
VibeVoice-Realtime-0.5Bとは?300ms応答のリアルタイムTTSモデルを徹底解説

- 約300msで応答できるリアルタイムTTSモデル
- 8kトークン対応により、長文読み上げでも文脈を維持した自然な音声生成が可能
- MITライセンスで公開され、研究からプロトタイプ開発まで柔軟に活用できる
2025年12月、Microsoftから新たな音声生成モデルがリリースされました!
今回リリースされた「VibeVoice-Realtime-0.5B」はわずか0.5Bながらにリアルタイム処理が可能。長文読み上げにも対応できるよう、最大8kトークンという長いコンテキストウィンドウを処理できます。
本記事ではVibeVoice-Realtime-0.5Bの概要から仕組み、実際の使い方について解説をします。本記事を最後までお読みいただければ、VibeVoice-Realtime-0.5Bの使い方が理解できます。
ぜひ最後までお読みください!
\生成AIを活用して業務プロセスを自動化/
VibeVoice-Realtime-0.5Bの概要
VibeVoice-Realtime-0.5Bは、Microsoftが公開した軽量なリアルタイム向けテキスト読み上げ(TTS)モデル。
約5億パラメータというコンパクトなサイズながら、ストリーミング入力に対応した高品質な音声生成を実現。入力されたテキストから約300msで最初の音声を出力できるため、対話アプリやライブ配信など即応性が求められる場面で活用できるでしょう。
長文テキストをリアルタイムに読み上げながら途切れにくい音声を維持することを前提に設計されており、短いフレーズだけでなく長尺コンテンツにも対応しています。
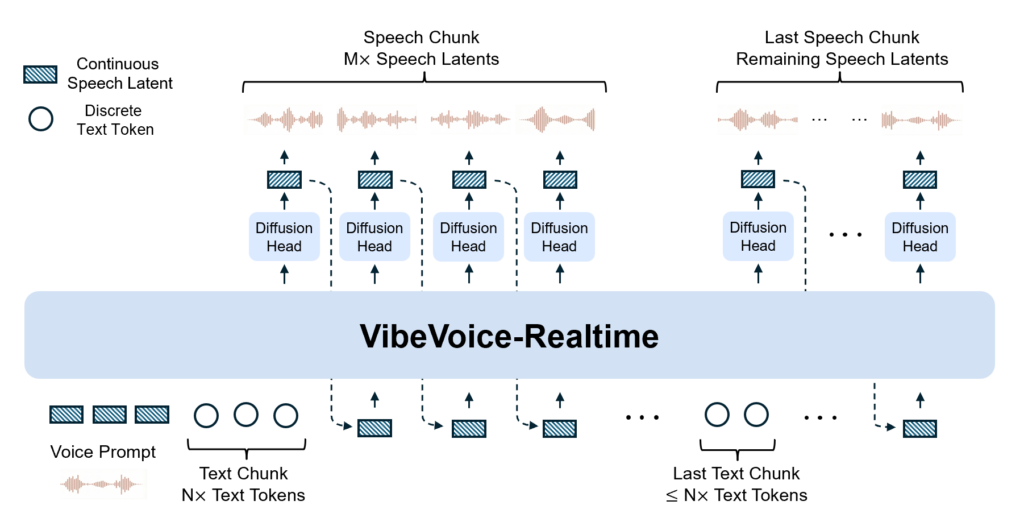


VibeVoice-Realtime-0.5Bの仕組み
VibeVoice-Realtime-0.5Bの内部構造は、リアルタイム処理と長尺生成を両立するために最適化された3段階の音声生成パイプラインで構成されています。
モデルは音響トークナイズ、言語モデル処理、音声デコードという工程を直列に組み合わせることで、軽量ながら高精度のテキスト読み上げを実現。
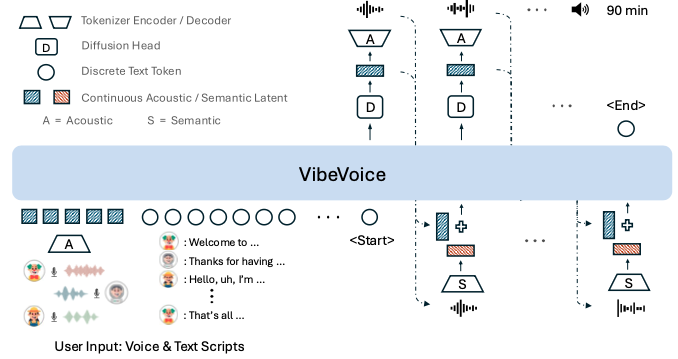
音響トークナイザーによる表現圧縮
VibeVoice-Realtime-0.5Bは、他のVibeVoice長尺モデルで使用されるセマンティックトークナイザーを採用していません。代わりに、7.5Hzという低フレームレートの音響トークナイザーのみを採用。
トークン数が大幅に削減されることで、後段のモデルが処理すべきステップが少なくなり、リアルタイム性の向上につながっています。
また、この方式は音声内容そのものの構造を直接扱えるため、話者識別を目的としない単一話者の読み上げに特化した処理効率の良さが際立つという特徴もあります。
Qwen2.5-0.5Bベースのテキストモデル
テキスト入力を処理する中心部分には、Qwen2.5-0.5Bをベースとしたトランスフォーマー言語モデルが用いられています。
