
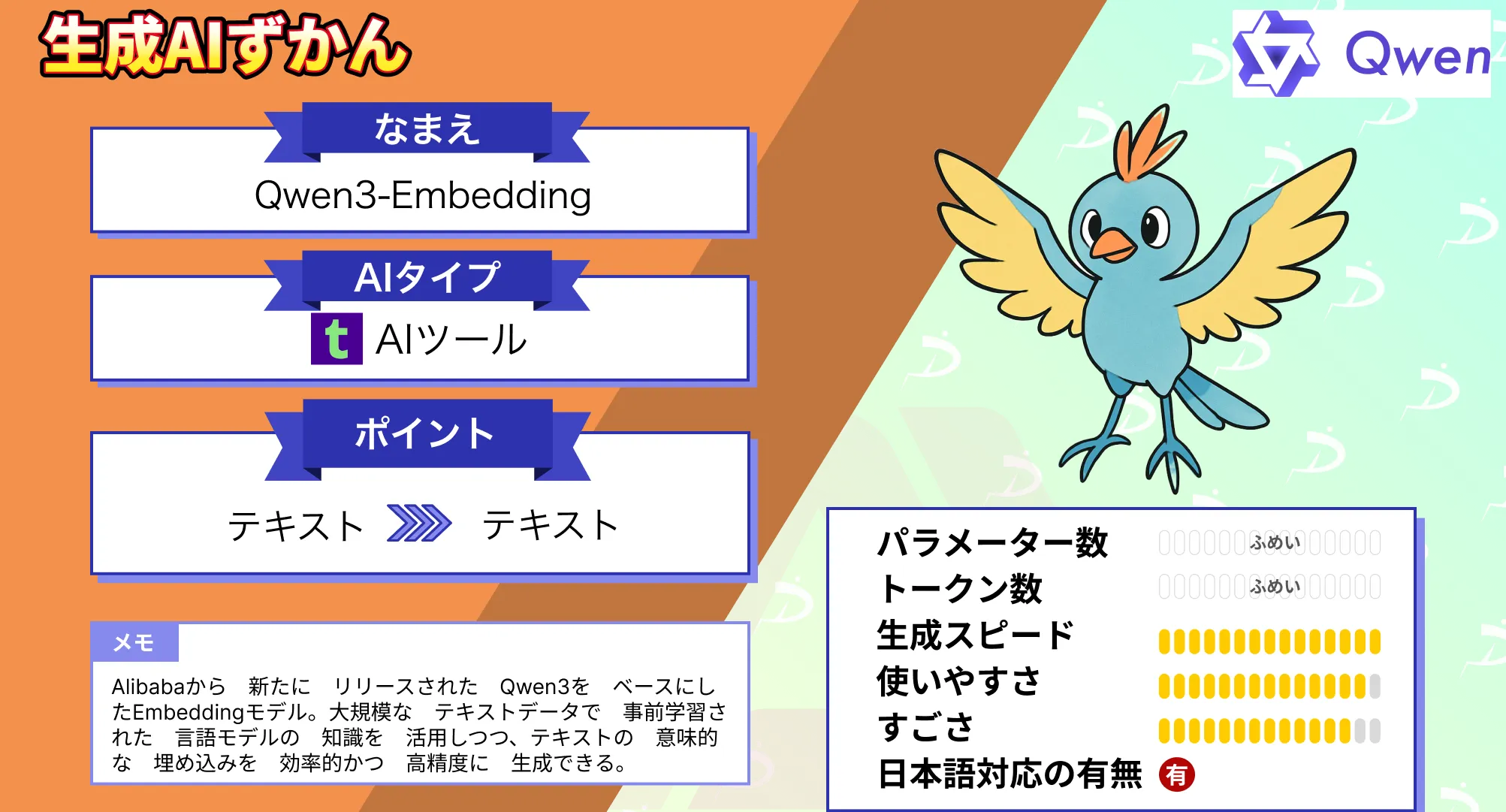
【Qwen3-Embedding】多言語&明示タスク対応の高精度モデルが登場!性能や使い方、検証結果を徹底解説
- テキスト埋め込みモデルの多言語対応
- 明示的なタスク記述に対応
- MTEB世界1位のスコアを獲得
2025年6月6日、Alibabaから新たなAIモデルが登場!
今回リリースされた「Qwen3-Embedding」はテキスト埋め込みモデルで、多言語対応です。Qwen3-Embeddingは従来のLLMと異なり、明示的なタスク記述に対応したLLM。
本記事では、Qwen3-Embeddingの概要からモデルの特徴や使い方について解説します。最後までお読みいただければ、Qwen3-Embeddingについて理解が深まりますので、ぜひ最後までお読みください!
\生成AIを活用して業務プロセスを自動化/
Qwen3-Embeddingの概要
Qwen3-EmbeddingはAlibabaが新たに開発した、多言語対応・指示対応型のテキスト埋め込みモデルです。
モデルサイズは3サイズ用意されており、それぞれ0.6B/4B/8B。対応言語は100以上の自然言語に対応しており、それ以外に、プログラミング言語にも対応しています。プログラミング言語に関しては、どの言語に対応しているか明記されていません。
Hugging Faceにはコード検索機能もあると明記されています。
従来のLLMとQwen3-Embeddingの違いとして、合成データを用いた学習がQwen3-Embeddingにはあります。
従来モデルは人手によるアノテーションや自然文に依存していましたが、Qwen3-Embeddingは、Qwen3 LLM自身を使って多様なペアデータ(検索、分類、STSなど)を生成し、制御された条件で学習します。
Qwen3-Embeddingの技術
Qwen3-Embeddingは3段階からなる高精度な訓練方法を採用しています。
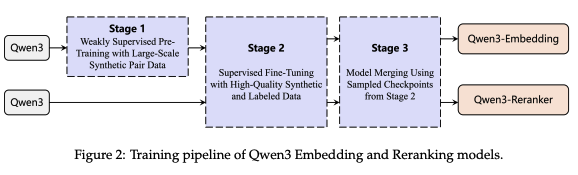
まず第一段階では、弱教師あり事前学習を実行。この事前学習では、Qwen3のLLMを使って学習用データを自動的に生成します。
通常、埋め込みモデルの訓練にはQ&Aフォーラムや学術論文など、既存のデータを用いますが、Qwen3ではそれをさらに進めて、プロンプトを制御しペアデータを自由に合成しています。
第二段階では、高品質データによる教師ありファインチューニングを行います。
ここでは、事前学習で用いた大量の合成ペアの中から、意味的に高い類似性を示す約1200万件のデータが抽出されます。この選別にはコサイン類似度が使われ、しきい値0.7以上のペアのみが採用されます。つまり、この段階ではノイズを除去しモデルの判断を適切に強化することになります。
最後の段階で行われるのが、モデルマージ(統合)。
これは、前の段階で得られた複数の学習チェックポイントを球面線形補間という手法で統合するもの。このプロセスは「異なる視点・文脈で学習された重みたちを、力のバランスを保ちながらブレンドする」ようなものです。これを行うことで、特定のデータ分布に偏ることなく、より汎用的に機能するモデルになります。


Qwen3-Embeddingの特徴
Qwen3-Embeddingはユーザーの意図を明示的に伝える「インストラクション」をクエリに加える形式が採用されています。下記のような形式です。
{Instruction} {Query}<|endoftext|>たとえば、「Web検索の質問に対して関連文書を探して」というタスクであれば、次のような入力になります。
Instruct: Find relevant documents in response to web search queries.
