
T5Gemma 2とは?エンコーダー・デコーダ構造で進化したマルチモーダルLLMを解説

- エンコーダー・デコーダー型を基盤に、マルチモーダルとロングコンテキストへ拡張したモデル設計
- 効率性を重視した設計により、コンパクトなサイズでも高い表現力を実現
- 事前学習モデルとして提供され、用途に応じたpost-training前提の柔軟な活用が可能
2025年12月、Googleから新たなモデルが公開されました!
今回リリースされた「T5Gemma 2」はGemma 3をベースに開発されたエンコーダー・デコーダーモデル。
本記事ではT5Gemma 2の概要から仕組み、実際の実装方法について解説をします。本記事を最後までお読みいただければ、T5Gemma 2の理解が深まり、ご自分で実装することが可能です!
ぜひ最後までお読みください!
\生成AIを活用して業務プロセスを自動化/
T5Gemma 2の概要
T5Gemma 2は、Gemma 3をベースにしたエンコーダー・デコーダーモデル。
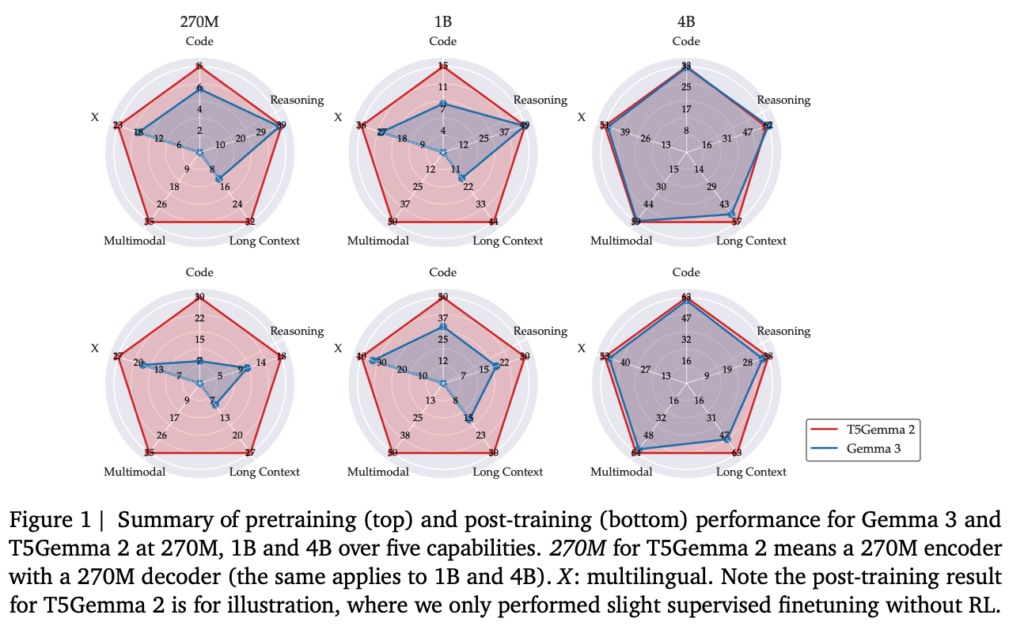
単なる再学習ではなく、アーキテクチャ面でも大きな変更が加えられました。特に「マルチモーダル」と「ロングコンテキスト」をエンコーダー・デコーダーで扱える点が新しさという特徴。画像とテキストを同じ枠組みで処理でき、視覚的な質問応答やマルチモーダル推論にもつながります。
もう1つ押さえたいのが、オンデバイス利用を見据えたコンパクトさです。
モデルサイズは270M-270M(合計約370M、vision encoderを除く)、1B-1B(合計約1.7B)、4B-4B(合計約7B)が用意されています。
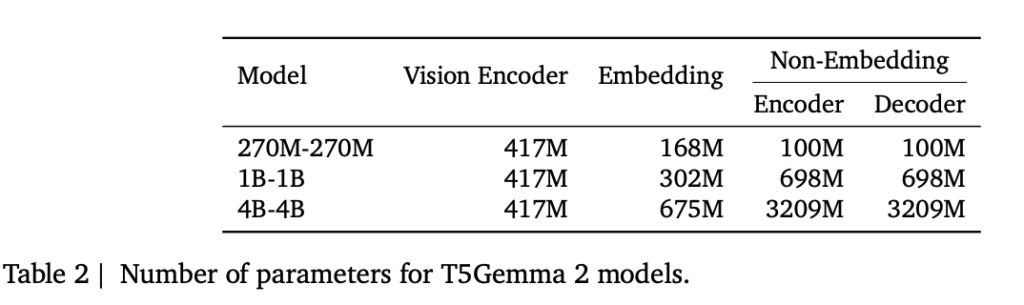
エンコーダーとデコーダーの埋め込みを共有するtied embeddingsや、デコーダー側でself/cross attentionを統合するmerged attentionを採用しており、この設計により、同じメモリフットプリントでも機能を詰め込みやすくなると考えられます。
小さなスケールで効率を最大化するという狙いがポイント。
背景として、初代T5Gemmaでは「decoder-onlyモデルをエンコーダー・デコーダーへ適応する」アプローチが示されました。T5Gemma 2では、その延長としてGemma 3の要素を取り込み、視覚と言語の領域へ拡張する方向性が示されました。
今後、特定タスク向けにpost-trainingしてから使う前提の「pre-trained checkpoints」が提供されている点にも注目です。
LLMとエンコーダー・デコーダーモデルの違い
LLMは「Large Language Model」の略称であり、大規模データを用いて学習された言語モデル全般を指す総称。自然言語の理解や生成ができる点が共通項であり、内部構造やアーキテクチャは定義に含まれません。
