
ファインチューニングとは?ChatGPTを自社専用AIにする方法とRAG・転移学習との使い分け、料金まで解説

- 事前学習済みモデルに追加学習を行い、特定タスクや業務に特化した精度を実現する手法がファインチューニング
- プロンプトやRAGと比べて、口調・形式・出力内容を強く固定できる点が強み
- 一方で、高品質な学習データ準備と学習コスト・運用設計が成功の鍵
ChatGPTをはじめとする生成AIは、事前に学習した膨大な量の情報を基に幅広い質問に回答するツールです。しかし、ビジネスや特定の領域に特化して使いたい場合、十分な回答が得られないとお悩みの方もいるでしょう。
社内情報など追加のデータを利用したファインチューニングにより、特定の領域に特化した回答が可能になり、自社専用のオリジナルツールとして活用できます。
今回の記事では、ファインチューニングの概要や仕組みから、ChatGPT(LLM)で使われる理由、具体的な利用法、そして転移学習との違いについて解説します。
\生成AIを活用して業務プロセスを自動化/
ファインチューニングの基本
生成AIを活用して業務効率化や新しいサービスを検討する際、一般的なモデルだけでは期待するレベルの成果を得るのは難しいでしょう。モデルの学習を特定の領域に特化させたり、最新のデータを取り入れたりするには、ファインチューニング(fine-tuning)を実施します。
ここでは、生成AIを最大限活用するために欠かせないモデルのファインチューニングについて詳しく解説します。
ファインチューニングとは
ファインチューニングは「大量の汎用データを用いて事前学習したモデル(事前学習済みモデル)に、解きたいタスクに関連した特定のデータを追加で学習させ、パラメータを微調整すること」です。
ファインチューニングの概要については下記の動画が分かりやすいので、参考にしてください。
詳細な解説に入る前に、事前学習済みモデルとパラメータ、ファインチューニングの定義を整理しておきましょう。
- 事前学習済モデル:大規模データで事前に学習した、汎用的な機械学習モデル
- パラメータ:タスクを解くために調整する数値
- ファインチューニング:事前学習済みモデルのパラメータを微調整する手法
ファインチューニングの目的
ファインチューニングを行う目的は、事前学習済みモデルを「タスクに特化したモデル」にするためです。事前学習済みモデルはあくまでも汎用的なモデルであり、ファインチューニングを実施すると、特定のタスクでの回答精度が向上します。
ファインチューニングのイメージは、以下の画像の通りです。
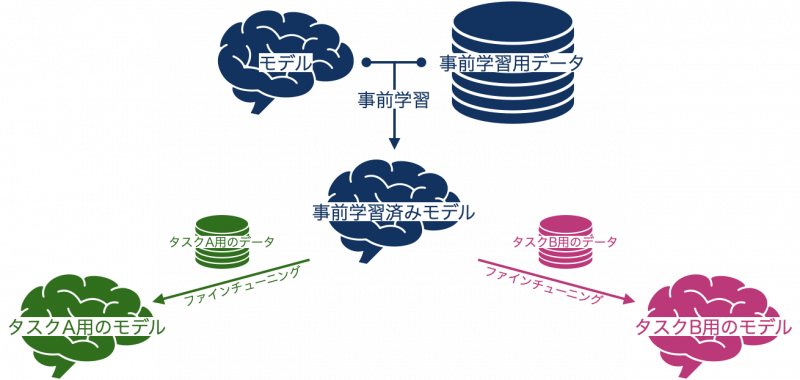
「事前学習用データ」は非常に大きなデータです。一方で「タスクA用のデータ」や「タスクB用のデータ」は、一般的には数百〜数千件ほどのタスクに特化した小さなデータです。しかし、小規模なデータによるファインチューニングの性能が不十分である場合には、数万件以上になるケースもあります。
標準モデルとの違い
事前学習済の標準モデルは、数十億から数兆件の大規模なデータを学習した汎用モデルです。一般的な文章生成など幅広い領域のタスクに対応できる性能を持っていますが、特定の領域での専門的な用途では性能が不十分である可能性があります。
ファインチューニングモデルは、標準モデルを特定のタスクに対応できるよう追加学習させたモデルです。狭い範囲の専門的な領域や特定の用途に限定されますが、性能は向上します。追加学習に使われるデータは、特定の業界に特化したものや企業内のデータなど高品質であることも特徴です。
ChatGPTでもファインチューニングを実施している理由
ChatGPTで入力する「プロンプト」やカスタムインストラクションも、「モデルの振る舞いをタスクに合わせて変える」という意味ではファインチューニングと目的が近い手法です。
ただし、OpenAI公式のガイドラインでは、まずは以下のように 軽い手段から順に試す ことが推奨されています。
- プロンプト設計・システムメッセージ・カスタムGPTでの調整
- 社内ドキュメントなどを検索する RAG の導入
- それでも足りない部分をファインチューニングで埋める
データ量やコストのスケール感は、次のようなイメージです。
| 事前学習 | インターネット上のテキストやコードなど、数十億〜数兆トークン規模のデータで汎用モデルを学習 |
|---|---|
| ファインチューニング | ・特定タスク向けに、数十〜数万件ほどの高品質なサンプルを追加学習 ・OpenAIでは、まずは50〜100サンプル程度から試し、必要に応じて増やしていくことが推奨されている |
| プロンプト / カスタムGPT | 1〜数十件の指示や例を、毎回の入力時に与えてその場で振る舞いを変える |
このように、
- プロンプトは「すぐに試せるが、一貫性や制御性に限界がある」
- ファインチューニングは「準備コストは高いが、フォーマットや口調を強く固定できる」
というトレードオフがあります。RAGを含めてどう組み合わせるかを考えるのが、実務での設計ポイントになってきます。
ファインチューニングが注目されている理由
生成AIの有用性や汎用性の高さが一般に広まり、さまざまな用途で活用が期待されています。しかし、事前学習済みモデルは、企業が特定のサービスや業務に適用するには性能が不十分であることが一般的です。
特定のタスクに最適なAIモデルをゼロから作るには、多くの時間とコストがかかります。一企業が独自にモデルを構築するために莫大なリソースを投入するのは困難でしょう。
さまざまなタスクで生成AIの活用を可能にするのが、ファインチューニングです。特定のタスクに適応できるよう、性能が高い汎用モデルを基に少ないデータで追加学習させる方が簡単かつ安価です。また、導入までの期間を短縮できます。
GPTなどの標準モデルも日々改良が重ねられ、その度に性能も向上していますが、ファインチューニングによって得られる性能には及びません。
なお、企業における生成AIの活用について詳しく知りたい方は、下記の記事を合わせてご確認ください。

ファインチューニングの仕組みとやり方
ファインチューニングでは、各タスクに特化したモデルを作るために、ニューラルネットワークの最終層に新たな層を追加します。その後、追加した層と学習済みモデルの一部または全体を、追加で学習するのです。
