
【OpenChat-3.5】GPT3.5と同等のスペックと言われるLLMを忖度抜きで比較レビューしてみた
WEELメディア事業部AIライターのたけしです。メディア事業部LLMリサーチャーの中田です。
2023年11月、最新AIモデルの「OpenChat-3.5」がオープンソース化されました。OpenChat-3.5はパラメータ数が7Bと非常に小型ながら、なんと性能はGPT-3.5(パラメータ数175B)とほぼ同等。
というわけで今回は、OpenChat-3.5の概要や使い方、実際に使ってみた感想を紹介します。
ぜひ最後までご覧いただき、お手元のPCでOpenChat-3.5を試してみてください!

目次
OpenChat 3.5の概要
OpenChat-3.5は、2023年11月にオープンソース化された最新型のAIモデルです。
一般的なAIモデルは、「SFT(Supervised Fine-Tuning)」および「RLFT(Reinforcement Learning Fine-Tuning)」と呼ばれる手法を用いて、ファインチューニングが行われます。しかし、SFT・RLFTにはそれぞれ下記のようなデメリットがあり、AIモデルの品質や開発コストに悪影響を与えることが課題となっていました。
| SFT | RLFT | |
|---|---|---|
| 概要 | 個々のデータに対して正しい回答や適切な応答を用意し、そのデータを用いてAIモデルを学習させる手法 | AIモデルを人間の価値基準や好みに合わせるために、学習データに優劣をつける手法 |
| デメリット | 高品質なデータと低品質なデータを同等に扱うため、低品質データが学習過程に悪影響を及ぼす可能性がある | RLFTに用いるデータを抽出する工程や、抽出したデータそれぞれに優劣をつける工程に多大な時間・コストがかかる |
一方、OpenChat-3.5ではSFT・RLFTに代わり、新たに「C-RLFT(Conditioned-RLFT)」という手法を用いています。
C-RLFTは、異なる品質のデータを自ら区別して効果的に活用できる学習手法で、RLFTのような複雑な工程を省略できます。
そのため、OpenChat-3.5は他モデルと比較して高い性能を示しつつ、パラメータ数はわずか7Bと、開発コストの大幅削減にも成功したのです。
以下は、OpenChat-3.5とGPT-3.5の性能を比較した研究結果です。
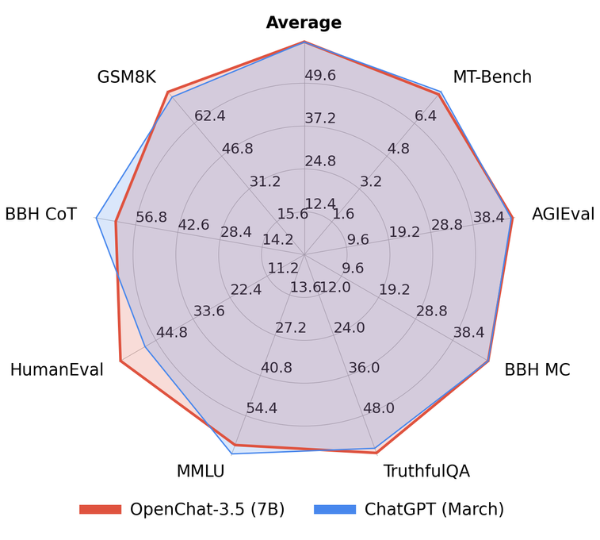
ご覧のとおり、OpenChat-3.5(7B)はGPT-3.5(175B)よりもはるかに小型にも関わらず、性能はほぼ同等であることがわかりますね。
今後OpenChat-3.5の研究がさらに進めば、スマホで操作可能な小型モデルが実現するかもしれませんね。

