して、最適な画像を生成する能力を備えているようです。
オープンソースで公開されていて、誰でもダウンロードして利用可能であり、強力な視覚理解と高品質な画像生成による新たなクリエイティブ手段として注目が集まっています。
そこで本記事では、HunyuanImage 3.0-Instructの性能やライセンス情報、使い方まで徹底的に解説します。
ぜひ最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
HunyuanImage 3.0-Instructの概要

HunyuanImage 3.0-Instructは、ネイティブなマルチモーダル・アーキテクチャを採用し、テキスト理解と画像生成を統合した自己回帰モデルです。
80億個のパラメータを持つ巨大モデルですが、Mixture-of-Experts(MoE)を用いていて、トークンごとに約13億個のパラメータだけが活性化される仕組みになっています。
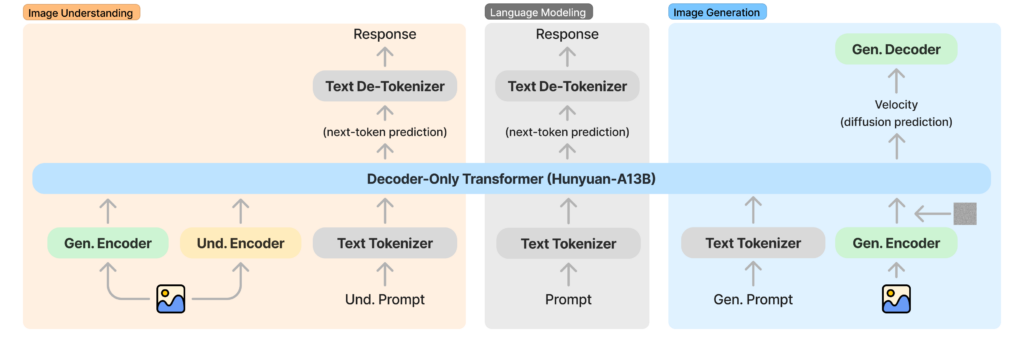
64人の専門家が協力するようなイメージで、モデル全体としては、膨大な知識量と表現力を実現しています。学習には膨大な画像・テキストデータが用いられ、最適化後には「優れたセマンティックな整合性とフォトリアリスティックな画像品質」を両立しています。
特に、プロンプトへの忠実性が高く、詳細な指示でも期待通りの結果を得られる点が特徴です。
また、本モデルは、中国語と英語の両言語でテキストを高精度に画像化できる点も強みで、1,000文字以上の長文プロンプトにも対応しています。
さらに、HunyuanImage 3.0-Instructは、世界知識に基づく推論能力を備えていて、ユーザーの曖昧な指示に対して文脈を補完して理解し、より完全な画像を生成してくれます。


HunyuanImage 3.0-Instructの性能
HunyuanImage 3.0-InstructおよびベースモデルであるHunyuanImage 3.0の性能は、既存モデルを上回る結果が報告されています。
先行するクローズドソースの最先端モデルにも匹敵あるいは優る性能を持つと公式GitHubでも言及されていて、厳しい評価実験でも高評価を得ています。
例えば、LM Arenaのユーザー評価ランキングでは、本モデルは1,152点で第8位に達し、コミュニティから高い評価を受けています。
生成画像の品質においても、Tensor公式レポートでは「意味論的精度と視覚的完成度のバランスが最適化され、プロンプトへの忠実度が非常に高い」と評価されています。
さらに、世界知識の文脈を利用できる点が質的なアドバンテージとなっていて、専門家による評価では、本モデルが複雑なシーンや長文指示でも詳細を正確に捉えられることが報告されています。
なお、同じく中国発の画像生成AI「GLM-Image」について詳しく知りたい方は、以下の記事も参考にしてみてください。

HunyuanImage 3.0-Instructのライセンス
HunyuanImage 3.0-Instructは「Tencent Hunyuan Community License Agreement」のもとで公開されています。
ライセンスの下では、個人・企業問わず、モデルの利用、複製、頒布、改変が自由に認められており、商用利用や派生プロジェクトの開発も許可されています。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
\画像生成AIを商用利用する際はライセンスを確認しましょう/