Query: What is the capital of China?<|endoftext|>このように、instructionとqueryを1つにまとめて入力し、文書と分けて処理することで、タスクの意味をモデル内部に明示的に伝える構造になっています。

Qwen3-Embeddingの性能
Qwen3-EmbeddingはMTEBで世界1位のスコアを記録しており、高い性能を誇ります。
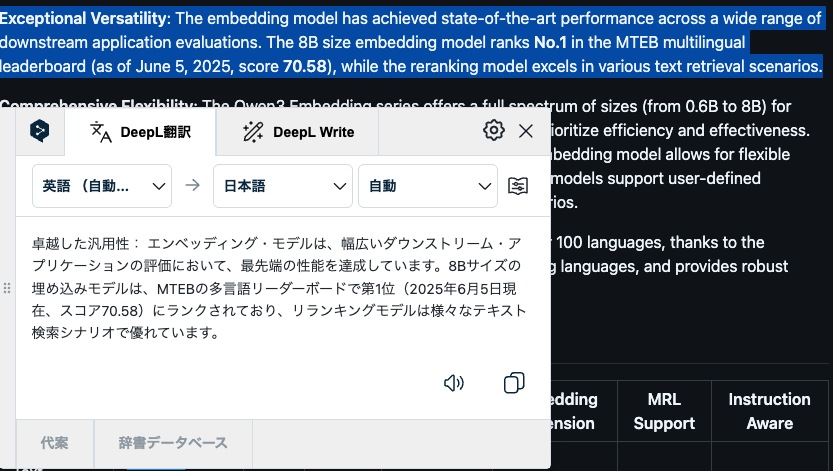
ベンチマークは以下です。
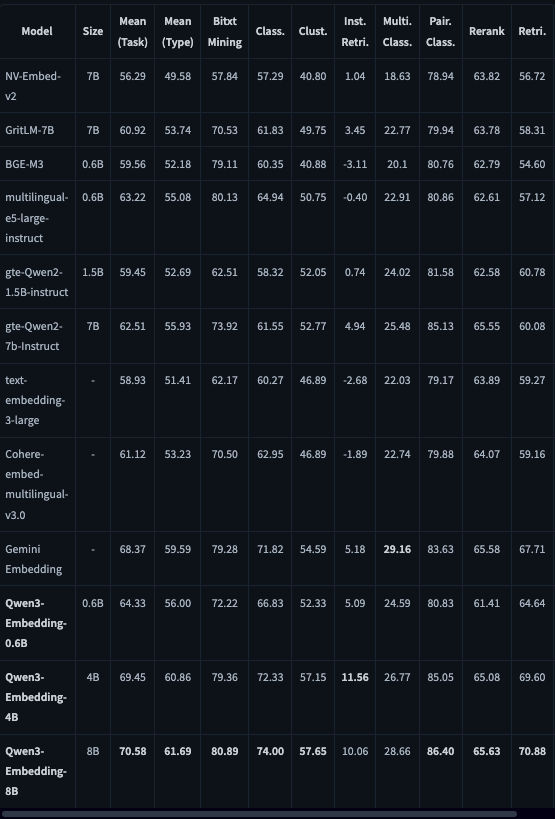
Qwen3-Embedding-8Bが総合性能でトップスコアを叩き出しており、Gemini Embeddingを上回っています。また、Bitext Miningでは80.89のスコアで、これは多言語対応に強く、並列文検出能力が高いことを示します。
また、分類やクラスタリングのスコアも高く、RAGのような使い方に非常に優れていると言えます。
Qwen3-Embeddingのライセンス
Qwen3-EmbeddingのライセンスはApache2.0です。そのため、基本的には改変や再配布、商用利用が可能です。ただし、再配布時には元の著作権表示やライセンスの通知を行う必要があります。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
なお、SoraやLuma超えの動画生成AI【Wan2.1】について詳しく知りたい方は、下記の記事を合わせてご確認ください。

Qwen3-Embeddingの使い方
では実際にQwen3-Embeddingをgoogle colaboratoryで使っていきます。
■システム RAM
6.9 / 53.0GB
■GPU RAM
0.0 / 22.5GB
■ディスク
43.8 / 112.6 GB
■GPUの種類:L4
■プラン:有料
サンプルコードはこちら
import torch
import torch.nn.functional as F
from transformers import AutoTokenizer, AutoModel
import pandas as pd
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3-Embedding-0.6B")
model = AutoModel.from_pretrained("Qwen/Qwen3-Embedding-0.6B")
def last_token_pool(last_hidden_states, attention_mask):
"""
最後の有効なトークンの埋め込みを取得する関数。
Qwen-Embeddingモデルの推奨プーリング方法。
"""
sequence_lengths = attention_mask.sum(dim=1) - 1
return last_hidden_states[torch.arange(last_hidden_states.size(0)), sequence_lengths]
def compute_and_show_qwen_embedding(queries, documents, top_k=3, title="類似度計算テスト"):
"""
Qwenモデルで埋め込みを計算し、類似度を評価して上位結果を表示する関数。
"""
print("\n" + "="*80)
print(f"✨ {title} ✨")
print(f"🚀 {len(queries)}個のクエリ × {len(documents)}個の文書で類似度を計算中 (Qwen-Embeddingモデル使用)...")
