
MAI-UIとは?スマホ操作を理解・実行するGUIエージェントの仕組みと使い方を解説
- 実世界を前提にしたGUI操作設計で、単発ではなくマルチステップのタスク完遂を重視
- ask_userや外部ツール連携を前提とした柔軟なエージェント設計により、不確実な状況でも破綻しにくい構造
- 端末とクラウドの協調実行による、性能とプライバシーのバランス重視
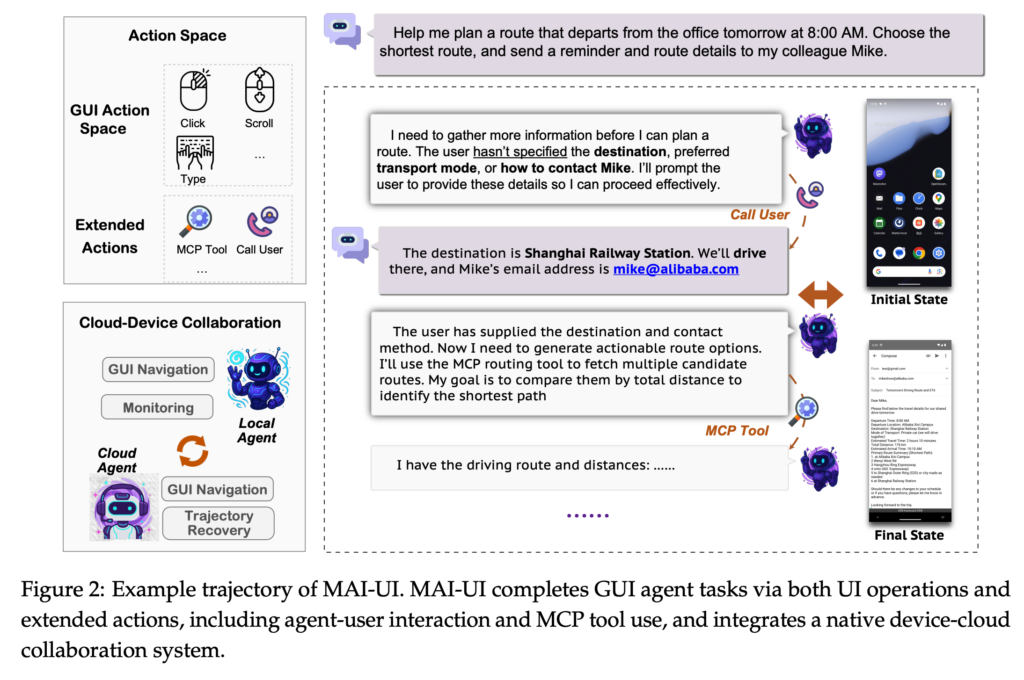
2025年12月、Alibabaから新たなAIエージェントが登場!
今回リリースされた「MAI-UI」はGUI操作が可能なAIエージェントです。ベンチマークではGemini 3 Proと比較して高い操作性能を示す結果が報告されています
本記事ではMAI-UIの概要から仕組み、実際の使い方について解説します。本記事を最後までお読みいただければ、MAI-UIの理解が深まり、ご自身で使うことが可能です。
ぜひ最後までお読みください!