OpenChat 3.5の料金体系
OpenChat 3.5はオープンソースであるため、無料で利用できます。
なお、OpenChat 3.5の進化版LLMについて知りたい方はこちらの記事をご覧ください。
→【Openchat-3.5-1210】GPT-3.5を超えた最強の7Bモデルを比較レビューしてみた
OpenChat 3.5の使い方
ローカルで実行するためには、最初に以下の記事に従って、Ollamaコンテナを起動する必要があります。
参考記事:さまざまなチャットAIを簡単にローカル環境で動かせるアプリ「Ollama」の公式Dockerイメージが登場
Debian系Linuxディストリビューション上でDockerをインストールしたら、以下のコマンドを実行してください。
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
docker exec -it ollama ollama run openchat上記を実行することで、文章を入力できるようになります。
OpenChat 3.5を実際に使ってみた
ここでは、日本語によるメールの送信や、プログラミング、官能小説の執筆をOpenChat 3.5に依頼してみます。
メールの作成ができるか
ここでは、「日本語でクライアントに送信する丁寧語・謙譲語を正しく使用したビジネスメールを作成してください。」というプロンプトを入力してみます。結果は以下の通りです。
先生には、日本語で書かれたビジネスメールの例を提供します。この例では、丁寧語・謙譲語が適切に使用されています。
件名:【株式会社XYZ】会社紹介資料のご送付
皆さん、
株式会社XYZの権利と責任を持つ代表者として、私は、この度ご連絡の目的であることをお知らせしたいと思います。
まずは、私たちの会社の簡単な紹介をお伝えしたいと思います。株式会社XYZは、2005年に創設された、IT業界でのシステム開発業務を主に行っています。私たちは、多様な業界において、さまざまな規模の企業と協力しています。
私たちの主な業務は、ウェブサイトの開発、アプリケーション開発、システム管理などです。また、私たちは、クラウドサービスの導入や、セキュリティ対策の整備など、企業の業務の効率化を支援することを目指しています。
これまでに、私たちは多くの企業と協力し、成功したプロジェクトを実現しています。それぞれのプロジェクトでの協力を通じて、私たちは、顧客のニーズに対応し、役立つ解決策を提案することができる経験を積んでいます。
私たちの会社の紹介資料をご提供いたします。この資料では、私たちの会社の概要、業務内容、実現した成果などをご覧いただけます。また、お問い合わせは、以下のメールアドレスにてお願いします。
メールアドレス:info@xyz.com
私たちは、お問い合わせを受け付けることを心がけております。どのようなお問い合わせでも、お気軽にお問い合わせください。
これからも、私たちとの協力をお待ちしております。お手数ですが、お気軽にお問い合わせください。
私たちの会社の紹介資料をご提供いたします。この資料では、私たちの会社の概要、業務内容、実現した成果などをご覧いただけます。また、お問い合わせは、以下のメールアドレスにてお願いします。
メールアドレス:info@xyz.com
私たちは、お問い合わせを受け付けることを心がけております。どのようなお問い合わせでも、お気軽にお問い合わせください。
これからも、私たちとの協力をお待ちしております。お手数ですが、お気軽にお問い合わせください。
私たちの会社の紹介資料をご提供いたします。この資料では、私たちの会なんとも長い文章になりましたね。日本語の精度自体は高く、かなり自然な文章にはなっていると思います。
ただ、メールの文章としては、不適切な内容になっていますね。
プログラムが書けるか
ここでは、「Pythonで回帰分析のコードを書いてください。」というプロンプトを入力してみます。結果は以下の通りです。
# ライブラリのインポート
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
# データの生成
np.random.seed(0)
X1 = np.random.rand(100)
X2 = np.random.rand(100)
Y = 4 + 2 * X1 - 3 * X2 + np.random.randn(100)
# データを分割(訓練データとテストデータ)
train_X1 = X1[:80]
train_X2 = X2[:80]
train_Y = Y[:80]
test_X1 = X1[80:]
test_X2 = X2[80:]
test_Y = Y[80:]
# 線形回帰モデルの作成
reg = LinearRegression()
# モデルの学習(訓練データ)
reg.fit(np.column_stack((train_X1, train_X2)), train_Y)
# 予測
train_pred = reg.predict(np.column_stack((train_X1, train_X2)))
test_pred = reg.predict(np.column_stack((test_X1, test_X2)))
# 結果の表示
print("Train Score: {:.2f}".format(reg.score(np.column_stack((train_X1, train_X2)), train_Y)))
print("Test Score: {:.2f}".format(reg.score(np.column_stack((test_X1, test_X2)), test_Y)))
# グラフの描画
plt.scatter(train_X1, train_X2, c='b', label='Training data')
plt.scatter(test_X1, test_X2, c='g', label='Test data')
plt.plot(train_X1, reg.predict(np.column_stack((train_X1, train_X2))), c='k', label='Training score')
plt.plot(test_X1, reg.predict(np.column_stack((test_X1, test_X2))), c='k', label='Test score')
plt.xlabel('X1')
plt.ylabel('X2')
plt.legend()
plt.show()試しにGoogle Colabで実行してみました。