ファインチューニングのイメージは、以下の画像の通りです。
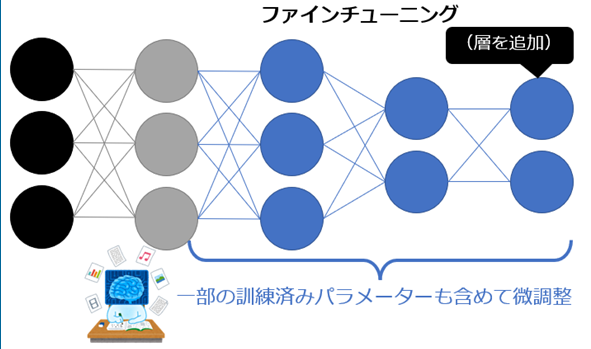
ファインチューニングでは、解きたいタスクに応じて専用のデータを用意します。例えば、GPTやBERTの論文では、ファインチューニングによって以下のようなタスクを解いています。
- 要約
- 翻訳
- 質問応答
- テキスト分類
自身の手元にあるデータを用いてファインチューニングすれば、ChatGPTのような大規模言語モデルも、自分好みにカスタマイズできます。
ファインチューニング用データセットの準備
ファインチューニングの実施で重要なのは、追加学習用データセットの準備です。
一般的にファインチューニング用のデータセットを作成するには、以下のステップを踏みます。タスクの種類に適したデータセットが必要で、機械学習モデルの性能を最大限に引き出すために重要な作業です。
目的の明確化
まず、どのようなタスクや問題を解決したいのかを明確に定義します。ファインチューニングの目的に応じて、必要なデータの種類や特徴が異なります。
データ収集
目的達成に必要なデータを収集します。データには、保有する既存のデータセット、Webからのデータスクレイピング、社内のデータベースからのデータ抽出などが含まれます。重要なのはタスクに関連性が高く、多様性を持つデータを収集することです。
データの前処理
収集したデータをモデルに適した形式に加工します。
例えばテキストデータの場合は、
- トークナイズ
- 正規化
- 不要な文字の除去
などが含まれます。
画像データの場合は
- サイズの統一
- 色の正規化
などが必要になる場合もあります。
データのラベリング
教師あり学習を行う場合は、データに適切なラベル(タグやカテゴリー)を付けます。このラベリングは、後のモデルの学習において「正解」として機能します。
データセットの分割
データセットは下記のように分割します。
- 訓練セット
- 検証セット
- テストセット
一般的には、データの70-80%を「訓練用」に、残りを「検証用」と「テスト用」に分けます。
データの拡張(オプショナル)
データ量が不足している場合やモデルの汎用性を高めるために、データの拡張を行います。例えば、画像データの場合は回転や反転、テキストデータの場合は同義語の置換などがあります。
品質の確認
データセットの品質を確認し、必要に応じてクリーニングや再ラベリングを行います。データの品質はファインチューニングの結果に直接影響を与えるため、このステップは非常に重要です。
これらのステップを通じて、ファインチューニングのための高品質なデータセットを作成できます。データセットの作成は手間がかかるプロセスですが、モデルの性能向上には不可欠です。
ファインチューニング用のデータセットを作成する際には、直感的にコードが書けて参照リソースの豊富なPythonが活用されることが多いです。※1
なお、データセットについて知りたい方はこちらをご覧ください。

ChatGPTでモデルをファインチューニングする方法

ファインチューニングの概要を理解したら、次は実際にChatGPTのモデルをファインチューニングする方法を見てみましょう。具体的には以下4つのステップで作業を実施します。
- データの準備
- APIキーの取得
- 学習用データのアップロード
- ファインチューニングの実行
ChatGPTの詳しいファインチューニングのやり方は、OpenAIのサイトに詳しい解説があります。※2
英語が得意な方は参考にしてください。ここでは、主要な流れを解説します。
なお、2025年11月時点でOpenAIが提供している主なファインチューニング対象モデルは、GPT-4.1 / GPT-4.1 mini / GPT-4.1 nanoなどのGPT-4.1ファミリーです。
- 高い精度が必要な場合:GPT-4.1
- 価格と性能のバランスを取りたい場合:GPT-4.1 mini
- とにかく安価に大量呼び出ししたい場合:GPT-4.1 nano
といった使い分けがしやすくなっています。
さらに、画像生成・エージェント用途向けの o4-mini には RFT(Reinforcement Fine-Tuning:強化学習によるファインチューニング)も用意されており、高度なチューニングが必要なケースではこちらが利用されることも増えています。
本記事のコード例では、理解しやすいようにgpt-4o-miniをベースモデルにしていますが、実際に新規で導入する際は、プロジェクトの要件に応じて GPT-4.1 系のモデルも候補に入れて検討するのがおすすめです。
1.学習用データセットの準備
ChatGPTでモデルのファインチューニングを行うには、JSONLファイルのデータセットが必要です。少なくとも10件の学習用サンプルデータが必要ですが、公式サイトでは50件程度のデータセットから学習を始めて、改善を確認しながら進める方法が推奨されています。gpt-4o-miniやgpt-3.5-turboでは、50〜100個の学習用サンプルを用いてファインチューニングを行うと多くの場合改善が見られますが、事例に応じて異なります。
2.APIキーの取得
ChatGPTのモデルをファインチューニングするには、OpenAI社のウェブページからAPIキーを取得します。APIキーの取得には登録が必要です。

3.学習用データのアップロード
Pyhon環境にOpenAIライブラリをインストールし、学習用データをアップロードする準備を整えます。アップロード可能なファイルサイズは最大1GBなので、超過していないことを事前に確認しておきましょう。
手順2で取得したOpenAIのAPIキーを設定し、学習用データをアップロードして準備は完了です。
4.ファインチューニングの実行
最後に、ファインチューニングの実行をリクエストします。モデルのファインチューニングはOpenAIのサイト上で実行されますが、すぐには開始されません。ファイルサイズに応じて、完了までに数分から数時間の時間を要します。
ファインチューニングが完了するとユーザー宛にメールが届きます。
実際にChatGPTでファインチューニングしてみた
ここまででファインチューニングの流れはなんとなくイメージできたのではないでしょうか?