HunyuanImage 3.0-Instructの料金
HunyuanImage 3.0-Instruct自体はオープンソースモデルであり、モデルのダウンロードやコードは無料で提供されています。
モデルを利用して画像を生成することもライセンスに沿う限り無料ですが、高度な推論には、強力なGPUや計算資源が必要となります。
一方、Tencentの「元宝(Yuanbao)」など、クラウドサービス経由で本モデルを利用する場合は、従量課金制で料金が発生する可能性があります。
2026年1月27日時点では、正式なAPI価格は公表されていませんが、一般的にはトークン消費量や計算時間に応じた利用料を想定しておくと良いでしょう。
なお、Tencent発の動画生成AI「HunyuanVideo」について詳しく知りたい方は、以下の記事も参考にしてみてください。

HunyuanImage 3.0-Instructの使い方
HunyuanImage 3.0-Instructの利用方法は、①公式Webチャット、②Hugging Faceからのモデルダウンロードの2通りがあります。
①公式Webチャット
公式チャットページを開き、未ログインの場合は画面の案内に沿ってログインします。ログイン後、画面上で選択されているモデルが既にHunyuan-Image-3.0-Instructになっているかと思います。
次に、チャットの入力欄に「生成したい画像の指示」をそのまま文章で入力することで生成ができます。
画像編集をしたい場合は、チャット入力欄左下の画像追加(アップロード)から編集したい画像を1枚入れ、続けて「この写真の背景を夜の街に変更して、人物の顔は変えないでください」のように、変える点/変えない点を明記して送信します。
②Hugging Faceからのモデルダウンロード
2026年1月27日時点で、公式GitHub上にHugging Faceへのリンクが表示されていますが、実際にはアクセスができない状態となっています。

モデル名およびモデルIDが、HunyuanImage-3.0-Instruct になる可能性はありますが、基本的な手順は以下の通りになります。
Hugging Faceからモデルデータを取得します。
hf download tencent/HunyuanImage-3.0 --local-dir ./HunyuanImage-3モデルをダウンロードできたら、Transformersライブラリを用いてモデルを読み込み、プロンプトから画像を生成します。以下はコード例です。
from transformers import AutoModelForCausalLM
model_id = "./HunyuanImage-3"
kwargs = dict(
attn_implementation="sdpa",
trust_remote_code=True,
torch_dtype="auto",
device_map="auto",
moe_impl="eager",
)
model = AutoModelForCausalLM.from_pretrained(model_id, **kwargs)
model.load_tokenizer(model_id)
prompt = "A brown and white dog is running on the grass"
image = model.generate_image(prompt=prompt, stream=True)
image.save("output.png")以上、2通りの利用方法の紹介でした。
HunyuanImage 3.0-Instructを使ってみた
それでは実際に、HunyuanImage 3.0-Instructを公式Webチャットページで試していきます。
大前提として、画像を添付せず、テキストプロンプトだけでの画像生成は試すことができませんでした。なので、今回はテキスト+画像を入力とすることとします。
デザインを崩さず、HunyuanImage 3.0-Instructに修正してください。入力画像はこちら

出力結果はこちら

元画像のテイストは踏襲しながら、テキストとデザインを修正してくれました。もう少しプロンプトを工夫したり、何度かやり取りすればより良い画像に仕上げられそうです。
続いて、Nano Banana Proで生成した架空の人物の画像を入力として使用します。
この画像の人物の顔・髪型・服は一切変えずに、背景だけを『朝の窓辺のカフェ』に変更してください。
光は左からの自然光で、肌の色はそのまま。背景に文字やロゴは入れない。
編集したことがわからない自然な合成にしてください。入力画像はこちら

出力結果はこちら

意図通りに自然な画像編集をしてくれました。自然光のあたり具合がリアルで良い感じですね。
他にも複数画像の融合にも適したモデルなので、気になる方は試してみてください!


まとめ
TencentのHunyuanImage 3.0-Instructは、現時点で最も先進的なオープンソース画像生成モデルの1つです。
80億パラメータの大規模なMoEアーキテクチャにより、従来モデルを超える高品質な画像生成と柔軟な編集能力を実現しています。商用利用や改変もライセンス上許可されているため、企業・研究問わず活用の幅が広い点も特長です。
気になる方は、ぜひ一度試してみてください!

最後に
いかがだったでしょうか?
弊社では、AI導入を検討中の企業向けに、業務効率化や新しい価値創出を支援する情報提供・導入支援を行っています。最新のAIを活用し、効率的な業務改善や高度な分析が可能です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。


