
生成AI向けデータセットの完全ガイド!種類や作り方、オープンデータ19選を解説

近年では様々な分野でAIが活用されていますが、生成AIの登場により利用度は加速度的に上昇しています。「AIだからこそできること」も増加してきました。生成AIによる新たな事業のため、機械学習モデルの構築を考える企業も多いでしょう。
しかし、生成AIモデルの構築には学習させるためのデータセットが欠かせません。学習データによって生成AIモデルが構築されるため、「データがどのように動くのか」を理解していくことが大切となってきます。
今回は生成AIの学習モデルを構築するのに欠かせないデータセットについて、その種類や作り方について詳しく解説していきます。
また、データセットの作成に活用できるオープンデータのサイトもご紹介しますので、最後までお読みください。
\生成AIを活用して業務プロセスを自動化/
生成AIに欠かせないデータセットの種類3選
生成AIはまとまったデータを基にして、決められた法則に基づいて学習、予測や推論を行って精錬されていきます。この、まとまったデータを「データセット」と言います。
データセットの内容は、画像・音声・言語処理など分析したいデータによってさまざまです。内容が質・量ともに優良であれば、生成AIの精度が高まり汎用的となります。これから、3つのデータセットについて詳しく解説しますので、参考にしてください!
アルゴリズムに命を吹き込む「トレーニングセット / 学習データ」
トレーニングセットは、生成AIを構築するために最初に用いられる学習用のデータセットです。このデータを用いて、AIは様々な学習方法で知識を得ます。
- 「教師あり学習」では、正しい答えがわかるデータを読み込ませ、AIがそれに基づいて正しい結果を出せるようにします。
- 「教師なし学習」は、正解が示されてないデータを使い、AI自身がデータの中からパターンや関連性を見つけ出し、答えを導き出します。
- 「強化学習」では、特定の結果に対して最適な行動をAIが自ら学び取る方法です。
これらの基本学習後、AIはさらなる精度向上のために、ファインチューニングを行います。ここでは、新たなデータセットを使って、すでに学んだことを調整し精度を高めて行きます。
パラメーターの調整に用いる「バリデーションセット / 検証データ」
バリデーションセットは、生成AIのモデルをトレーニングセットで訓練した後、「ハイパーパラメーター」をチューニングするために利用するデータセットです。
推論や予測の枠組みの中で決定されず、手動で設定しなければいけないパラメータ(層数・ユニット数・最適化手法など)を調整するための検証用データです。
バリデーションセットを利用し、パフォーマンスが優秀なものを選択します。
精度測定に用いる「テストセット /テストデータ」
テストセットとは、トレーニングセットやバリデーションセットにて構築した生成AIモデルの性能を最終的に検証するために使用するデータセットです。
パフォーマンスを確かめるために使用するデータのため、当然今までに使用したデータセットとは別なものを使用します。
なお、生成AI開発のベストな環境の作り方について詳しく知りたい方は、下記の記事を合わせてご確認ください。

続きを読む
生成AI用データセットの入手方法は?