input_texts = queries + documents
batch = tokenizer(input_texts, return_tensors="pt", padding=True, truncation=True, max_length=8192)
with torch.no_grad():
outputs = model(**batch)
embeddings = last_token_pool(outputs.last_hidden_state, batch["attention_mask"])
embeddings = F.normalize(embeddings, p=2, dim=1)
query_embeddings = embeddings[:len(queries)]
document_embeddings = embeddings[len(queries):]
cos_scores = (query_embeddings @ document_embeddings.T)
print(f"\n📊 各クエリの上位{top_k}件の結果:")
print("-" * 60)
for i, query_text in enumerate(queries):
print(f"\n🔍 Q{i+1}: {query_text}")
query_scores = cos_scores[i]
sorted_scores, sorted_indices = torch.sort(query_scores, descending=True)
for rank, idx in enumerate(sorted_indices[:top_k].tolist(), 1):
score = sorted_scores[rank-1].item()
doc_text = documents[idx]
status_icon = "🌟" if rank == 1 and score > 0.7 else "📄"
print(f" {rank}位 {status_icon} D{idx+1} (スコア: {score:.4f}): {doc_text}")
if len(doc_text) > 70:
print(f" ... {doc_text[:67]}...")
else:
print(f" {doc_text}")
queries_tech = [
"Instruct: Retrieve relevant document.\nQuery: 5Gとは何か?",
"Instruct: Retrieve relevant document.\nQuery: 量子コンピューターの原理を教えてください。",
"Instruct: Retrieve relevant document.\nQuery: サイバーセキュリティの脅威について。",
"Instruct: Retrieve relevant document.\nQuery: AIの倫理的課題について。"
]
documents_tech = [
"5Gは第5世代移動通信システムの略で、高速・大容量、低遅延、多数同時接続が特徴です。",
"量子コンピューターは量子力学の原理を利用し、従来のコンピューターでは解けない問題を高速に計算する次世代のコンピューターです。",
"フィッシング詐欺は、偽のウェブサイトやメールを使って個人情報をだまし取るサイバー攻撃の一種です。",
"AIの倫理的課題には、雇用への影響、プライバシーの侵害、差別的なバイアス、責任の所在などが挙げられます。",
"ブロックチェーンは分散型台帳技術であり、データの改ざんが困難な信頼性の高いシステムを構築します。"
]
compute_and_show_qwen_embedding(queries_tech, documents_tech, top_k=3, title="テクノロジーと現代社会")
queries_lit_phil = [
"Instruct: Retrieve relevant document.\nQuery: カントの哲学における主要な概念は?",
"Instruct: Retrieve relevant document.\nQuery: シェイクスピアの代表作は?",
"Instruct: Retrieve relevant document.\nQuery: 自由意志に関する議論について教えて。",
"Instruct: Retrieve relevant document.\nQuery: 徒然草の作者は誰ですか?"
]
documents_lit_phil = [
"イマヌエル・カントの批判哲学では、純粋理性批判、実践理性批判、判断力批判の三部作が主要であり、義務論が重要な概念です。",
"ウィリアム・シェイクスピアの四大悲劇には、『ハムレット』、『オセロ』、『リア王』、『マクベス』があります。",
"自由意志とは、人間の行動が外的要因や必然的な法則によって決定されるのではなく、自らの意思によって選択されるという思想です。",
"兼好法師は鎌倉時代末期から南北朝時代の歌人で、随筆『徒然草』の作者として知られています。",
"ニーチェは「神は死んだ」という言葉で知られるドイツの哲学者で、永劫回帰や力への意志などの概念を提唱しました。"
]
compute_and_show_qwen_embedding(queries_lit_phil, documents_lit_phil, top_k=2, title="文学と哲学")
print("\n🎉 全てのテストが完了しました!Qwenモデルが多様なテーマで意味的な類似性を捉えられていることを確認しました。")結果はこちら
================================================================================
✨ テクノロジーと現代社会 ✨
🚀 4個のクエリ × 5個の文書で類似度を計算中 (Qwen-Embeddingモデル使用)...
📊 各クエリの上位3件の結果:
------------------------------------------------------------
🔍 Q1: Instruct: Retrieve relevant document.
Query: 5Gとは何か?
1位 🌟 D1 (スコア: 0.7464): 5Gは第5世代移動通信システムの略で、高速・大容量、低遅延、多数同時接続が特徴です。
5Gは第5世代移動通信システムの略で、高速・大容量、低遅延、多数同時接続が特徴です。
2位 📄 D5 (スコア: 0.3177): ブロックチェーンは分散型台帳技術であり、データの改ざんが困難な信頼性の高いシステムを構築します。
ブロックチェーンは分散型台帳技術であり、データの改ざんが困難な信頼性の高いシステムを構築します。
3位 📄 D2 (スコア: 0.3095): 量子コンピューターは量子力学の原理を利用し、従来のコンピューターでは解けない問題を高速に計算する次世代のコンピューターです。
量子コンピューターは量子力学の原理を利用し、従来のコンピューターでは解けない問題を高速に計算する次世代のコンピューターです。
🔍 Q2: Instruct: Retrieve relevant document.
Query: 量子コンピューターの原理を教えてください。
1位 🌟 D2 (スコア: 0.7516): 量子コンピューターは量子力学の原理を利用し、従来のコンピューターでは解けない問題を高速に計算する次世代のコンピューターです。
量子コンピューターは量子力学の原理を利用し、従来のコンピューターでは解けない問題を高速に計算する次世代のコンピューターです。
2位 📄 D5 (スコア: 0.3263): ブロックチェーンは分散型台帳技術であり、データの改ざんが困難な信頼性の高いシステムを構築します。
ブロックチェーンは分散型台帳技術であり、データの改ざんが困難な信頼性の高いシステムを構築します。
3位 📄 D1 (スコア: 0.2652): 5Gは第5世代移動通信システムの略で、高速・大容量、低遅延、多数同時接続が特徴です。
5Gは第5世代移動通信システムの略で、高速・大容量、低遅延、多数同時接続が特徴です。
🔍 Q3: Instruct: Retrieve relevant document.