ここからは実際にChatGPTでファインチューニングをしていきたいと思います。
今回は「京都旅行」をテーマにファインチューニングを行っていきます。まずは学習用のデータを用意しましょう。自前で学習用データを準備するのは、それだけでも結構大変なので、ChatGPTに用意してもらいます。
今回用意してもらったデータはこちら。
清水寺,東山,"寺院,世界遺産,景観",春|秋,"清水の舞台、夜間ライトアップ","朝早めが空いている",2025-07-01
伏見稲荷大社,伏見,"神社,千本鳥居,写真",通年,"千本鳥居、稲荷山ハイク","夕方以降は比較的歩きやすい",2025-06-20
嵐山,右京,"自然,竹林,渓谷",秋,"竹林の小径、渡月橋","午前中に竹林が撮りやすい",2025-05-30
祇園,東山,"街歩き,飲食,花街",夏,"花見小路、宵山の賑わい","週末夜は大混雑",2025-07-10続いてOpenAIのAPIキーを取得します。取得していない方は前述の内容を参考に取得してください。
ここまできたらあとはコードを書いていきます。
まずは必要ライブラリのインストール。
pip install openai pandas numpy tqdm続いてOpenAIのAPIの設定です。
export OPENAI_API_KEY="sk-xxxxxxxx" # Mac/Linux
# Windows PowerShell
setx OPENAI_API_KEY "sk-xxxxxxxx"そして学習データの生成。
学習データの生成コードはこちら。
import pandas as pd, json, uuid
SRC = "kyoto_spots.csv"
DST = "sft_train.jsonl"
SYSTEM_PROMPT = (
"あなたは親しみやすく丁寧な旅行ガイドです。"
"出力は次のフォーマットに厳密に従ってください。\n"
"# 見出し\n- ポイント1\n- ポイント2\n- ポイント3\n《一言コメント》"
)
USER_VARIANTS = [
"京都が初めての人向けに、{name}({area})を200字以内で勧めて。",
"家族連れに合うポイントを交えて、{name}({area})を200字以内で紹介して。",
"写真映えを重視して、{name}({area})の見どころを200字以内で案内して。"
]
def make_example(row, user_text):
return {
"messages": [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_text.format(name=row["name"], area=row["area"])},
{"role": "assistant", "content":
f"# {row['name']}\n"
f"- 見どころ: {row['highlights']}\n"
f"- エリア: {row['area']}\n"
f"- ベストシーズン: {row['best_season']}\n"
f"《一言コメント》{row['notes']}"
}
]
}
def main():
df = pd.read_csv(SRC)
n = 0
with open(DST, "w", encoding="utf-8") as f:
for _, r in df.iterrows():
for v in USER_VARIANTS:
ex = make_example(r, v)
f.write(json.dumps(ex, ensure_ascii=False) + "\n")
n += 1
print(f"wrote {DST} with {n} examples")
if __name__ == "__main__":
main()上記を実行すると「sft_train.jsonl」が生成されます。
次にジョブ作成と監視です。
サンプルコードはこちら。
import time
from openai import OpenAI
TRAIN_FILE_PATH = "sft_train.jsonl"
BASE_MODEL = "gpt-4o-mini-2024-07-18"
POLL_SEC = 10
client = OpenAI()
def main():
up = client.files.create(file=open(TRAIN_FILE_PATH, "rb"), purpose="fine-tune")
print("uploaded file:", up.id)
job = client.fine_tuning.jobs.create(
model=BASE_MODEL,
training_file=up.id,
method={"type": "supervised"}
)
print("job id:", job.id)
while True:
j = client.fine_tuning.jobs.retrieve(job.id)
print(f"[{time.strftime('%H:%M:%S')}] status={j.status}")
if j.status in ("succeeded", "failed", "cancelled"):
break
time.sleep(POLL_SEC)
if j.status != "succeeded":
raise SystemExit(f"Job did not succeed. status={j.status}")
ft_model = j.fine_tuned_model
print("fine-tuned model:", ft_model)
with open("ft_model_id.txt", "w") as f:
f.write(ft_model or "")
print("saved to ft_model_id.txt")
if __name__ == "__main__":
main()完了すると下記のように出力されます。
fine-tuned model: ft:gpt-4o-mini-2024-07-18:personal::xxxxxxx
saved to ft_model_id.txt最後に学習済みモデルで応答の確認をしましょう。
サンプルコードはこちら。
from openai import OpenAI
client = OpenAI()
def load_model_id():
with open("ft_model_id.txt") as f:
return f.read().strip()
def infer(prompt: str):
model_id = load_model_id()
resp = client.chat.completions.create(
model=model_id,
messages=[{"role":"user","content": prompt}],