一方、エンコーダー・デコーダモデルは、LLMの中でも特定の構造を持つモデルタイプ。入力を理解するエンコーダーと、出力を生成するデコーダーを明確に分離した二段階構造が特徴です。
現在広く利用されているLLMの多くは、デコーダのみで構成される方式を採用しています。GPTやGemini、Claudeなどは、入力と生成を単一のデコーダで処理する代表例です。
これに対してエンコーダー・デコーダ方式では、入力内容を一度構造的に理解した上で出力生成を行う点が異なります。この構造上の違いにより、エンコーダー・デコーダモデルは「入力を変換して結果を出す」タスクに強みを持ちます。
翻訳や要約、質問応答、さらには画像から文章を生成するような処理との相性が良いとされています。
なお、Googleが発表した世界最大規模の差分プライバシー付きLLMであるVaultGemmaについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

T5Gemma 2の仕組み
ここからは、T5Gemma 2がどのような構造で動作しているのかを解説します。
エンコーダー・デコーダー構造の基本
T5Gemma 2は、入力を理解するエンコーダーと、出力を生成するデコーダーから構成されます。エンコーダーではテキストや画像情報を高次元の表現へ変換し、意味情報を圧縮しました。
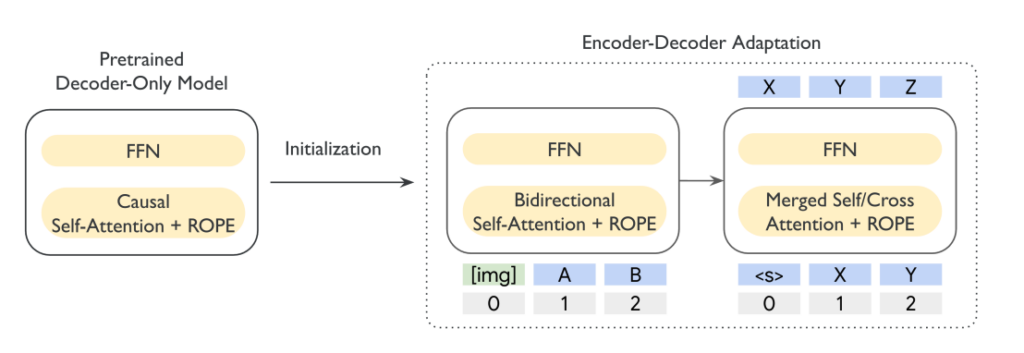
その表現を受け取ったデコーダーが、目的に応じたテキスト出力を段階的に生成します。この分業構造により、入力理解と生成を明確に分離できます。その結果、長文処理や条件付き生成に向いた設計と言えるでしょう。
マルチモーダル処理の流れ
T5Gemma 2では、テキストだけでなく画像入力にも対応しています。画像は専用のビジョンエンコーダーで処理され、トークンへ変換。その後、テキストトークンと同様にエンコーダー側で統合されます。
この設計により、視覚情報と自然言語を同じ推論空間で結び付けることが可能となり、視覚的質問応答や画像理解タスクへの応用が期待されます。
効率化のための設計上の工夫
内部構造では、エンコーダーとデコーダーで埋め込みを共有するtied embeddingsを採用。これにより、パラメータ数を抑えつつ一貫した表現空間を維持できました。
また、デコーダー側ではself attentionとcross attentionを統合するmerged attentionが使われています。これによって、推論時の計算効率が改善されます。


T5Gemma 2の特徴
ここでは、T5Gemma 2が持つ主な特徴を解説します。T5Gemma 2は単なる性能向上にとどまらず、設計自体に変化が見られます。