生成AIを構築するためのデータセットを入手する方法は、3つの方法が挙げられます。
- 「オープンデータセット」を利用する
インターネット上で公開されており、気軽に活用することができます。オープンデータのみを活用して、優位性のあるAIを構築するのは現実的ではありません。また、データ使用に費用が掛かったり、商用利用ができなかったりする場合もあります。
- 「独自で集めたデータ」を用いる
調査などを利用して独自で集めることで収集した場合、費用を抑えられるのとデータに独自性が生まれます。
- 「アノテーションサービス」を利用する
ビッグデータをアノテーションすることで、ラベルごとの目的を絞って学習させることができます。
弊社の生成AIツールの開発を例としますと、下表のプロトタイプ開発においてデータクレンジングによってアノテーションされたデータを用いて学習させることで、目的に応じた生成AIを作成しております。
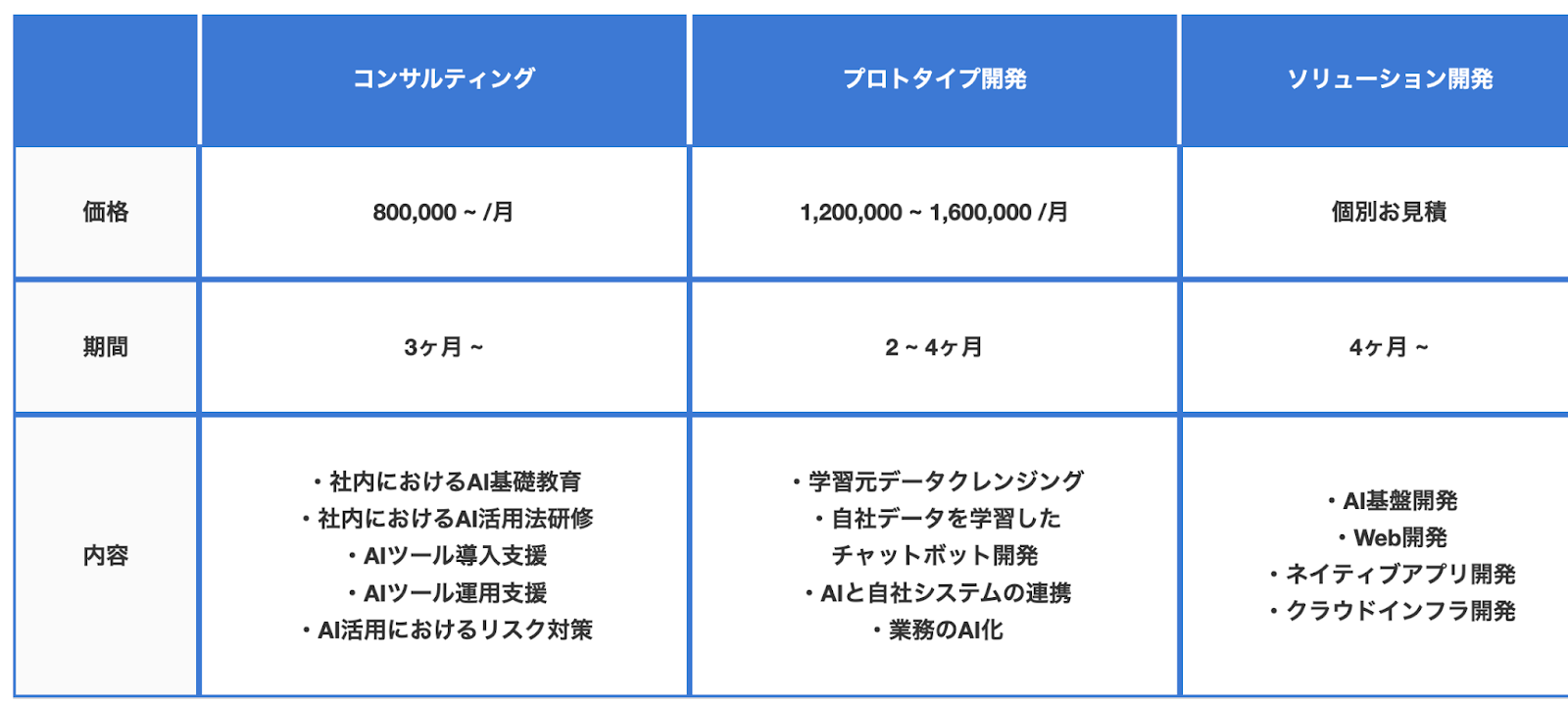


生成AI用データセットの作り方
実際に生成AI用のデータセットを作成する場合、どのような方法で作成していけばいいのでしょうか。生成AI向けのデータセットの作り方はデータのタイプ(画像、動画、音声、データなど)によって様々です。
ここでは、生成AI用データセットの作り方を順序だてて紹介していきます。
作りたい生成AIについて目標を決める
初めに適切なデータセットを用意するために生成AIで行いたい課題・解決したい項目について、実施する目的を決定しましょう。曖昧な「AIを導入して作業を効率化する」を主目的とするのは良くありません。
例えば「会議や会合、打合せの音声データから報告書の形式でまとめて提出できる形にする」など具体的な目標を設定することが重要です。これによってどのようなデータセットを準備すべきかが明確となります。
各データを収集する
目的が明確化されたら、それに向けた生成AI用のデータの収集作業になります。
AIはこの教師データの「質」と「量」が大きな影響を与えますので、これを高めていくことでAIモデルの精度を向上させることが可能です。生成AIはデータに適応して行くことになりますのでデータが少ないと、オーバーフィッティングを起こしてしまうことになります。
必要量は目的によって大きく異なりますが、顔認識等画像ですと10〜20万枚、文章ですとおおよそ最低10万程度は必要です。
データクレンジング
データクレンジングとは、データベースに保存されている各種データを参照し、誤記、重複などの修正や削除を行うことです。収集したデータごとに異なるやり方でデータ入力が行われていたりするため、それを統一する作業にもなります。
データクレンジングを行うことで、データは整理・標準化され、スムーズに使用できます。