約5億パラメータと小規模でありながら、最大8kトークンのコンテキストを扱えるため、長文の文脈保持が可能です。特にニュース記事や長尺台本のように文脈の流れが重要な場合、この長いコンテキスト処理能力が音声の自然さに直結します。
拡散モデルベースのデコーダー
音響トークンを最終的な音声波形に変換する工程では、拡散モデル(Diffusion Model)が採用されています。拡散モデルは時間方向のノイズ除去を段階的に行う生成方式であり、音質の安定性と滑らかなイントネーションを作り出す点が優れています。
リアルタイムモデルでありながら拡散方式を採用している点は特徴的で、音質劣化を最小限に抑えつつ軽量化を実現しています。
なお、Microsoft初の自社モデルであるMAI-Voice-1・MAI-1-previewについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
VibeVoice-Realtime-0.5Bの特徴

VibeVoice-Realtime-0.5Bには、リアルタイム処理と長時間読み上げを両立するための特徴がいくつか組み込まれています。
約300msで音声を生成する高速応答
VibeVoice-Realtime-0.5B最大の特徴が、テキスト入力からおよそ300msで音声を出力できる点です。
リアルタイムTTSでは応答遅延がユーザー体験を大きく左右します。短いチャット応答やインタラクティブな対話エージェントでは、このリアルタイム性によって「間」を感じさせない自然なやり取りが可能になるでしょう。
さらに、ストリーミング実装を前提として最適化されているため、継続的な読み上げでも遅延蓄積が起きにくい設計となっています。
長文読み上げに強い最大8kトークンのコンテキスト
VibeVoice-Realtime-0.5Bは、最大8kトークンという長いコンテキストウィンドウを処理できます。これによりニュース記事や技術文書のような長文でも、文脈を保ちながら読み上げられる点が特徴。
一般的な軽量TTSモデルは数百〜数千トークン程度の制限を持つケースも多く、長尺生成で音質が不安定になることがあります。
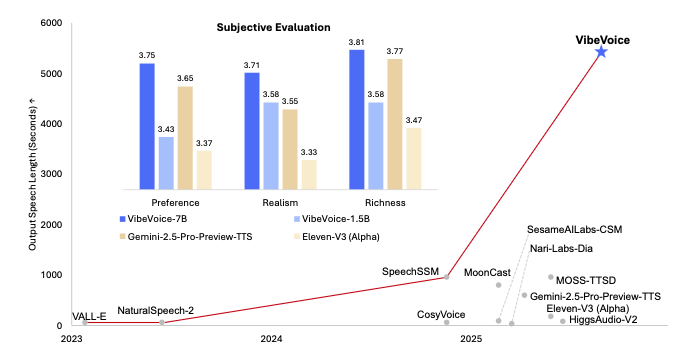
単一話者に特化した安定生成
VibeVoice-Realtime-0.5Bは単一話者を前提としたTTSモデルであり、話者切り替えを必要としないシナリオに最適化されています。
この特化設計により、声質のばらつきが抑えられ、長い読み上げでも安定したトーンを保つことができます。マルチスピーカー機能を備えていない点はデメリットにもなり得ますが、安定性を優先するプロダクトではメリットに転じる場面もあります。
例えば、読み上げニュースや教育コンテンツのナレーションなど、一貫した声が求められる用途に適しているでしょう。
VibeVoice-Realtime-0.5Bの安全性・制約
VibeVoice-Realtime-0.5Bは研究目的で公開されていますが、利用する上で押さえておきたい制約があります。
英語単一話者モデルであることによる制約