Query: サイバーセキュリティの脅威について。
1位 📄 D3 (スコア: 0.5014): フィッシング詐欺は、偽のウェブサイトやメールを使って個人情報をだまし取るサイバー攻撃の一種です。
フィッシング詐欺は、偽のウェブサイトやメールを使って個人情報をだまし取るサイバー攻撃の一種です。
2位 📄 D5 (スコア: 0.3551): ブロックチェーンは分散型台帳技術であり、データの改ざんが困難な信頼性の高いシステムを構築します。
ブロックチェーンは分散型台帳技術であり、データの改ざんが困難な信頼性の高いシステムを構築します。
3位 📄 D4 (スコア: 0.3004): AIの倫理的課題には、雇用への影響、プライバシーの侵害、差別的なバイアス、責任の所在などが挙げられます。
AIの倫理的課題には、雇用への影響、プライバシーの侵害、差別的なバイアス、責任の所在などが挙げられます。
🔍 Q4: Instruct: Retrieve relevant document.
Query: AIの倫理的課題について。
1位 🌟 D4 (スコア: 0.7620): AIの倫理的課題には、雇用への影響、プライバシーの侵害、差別的なバイアス、責任の所在などが挙げられます。
AIの倫理的課題には、雇用への影響、プライバシーの侵害、差別的なバイアス、責任の所在などが挙げられます。
2位 📄 D2 (スコア: 0.2820): 量子コンピューターは量子力学の原理を利用し、従来のコンピューターでは解けない問題を高速に計算する次世代のコンピューターです。
量子コンピューターは量子力学の原理を利用し、従来のコンピューターでは解けない問題を高速に計算する次世代のコンピューターです。
3位 📄 D5 (スコア: 0.2144): ブロックチェーンは分散型台帳技術であり、データの改ざんが困難な信頼性の高いシステムを構築します。
ブロックチェーンは分散型台帳技術であり、データの改ざんが困難な信頼性の高いシステムを構築します。
================================================================================
✨ 文学と哲学 ✨
🚀 4個のクエリ × 5個の文書で類似度を計算中 (Qwen-Embeddingモデル使用)...
📊 各クエリの上位2件の結果:
------------------------------------------------------------
🔍 Q1: Instruct: Retrieve relevant document.
Query: カントの哲学における主要な概念は?
1位 📄 D1 (スコア: 0.6208): イマヌエル・カントの批判哲学では、純粋理性批判、実践理性批判、判断力批判の三部作が主要であり、義務論が重要な概念です。
イマヌエル・カントの批判哲学では、純粋理性批判、実践理性批判、判断力批判の三部作が主要であり、義務論が重要な概念です。
2位 📄 D5 (スコア: 0.3590): ニーチェは「神は死んだ」という言葉で知られるドイツの哲学者で、永劫回帰や力への意志などの概念を提唱しました。
ニーチェは「神は死んだ」という言葉で知られるドイツの哲学者で、永劫回帰や力への意志などの概念を提唱しました。
🔍 Q2: Instruct: Retrieve relevant document.
Query: シェイクスピアの代表作は?
1位 🌟 D2 (スコア: 0.7044): ウィリアム・シェイクスピアの四大悲劇には、『ハムレット』、『オセロ』、『リア王』、『マクベス』があります。
ウィリアム・シェイクスピアの四大悲劇には、『ハムレット』、『オセロ』、『リア王』、『マクベス』があります。
2位 📄 D5 (スコア: 0.3076): ニーチェは「神は死んだ」という言葉で知られるドイツの哲学者で、永劫回帰や力への意志などの概念を提唱しました。
ニーチェは「神は死んだ」という言葉で知られるドイツの哲学者で、永劫回帰や力への意志などの概念を提唱しました。
🔍 Q3: Instruct: Retrieve relevant document.
Query: 自由意志に関する議論について教えて。
1位 📄 D3 (スコア: 0.6640): 自由意志とは、人間の行動が外的要因や必然的な法則によって決定されるのではなく、自らの意思によって選択されるという思想です。
自由意志とは、人間の行動が外的要因や必然的な法則によって決定されるのではなく、自らの意思によって選択されるという思想です。
2位 📄 D1 (スコア: 0.4340): イマヌエル・カントの批判哲学では、純粋理性批判、実践理性批判、判断力批判の三部作が主要であり、義務論が重要な概念です。
イマヌエル・カントの批判哲学では、純粋理性批判、実践理性批判、判断力批判の三部作が主要であり、義務論が重要な概念です。
🔍 Q4: Instruct: Retrieve relevant document.
Query: 徒然草の作者は誰ですか?
1位 📄 D4 (スコア: 0.6264): 兼好法師は鎌倉時代末期から南北朝時代の歌人で、随筆『徒然草』の作者として知られています。
兼好法師は鎌倉時代末期から南北朝時代の歌人で、随筆『徒然草』の作者として知られています。
2位 📄 D5 (スコア: 0.2696): ニーチェは「神は死んだ」という言葉で知られるドイツの哲学者で、永劫回帰や力への意志などの概念を提唱しました。
ニーチェは「神は死んだ」という言葉で知られるドイツの哲学者で、永劫回帰や力への意志などの概念を提唱しました。
🎉 全てのテストが完了しました!Qwenモデルが多様なテーマで意味的な類似性を捉えられていることを確認しました。Qwen3-Embeddingを使って検証してみた!
Qwen3-Embeddingは、テキストの意味的な類似性を数値化し、それに基づいて最も関連性の高いテキストを効率的に「検索・特定する」ことができるモデル。
そこで、さまざまなクエリと文章を与え、意味的には関連していそうな文章を抽出できるか、より抽象的なテーマのクエリに対して具体的な内容を抽出できる、ノイズが入っていても問題なく抽出できるかなどを検証していきます。
サンプルコードはこちら
import torch
import torch.nn.functional as F
from transformers import AutoTokenizer, AutoModel
print("🚀 Qwen-Embeddingモデルをロード中...")