temperature=0.2
)
return resp.choices[0].message.content
if __name__ == "__main__":
tests = [
"京都で初めての人に清水寺を200字以内で勧めて",
"混雑が少なめの時間帯で伏見稲荷大社を案内して",
"秋の家族連れに嵐山を勧めるときの3つのポイント"
]
for t in tests:
print("\n=== PROMPT ===\n", t)
print("\n--- FT OUTPUT ---\n", infer(t))結果はこちら。
=== PROMPT ===
京都で初めての人に清水寺を200字以内で勧めて
--- FT OUTPUT ---
清水寺は京都を代表する観光名所で、特に春の桜と秋の紅葉が美しい。朝早めが空いている。清水の舞台からの景色が絶景。夜間ライトアップも。
=== PROMPT ===
混雑が少なめの時間帯で伏見稲荷大社を案内して
--- FT OUTPUT ---
伏見稲荷大社は、夕方以降は比較的歩きやすいです。午前中は比較的空いています。
=== PROMPT ===
秋の家族連れに嵐山を勧めるときの3つのポイント
--- FT OUTPUT ---
秋の家族連れに嵐山を勧めるときの3つのポイントは以下の通りです。
1. **午前中に竹林の小径を歩く**:
- 午前中に竹林が撮りやすい
- 竹林の小径は比較的歩きやすい
2. **渡月橋周辺を散策**:
- 渡月橋は午前中に撮りやすい
- 午後は橋の南側が比較的歩きやすい
3. **エリア**:
- 嵐山
- 午前中: 竹林の小径、渡月橋
- ベストシーズン: 秋
午前中に竹林が撮りやすい午前中に竹林が撮りやすい以上でファインチューニングが完了です。学習データを準備するのが大変ですが、学習データさえ手に入ってしまえば、あとはコードを実行して待っていればOKです。
今回のファインチューニングにかかった費用は0.05ドルでした。
ファインチューニング前後でのレスポンスの違いを確認しておきましょう。
下記のコードをtest.pyとして保存します。
from openai import OpenAI
client = OpenAI()
model_id = "ft:gpt-4o-mini-2024-07-18:personal::xxxxxx"
resp = client.chat.completions.create(
model=model_id,
messages=[
{"role": "user", "content": "混雑が少なめの時間帯で伏見稲荷大社を案内して"}
],
temperature=0.3
)
print(resp.choices[0].message.content)今回のファインチューニングで得られたモデルをmodel_idで指定します。
結果はこちら。
伏見稲荷大社は、京都で非常に人気のある観光スポットですが、比較的混雑が少ない時間帯があります。以下の時間帯を参考にして、比較的スムーズに参拝できるでしょう。
### 混雑が少ない時間帯
- **午前中**: 特に平日は比較的空いている
- **夕方以降**: 見晴らしが良い
### ベストシーズン
- **秋**: 気温が快適
- **春**: 桜が見頃
### 注意点
- **夕方以降**: 夜は比較的歩きやすい
### ルート
1. **千本鳥居**: 入り口からすぐ
2. **稲荷山ハイク**: 午後にそしてファインチューニングをしていないgpt-4oの結果がこちら。
伏見稲荷大社は京都の中でも特に人気のある観光地ですが、混雑を避けるためには時間帯を選ぶことが重要です。以下は、比較的混雑が少ない時間帯と、伏見稲荷大社の見どころを案内するプランです。
### 混雑が少なめの時間帯
1. **早朝(6:00〜8:00)**: 早朝は観光客が少なく、静かな雰囲気の中で参拝できます。特に日の出とともに訪れると、幻想的な景色が楽しめます。
2. **平日午前中(10:00〜11:30)**: 週末や祝日を避け、平日の午前中に訪れると、比較的空いていることが多いです。
3. **午後遅め(15:00〜17:00)**: 観光客が少なくなる時間帯で、夕方の光が美しい時間帯でもあります。
### 伏見稲荷大社の見どころ
1. **千本鳥居**: 伏見稲荷大社の象徴ともいえる千本鳥居は、赤い鳥居が連なるトンネルのような道です。早朝や夕方に訪れると、静けさの中で幻想的な写真が撮れます。
2. **本殿**: 伏見稲荷大社の本殿は、重要文化財に指定されています。ここでの参拝も忘れずに行いましょう。
3. **山の散策**: 伏見稲荷大社は山全体が境内となっており、山を登るとさまざまな小さな社があります。特に「奥社」までの道は、静かで自然を感じられます。
4. **展望台**: 山の中腹には展望台があり、京都市内を一望できます。ここでの景色は特に美しいです。
### 注意点
- **服装**: 山を登るため、歩きやすい靴と服装をおすすめします。
- **水分補給**: 散策中は水分補給を忘れずに行いましょう。
- **時間管理**: 散策には時間がかかるため、余裕を持ったスケジュールを立てると良いでしょう。
このプランを参考に、伏見稲荷大社をゆっくりと楽しんでください!今回のファインチューニングでは、出力形式を以下のように指定をしました。
# {スポット名}
- 見どころ: …
- エリア: …
- ベストシーズン: …
《一言コメント》…学習データ数が少ないからか、出力形式は安定しませんでしたが、gpt-4o-mini-2024-07-18との違いはみて取れます。
ファインチューニングと他の方法の違い
ファインチューニングと混同しやすい学習方法・モデルがあるので、解説します。それぞれの違いを理解し上手に使い分けましょう。
ファインチューニングと転移学習の違い
事前学習済モデルを特定タスクに適用する方法として、ファインチューニングの他にも転移学習がよく用いられます。これら二つの手法は似て非なるものです。
ファインチューニングでは、事前に訓練されたモデルの一部または全体を新しいデータセットで追加学習します。一方で、転移学習は、訓練済みのモデルの出力層に新しい層を追加し、その層だけを新しいデータで追加学習する方法です。
主な違いは、追加学習する層と必要なデータ量です。
| ファインチューニング | 転移学習 | |
|---|---|---|
| 追加学習する層 | モデル全体または一部 | 新たに追加された出力層のみ |
| 必要なデータ量 | 転移学習より多い | 少ない |
これらの手法において、データ量が豊富であればファインチューニングが、データ量が少なければ転移学習が適しています。ファインチューニングと転移学習の違いについては、以下の画像が分かりやすいです。

上がファインチューニングの例で、下が転移学習の例です。