\生成AIを活用して業務プロセスを自動化/
MAI-UIの概要
MAI-UIは、自然言語の指示に従ってスマホのGUI上で「見る・考える・操作する」を一体で担う、モバイル向けのFoundation GUI Agentです。GUI要素の位置特定(grounding)と、複数手順にまたがる画面操作(navigation)を主対象に据えています。
従来のGUIエージェントでは、実運用を想定したときにいくつかの壁がありました。
例えば、指示が曖昧な場面でのユーザー確認が弱いこと、UI操作だけに頼ることで手順が長くなり失敗が連鎖しやすいこと、端末内とクラウドを行き来する現実的な配置設計が不足しがちなことなどです。
MAI-UIはこれらに対して、ユーザーへの確認(ask_user)とMCPツール呼び出し(mcp_call)を含む拡張アクション、タスク状態とデータ感度に応じて端末/クラウド実行を切り替えるdevice-cloud協調、動的環境でのonline RLなどを組み合わせる方針を採用。
モデルは2B/8B/32B/235B-A22Bのサイズ展開が示されており、ハードウェア制約と性能要件に合わせて選べる形になっています。Hugging Face上ではまだ2Bと8Bのみです。
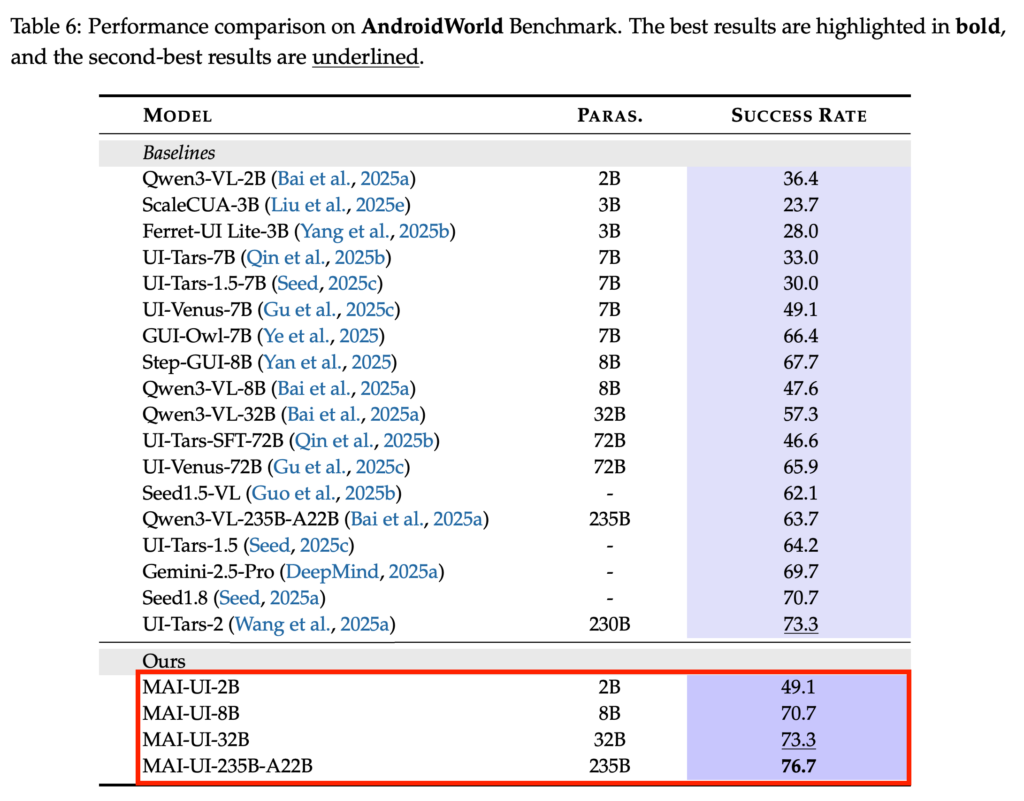
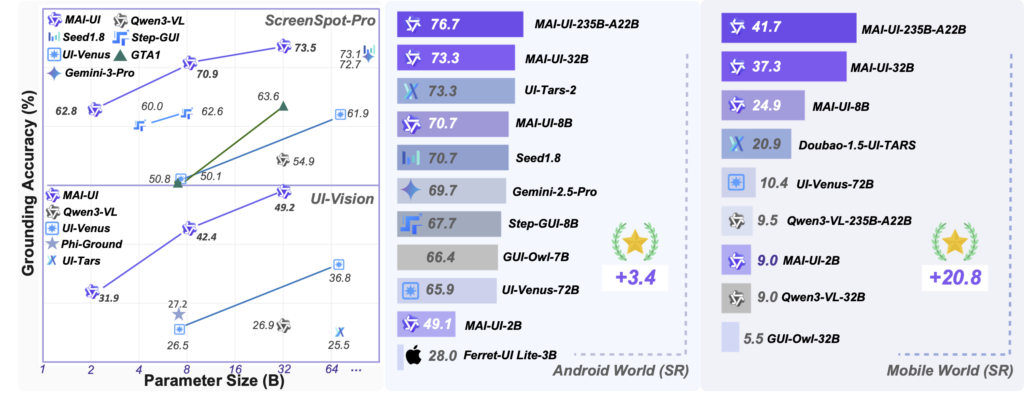
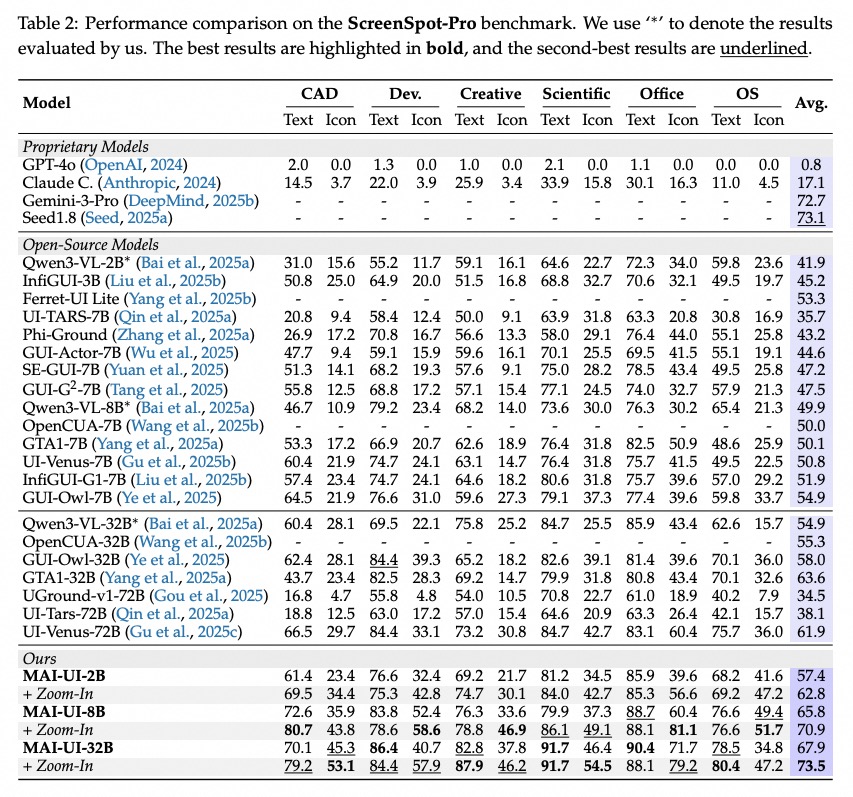
加えて、複数の評価で高いスコアが報告されており、ScreenSpot-Proで73.5%、MMBench GUI L2で91.3%、OSWorld-Gで70.9%、UI-Visionで49.2%といった性能を達成。
モバイルGUIナビゲーションでもAndroidWorldで76.7%、MobileWorldで41.7%の成功率です。
なお、ブラウザ操作を自動化する次世代エージェントモデルであるFara-7Bについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
MAI-UIの仕組み
ここでは、MAI-UIがどのように入力を理解し、実際のモバイルGUI操作へとつなげているのか、その内部構造と処理の流れを解説します。
MAI-UIは単なるUI操作自動化ではなく、「判断」と「実行」を統合している点がポイントです。
まず、MAI-UIはスクリーンショットを中心とした視覚入力と、自然言語指示を同時に扱うマルチモーダル構成を採用しています。
画面上の要素は、テキストだけでなく位置情報やレイアウト構造を含めて認識。これにより「右下の送信ボタンを押す」といった曖昧さを含む指示にも対応できる設計となっています。
処理フローは大きく三段階です。