VibeVoice-Realtime-0.5Bは英語の単一話者を前提として訓練されています。英語以外の言語は学習対象ではなく、入力した場合は音質が不安定になったり、期待通りの発音にならない可能性が高いです。
また、話者切り替えやスタイル変化などの高度なパラメータ操作にも対応していません。用途を選ぶモデルである点を理解したうえで採用を判断すべきでしょう。
安全性に関する公式な制御仕様は非公開
VibeVoice-Realtime-0.5Bには、出力フィルタリングや不適切コンテンツ抑制といった、安全性に特化した制御機構が明示されていません。
研究モデルとして提供されているため、運用に必要な安全基準は利用者側が適切に設計する必要があります。
特に商用利用の環境で想定されるリスクに対しては、外部の検証プロセスを組み合わせる判断が求められ、安全性要件が明確でないまま本番導入することのリスクは軽視できないと言えるでしょう。
VibeVoice-Realtime-0.5Bの料金
VibeVoice-Realtime-0.5Bは研究目的で公開されているモデルですが、料金体系に関する具体的な情報は公式では明らかにされていません。
モデル自体はHugging Face上で公開されており、ダウンロードしてローカル環境で利用することになります。
VibeVoice-Realtime-0.5Bのライセンス
VibeVoice-Realtime-0.5BはMITライセンスに基づいて提供されています。
通常、MITでは暗黙の許可と解釈される場合が多いですが、技術特許に関わる利用には留意が必要です。
| 利用用途 | 可否 | 備考 |
|---|---|---|
| 商用利用 | ⭕️ | |
| 改変 | ⭕️ | |
| 配布 | ⭕️ | |
| 特許使用 | 明示的には記載なし | MITでは暗黙的に許可されると解釈できるが要注意 |
| 私的使用 | ⭕️ |
なお、1600言語対応の次世代音声認識モデルであるOmnilingual ASRについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
VibeVoice-Realtime-0.5Bの実装方法
ここからはVibeVoice-Realtime-0.5Bをgoogle colaboratoryで実装しますが、公式でgoogle colaboratoryが用意されているので、そちらを使っていきます。
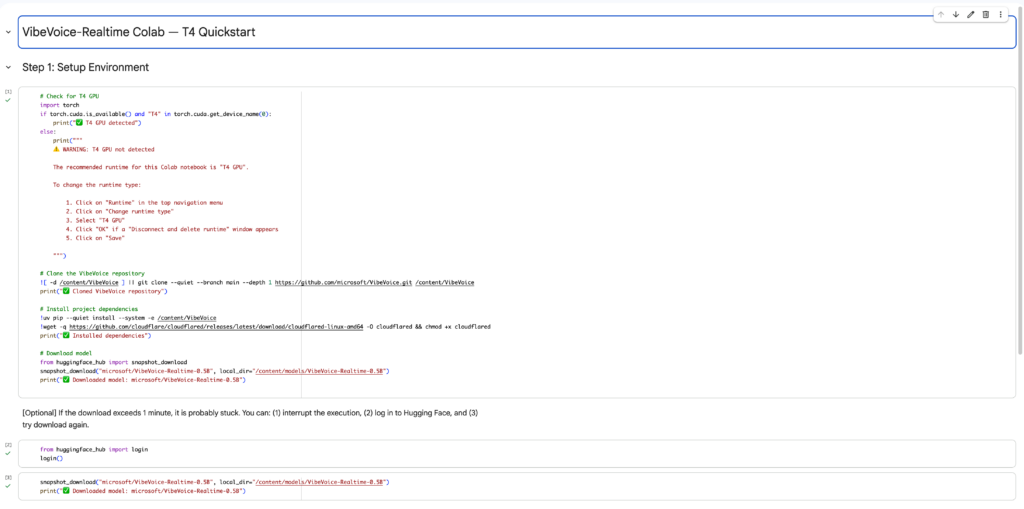
google colaboratoryページに移動したら、上から順に実行ボタンを押していけばOKです。
最後にパブリックURLが出力されるので、そちらにアクセスすればTTSを使うことができます。実際にTTSを実行している様子がこちら。
最初の音声が出力されるまでに若干の遅延はありますが、それでもリアルタイムに近い体験をすることができます。
VibeVoice-Realtime-0.5Bの活用事例
VibeVoice-Realtime-0.5Bは、リアルタイム応答と長文読み上げの両方に強い構造を持つため、さまざまな場面での活用が考えられます。ここではいくつかVibeVoice-Realtime-0.5Bの活用事例について考えてみます。