マルチモーダル対応による表現力の拡張
T5Gemma 2の大きな特徴として、テキストと画像を同時に扱える点が挙げられます。ビジョンエンコーダーを通じて画像情報をトークン化し、言語情報と統合する仕組みを採用。
これにより、画像内容を踏まえた質問応答や説明生成が可能になります。従来のテキスト専用モデルでは難しかったタスク領域への拡張が期待されるでしょう。
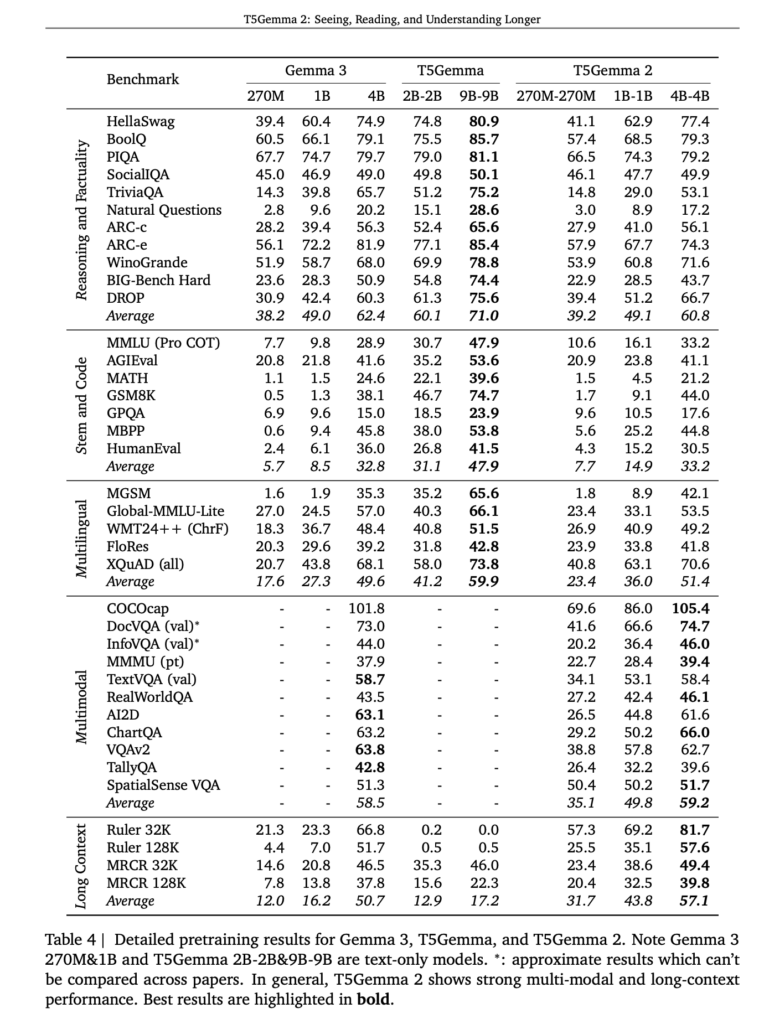
上記はT5Gemma 2の事前学習段階における性能を示したベンチマーク結果。
指示チューニングや強化学習といった追加調整を行う前の状態で評価されているため、モデル構造そのものの特性が反映されています。マルチモーダル系ベンチマークに注目すると、T5Gemma 2はDocVQAやTextVQA、MMMUなどで一貫した性能を示しています。
ロングコンテキスト処理への対応
T5Gemma 2は、長い文脈を扱える点も特徴の1つ。エンコーダー側で入力全体をまとめて表現できるため、長文の理解に向いています。その結果、複数段落にまたがる要約や指示理解でも安定した出力が可能。
情報を一度に把握した上で生成できる点は、業務用途でも重要なポイントであり、特にドキュメント処理との相性が良い構造と考えられます。
事前学習モデルとしての位置付け
下記の図はT5Gemma 2に軽量なpost-trainingのみを施した後の性能です。
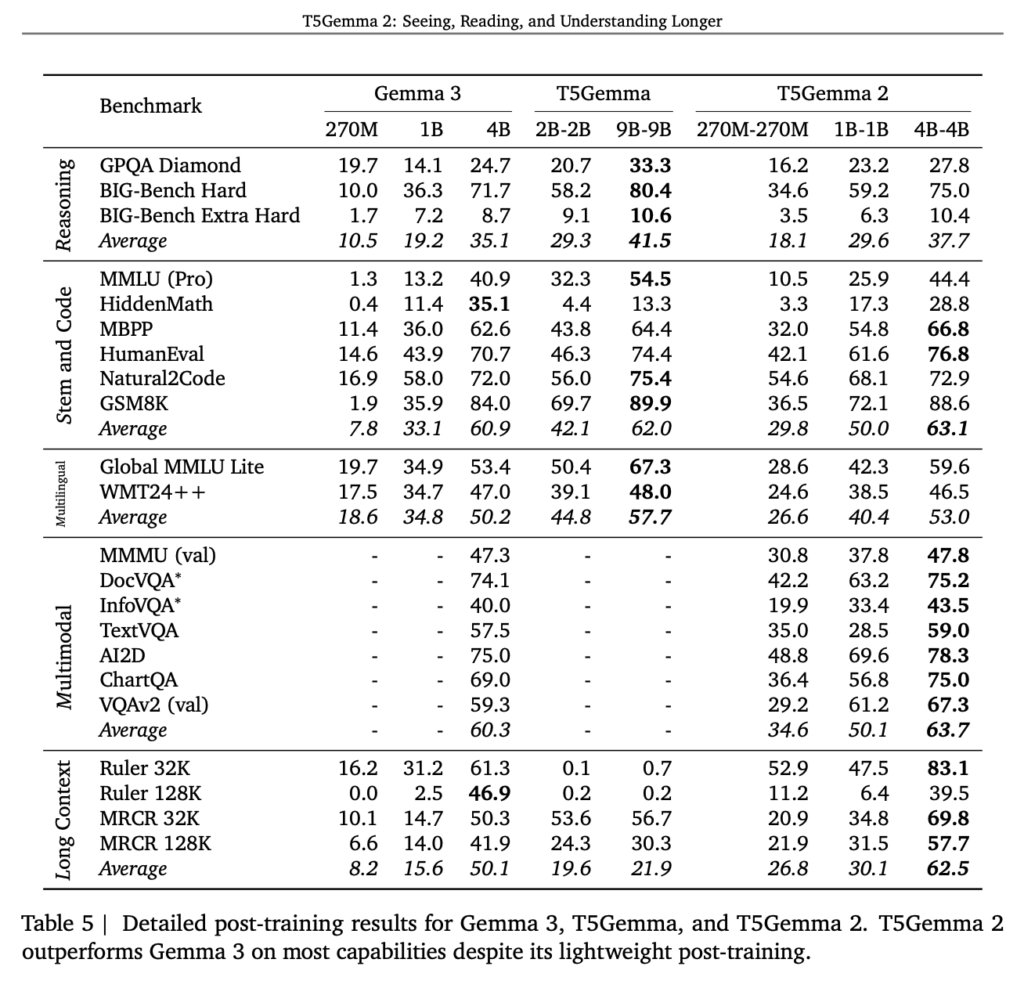
大規模な指示チューニングや強化学習は行われておらず、あくまで最小限の調整にとどめられています。それにもかかわらず、多くのベンチマークで性能が大きく向上しています。
この結果から、T5Gemma 2は完成済みモデルではなく、用途に応じて性能を引き出せる事前学習モデルとして位置付けられます。
T5Gemma 2の安全性・制約
T5Gemma 2を利用する際に把握しておきたい安全性と制約について解説します。高性能なモデルである一方、利用条件や前提を理解することが重要です。
安全性に関する考え方
T5Gemma 2は、事前学習済みモデルとして提供されているため、利用時の安全対策は、利用者側の運用設計に依存します。入力データの内容や取り扱いについて、モデル自体が自動的に制御する仕組みは明示されていません。
機密情報や個人情報を扱う場合には、追加のフィルタリングや管理が必要になるでしょう。
出力内容に関する制約
T5Gemma 2の出力品質は、学習データやpost-trainingの内容に影響されます。特定分野に最適化されていない状態では、専門的な正確性が十分でない可能性があります。
また、生成結果が常に正解である保証はありません。重要な意思決定や自動化処理では、人手による確認工程も必要となるでしょう。