try:
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3-Embedding-0.6B")
model = AutoModel.from_pretrained("Qwen/Qwen3-Embedding-0.6B")
print("✅ モデル 'Qwen/Qwen3-Embedding-0.6B' のロードが完了しました。")
except Exception as e:
print(f"❌ モデル 'Qwen/Qwen3-Embedding-0.6B' のロード中にエラーが発生しました: {e}")
print("モデルをロードできませんでした。スクリプトを終了します。")
exit()
def last_token_pool(last_hidden_states, attention_mask):
"""
最後の有効なトークンの埋め込みを取得する関数。
Qwen-Embeddingモデルの推奨プーリング方法。
"""
sequence_lengths = attention_mask.sum(dim=1) - 1
sequence_lengths = torch.clamp(sequence_lengths, min=0)
return last_hidden_states[torch.arange(last_hidden_states.size(0)), sequence_lengths]
def compute_and_show_qwen_embedding(queries_with_meta, documents, top_k=3, title="類似度計算テスト"):
"""
Qwenモデルで埋め込みを計算し、類似度を評価して上位結果を表示する関数。
Args:
queries_with_meta (list): クエリとそのメタデータ(期待される正解文書のインデックス)のリスト。
例: [{"query": "テキスト", "expected_doc_indices": [0, 2]}, ...]
documents (list): 文書群のリスト。各要素はテキスト文字列。
top_k (int): 上位何件の結果を表示するか。
title (str): テストのタイトル。
"""
print("\n" + "="*80)
print(f"✨ {title} ✨")
print(f"🚀 {len(queries_with_meta)}個のクエリ × {len(documents)}個の文書で類似度を計算中 (Qwen-Embeddingモデル使用)...")
queries_text = [q_item["query"] for q_item in queries_with_meta]
input_texts = queries_text + documents
batch = tokenizer(input_texts, return_tensors="pt", padding=True, truncation=True, max_length=8192)
with torch.no_grad():
outputs = model(**batch)
embeddings = last_token_pool(outputs.last_hidden_state, batch["attention_mask"])
embeddings = F.normalize(embeddings, p=2, dim=1)
query_embeddings = embeddings[:len(queries_text)]
document_embeddings = embeddings[len(queries_text):]
cos_scores = (query_embeddings @ document_embeddings.T)
print(f"\n📊 各クエリの上位{top_k}件の結果:")
print("-" * 60)
for i, query_item in enumerate(queries_with_meta):
display_query = query_item["query"].replace("Instruct: Retrieve relevant document.\nQuery: ", "")
expected_indices = set(query_item.get("expected_doc_indices", []))
print(f"\n🔍 Q{i+1}: {display_query}")
query_scores = cos_scores[i]
sorted_scores, sorted_indices = torch.sort(query_scores, descending=True)
for rank, idx in enumerate(sorted_indices[:top_k].tolist(), 1):
score = sorted_scores[rank-1].item()
doc_text = documents[idx]
status_icon = "🌟" if idx in expected_indices else "📄"
print(f" {rank}位 {status_icon} D{idx+1} (スコア: {score:.4f}): {doc_text}")
if len(doc_text) > 70:
print(f" ... {doc_text[:67]}...")
else:
print(f" {doc_text}")
documents_tech_extended = [
"5Gは第5世代移動通信システムの略で、高速・大容量、低遅延、多数同時接続が特徴です。", # D1 (idx 0)
"量子コンピューターは量子力学の原理を利用し、従来のコンピューターでは解けない問題を高速に計算する次世代のコンピューターです。", # D2 (idx 1)
"フィッシング詐欺は、偽のウェブサイトやメールを使って個人情報をだまし取るサイバー攻撃の一種です。", # D3 (idx 2)
"AIの倫理的課題には、雇用への影響、プライバシーの侵害、差別的なバイアス、責任の所在などが挙げられます。", # D4 (idx 3)
"ブロックチェーンは分散型台帳技術であり、データの改ざんが困難な信頼性の高いシステムを構築します。", # D5 (idx 4)
"クラウドコンピューティングは、インターネット経由でサーバーやストレージ、ソフトウェアなどのコンピューターリソースを提供するサービスです。", # D6 (idx 5)
"IoT(モノのインターネット)は、様々な物理デバイスがインターネットに接続され、データの収集や遠隔操作を可能にする技術です。", # D7 (idx 6)
]
queries_tech_extended = [
{"query": "Instruct: Retrieve relevant document.\nQuery: 5Gとは何か?", "expected_doc_indices": [0]},
{"query": "Instruct: Retrieve relevant document.\nQuery: 量子コンピューターの原理を教えてください。", "expected_doc_indices": [1]},
{"query": "Instruct: Retrieve relevant document.\nQuery: サイバーセキュリティの脅威について。", "expected_doc_indices": [2]},
{"query": "Instruct: Retrieve relevant document.\nQuery: AIの倫理的課題について。", "expected_doc_indices": [3]},
{"query": "Instruct: Retrieve relevant document.\nQuery: フィッシング詐欺とはなんですか?", "expected_doc_indices": [2]}, # 正しいクエリ (比較用)
{"query": "Instruct: Retrieve relevant document.\nQuery: フイッシング詐欺とはなんですか?", "expected_doc_indices": [2]}, # 微細な誤字