最初に、現在の画面状態を入力としてGUI理解を行い、要素の候補と関係性を抽出。
次に、与えられたタスク目標と照合しながら、どの操作を次に行うべきかを推論します。
この段階では、過去の操作履歴やタスク進行状況も内部状態として参照されています。そして最後に、タップやスワイプ、入力といった具体的なアクションが生成され、実行へと移ります。
単発の推論ではなく、状態遷移を前提としたループ構造になっている点がポイントです。
このループを成立させるため、MAI-UIではいくつかの補助的な仕組みが組み込まれています。
判断に必要な情報が不足している場合にはask_userアクションを通じてユーザー確認を実施。
さらに、外部知識や計算が必要な場面では、MCPツール呼び出しを介して追加処理を行うことも想定されている構成です。全てをモデル内部で完結させない柔軟さが、実運用での安定性につながると考えられます。


MAI-UIの特徴
MAI-UIには、実運用を前提としたGUIエージェントとして、いくつかの特徴があります。
実世界志向のGUIグラウンディングとナビゲーション
MAI-UIの中心となるのが、実世界に近い環境を想定したGUIグラウンディング能力です。
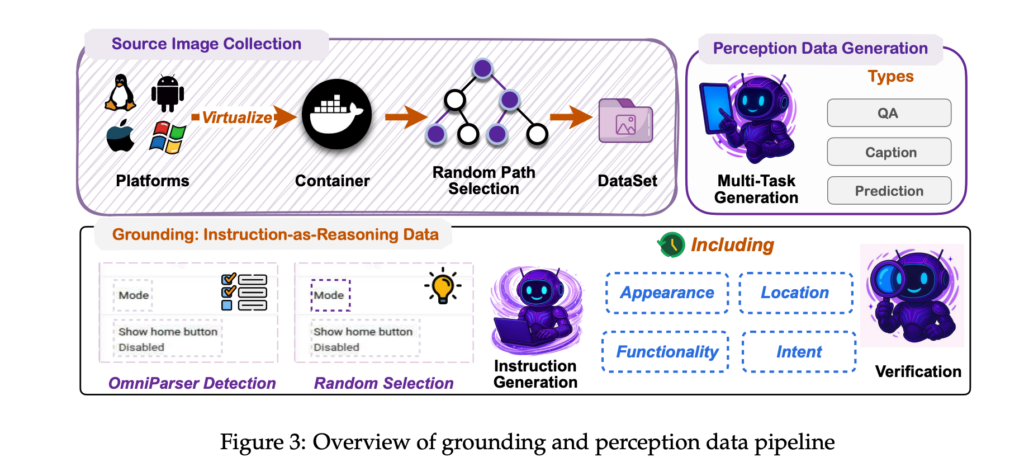
単に画面上の要素を検出するだけでなく、要素間の関係性や文脈を踏まえて操作対象を特定する仕組みとなっています。
その結果、ScreenSpot-ProやMMBench GUIといった評価環境で高いスコアを達成。静的なUI理解にとどまらず、画面遷移を伴うタスクに強い点がポイントです。
マルチステップタスクに耐える状態管理設計
MAI-UIは、1アクションごとに完結する設計ではありません。
タスクの進行状況や過去の操作履歴を内部状態として保持し、次に取るべき行動を継続的に判断する構造となっています。この仕組みにより、複数画面をまたぐ操作や条件分岐を含むタスクにも対応できるようになっています。
ask_userとMCPによる柔軟な行動拡張
特徴的なのが、モデル単体で全てを完結させない点です。
判断に必要な情報が不足している場合、ask_userアクションを通じてユーザーに確認を求める設計がされています。
さらに、外部ツールや知識が必要な場面ではMCP呼び出しを行うことも想定。これにより、現実の利用環境で起こり得る不確実性に対応しやすくなっている構成です。
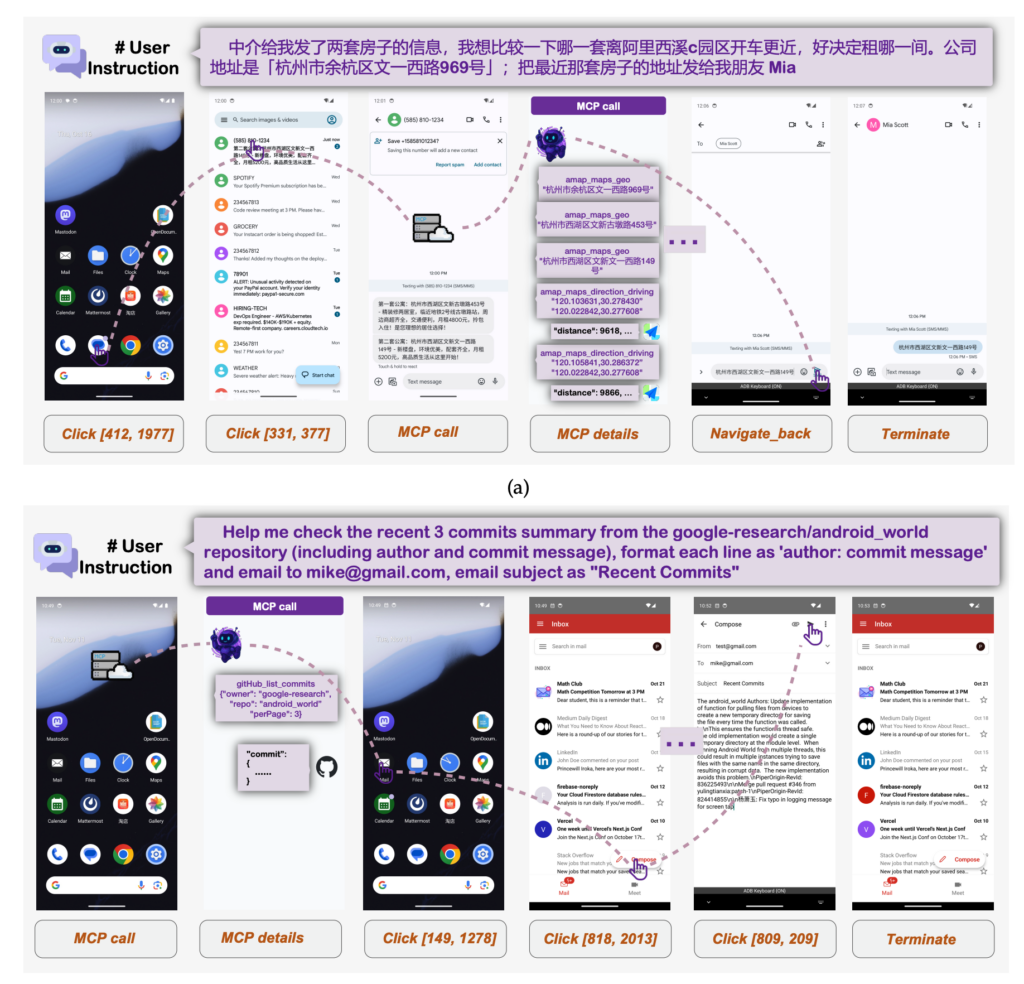
MAI-UIの安全性・制約
ここでは、MAI-UIを利用する際に押さえておきたい安全面の考え方と、現時点で確認できる制約について解説します。
まず安全性について、MAI-UIは端末とクラウドを役割分担させる設計方針を採っています。個人情報や即時性が求められる処理は端末側で行い、計算負荷の高い推論や学習関連はクラウド側で担う構成です。