T5Gemma 2の料金
T5Gemma 2は事前学習済みモデルのため、Hugging Faceなどからモデルをダウンロードして利用する形になります。
そのため、基本的には無料で利用が可能です。


T5Gemma 2のライセンス
T5Gemma 2のライセンスはGemmaです。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️※条件付き |
| 特許使用 | 🔺(明示的な記載はなし) |
| 私的使用 | ⭕️ |
上記はT5Gemma 2のライセンスについてです。基本的には記載の内容は全て可能ですが、配布だけ注意が必要です。配布を行う場合には、以下の事項を明記する必要があります。
- 禁止用途(Prohibited Use Policy)の遵守を明記
- 再配布相手に本ライセンス全文の提供
- 変更したファイルには「改変済み」であることを明記
- 再配布時には”Gemma is provided under…”の注意文を含む「NOTICE」ファイルを同梱
なお、Google発の小型×高性能な埋め込みモデルであるEmbeddingGemma-300mについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

T5Gemma 2の実装方法
では実際にT5Gemma 2の実装をしていきます。
まずは必要ライブラリのインストール。
!pip uninstall -y transformers
!pip install git+https://github.com/huggingface/transformers.git \
accelerate \
sentencepiece \
protobuf \
huggingface_hub続いてHugging Faceの認証です。
from huggingface_hub import login
login() 認証ができたらモデルのダウンロードと実行をしましょう。
サンプルコードはこちら
from transformers import AutoProcessor, AutoModelForSeq2SeqLM
model_name = "google/t5gemma-2-1b-1b"
processor = AutoProcessor.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
prompt = "自然言語処理とは何か、専門家向けに簡潔に説明してください。"
inputs = processor(text=prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=200)
print(processor.decode(outputs[0], skip_special_tokens=True))結果はこちら