{"query": "Instruct: Retrieve relevant document.\nQuery: サイバーセキュリテイのキョウイについて。", "expected_doc_indices": [2]}, # カタカナの誤字 + 全角/半角
{"query": "Instruct: Retrieve relevant document.\nQuery: AIの倫理的課題とか、そのへんの話。", "expected_doc_indices": [3]}, # 余計な表現が混入
{"query": "Instruct: Retrieve relevant document.\nQuery: 5Gって何?早く教えて!", "expected_doc_indices": [0]}, # 口語表現・余計な言葉
{"query": "Instruct: Retrieve relevant document.\nQuery: 未来の通信インフラについて。", "expected_doc_indices": [0]}, # より抽象的なクエリ
{"query": "Instruct: Retrieve relevant document.\nQuery: 次世代の計算機技術。", "expected_doc_indices": [1]}, # より抽象的なクエリ
{"query": "Instruct: Retrieve relevant document.\nQuery: データの信頼性を保証する技術。", "expected_doc_indices": [4]}, # より抽象的なクエリ(ブロックチェーンに言及なし)
{"query": "Instruct: Retrieve relevant document.\nQuery: インターネット上のリソース利用形態。", "expected_doc_indices": [5]}, # より抽象的なクエリ(クラウドコンピューティングに言及なし)
{"query": "Instruct: Retrieve relevant document.\nQuery: あらゆるモノをネットに繋げる概念。", "expected_doc_indices": [6]}, # より抽象的なクエリ(IoTに言及なし)
]
compute_and_show_qwen_embedding(queries_tech_extended, documents_tech_extended, top_k=3, title="テクノロジーと現代社会 (ノイズ耐性/抽象度検証)")
documents_lit_phil_extended = [
"イマヌエル・カントの批判哲学では、純粋理性批判、実践理性批判、判断力批判の三部作が主要であり、義務論が重要な概念です。", # D1 (idx 0)
"ウィリアム・シェイクスピアの四大悲劇には、『ハムレット』、『オセロ』、『リア王』、『マクベス』があります。", # D2 (idx 1)
"自由意志とは、人間の行動が外的要因や必然的な法則によって決定されるのではなく、自らの意思によって選択されるという思想です。", # D3 (idx 2)
"兼好法師は鎌倉時代末期から南北朝時代の歌人で、随筆『徒然草』の作者として知られています。", # D4 (idx 3)
"ニーチェは「神は死んだ」という言葉で知られるドイツの哲学者で、永劫回帰や力への意志などの概念を提唱しました。", # D5 (idx 4)
"夏目漱石は明治・大正期の日本の小説家で、『こころ』や『吾輩は猫である』、『坊っちゃん』などの作品を残しました。", # D6 (idx 5)
]
queries_lit_phil_extended = [
{"query": "Instruct: Retrieve relevant document.\nQuery: カントの哲学における主要な概念は?", "expected_doc_indices": [0]},
{"query": "Instruct: Retrieve relevant document.\nQuery: シェイクスピアの代表作は?", "expected_doc_indices": [1]},
{"query": "Instruct: Retrieve relevant document.\nQuery: 自由意志に関する議論について教えて。", "expected_doc_indices": [2]},
{"query": "Instruct: Retrieve relevant document.\nQuery: 徒然草の作者は誰ですか?", "expected_doc_indices": [3]},
{"query": "Instruct: Retrieve relevant document.\nQuery: シェークスピアの作品?", "expected_doc_indices": [1]}, # 微細な誤字
{"query": "Instruct: Retrieve relevant document.\nQuery: 徒然草のさくしゃはだれ?", "expected_doc_indices": [3]}, # ひらがな混じり
{"query": "Instruct: Retrieve relevant document.\nQuery: ニーチェについて知りたい。", "expected_doc_indices": [4]}, # 短いクエリ
{"query": "Instruct: Retrieve relevant document.\nQuery: カントのテツガク。", "expected_doc_indices": [0]}, # 短いクエリ + カタカナ
{"query": "Instruct: Retrieve relevant document.\nQuery: 倫理的な選択の自由について。", "expected_doc_indices": [2]}, # より抽象的なクエリ(自由意志に言及なし)
{"query": "Instruct: Retrieve relevant document.\nQuery: 義務に関する哲学的な考え方。", "expected_doc_indices": [0]}, # より抽象的なクエリ(カント、義務論に言及なし)
{"query": "Instruct: Retrieve relevant document.\nQuery: 日本の有名な近代文学の作家。", "expected_doc_indices": [5]}, # より抽象的なクエリ(夏目漱石に言及なし)
{"query": "Instruct: Retrieve relevant document.\nQuery: ドイツの思想家の永劫回帰説。", "expected_doc_indices": [4]}, # より抽象的なクエリ(ニーチェに言及なし)
]
compute_and_show_qwen_embedding(queries_lit_phil_extended, documents_lit_phil_extended, top_k=2, title="文学と哲学 (ノイズ耐性/抽象度検証)")
print("\n🎉 全てのテストが完了しました!")
print("そして抽象度の異なるクエリに対しても、意味的な類似性をどの程度捉えられているかを確認できたことと思います。")
print("特に、ノイズを含むクエリや、文書内容を直接示唆しない抽象的なクエリに対して、")
print("どれだけ正確に適切な文書が上位に抽出されているかに注目すると良いでしょう。")結果はこちら
🚀 Qwen-Embeddingモデルをロード中...
✅ モデル 'Qwen/Qwen3-Embedding-0.6B' のロードが完了しました。
================================================================================
✨ テクノロジーと現代社会 (ノイズ耐性/抽象度検証) ✨
🚀 14個のクエリ × 7個の文書で類似度を計算中 (Qwen-Embeddingモデル使用)...