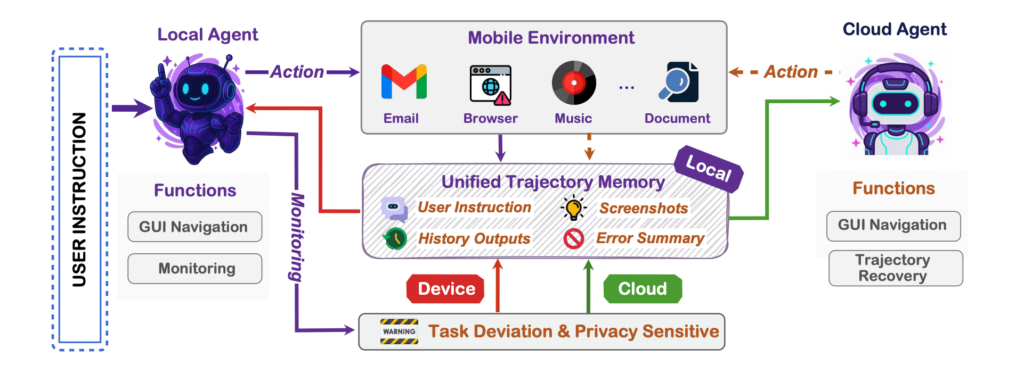
一方で、データの保存期間や暗号化方式、アクセス制御の詳細については、公式情報では明らかにされていません。どのデータがどこまで保持されるのか、第三者提供があるのかといった点も具体的な説明は公開されていない状況となっています。
制約面では、MAI-UIがGUI操作を前提としている点に注意が必要です。
アプリ側のUI変更やレイアウト差異が大きい場合、意図した操作が失敗する可能性があります。
また、動的に変化する要素が多い画面では、追加のユーザー確認や再推論が必要になる場面もあるため、完全自動化というより、ユーザーと協調しながら進める前提の設計といえます。
MAI-UIの料金
MAI-UIはHugging Faceからモデルをダウンロードして実行するため、基本的には料金がかかりません。
MAI-UIのライセンス
MAI-UIはApache 2.0ライセンスで公開されていて、商用利用・改変・再配布・特許利用・私的利用のすべてが許可されています。Apache 2.0ライセンスはオープンな条件で利用を認められているライセンスです
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
MAI-UIはApache 2.0ライセンスのもと、商用利用を含めて幅広い用途で利用できますが、生成物の内容や利用方法については利用者側が責任を負う点に注意が必要です。
まず、違法・有害なコンテンツの生成や法令に反する利用は認められていません。また、既存IPや実在人物を用いた生成物を商用利用する場合は、権利者のガイドラインや肖像権・プライバシーへの配慮が不可欠です。
なお、AIエージェントが自動でブラウザを操作するBrowser Useについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
MAI-UIの実装方法
では実際にgoogle colaboratoryを使ってMAI-UIを使っていきます。GitHub、Hugging Faceはそれぞれこちらです。
実装時のgoogle colaboratoryの環境は下記です。
◆システム RAM:7.0 / 12.7 GB
◆GPU RAM:12.4 / 15.0 GB
◆ディスク:49.5 / 112.6 GB
◆GPU:T4
◆プラン:無料
今回はiPhoneのトップ画面のスクショを渡してどのような操作をすればいいのかの助言を求めます。

まずは必要ライブラリのインストール。
pip -q install -U "transformers>=4.57.1" accelerate pillow torch torchvisionサンプルコードはこちら