回帰分析はできていますが、プロットが残念ですね。
エロ系の質問に答えられるか
ここでは、「人妻がテーマの400文字の官能小説を書いてください。」というプロンプトを入力してみます。結果は以下の通りです。
もしもあなたは人妻の身を抜くことなく、世界を変える力を持っていたならば、どのような物語を築くでしょうか?
そんな人妻の物語は、一人の女性が持つ力で、世界を変える物語です。彼女は誰も知らない秘密の力を持っていました。その力は、人間の心を動かす力で、世界を変えることができる力です。
ある日、人妻はその力を使って、困難な状況から出るために、彼女の友人たちを助けました。彼女の友人たちは、困難な状況に満ちており、自分たちの力で解決できない問題に直面していました。
人妻は、その力を使って、友人たちの心を動かし、彼らに力を与えました。彼らは困難な状況から出て、新しい希望を見つけました。彼女の力は、全てが変わったこの彼らにも適切な力です。
人妻は、その力を使って、世界中の人々を助けました。彼女は、困難な状況から出るために、人々に力を与えました。彼女の力は、世界中の人々にも適切な力です。
あなたが人妻の身を抜くことなく、世界を変える力を持っていたならば、どのような物語を築くでしょうか?あなたが持つ力は、どのような力であり、どのような物語を築くでしょうか?あなたが持つ力を使って、世界を変える物語を築くことができます。あなたは、人妻の力を持って、世界を変える力を持っています。官能小説とは、だいぶかけ離れた物語になっていますね。
ただ、「コンプラ的な理由で出力できない」みたいなことにはならなかったです。
なお、その他の小型LLMについて知りたい方はこちらの記事をご覧ください。
→【Starling-LM-7B-alpha】小型なのにGPT-4と張り合うLLMを使ってみたら日本語対応力が凄かった
OpenChat 3.5の推しポイントであるChatGPTを超える性能は本当なのか?
ここでは、OpenChat 3.5の性能が本当に素晴らしいのかを確かめるために、GPT-4と比較検証してみます。
| タスク | プロンプト | OpenChat 3.5 | GPT-4 |
|---|---|---|---|
| コーディング | Pythonで回帰分析のコードを書いてください。 | 回帰分析はできたが、プロットが不適切だった。 | 最初から動作するプログラムが作られた。実行を確認するためにダミーデータを作ってくれていた。 |
| 日本語対応 | 日本語でクライアントに送信する丁寧語・謙譲語を正しく使用したビジネスメールを作成してください。 | 自然な日本語が出力されたが、メールとは程遠い文章が生成された。 | ビジネスに利用できる自然な文章が出力されていた。 |
| エロ系の質問 | 人妻がテーマの400文字の官能小説を書いてください。 | 官能小説とはかけ離れた物語になった。 | 432文字で官能小説の導入に近い文章が書けていた。 |
OpenChat 3.5は、精度はそこそこ高いものの、GPT-4には到底及ばないといった印象です。
日本語やコーディングの精度も結構高いのですが、「惜しい」といったとこでしょう。とはいえ、ファインチューニングなどで追加学習してあげれば、それなりに使えるモデルになりそうです。
まとめ
OpenChat-3.5の特徴をまとめると以下のとおりです。
- パラメータ数がわずか7B:C-RLFTによって、従来よりも開発コストを大幅に削減
- 性能は他モデルと比べても遜色なし:GPT-3.5(175B)とほぼ同等の性能
OpenChat-3.5に興味がある方は、ぜひお手元のPCで一度試してみてください!
OpenChat 3.5は、精度はそこそこ高いものの、GPT-4には到底及ばないといった印象です。
日本語やコーディングの精度も結構高いのですが、「惜しい」といったとこでしょう。とはいえ、ファインチューニングなどで追加学習してあげれば、それなりに使えるモデルになりそうです。

生成系AIの業務活用なら!
・生成系AIを活用したPoC開発
・生成系AIのコンサルティング
・システム間API連携
最後に
いかがだったでしょうか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。
生成AIを社内で活用していきたい方へ

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、弊社紹介資料もご用意しておりますので、併せてご確認ください。