📊 各クエリの上位3件の結果:
------------------------------------------------------------
🔍 Q1: 5Gとは何か?
1位 🌟 D1 (スコア: 0.7464): 5Gは第5世代移動通信システムの略で、高速・大容量、低遅延、多数同時接続が特徴です。
5Gは第5世代移動通信システムの略で、高速・大容量、低遅延、多数同時接続が特徴です。
2位 📄 D7 (スコア: 0.4541): IoT(モノのインターネット)は、様々な物理デバイスがインターネットに接続され、データの収集や遠隔操作を可能にする技術です。
IoT(モノのインターネット)は、様々な物理デバイスがインターネットに接続され、データの収集や遠隔操作を可能にする技術です。
3位 📄 D5 (スコア: 0.3177): ブロックチェーンは分散型台帳技術であり、データの改ざんが困難な信頼性の高いシステムを構築します。
ブロックチェーンは分散型台帳技術であり、データの改ざんが困難な信頼性の高いシステムを構築します。
🔍 Q2: 量子コンピューターの原理を教えてください。
1位 🌟 D2 (スコア: 0.7516): 量子コンピューターは量子力学の原理を利用し、従来のコンピューターでは解けない問題を高速に計算する次世代のコンピューターです。
量子コンピューターは量子力学の原理を利用し、従来のコンピューターでは解けない問題を高速に計算する次世代のコンピューターです。
2位 📄 D6 (スコア: 0.3983): クラウドコンピューティングは、インターネット経由でサーバーやストレージ、ソフトウェアなどのコンピューターリソースを提供するサービスです。
クラウドコンピューティングは、インターネット経由でサーバーやストレージ、ソフトウェアなどのコンピューターリソースを提供するサービスです。
3位 📄 D5 (スコア: 0.3263): ブロックチェーンは分散型台帳技術であり、データの改ざんが困難な信頼性の高いシステムを構築します。
ブロックチェーンは分散型台帳技術であり、データの改ざんが困難な信頼性の高いシステムを構築します。
🔍 Q3: サイバーセキュリティの脅威について。
1位 🌟 D3 (スコア: 0.5014): フィッシング詐欺は、偽のウェブサイトやメールを使って個人情報をだまし取るサイバー攻撃の一種です。
フィッシング詐欺は、偽のウェブサイトやメールを使って個人情報をだまし取るサイバー攻撃の一種です。
2位 📄 D5 (スコア: 0.3551): ブロックチェーンは分散型台帳技術であり、データの改ざんが困難な信頼性の高いシステムを構築します。
ブロックチェーンは分散型台帳技術であり、データの改ざんが困難な信頼性の高いシステムを構築します。
3位 📄 D6 (スコア: 0.3514): クラウドコンピューティングは、インターネット経由でサーバーやストレージ、ソフトウェアなどのコンピューターリソースを提供するサービスです。
クラウドコンピューティングは、インターネット経由でサーバーやストレージ、ソフトウェアなどのコンピューターリソースを提供するサービスです。
🔍 Q4: AIの倫理的課題について。
1位 🌟 D4 (スコア: 0.7620): AIの倫理的課題には、雇用への影響、プライバシーの侵害、差別的なバイアス、責任の所在などが挙げられます。
AIの倫理的課題には、雇用への影響、プライバシーの侵害、差別的なバイアス、責任の所在などが挙げられます。
2位 📄 D2 (スコア: 0.2820): 量子コンピューターは量子力学の原理を利用し、従来のコンピューターでは解けない問題を高速に計算する次世代のコンピューターです。
量子コンピューターは量子力学の原理を利用し、従来のコンピューターでは解けない問題を高速に計算する次世代のコンピューターです。
3位 📄 D7 (スコア: 0.2296): IoT(モノのインターネット)は、様々な物理デバイスがインターネットに接続され、データの収集や遠隔操作を可能にする技術です。
IoT(モノのインターネット)は、様々な物理デバイスがインターネットに接続され、データの収集や遠隔操作を可能にする技術です。
🔍 Q5: フィッシング詐欺とはなんですか?
1位 🌟 D3 (スコア: 0.5851): フィッシング詐欺は、偽のウェブサイトやメールを使って個人情報をだまし取るサイバー攻撃の一種です。
フィッシング詐欺は、偽のウェブサイトやメールを使って個人情報をだまし取るサイバー攻撃の一種です。
2位 📄 D7 (スコア: 0.2377): IoT(モノのインターネット)は、様々な物理デバイスがインターネットに接続され、データの収集や遠隔操作を可能にする技術です。
IoT(モノのインターネット)は、様々な物理デバイスがインターネットに接続され、データの収集や遠隔操作を可能にする技術です。
3位 📄 D2 (スコア: 0.2161): 量子コンピューターは量子力学の原理を利用し、従来のコンピューターでは解けない問題を高速に計算する次世代のコンピューターです。
量子コンピューターは量子力学の原理を利用し、従来のコンピューターでは解けない問題を高速に計算する次世代のコンピューターです。
🔍 Q6: フイッシング詐欺とはなんですか?
1位 🌟 D3 (スコア: 0.5755): フィッシング詐欺は、偽のウェブサイトやメールを使って個人情報をだまし取るサイバー攻撃の一種です。
フィッシング詐欺は、偽のウェブサイトやメールを使って個人情報をだまし取るサイバー攻撃の一種です。
2位 📄 D7 (スコア: 0.2272): IoT(モノのインターネット)は、様々な物理デバイスがインターネットに接続され、データの収集や遠隔操作を可能にする技術です。
IoT(モノのインターネット)は、様々な物理デバイスがインターネットに接続され、データの収集や遠隔操作を可能にする技術です。
3位 📄 D2 (スコア: 0.2165): 量子コンピューターは量子力学の原理を利用し、従来のコンピューターでは解けない問題を高速に計算する次世代のコンピューターです。
量子コンピューターは量子力学の原理を利用し、従来のコンピューターでは解けない問題を高速に計算する次世代のコンピューターです。
🔍 Q7: サイバーセキュリテイのキョウイについて。
1位 🌟 D3 (スコア: 0.3161): フィッシング詐欺は、偽のウェブサイトやメールを使って個人情報をだまし取るサイバー攻撃の一種です。
フィッシング詐欺は、偽のウェブサイトやメールを使って個人情報をだまし取るサイバー攻撃の一種です。
2位 📄 D5 (スコア: 0.2796): ブロックチェーンは分散型台帳技術であり、データの改ざんが困難な信頼性の高いシステムを構築します。
ブロックチェーンは分散型台帳技術であり、データの改ざんが困難な信頼性の高いシステムを構築します。
3位 📄 D2 (スコア: 0.2767): 量子コンピューターは量子力学の原理を利用し、従来のコンピューターでは解けない問題を高速に計算する次世代のコンピューターです。
量子コンピューターは量子力学の原理を利用し、従来のコンピューターでは解けない問題を高速に計算する次世代のコンピューターです。
🔍 Q8: AIの倫理的課題とか、そのへんの話。
1位 🌟 D4 (スコア: 0.7485): AIの倫理的課題には、雇用への影響、プライバシーの侵害、差別的なバイアス、責任の所在などが挙げられます。
AIの倫理的課題には、雇用への影響、プライバシーの侵害、差別的なバイアス、責任の所在などが挙げられます。
2位 📄 D2 (スコア: 0.3091): 量子コンピューターは量子力学の原理を利用し、従来のコンピューターでは解けない問題を高速に計算する次世代のコンピューターです。
量子コンピューターは量子力学の原理を利用し、従来のコンピューターでは解けない問題を高速に計算する次世代のコンピューターです。
3位 📄 D7 (スコア: 0.2536): IoT(モノのインターネット)は、様々な物理デバイスがインターネットに接続され、データの収集や遠隔操作を可能にする技術です。
IoT(モノのインターネット)は、様々な物理デバイスがインターネットに接続され、データの収集や遠隔操作を可能にする技術です。
🔍 Q9: 5Gって何?早く教えて!