アノテーション
膨大なビッグデータにタグ付けを行う事をアノテーションと言います。
生成AIの学習・利用において極めて重要な前処理であり、アノテーションによってデータを分類したりパターン化することによって、ビッグデータを効率的に管理することが可能です。
なお、生成AIツールの開発について知りたい方はこちらをご覧ください。

良質な生成AI用データセットを作るためのポイント5つ
生成AI開発には利用するデータセットが非常に重要な役割を持ちます。自分が実現するべき対象を作成するために、必要なデータを理解することで理想的な生成AIを作成可能です。
そこで、良質な生成AI用データセットのためのポイントを5つ紹介いたします。
被覆性のあるデータセットを目指す
生成AIのシステムが要求される動作範囲の様々な状況に対して、データの量が十分であること・データに偏りがなく網羅的であることが必要となります。これを「データセットの被覆性」といい、これによって十分にリスクに対応した学習ができることが担保されます。
データが不足すると適切に推論することができなくなります。そのため、使用する生成AIに対してどのようなデータが必要なのか検討し、網羅的にデータを収集しましょう。
均一性のあるデータセットを目指す
使用データの分布が、実際のデータ集団の分布に近いかというのも重要です。
全体として偏りなく均一にデータが含まれていることを確認しましょう。それによって、モデルの全体性能を向上させることになります。
これは上記の「データセットの被覆性」と対になるもので、稀なものも網羅しつつバランスを整えるとなると、当然データ集団は非常に大きいものが求められます。
データセットのバイアスを除く
データセットを選択・利用する際に、収集されるデータにバイアスがかからないように留意する必要があります。例えば、元々のデータセットが男性に偏りがあるもので、作成した生成AIに女性のデータを利用すると正しい結果が表れない可能性があるといったものです。バイアスとしてはサンプリング時・重要でないデータを除外する際、測定する際の偏りなどが挙げられます。
データセットのノイズを除く
収集したデータからはノイズを除去する必要があります。
ノイズは、測定誤差やデータの入力エラーなどさまざまな要因によって発生する可能性があり、生成AIのモデル訓練に悪影響を与えることがあります。
ノイズ除去をすることによって、信頼性の高いデータを取得し、モデルのパフォーマンスを向上させることが可能です。
データセットの著作権を明らかにしておく
データセットを用いる際には、著作権は気になる部分です。
2023年11月現在、日本の著作権法においては、生成AIの学習のために第三者が著作権を持つデータを元に学習させ、学習済みモデルを公開しても問題ないとなっています。
