
LFM2.5とは?Liquid AIが公開したオンデバイス基盤モデルの特徴・性能・使い方を徹底解説

- スマートフォンやPCなど、デバイス上で直接動作することを念頭に設計された基盤モデル(Foundation Model)
- 従来モデルから、事前学習データを10兆トークンから28兆トークンへ約3倍に拡大
- 強化学習手法も刷新したことで、品質・性能とも飛躍的に向上
2026年1月6日、MIT発のスタートアップであるLiquid AI社が、次世代のオンデバイスAIモデルファミリー「LFM2.5」を発表しました!
LFM2.5は、スマートフォンやPCなど、デバイス上で直接動作することを念頭に設計された基盤モデル(Foundation Model)で、インターネットに接続せずとも、高度なAI機能を利用できる点が大きな特徴です。
前世代モデル(LFM2)から、事前学習データを10兆トークンから28兆トークンへ約3倍に拡大し、強化学習手法も刷新したことで、品質・性能とも飛躍的に向上しているとのこと。
そこで本記事では、このLFM2.5の概要や性能、ライセンス、使い方について詳しく解説します。
ぜひ最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
LFM2.5の概要
LFM2.5は、Liquid AIが開発した小型高効率のAIモデル群です。
パラメータ数は、約12億(1.2B)と比較的小さいにもかかわらず、はるかに大規模なモデルに匹敵する高性能を発揮するよう最適化されています。
本モデルは、初めからオンデバイスでの動作を想定して設計されていて、従来の巨大モデルを単に縮小したものではなく、デバイス上で効率的に動作する独自アーキテクチャ「Liquid時間定数ネットワーク(Liquid Time-Constant Networks)」を採用しています。
その結果、処理の高速化やメモリ節約に優れ、エッジデバイス上でリアルタイムに近い応答を実現しています。
今回、LFM2.5ファミリーとして、用途別に以下のモデルが同時公開されました。
| モデル | 用途 |
|---|---|
| ベースモデル (Base) | あらゆるタスクの土台となる事前学習済みモデル |
| インストラクション対応モデル (Instruct) | ユーザー指示に従って応答できるよう指示追従に最適化されたモデル |
| 日本語特化モデル (JP) | 日本語のチャットやQAに最適化されたモデル |
| ビジョンと言語の複合モデル (VL) | 画像とテキストのマルチモーダルに対応したモデル |
| 音声言語モデル (Audio) | 音声入力・出力に対応したモデル(音声合成や音声認識を含む) |
これらすべてのモデルがオープンアクセスで提供され、Hugging Face上で重量データ(ウェイト)が公開されています。


LFM2.5の性能
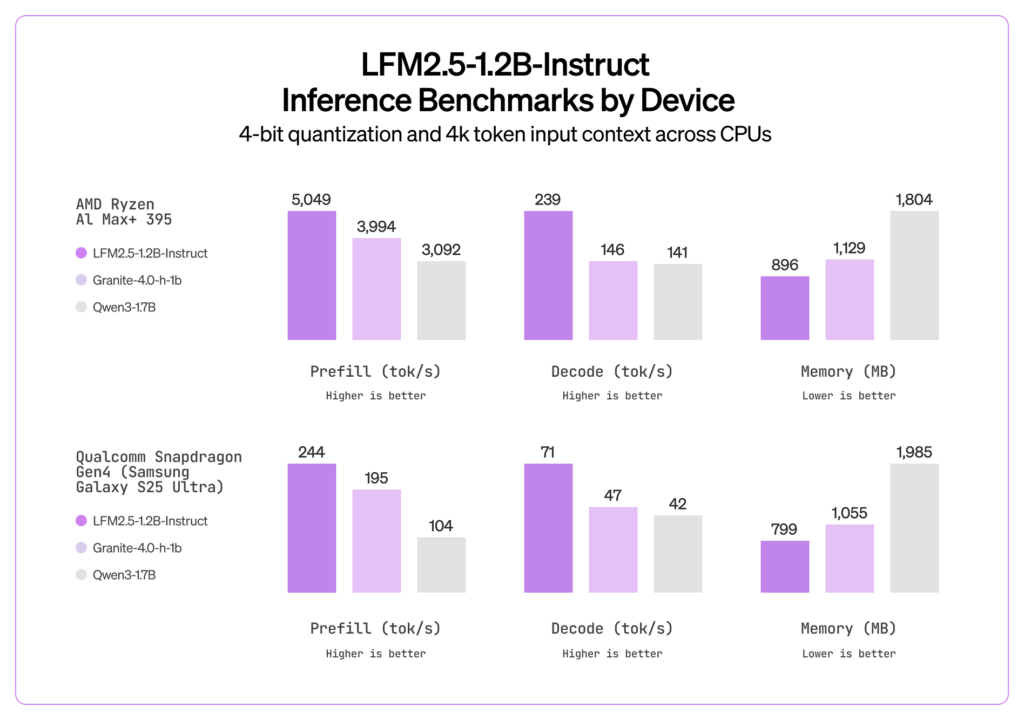
LFM2.5-1.2B(約12億パラメータのモデル)は、そのコンパクトさからは想像できないほど高い知能性能を誇っています。
様々なベンチマークで、従来モデルや競合の小型モデルを上回っていて、例えば、ユーザー指示への応答精度を測るIFEvalという指標では、86%というスコアを記録しました。
これは、約30%大きい競合モデルQwen3-1.7Bの74%を大きく超える値です。
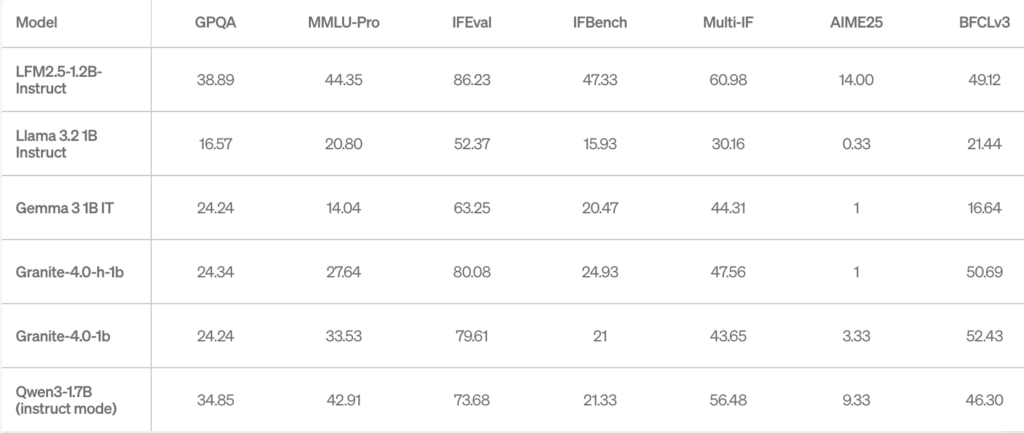
また、多岐にわたる知識問題を含むMMLU-Proベンチマークでも44.3%と、Qwen3-1.7Bの42.9%を上回りました。
モデル規模が小さいにもかかわらず、同等以上の成績を収めている点から、LFM2.5の凄さが分かりますね。