import torch
from PIL import Image
from transformers import AutoProcessor, Qwen3VLForConditionalGeneration
MODEL_ID = "Tongyi-MAI/MAI-UI-2B"
model = Qwen3VLForConditionalGeneration.from_pretrained(
MODEL_ID,
dtype=torch.float16,
device_map="auto",
)
processor = AutoProcessor.from_pretrained(MODEL_ID)
image_path = ""
image = Image.open(image_path).convert("RGB")
instruction = "この画面で次に行うべき操作を1つだけ提案して。可能ならタップ対象(ボタン名など)も書いて"
messages = [{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": instruction},
],
}]
prompt = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
inputs = processor(text=prompt, images=image, return_tensors="pt")
inputs = {k: v.to(model.device) for k, v in inputs.items()}
inputs.pop("token_type_ids", None)
with torch.inference_mode():
out = model.generate(**inputs, max_new_tokens=128, do_sample=False)
gen = out[0][inputs["input_ids"].shape[-1]:]
print(processor.decode(gen, skip_special_tokens=True))結果はこちら
タップ対象:検索ボタン(グレーの円形ボタン、中央に「検索」の文字)もし上記でエラーになる場合には「Pillow」のバージョンを変えてください。
Pillowの再インストールはこちら
!pip -q uninstall -y Pillow pillow
!pip -q install --no-cache-dir --force-reinstall "Pillow==10.4.0"
!python -c "import PIL; print(PIL.__version__, PIL.__file__)"