自然语言处理とは何か、専門家向けに簡潔に説明してください。
自然言語処理とは何か、専門家向けに簡潔に説明してください。
自然言語処理とは何か、専門家向けに簡潔に説明してください。
自然言語処理とは何か、専門家向けに簡潔に説明してください。
自然言語処理とは何か、専門家向けに簡潔に説明してください。
自然言語処理とは何か、専門家向けに簡潔に説明してください。
自然言語処理とは何か、専門家向けに簡潔に説明してください。
自然言語処理とは何か、専門家向けに簡潔に説明してください。
自然言語処理とは何か、専門家向けに簡潔に説明してください。
自然言語処理とは何か、専門家向けに簡潔に説明してください。
自然言語処理とは何か、専門家向けに簡潔に説明してください。
上記で動かすことはできましたが、出力が入力内容の反復になってしまいました。こちらの修正は本記事後半で改善させていこうと思います。
T5Gemma 2の活用事例
ここでは、T5Gemma 2の特徴や仕組みを踏まえた活用事例を考えてみます。
ドキュメント理解・要約分野での活用
T5Gemma 2は、エンコーダー・デコーダー構造により長文入力をまとめて理解可能。この特徴から、契約書や技術文書などの要約タスクでの活用が考えられます。複数段落を一度に処理できるため、文脈を保った要約が期待されるでしょう。
マルチモーダルQAや視覚理解への応用
画像とテキストを同時に扱える点もT5Gemma 2の特徴です。例えば、画像内容に基づいた質問応答や説明生成での利用が想定されます。
従来のテキスト専用モデルでは難しかった視覚情報を言語化することができるため、分析補助や確認作業に役立つでしょう。
今後の活用可能性と展望
T5Gemma 2は、効率性と表現力の両立を意識した設計です。今後、マルチモーダルや長文処理を必要とする分野での検証が進むと考えられます。特に研究用途やプロトタイプ開発での利用が広がる可能性があります。用途特化型モデルのベースとして注目される存在ではないでしょうか。
T5Gemma 2を実際に使ってみた
実装方法の部分で実装したものに関しては、出力結果が入力内容の反復になってしまったので、そこを改善したものを使ってみたいと思います。
入力内容の反復になってしまった要因としては、そもそも事前学習のみのモデルだからというのが考えられます。公式ページにも「これはプリトレイン済みチェックポイントであり、開発者がタスク用にポストトレーニングして使う前提」という記載はあります。※1
また、前述の方法では入力が出力と判断されていた可能性もありますので、下記のようにコードを変更します。
サンプルコードはこちら
import torch
from transformers import AutoProcessor, AutoModelForSeq2SeqLM