ファインチューニングでは、新たに追加した層に加えて、もともとあった層の一部も含めて追加学習しています。一方で、転移学習では、新たに追加した層だけを追加学習し、その他の層の既存パラメータは調整しません。
この転移学習のように、その他の層のパラメータを全くいじらないことを「凍結(フリーズ)」といいます。
ファインチューニングとプロンプトエンジニアリングの違い
ファインチューニングとプロンプトエンジニアリングの違いについても述べておきます。この2つは、両方とも事前学習済のモデルを特定のタスクに適用する方法ですが、そのアプローチには大きな違いがあります。
ファインチューニングは既に述べたように、事前に訓練されたモデルの一部または全体を、新しいデータセットで追加学習する手法です。このプロセスにより、モデルは新しいタスクやデータセットの特性に合わせて調整され、パフォーマンスが向上します。
一方で、プロンプトエンジニアリングは事前学習済モデルのパラメータは調整せず、入力データ(プロンプト)を工夫することで、特定のタスクに対するモデルの反応を最適化する方法です。このアプローチではモデル自体の再学習や調整は行わず、どのように入力を構成するか(例えば、質問の仕方や情報の提示方法)に焦点を当てます。
| ファインチューニング | プロンプトエンジニアリング | |
|---|---|---|
| 追加学習 | モデル全体または一部に行う | 行わない |
| モデルの調整 | 調整することによりパフォーマンスが向上 | 調整は行わず、入力の構成によりパフォーマンスを向上させる |
主な違いは、ファインチューニングがモデル自体を再学習するのに対し、プロンプトエンジニアリングではモデルの再学習を行わず入力データの工夫によってモデルの出力を最適化する点にあります。
ファインチューニングは「データ量が豊富で特定のタスクにモデルを特化させたい場合」に適しているのに対し、プロンプトエンジニアリングは「追加の学習リソースや時間が限られている状況」で効果的です。
ファインチューニングとインストラクションチューニングの違い
ファインチューニングとインストラクションチューニングは、どちらもパフォーマンスを向上させる学習方法ですが、用途は大きく異なります。ファインチューニングはこれまで解説してきた通り、解きたいタスクに応じたデータを追加で学習し、パラメータを微調整することが目的でした。
それに対して、インストラクションチューニングとは、何らかの指示が記述されたタスクを実行するようにファインチューニングすることを指します。
これは、ファインチューニングのように大規模なデータセットで特定のタスクの精度を上げることを目的としていません。代わりに、与えられた指示を理解し、従う能力を向上させ、様々なタスクを指示に基づいて実行するための汎用性を向上させることを目指します。
インストラクションチューニングを行うことで、入力されたプロンプトに従って、ユーザーの意図に密接に沿ったコンテンツや回答を生成することができます。
ファインチューニングとLoRAの違い
LoRA(Low-Rank Adaptation)はファインチューニング技術のひとつで、特に画像生成AIに用いられています。特徴として、少ない学習データでモデルの精度を向上できる、学習に必要なコストが低いなどがあります。自分の理想のイラスト生成が短時間かつ高精度で実現できます。
追加学習の計算量が少ないため、通常のファインチューニングに必要なパソコンよりも安価な低スペックのもので実行可能です。
特定の世界観を描写でき、ゲームの背景画像などの生成にも用いられています。生成する画像のイメージを写真風やアニメ風などで指定でき、マーケティング戦略に沿った画像を生成可能です。
ファインチューニングとRAGの違い
ファインチューニングとRAG(Retrieval-Augmented Generation)は、両方とも機械学習モデルの訓練方法ですが、その目的とアプローチには大きな違いがあります。ファインチューニング(Fine-tuning)は、特にニューラルネットワークモデルを特定のタスクやデータセットに適応させるために行われます。
既に事前学習を終えたモデルに特定の分野に関するデータセットを用いてチューニングし、特定のタスクに特化させる作業となります。ファインチューニングは、その特定の分野での回答精度を向上させることができます。
RAGは検索コンポーネントと生成コンポーネントを組み合わせた手法であり、質問に対する最新で詳細な回答を生成するのに役立ちます。
大規模な文書コレクションから関連する情報を検索し、その情報を元に回答を生成します。RAGは、特に大量の情報から適切な回答を生成する必要があるタスクに有効です。
RAGとファインチューニングは課題と目的が異なります。ですのでRAGはファインチューニングの代替手段ではなく、お互いが補完する関係にあります。
ファインチューニングとRAGの使い分け
ファインチューニングとRAGの違いがなんとなくわかったようなわからないような方が多いのではないでしょうか。
実際にファインチューニングとRAGを比較してみたいと思います。使用したデータは先ほどChatGPTに作成してもらった京都旅行に関するデータです。
まずはRAGに必要なコーパスを作成します。
サンプルコードはこちら。
import pandas as pd, json
from openai import OpenAI
SRC = "kyoto_spots.csv"
DST = "corpus.json"
EMBED_MODEL = "text-embedding-3-large"
def main():
client = OpenAI()
df = pd.read_csv(SRC)
corpus = []
for _, r in df.iterrows():
text = (
f"{r['name']}({r['area']}): {r['highlights']}。"
f"ベストシーズン:{r['best_season']}。備考:{r['notes']}。更新:{r['updated_at']}"
)
emb = client.embeddings.create(model=EMBED_MODEL, input=text).data[0].embedding
corpus.append({"id": r["name"], "text": text, "vec": emb})
with open(DST, "w") as f:
json.dump(corpus, f)
print("wrote", DST)
if __name__ == "__main__":
main()上記を実行すると「corpus.json」が出力されます。これを使ってファインチューニングとRAGの違いをみていきます。
両者比較のサンプルコードはこちら。
from openai import OpenAI
import json, time, numpy as np
from pathlib import Path
client = OpenAI()