!pip show Pillow | sed -n '1,8p'これでPillowのバージョンが10.4.0になっていればOKです。
MAI-UIの活用事例
ここでは、MAI-UIの仕組みや特徴を踏まえ、どのような場面での活用が想定されるのかを解説します。
モバイル業務の操作自動化支援
MAI-UIは、スマートフォン上のGUI操作を前提に設計されています。
この特徴から、業務アプリでの定型操作を補助する用途が考えられるでしょう。
例えば、毎日決まった画面遷移を伴う入力作業や確認作業を、自然言語指示で進めるといった使い方が想定されます。マルチステップに対応している点は、業務フロー全体をまとめて任せたい場面で有効と言えます。
カスタマーサポートや社内ヘルプデスク支援
ask_userによるユーザー確認機構を備えていることから、対話を挟みながら操作を進める支援用途とも相性があります。
ユーザーからの「設定を変更したい」「どこを押せばよいか分からない」といった問い合わせに対し、実際の画面を見ながら案内する形での活用です。
モバイルアプリ検証・テスト支援
GUIグラウンディングとナビゲーション性能の高さから、アプリの操作検証やテスト自動化への応用も考えられます。人が行っていた一連の操作手順を自然言語で与え、実機やエミュレータ上で再現させる使い方が想定されるでしょう。
UI変更に対する追従性には注意が必要ですが、探索的テストの補助としては有効な可能性があります。


MAI-UIを実際に使ってみた
先ほどのスクショを使ってもう少しMAI-UIを使っていきます。
今度は「メールを確認したいとき、次に取るべき操作は?」と指示を与えます。
サンプルコードはこちら
import torch
from PIL import Image
from transformers import AutoProcessor, Qwen3VLForConditionalGeneration
MODEL_ID = "Tongyi-MAI/MAI-UI-2B"
model = Qwen3VLForConditionalGeneration.from_pretrained(
MODEL_ID,
dtype=torch.float16,
device_map="auto",
)
processor = AutoProcessor.from_pretrained(MODEL_ID)
image_path = "/content/スクリーンショット 2026-01-06 13.06.56.png"
image = Image.open(image_path).convert("RGB")
instruction = "メールを確認したいとき、次に取るべき操作は?"
messages = [{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": instruction},