LFM2.5のもう1つの大きな強みは、推論速度と省メモリ性能です。
約1GB未満のメモリで動作し、エッジデバイス上で非常に高速に実行できます。例えば、最新のスマートフォンCPU上でテキスト生成を行った場合、1秒間に約70トークン前後を生成可能で、同条件でのQwen3-1.7B(約40トークン/秒)に比べてほぼ2倍近い速度が確認されているそうです。
なお、Qwen3について詳しく知りたい方は、以下の記事も参考にしてみてください。

LFM2.5のライセンス
LFM2.5のモデルはオープンに提供されていますが、その利用には、Liquid AI独自の「LFM Open License v1.0」が適用されています。
このライセンスは、Apache 2.0ライセンスをベースに一部条件を加えたもので、基本的にモデルや派生モデルの使用・改変・再配布を無償で許可しつつ、特定の場合に、商用利用の制限を設けた内容になっています。
| 利用用途 | 可否 | 備考 |
|---|---|---|
| 商用利用 | ⭕️ | ・年間収益1,000万ドル未満の企業は無料で商用利用可能 ・それ以上の場合は別途Liquid AIとの商用ライセンス契約が必要 |
| 改変 | ⭕️ | |
| 配布 | ⭕️ | ・再配布時は元の著作権表示およびライセンス文を保持し、変更点の告知が必要 |
| 特許使用 | ⭕️ | |
| 私的使用 | ⭕️ |
LFM2.5の料金
LFM2.5モデルの利用そのものは無料です。
Liquid AIは、開発者向けに提供するプラットフォーム「LEAP」において、モデル検索やダウンロード、微調整(ファインチューニング)機能、デプロイ支援ツールなど、主要なサービスを無償で開放しています。
これは、個人開発者から企業まで、誰でもコア機能にアクセスできるものとなっています。
一方で、大規模な導入や高度なサポートが必要な企業向けにはエンタープライズ向けの有償プランも用意されています。
LFM2.5の使い方
LFM2.5の主な使い方としては、①スマートフォンでの利用、②PCでの利用、の2通りがあります。
①スマートフォンでの利用
1番かんたんなのは、Liquid AI公式のモバイルアプリ「Apollo」を使う方法です。
ApolloはiPhoneやアンドロイド端末で、LFMs(Liquid Foundation Models)を直接実行できる軽量アプリで、公式サイトの「Download Apolio」から無料でダウンロードできます。
インストールしたらアプリを起動し、使用するモデルとして最新のLFM2.5を選択します。
例えば、LFM2.5-1.2B-JP(日本語モデル)を選べば、日本語で質問を入力するだけで即座に回答が得られます。
使い方はシンプルで、チャットアプリのようにテキストを送信するだけです。インターネットに接続しなくても、端末内で完結してAIが応答してくれます。
なお、Apollo上では音声入力や音声読み上げにも対応しており、マイクアイコンをタップして話しかければ音声認識で質問ができて、モデルによる回答は、テキスト表示だけでなく音声でも返ってきます(端末のスピーカーから回答を読み上げてくれます)
②PCでの利用
Hugging FaceのモデルページからLFM2.5の重みデータを取得し、自分の環境で実行することもできます。
例えばPython+PyTorch環境があれば、Hugging FaceのTransformersライブラリを使って、以下のようにモデルをロードできます。
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "LiquidAI/LFM2.5-1.2B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", dtype="bfloat16")上記コードでモデルとトークナイザを読み込み、model.generate()メソッドでテキスト生成が可能です。