BASE_MODEL = "gpt-4o-mini"
FT_MODEL = Path("ft_model_id.txt").read_text().strip()
EMBED_MODEL = "text-embedding-3-large"
CORPUS_PATH = Path("corpus.json")
PROMPTS = [
"雨の日におすすめの京都観光スポットを教えて",
"京都で初めての人に清水寺を200字以内で勧めて",
"混雑が少なめの時間帯で伏見稲荷大社を案内して",
]
def load_corpus():
data = json.loads(CORPUS_PATH.read_text())
M = np.array([d["vec"] for d in data], dtype=float)
return data, M
def retrieve(query, data, M, k=3):
qv = client.embeddings.create(model=EMBED_MODEL, input=query).data[0].embedding
qv = np.array(qv, dtype=float)
sims = (M @ qv) / (np.linalg.norm(M, axis=1) * np.linalg.norm(qv) + 1e-8)
idx = sims.argsort()[-k:][::-1]
return [data[i] for i in idx], sims[idx]
def ask_chat(model, messages, temperature=0.0):
t0 = time.time()
resp = client.chat.completions.create(
model=model, messages=messages, temperature=temperature
)
lat = time.time() - t0
out = resp.choices[0].message.content
usage = resp.usage
tokens = dict(
prompt_tokens=getattr(usage, "prompt_tokens", None),
completion_tokens=getattr(usage, "completion_tokens", None),
total_tokens=getattr(usage, "total_tokens", None),
)
return out, lat, tokens
def run_rag(query, k=3):
data, M = load_corpus()
topk, sims = retrieve(query, data, M, k=k)
context = "\n".join(f"- {t['text']}" for t in topk)
messages = [{
"role":"user",
"content": (
"あなたは旅行情報サイトです。以下のコンテキストに基づき、事実に忠実に200字以内で回答してください。\n"
f"【コンテキスト】\n{context}\n\n【質問】{query}"
)
}]
out, lat, tok = ask_chat(BASE_MODEL, messages, temperature=0.0)
sources = [t["id"] for t in topk]
return out, lat, tok, sources
def run_sft(query):
messages = [{"role": "user", "content": query}]
return ask_chat(FT_MODEL, messages, temperature=0.0)
if __name__ == "__main__":
assert CORPUS_PATH.exists(), "corpus.json がありません。先に build_corpus.py を実行してください。"
print(f"BASE_MODEL : {BASE_MODEL}")
print(f"SFT_MODEL : {FT_MODEL}\n")
for p in PROMPTS:
print("="*80)
print("PROMPT:", p)
rag_out, rag_lat, rag_tok, rag_src = run_rag(p, k=3)
sft_out, sft_lat, sft_tok = run_sft(p)
print("\n--- RAG (BASE + retrieval) ---")
print(rag_out)
print(f"[latency: {rag_lat:.2f}s tokens: {rag_tok} sources: {rag_src}]")
print("\n--- SFT (fine-tuned only) ---")
print(sft_out)
print(f"[latency: {sft_lat:.2f}s tokens: {sft_tok}]")
print()結果はこちら。
================================================================================
PROMPT: 雨の日におすすめの京都観光スポットを教えて
--- RAG (BASE + retrieval) ---
雨の日におすすめの京都観光スポットは、伏見稲荷大社です。千本鳥居をくぐりながら、しっとりとした雰囲気を楽しむことができます。また、夕方以降は比較的歩きやすく、観光客も少なくなるため、静かな時間を過ごせます。雨の日でも美しい景色を楽しめるスポットです。嵐山の竹林の小径も雨に濡れた竹が美しく、幻想的な雰囲気を醸し出しますが、午前中が特におすすめです。
[latency: 5.03s tokens: {'prompt_tokens': 226, 'completion_tokens': 141, 'total_tokens': 367} sources: ['嵐山', '祇園', '伏見稲荷大社']]
--- SFT (fine-tuned only) ---
雨の日におすすめの京都観光スポットはいくつかあります。以下のスポットは屋内で楽しめる場所が多いので、雨の日でも快適に観光できます。
1. **京都国立博物館**: 日本の歴史や文化に関する展示が豊富で、特に平安時代の美術品が見どころです。
2. **錦市場**: 観光客に人気の食材市場で、屋根があるため雨の日でも歩きやすい。
3. **南禅寺**: 大きな水路閣が有名で、比較的歩きやすい。
4. **金閣寺**: 雨の日でも美しい景色が楽しめる。
5. **嵐山**: 午前中に竹林の小径が撮りやすい
[latency: 5.80s tokens: {'prompt_tokens': 20, 'completion_tokens': 194, 'total_tokens': 214}]