],
}]
prompt = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
inputs = processor(text=prompt, images=image, return_tensors="pt")
inputs = {k: v.to(model.device) for k, v in inputs.items()}
inputs.pop("token_type_ids", None)
with torch.inference_mode():
out = model.generate(**inputs, max_new_tokens=128, do_sample=False)
gen = out[0][inputs["input_ids"].shape[-1]:]
print(processor.decode(gen, skip_special_tokens=True))結果はこちら
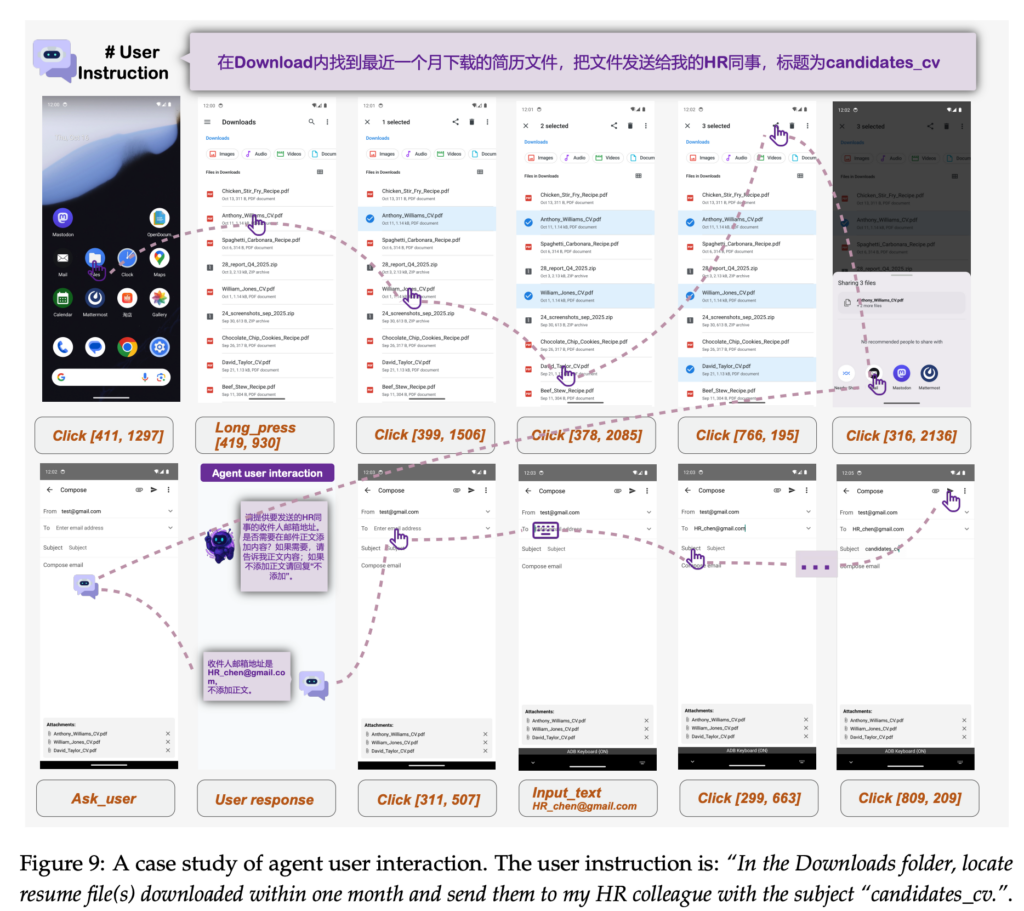
メールを確認したいとき、まず画面の上部に表示されている「メール」アプリのアイコンをタップします。このアイコンは青い背景に白いメールのアイコンと「メール」という文字、そして右上に赤いバッジに「45」という数字が表示されています。タップすることで、メールアプリが開き、最新のメールが確認できます。適切な指示をくれて、さらに未読メールが何件溜まっているかも教えてくれました。
次にこちらを試してみます。
サンプルコードはこちら
import torch
from PIL import Image
from transformers import AutoProcessor, Qwen3VLForConditionalGeneration
MODEL_ID = "Tongyi-MAI/MAI-UI-2B"
model = Qwen3VLForConditionalGeneration.from_pretrained(
MODEL_ID,
dtype=torch.float16,
device_map="auto",
)
processor = AutoProcessor.from_pretrained(MODEL_ID)
image_path = "/content/スクリーンショット 2026-01-06 13.06.56.png"
image = Image.open(image_path).convert("RGB")
instruction = "このスマートフォンのホーム画面を観察し、画面上から読み取れる情報を整理してください。アプリ名、通知の有無、フォルダと単体アプリの違いに注目し、推測ではなく画面から確認できる事実のみを述べてください。"