1.2Bモデルとはいえ、推論にはそれなりのメモリが必要なので、高性能なGPUまたはメモリ16GB以上のマシンで実行するのが望ましいかと思います。
Hugging Face上では、モデルの量子化版(4ビット圧縮したGGUF形式)も公開されていて、これを使えば、llama.cppというツールでCPU上でも高速に動作させることができます。
llama.cppを利用する場合は、提供されているGGUFファイルをダウンロードし、お使いのOS向けにビルドしたllama.cppからモデルをロードしてチャットを開始します。例えば以下は簡単な実行例です。
# 4-bit量子化済みのモデルを使って対話を開始
./main -m LFM2.5-1.2B-Instruct.Q4_0.gguf -c 2048 -n 256 -p "ユーザー: 今日は何をすべきかアドバイスしてください\nアシスタント:"上記コマンドをターミナルで実行すると、プロンプトに対するモデルの回答が表示されます。
その他にも、Appleシリコン向けの最適化フレームワークMLXを使ってCore ML形式に変換し、iPhoneやMac上でネイティブ動作させる方法や、ONNX形式でエクスポートして汎用的な推論エンジンで動かす方法など、用途に応じた様々な実行手段が用意されています。


LFM2.5を使ってみた
それでは実際に、スマートフォンでダウンロードしたApolioアプリ上で、LFM2.5を試してみます。
iOS端末、オフライン環境(機内モード、Wi-Fi接続なし)でモデルを実行していきます。
LFM2.5の特徴は?オフライン環境ですが、プロンプトを送信したら、すぐに回答を返してくれました。スピード感も回答の内容も問題なさそうです。
続いて長文要約もしてもらいましょう。
あなたは日本語の編集者です。以下の長文を、事実を捏造せずに読み解き、読み手が「結局なにが重要か」を一発で掴める要約にしてください。
【出力ルール】
- 日本語のみ
- 出力は次の3部構成(見出しも含めてそのまま出す)
1) 要約(450〜650文字)
2) 重要ポイント(本文の事実だけで、3つ。各120〜180文字)
3) 論点と打ち手(論点2つ+打ち手2つ。各80〜140文字)
- 本文にない数字・固有名詞・因果は書かない
- 断定が難しい箇所は「〜と述べています」の形で書く
- 表現は自然で読みやすいですます調
【長文(この下をまるごと要約してください)】
――――――――――
【サンプル長文】
本レポートは、社内の問い合わせ対応(メール・チャット・電話)の負荷増大に対して、生成AIを用いた一次対応の自動化を検討した結果をまとめたものです。対象期間は2025年4月から10月で、部門はカスタマーサポート、物流、経理の3部門です。現状の課題として、問い合わせ件数の増加だけでなく、内容が複雑化している点が挙げられます。具体的には、配送遅延に起因する個別対応、請求書の再発行、返品ルールの例外処理などが重なり、担当者が同時に複数のタスクを処理しなければならない状態が継続しています。
期間中の総問い合わせ件数は約12万件で、月平均は約2万件でした。チャネル別ではチャットが約55%、メールが約35%、電話が約10%です。電話比率は低いものの、1件あたりの平均処理時間が最も長く、対応品質のブレも大きいという指摘があります。一次回答のテンプレートは存在しますが、更新が追いついておらず、最新のキャンペーン条件や例外規定が反映されていないケースが散見されました。その結果、担当者が個別に判断し、二次確認のやり取りが増えるという悪循環が起きています。