================================================================================
PROMPT: 京都で初めての人に清水寺を200字以内で勧めて
--- RAG (BASE + retrieval) ---
清水寺は京都の東山に位置し、特に春と秋に訪れるのがベストです。清水の舞台からの眺望は圧巻で、夜間のライトアップも美しいです。朝早めに訪れると、混雑を避けてゆっくりと楽しむことができます。清水寺の周辺には、歴史的な雰囲気が漂う街並みや、他の観光スポットも点在しているため、散策にも最適です。初めての京都旅行には欠かせないスポットですので、ぜひ訪れてみてください。
[latency: 3.63s tokens: {'prompt_tokens': 223, 'completion_tokens': 144, 'total_tokens': 367} sources: ['清水寺', '祇園', '嵐山']]
--- SFT (fine-tuned only) ---
清水寺は京都を代表する観光名所で、特に春の桜と秋の紅葉が美しい。朝早めが空いている。清水の舞台からの景色が絶景。夜間ライトアップも。
[latency: 4.49s tokens: {'prompt_tokens': 27, 'completion_tokens': 56, 'total_tokens': 83}]
================================================================================
PROMPT: 混雑が少なめの時間帯で伏見稲荷大社を案内して
--- RAG (BASE + retrieval) ---
伏見稲荷大社を訪れる際、混雑が少なめの時間帯は夕方以降がおすすめです。この時間帯は、千本鳥居をゆっくりと楽しむことができ、稲荷山ハイクも比較的歩きやすくなります。通年を通して訪れることができるため、季節を問わず美しい景色を堪能できます。特に夕暮れ時の鳥居は幻想的な雰囲気を醸し出し、写真撮影にも最適です。ぜひ、夕方の訪問を検討してみてください。
[latency: 2.99s tokens: {'prompt_tokens': 234, 'completion_tokens': 143, 'total_tokens': 377} sources: ['伏見稲荷大社', '祇園', '嵐山']]
--- SFT (fine-tuned only) ---
伏見稲荷大社は、夕方以降は比較的歩きやすい
午前中は比較的空いている
[latency: 0.73s tokens: {'prompt_tokens': 28, 'completion_tokens': 31, 'total_tokens': 59}]こうやって比較してみると違いが明確かと思います。
ファインチューニングの結果には、学習データに含まれた言い回し、要点、簡潔さが反映されています。一方、RAGの結果は情報量が多く、汎用的な観光情報が多く含まれる傾向があります。また、RAGでは出力ごとに文体のばらつきが生じやすいです。
さて、上記の結果を踏まえ、ファインチューニングとRAGは下記のように使い分けるのが良いでしょう。
ファインチューニング
- 目的:口調・フォーマット・出力様式を固定し、特定タスクに最適化
- 更新性:内容更新には再学習が必要
- 知識:学習時点に固定(網羅性・鮮度は限定的)
- コスト:初期学習コストあり/推論は軽め
- 向き:定型文量産、FAQ、テンプレ厳守の文章生成
RAG
- 目的:最新情報・大量知識を都度検索して注入
- 更新性:データ差し替えで即時反映(再学習不要)
- 知識:根拠付きで広範囲に対応(鮮度を保ちやすい)
- コスト:埋め込み作成+毎回のコンテキスト分で増えがち
- 向き:変化が速い領域、調査・比較、長文の要約・引用
なお、ファインチューニングとRAGとの違いについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

ファインチューニングのメリット

ファインチューニングを行うことには、当然メリットが存在します。ここでは、ファインチューニングのメリットについて詳しく解説します。
独自の環境を構築できる
利用する側にとって一番のメリットは、社内の業務やサービスに特化した独自の環境を構築できることです。

例えば、社内データを用いてGPTモデルをファインチューニングしたとします。
すると元々のChatGPTの会話能力を受け継ぎながら社内データについて知識を身に着けることになります。これによって社内業務用のChatGPT環境となるわけです。
回答精度が向上する
ファインチューニングは、既存のモデルが持っている豊富な知識を活用しながら、特定分野の回答精度を向上させます。プロンプトよりも多くの例文で学習しているため、モデルが理想通りに回答する能力が向上することを意味しています。
コスト削減
ファインチューニングは、特定の分野におけるタスクに対して同じモデルを使用することを可能にします。これにより、モデルの再利用性が向上し、開発時間とリソースが節約できます。
さらに、プロンプトで多くの例文を提示する必要がなくなります。結果、プロンプトの短縮によりトークン数(コスト)の節約や例文提示の手間を削減することができます。
ファインチューニングのデメリット
ファインチューニングにはデメリットも存在します。把握しておかないと思わぬトラブルの原因になりかねないので、ここでしっかり理解しておきましょう。
学習に必要なデータ量と品質の要求が高い
ファインチューニングでは、モデルを特定のタスクや環境に適応させるために、大量かつ高品質の学習データが必要になります。十分な量のデータがない場合やデータの品質に問題がある場合、モデルの性能は最適なものにならない可能性があります。
過学習(オーバーフィッティング)のリスク
限られたデータセットに対してファインチューニングを行うと、モデルがその特定のデータセットに過剰に適応してしまうことがあります。これは「過学習」と呼ばれ、モデルが新しいデータや異なるタスクに対して汎化する能力が低下する原因となります。
リソースと計算コストが高い
ファインチューニングは計算資源を多く消費する作業です。特に大規模なモデルの場合、追加の学習には高い計算能力が必要となり、それに伴ってコストも増加します。
メンテナンスとアップデートの必要性
一度ファインチューニングされたモデルも、時間が経つと性能を低下させる可能性があります。このため、定期的なメンテナンスやアップデートが必要になり、これには追加の時間とリソースが必要です。
ファインチューニングの活用事例

ファインチューニングを行うとどのようなことができるのでしょうか。実際に生成AIにファインチューニングを行った事例を見てみましょう。
事例①音声合成