messages = [{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": instruction},
],
}]
prompt = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
inputs = processor(text=prompt, images=image, return_tensors="pt")
inputs = {k: v.to(model.device) for k, v in inputs.items()}
inputs.pop("token_type_ids", None)
with torch.inference_mode():
out = model.generate(**inputs, max_new_tokens=128, do_sample=False)
gen = out[0][inputs["input_ids"].shape[-1]:]
print(processor.decode(gen, skip_special_tokens=True))結果はこちら
- アプリ名:FaceTime、カレンダー、写真、カメラ、メール(45件)、時計、マップ、天気、メモ、ブック、App Store、ヘルスケア、設定、Folder、マルチコピー、Djangoで読書…、Python/Murasa…、プログラミング…、Google、食べログ、コネクト、LINE WORKS、Work Tree、Claude
- 通知:FaceTime(45件)、LINE WORKS(41件)、ミュージック(3件)
- フォルダと単体アプリのトークンの関係で途中で切れてしまいましたが、概ね適切に読み取れているようです。
2Bモデルでこのような精度なので、8Bや32Bではより精度高くスマホを操作できそうです。
なお、エージェント主導でUIを安全に生成するGoogle Agent-to-User Interfaceについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
まとめ
本記事ではMAI-UIの概要から仕組み、実際の使い方について解説をしました。
2Bモデルで検証を行いましたが、小さいモデルながらに精度高くスマホ画面を読み取り、出力をしてくれました。より大きいモデルを使えば、もっと細かい指示も与えられそうです。
ぜひ皆さんも本記事を参考にMAI-UIを使ってみてください!
最後に
いかがだったでしょうか?
MAI-UIを「実際に業務へどう活かせるのか」を知りたい方へ。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。