本検討では、一次対応を「受付」「状況確認」「FAQ回答」「必要情報の収集」「担当者への引き継ぎ」に分解し、それぞれに生成AIを適用できるかを評価しました。結論として、FAQ回答と必要情報の収集は自動化の効果が大きい一方で、返金の可否判断や例外処理の最終決定は人が担うべきだとしています。特に、規約の例外を認める判断には、顧客の利用履歴や過去のトラブル、キャンペーン適用条件など複数の情報を踏まえる必要があるため、誤判定のコストが高いという理由です。
プロトタイプは、ナレッジベース(社内規程・FAQ・手順書)を参照して回答を生成する方式を採用しました。回答の根拠となる文書の参照箇所を提示することで、担当者が確認しやすい形にしています。評価は、過去ログから抽出した1,000件の問い合わせで行い、正答率(想定する正しい回答に一致する割合)と、必要情報の回収率(引き継ぎに必要な項目が揃う割合)を測定しました。その結果、FAQ回答の正答率は83%で、必要情報の回収率は91%でした。一方で、返品・返金の境界にある問い合わせでは正答率が68%まで落ち、言い回しが強い顧客に対して過剰に譲歩する回答を出すケースが確認されました。
運用面では、回答のトーンと免責の書き方が重要だとしています。たとえば「返金します」と断定するのではなく、「状況を確認し、条件に合致する場合に返金の手続きをご案内します」といった表現に統一する必要があります。また、個人情報(住所・電話番号・注文番号)の取り扱いがチャネルによって異なるため、入力フォームの設計で漏えいリスクを下げることも必要です。加えて、ナレッジの更新フローを整備しないと、モデルの出力が古い規程に引っ張られるという懸念も述べています。
コスト試算では、一次対応の30%を自動化できれば、月あたりの削減工数は約1,200時間と見積もっています。これは、平均処理時間6分の問い合わせが月2万件あり、そのうち30%が一次対応で完結する前提です。一方、品質担保のためのレビュー工数として、初期は自動回答の10%をサンプリングし、人がチェックする体制を想定しています。これにより、導入初期の工数削減効果は目減りするものの、学習とナレッジ整備が進めば監査率を下げられるとしています。
リスクとしては、誤回答による炎上、規約違反の案内、差別的な表現、そして不適切な個人情報の取り扱いが挙げられています。対策として、出力のガードレール(禁止表現、断定禁止、根拠提示の必須化)に加え、センシティブなカテゴリは必ず人にエスカレーションするルールを設ける方針です。最後に、本レポートは「生成AIを入れれば終わり」ではなく、「運用設計とナレッジ更新が成果を左右する」と結論づけています。
――――――――――同じくオフライン環境ですが、20秒ほどで回答がスタートし、指示した出力ルール通りに回答生成してくれました。
インターネットに接続できない状況においても、デバイスで十分実用的な回答が得られることが分かりました。
まとめ
LFM2.5は、小型でありながら高い知能と応答性能を持ち、しかもデバイス上で動作するという画期的なAIモデルファミリーです。
導入文で述べたようにLiquid AI社は「すべてのデバイスを即座に賢くする」ことを目指してこのモデルを開発していますが、実際に触れてみてその片鱗を強く実感しました。
日本語モデルが用意されていることで、日本のユーザーや開発者にとっても扱いやすく、ローカライズされたAIソリューションを作りやすくなっています。
気になる方は、ぜひ一度試してみてください!

最後に
いかがだったでしょうか?
弊社では、AI導入を検討中の企業向けに、業務効率化や新しい価値創出を支援する情報提供・導入支援を行っています。最新のAIを活用し、効率的な業務改善や高度な分析が可能です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。