要は、AI開発・学習段階での利用はOKという事です。
ただし、生成されたものに関しては、当然他の作成物同様著作権は関係してきますし、「類似性」と「依拠性」による判断がなされることになります。
オープンデータセットを提供しているWebサイト19選
近年では、さまざまなデータがオープンに公開されており、基本的に無料で気軽に活用できます。(データ使用に費用が掛かったり、商用利用ができなかったりする場合もあります。)
オープンデータセットのみで生成AIの構築を行うことは、優位性の観点からも現実的ではありません。しかし、独自のデータセットと組み合わせることで、独自のAIを構築していくことは可能です。
そこで、オープンデータセットを提供しているwebサイトを以下の6つのカテゴリに分けてご紹介します。
生成AI開発に役立つものを厳選していますので、ぜひ参考にしてください。
- 画像
- 動画
- 音声
- テキスト
- データセット検索
- その他
画像データセット
MargeFace
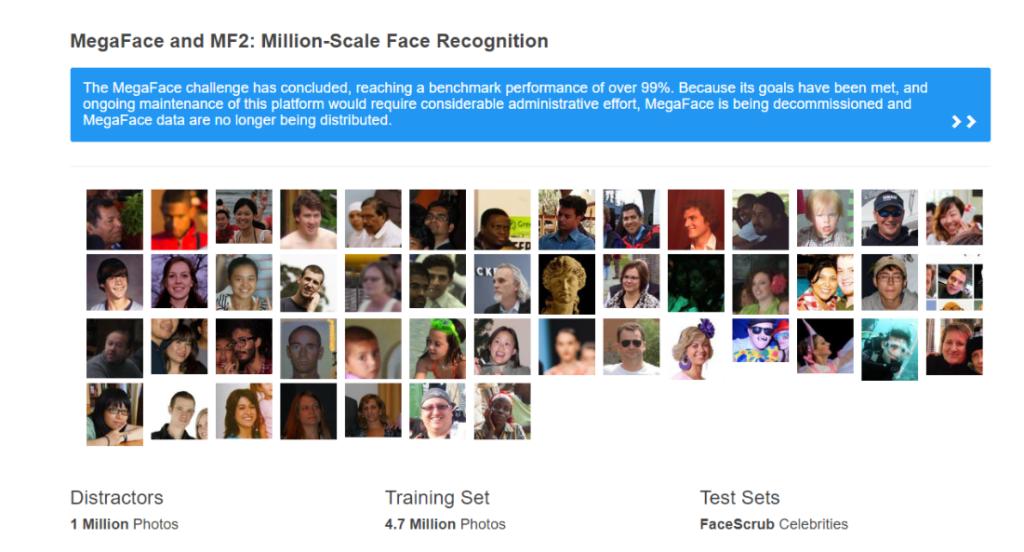
MegaFaceは、アメリカのワシントン大学で行われている顔認識アルゴリズムの公開競技で用いられている、ノイズデータを混ぜた顔認識の大規模なデータセットです。
Pascal VOC Dataset

Pascal VOC Datasetは、オブジェクトクラス認識用の標準化された画像データセットです。「データセット」「注釈にアクセスするためのツール」の2つがセットで提供されています。
Open Images Dataset V7
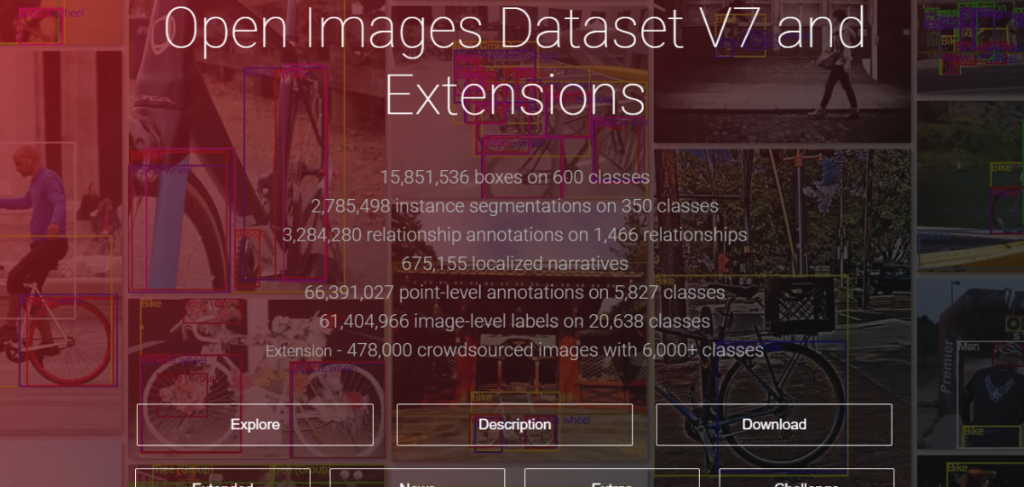
Open Images Dataset V7は、Googleが提供しているデータセットです。約900万枚の画像データに対して、「画像レベルのラベル」「オブジェクトの境界ボックス」「オブジェクトのセグメンテーションマスク」「視覚的関係」「ポイントラベル注釈」がアノテーションされています。
動画データセット
YouTube-8M Dataset
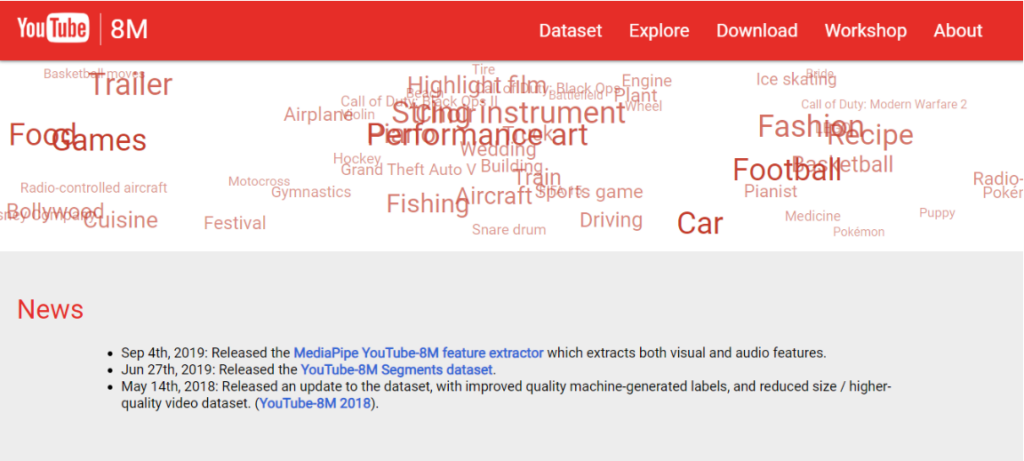
YouTube-8M Datasetは、Google研究チームが提供する動画用データセットです。タグ付けされた800万本ものYouTube動画が公開されており、人間が検証したラベル付け動画が利用できます。
Kinetics

Kineticsは、Google系AI企業として知名度を誇るDeep Mindが公開しているデータセットです。65万件の動画のデータセットが公開されています。
BDD100K