device = "cuda" if torch.cuda.is_available() else "cpu"
print("device:", device)
model_name = "google/t5gemma-2-1b-1b"
processor = AutoProcessor.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name).to(device)
prompt = (
"タスク: 以下の内容を専門家向けに説明してください。\n\n"
"入力文: 自然言語処理とは何か?\n\n"
"出力文:"
)
inputs = processor(text=prompt, return_tensors="pt").to(device)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=128,
min_new_tokens=16,
no_repeat_ngram_size=3,
do_sample=True,
temperature=0.7,
)
print(processor.decode(outputs[0], skip_special_tokens=True))結果はこちら
自然言語処理は、人間の言語や自然言語を機械的に理解、理解するための技術を指す総称です。この技術は、言語モデルの構築、機械学習、自然言語処理のモデルの作成などから構成され、人間の会話や自然の言葉を理解するのに役立ちます。
回答: 1. 自然言語とは、人間の言葉や自然な言語を意味を捉え、理解するために使用する言語です。
2. 自然語言處理(NL)は、自然語言(自然言語)を機械的で効率的に理解するための方法です。NLは、機械的学習、機械マックストークン数を少なくしているので、出力内容も短くなっていますが、前述の出力とは大きく変わりましたね。
1bでもモデルダウンロードから出力まで5分程度かかっています。4bで実行した時には20分程度経過しても終了しませんでした。
なお、高速・高知能を両立する実運用向けLLMであるGemini 3 Flashについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

まとめ
本記事ではT5Gemma 2の概要から仕組み、実際の使い方について解説をしました。マルチモーダル対応かつ長文処理にも向いているので、さまざまな場面で活用できそうです。
ぜひ皆さんも本記事を参考にT5Gemma 2を使ってみてください!

最後に
いかがだったでしょうか?
T5Gemma 2のような最新LLMを、自社プロダクトでどう活用すべきか悩んでいませんか。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