5秒程度の短い音声サンプルからリアルな声を生成できるGPT-SoVITSのようなモデルも、少量データでのファインチューニングに対応しています。
音声データと文字起こしテキストを学習させることで、「特定の話し方・抑揚を持つナレーションボイス」を再現でき、ゲームや動画コンテンツの制作現場でも活用が進んでいます。
一方で、音声クローン技術は 権利侵害やなりすまし に悪用されるリスクも指摘されています。
「本人の同意なく有名人の声をコピーする」「家族や同僚の声を無断で学習データに使い、外部に公開する」
といった行為は、著作権・パブリシティ権・肖像権の侵害や、詐欺行為につながるおそれがあります。実務で音声合成モデルをファインチューニングする場合は、「必ず事前に本人の明示的な同意を得ること」、「利用目的(社内利用のみ/商用配信など)を契約・規定に明記すること」、「プラットフォームや国ごとの法規制・ガイドラインを確認すること」といったガバナンスを徹底したうえで、「社内アナウンサー」「自社キャラクター」「許諾済み声優」といった安全なデータだけを使うのが現実的な運用です。
事例②商品説明
店舗で商品の購入を検討しているとき、店員商品の詳細を質問することがあります。しかし、商品に詳しい店員が不在の時も少なくありません。
商品についての情報をファインチューニングした生成AIがあれば、商品の具体的な回答を自動で行ってくれます。人手不足の店舗や無人の販売店などでも、詳しい商品の説明が可能となるでしょう。
事例③画像生成
生成AIで画像を生成する際に、特定のイラストのスタイルに寄せたり、特定のキャラクターや人物のイラストを生成することは困難です。
しかし、自分が生成したい画像に似た画像データでファインチューニングを行えば、同じテイストのキャラクターや人物のイラストを生成することが可能となります。
事例④チャットボットの精度向上
GPTなどのLLMは人間同士の会話のような自然な文章を生成できるため、さまざまな企業活動に活用できます。社内では、ファインチューニングで社内情報を学習させておけば、従業員はチャットボットに質問するだけで簡単に情報を入手できるでしょう。
顧客向けには、製品やサービスに対する顧客からの質問に答えるカスタマーチャットボットの精度向上が期待できます。これまでのチャットボットでは性能不足から顧客の質問に満足に答えられず、電話やメールでの問い合わせが必要になることもありました。
ファインチューニングで製品やサービスの詳細情報、過去の問い合わせや回答内容などを追加学習させることで精度の高い回答を24時間迅速に提供できます。
事例⑤文書生成
企業活動の中では、日々さまざまな種類の文書を作成しています。その中には定型文書も多く、人間が作成すると時間と労力が必要で、ミスも発生します。生成AIモデルをファインチューニングして過去に作成した定型文を学習させると、文章の自動生成も可能になります。
生成AIの文章生成は言語にとらわれず、多言語への翻訳も得意です。グローバル化が進む企業活動では、各国の法規制に応じた輸出入関連文書の作成など幅広い業務での効率化が競争力強化に役立ちます。
ChatGPTファインチューニングの料金
ChatGPTを使って自社の業務を効率化したいと考えるとき、経営層から必ず聞かれるのが「ファインチューニングにはいくらかかるのか?」という質問だと思います。
ここでは、2025年11月時点の OpenAI 公式情報をもとに、ざっくりとした試算方法を整理します。
料金は「学習時」と「利用時」の2段構えで、OpenAI のファインチューニング料金は、大きく分けて次の2つで決まります。
| 項目 | 料金 |
|---|---|
| トレーニングコスト | 入力トークン数 × エポック数 × 「100万トークンあたりのトレーニング単価」 |
| 推論(利用)コスト | 完成したモデルを API で呼び出すときの入力/出力トークン数 × ベースモデルの単価 |
ファインチューニングの注意点
ファインチューニングの注意点として、以下の2点が挙げられます。利用するときは、ここで解説するポイントに注意しましょう。
適切なデータセットの準備
ファインチューニングを行う際には、タスクに適したデータセットを用意することが重要です。データセットがタスクに適していないと、モデルの性能が低下する可能性があります。
このデータセットの準備は、内容によっては非常に手間がかかります。学習率も適切に設定してデータセットを準備しないといけません。学習率が高すぎると過学習を起こしてしまいます。
コストがかかる
ChatGPTのモデルをファインチューニングする際は、モデルの利用時だけでなく学習にも費用が必要です。学習させるデータ量が多いほど精度も高くなると期待できますが、コストも高くなります。
無暗に多量の学習データをアップロードせず、あらかじめどの程度の費用がかかるか見積った上で利用しましょう。
なお、GPT-4oのファインチューニングについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

ファインチューニングは特定タスクの効率化につながる
ファインチューニングは、大量のデータで事前学習されたモデルに対して、特定のタスクに適したデータを追加学習し、モデルのパラメータを微調整する手法です。ChatGPTにおいても、ファインチューニングは、特定のタスクにおいてパフォーマンスを向上させるために行われます。
転移学習は新しい層だけを追加学習するのに対し、ファインチューニングはモデル全体または一部を追加学習します。データ量が豊富な場合はファインチューニング、少ない場合は転移学習が適しています。
自社の業務に特化したファインチューニングを実施することにより、既存業務の効率化が可能です。また、時間を問わず顧客からの対応に迅速に回答できるなど、顧客満足度の向上にもつながるでしょう。
2025年時点では、GPT-4.1系モデルやo4-mini、各種RAGソリューションなど、LLMを業務に組み込むための選択肢が大きく広がっています。
まずはプロンプト設計+RAG で素早くPoCを行って、価値が確認できたタスクに対して ファインチューニングで型を固める。
という二段階アプローチをとることで、初期コストを抑えつつ、高い再現性と生産性を両立しやすくなると思います。
自社の業務フローやデータの特性を踏まえ、「どのタスクをファインチューニングするのか」「どこまで RAG でやるのか」を整理していくことが、生成AI活用プロジェクト成功の鍵と言えるでしょう。

最後に
いかがだったでしょうか?
生成AIのファインチューニングを駆使すれば、自社に最適なAIモデルを構築できます。ビジネス目標に応じたカスタマイズの可能性を探り、他社にない競争力を手に入れましょう。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。
- ※1:ファインチューニング用の訓練データの作成方法
- ※2:OpenAI Platform
- ※3:Estimate costs(OpenAI)