BDD100Kは、カリフォルニア大学のAIラボが公開する自動運転向けの動画データセットです。道路オブジェクトのバウンディングボックス、運転可能領域、車線のマーキングなどのラベルが付与されています。
音声データセット
AudioSet
AudioSetは、Googleが提供しているデータセットです。人間の声や動物の鳴き声、楽器の音などラベル付きの音声データが公開されています。
Mozilla Common Voice
Mozilla Common Voiceは、Mozillaが展開する「Common Voice」という音声データセット収集プロジェクトの中から、42,000貢献者、18言語、約1,400時間の音声データが公開されているデータセットです。
日本声優統計学会
日本声優統計学会が提供するオープンデータセットです。プロの声優による独自に構築した音声データが公開されています。
テキストデータセット
自然言語処理のためのリソース
「自然言語処理のためのリソース」は、京都大学の黒橋・河原・村脇研究室が提供しているオープンソース・データセットです。自然言語処理用のツールやデータセットの情報が公開されています。
日本語対訳データ
「日本語対訳データ」では、機械翻訳システムの構築に利用できる対訳コーパスや、対訳辞書などが公開されています。
Twitter日本語評判分析データセット
「Twitter日本語評判分析データセット」は、岐阜大学の研究室が提供しているデータセットです。ツイートの評判情報をクラウドソーシングによって分析した結果が公開されています。
データセット検索
Google Dataset Search
Google Dataset Searchは、Googleが2020年にリリースしたデータセット検索サービスです。世界中のデータセットを名前から検索することができます。ハーバード大学やWHOなどの国際機関のデータも含まれています。
Kaggle
Kaggleは、世界中の機械学習を学ぶ人のためのプラットフォームです。スポーツ、医療、政府など様々なトピックをカバーする、オンラインで利用可能な最大級のデータセットライブラリーを有しています。
Appen
Appenは、AI学習データで業界をリードするAppenが提供しているデータセットライブラリーです。画像、音声、動画、発音など幅広いアノテーション済みデータセットを公開しています。ユーザー要件に個別に対応したデータ作成も可能です。
e-GOV
e-GOVは、行政機関が保有し公開しているオープンデータを、個人や企業などの利用者が検索、活用するためのWebポータルサイトです。行政機関が保有している各種公共データセットを検索・ダウンロードし活用することができます。
その他のデータセット