対話アシスタントやチャットボットの即時応答
約300msで音声生成を開始できる特性は、対話型アプリケーションと非常に相性が良いでしょう。
ユーザーの発話に応じて即座に応答を返せるため、会話体験の自然さが大幅に向上。特にカスタマーサポートや問い合わせ対応では、応答速度の改善がユーザー満足度に直結するでしょう。
ニュースや記事の自動読み上げサービス
8kトークンという長文処理能力は、ニュースサイトやメディアアプリの読み上げ機能で効果を発揮します。
従来の軽量TTSでは文脈の途切れや音質劣化が起きやすい場面でも、安定した音声を維持しやすい点がメリット。文章構造を保持した自然な読み上げが求められる分野では、有用性が高いと言えるでしょう。生成コンテンツの量が多いサービスにも適した選択肢となるはずです。
実際に長文を読み込ませてみました。読み込ませたのは、Hugging Face内にあるテキストです。
教育向け音声教材の生成
一定の抑揚で長時間読み上げられる点は、教育教材のナレーションやリスニング教材の作成に向いているでしょう。
単一話者で安定した声質を維持できるため、学習者が内容に集中しやすくなる点も利点。音声収録にかかるコストを抑えつつ、教材制作を効率化したい教育機関や出版社での活用が期待されます。特に長尺コンテンツを扱うシナリオに適しているでしょう。
VibeVoice-Realtime-0.5Bを実際に使ってみた
google colaboratoryを使わなくてもAppが用意されているので、手軽に使ってみたい場合には、こちらの利用がおすすめです。
使い方はgoogle colaboratoryで実装した時のUIとほぼ一緒です。読み上げてほしいテキストを入力後、「Generate Speech」をクリックすればOKです。
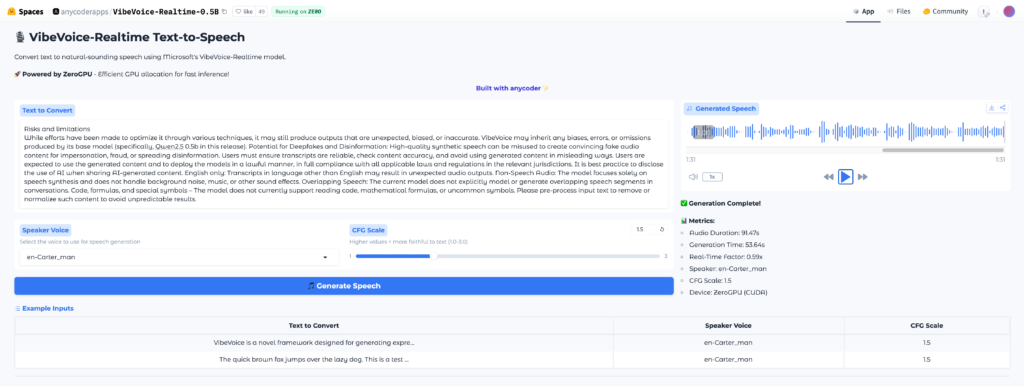
こちらの場合には、音声ファイルが生成されるので、生成された後に音声を再生することができます。
なお、150ms低遅延の次世代リアルタイム音声認識モデルであるScribe v2 Realtimeについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

まとめ
本記事ではVibeVoice-Realtime-0.5Bの概要から仕組み、実際の使い方について解説をしました。実際に使ってみたところ、読み上げ開始は若干の遅延がありますが、それ以降は特に気になる部分もなく、テキストを正確に読み上げてくれました。
話者分離や日本語に対応していない点などもありますが、英文の読み上げに特化したサービスとして考えれば、非常に有用性の高いモデルかなと感じます。
ぜひ皆さんも本記事を参考にVibeVoice-Realtime-0.5Bを使ってみてください!

最後に
いかがだったでしょうか?
「自社サービスに音声UIを導入したい」「最適なTTSモデルを比較したい」などのご相談があれば、お気軽にお問い合わせください。要件に合わせた技術選定をサポートします。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。