Nasdaq Data Link
Nasdaq Data Link(旧Quandl)は、投資家が世界中の金融や経済データにアクセスできるデータセットを提供しているサイトです。金融や経済関連のデータセットを公開しており、世界各国の財務情報を利用できます。
都立大自然言語処理研究室
「都立大自然言語処理研究室」は、東京都立大学自然言語処理研究室(小町研)が提供するコーパス・辞書・評価データセットです。AI開発に役立つ国内向けのデータセットが多数公開されています。
e-Stat

e-Statは、政府統計の総合窓口が提供している政府統計ポータルサイトです。日本に関するあらゆる統計データが公開されています。
なお、データセットに付随する著作権問題について知りたい方はこちらをご覧ください。

生成AIの開発でデータがない場合は
弊社では、データを作るところからサポートしています。
- 目標を決定する:生成AIで実現したい課題や解決したい問題を明確にします。具体的な目標設定が、適切なデータセットの準備へと繋がります。
- データ収集:目標に沿ったデータを、オープンデータセットや独自調査を通じて収集します。質と量を確保しデータの多様性を意識することが重要です。
- データクレンジング:収集したデータから誤記や重複などの不要な情報を除去し、整理・標準化を行います。そのため、効率的な学習が可能になります。
- アノテーション:データにタグ付けを行い、分類やパターン化を通じてデータセットを整理します。
データがない場合でも、目標設定からデータ収集・整理・アノテーションというステップを踏むことで、有用なデータセットを作り上げることが可能です。
なお、生成AIの開発コストを下げる方法について詳しく知りたい方は、下記の記事を合わせてご確認ください。

データセットを作成して生成AIを開発しよう!
生成AI用のデータセットの意味や役割、作り方などを説明しました。データセットは学習モデルにおいて、命ともいえる部分という事がご理解いただけたと思います。
良質なデータセットの作成は、精度の高い生成AIモデルを構築する上で欠かせません。特に、データセットを作る際には、著作権を明らかにしておく必要があります。データセットの入手方法は複数ありますので、目的・規模に合わせて比較検討するのがおすすめです。
また、記事内でご紹介したように、無料で気軽に使えるオープンデータもたくさんあります。独自で収集・作成したデータと組み合わせることで、生成AI開発がより効率的に行えるので、ぜひ参考にしてください。
データセットが準備できたら、実際に生成AI開発に活用してみましょう!

最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