1位 🌟 D1 (スコア: 0.7362): 5Gは第5世代移動通信システムの略で、高速・大容量、低遅延、多数同時接続が特徴です。
5Gは第5世代移動通信システムの略で、高速・大容量、低遅延、多数同時接続が特徴です。
2位 📄 D7 (スコア: 0.4430): IoT(モノのインターネット)は、様々な物理デバイスがインターネットに接続され、データの収集や遠隔操作を可能にする技術です。
IoT(モノのインターネット)は、様々な物理デバイスがインターネットに接続され、データの収集や遠隔操作を可能にする技術です。
3位 📄 D2 (スコア: 0.3566): 量子コンピューターは量子力学の原理を利用し、従来のコンピューターでは解けない問題を高速に計算する次世代のコンピューターです。
量子コンピューターは量子力学の原理を利用し、従来のコンピューターでは解けない問題を高速に計算する次世代のコンピューターです。
🔍 Q10: 未来の通信インフラについて。
1位 🌟 D1 (スコア: 0.4426): 5Gは第5世代移動通信システムの略で、高速・大容量、低遅延、多数同時接続が特徴です。
5Gは第5世代移動通信システムの略で、高速・大容量、低遅延、多数同時接続が特徴です。
2位 📄 D7 (スコア: 0.3340): IoT(モノのインターネット)は、様々な物理デバイスがインターネットに接続され、データの収集や遠隔操作を可能にする技術です。
IoT(モノのインターネット)は、様々な物理デバイスがインターネットに接続され、データの収集や遠隔操作を可能にする技術です。
3位 📄 D2 (スコア: 0.2922): 量子コンピューターは量子力学の原理を利用し、従来のコンピューターでは解けない問題を高速に計算する次世代のコンピューターです。
量子コンピューターは量子力学の原理を利用し、従来のコンピューターでは解けない問題を高速に計算する次世代のコンピューターです。
🔍 Q11: 次世代の計算機技術。
1位 🌟 D2 (スコア: 0.5822): 量子コンピューターは量子力学の原理を利用し、従来のコンピューターでは解けない問題を高速に計算する次世代のコンピューターです。
量子コンピューターは量子力学の原理を利用し、従来のコンピューターでは解けない問題を高速に計算する次世代のコンピューターです。
2位 📄 D1 (スコア: 0.3756): 5Gは第5世代移動通信システムの略で、高速・大容量、低遅延、多数同時接続が特徴です。
5Gは第5世代移動通信システムの略で、高速・大容量、低遅延、多数同時接続が特徴です。
3位 📄 D5 (スコア: 0.3449): ブロックチェーンは分散型台帳技術であり、データの改ざんが困難な信頼性の高いシステムを構築します。
ブロックチェーンは分散型台帳技術であり、データの改ざんが困難な信頼性の高いシステムを構築します。
🔍 Q12: データの信頼性を保証する技術。
1位 🌟 D5 (スコア: 0.6538): ブロックチェーンは分散型台帳技術であり、データの改ざんが困難な信頼性の高いシステムを構築します。
ブロックチェーンは分散型台帳技術であり、データの改ざんが困難な信頼性の高いシステムを構築します。
2位 📄 D7 (スコア: 0.3551): IoT(モノのインターネット)は、様々な物理デバイスがインターネットに接続され、データの収集や遠隔操作を可能にする技術です。
IoT(モノのインターネット)は、様々な物理デバイスがインターネットに接続され、データの収集や遠隔操作を可能にする技術です。
3位 📄 D2 (スコア: 0.3196): 量子コンピューターは量子力学の原理を利用し、従来のコンピューターでは解けない問題を高速に計算する次世代のコンピューターです。
量子コンピューターは量子力学の原理を利用し、従来のコンピューターでは解けない問題を高速に計算する次世代のコンピューターです。
🔍 Q13: インターネット上のリソース利用形態。
1位 🌟 D6 (スコア: 0.4621): クラウドコンピューティングは、インターネット経由でサーバーやストレージ、ソフトウェアなどのコンピューターリソースを提供するサービスです。
クラウドコンピューティングは、インターネット経由でサーバーやストレージ、ソフトウェアなどのコンピューターリソースを提供するサービスです。
2位 📄 D3 (スコア: 0.4002): フィッシング詐欺は、偽のウェブサイトやメールを使って個人情報をだまし取るサイバー攻撃の一種です。
フィッシング詐欺は、偽のウェブサイトやメールを使って個人情報をだまし取るサイバー攻撃の一種です。
3位 📄 D7 (スコア: 0.3757): IoT(モノのインターネット)は、様々な物理デバイスがインターネットに接続され、データの収集や遠隔操作を可能にする技術です。
IoT(モノのインターネット)は、様々な物理デバイスがインターネットに接続され、データの収集や遠隔操作を可能にする技術です。
🔍 Q14: あらゆるモノをネットに繋げる概念。
1位 🌟 D7 (スコア: 0.6493): IoT(モノのインターネット)は、様々な物理デバイスがインターネットに接続され、データの収集や遠隔操作を可能にする技術です。
IoT(モノのインターネット)は、様々な物理デバイスがインターネットに接続され、データの収集や遠隔操作を可能にする技術です。
2位 📄 D6 (スコア: 0.4728): クラウドコンピューティングは、インターネット経由でサーバーやストレージ、ソフトウェアなどのコンピューターリソースを提供するサービスです。
クラウドコンピューティングは、インターネット経由でサーバーやストレージ、ソフトウェアなどのコンピューターリソースを提供するサービスです。
3位 📄 D1 (スコア: 0.4319): 5Gは第5世代移動通信システムの略で、高速・大容量、低遅延、多数同時接続が特徴です。
5Gは第5世代移動通信システムの略で、高速・大容量、低遅延、多数同時接続が特徴です。
================================================================================
✨ 文学と哲学 (ノイズ耐性/抽象度検証) ✨
🚀 12個のクエリ × 6個の文書で類似度を計算中 (Qwen-Embeddingモデル使用)...
📊 各クエリの上位2件の結果:
------------------------------------------------------------
🔍 Q1: カントの哲学における主要な概念は?
1位 🌟 D1 (スコア: 0.6208): イマヌエル・カントの批判哲学では、純粋理性批判、実践理性批判、判断力批判の三部作が主要であり、義務論が重要な概念です。
イマヌエル・カントの批判哲学では、純粋理性批判、実践理性批判、判断力批判の三部作が主要であり、義務論が重要な概念です。
2位 📄 D5 (スコア: 0.3590): ニーチェは「神は死んだ」という言葉で知られるドイツの哲学者で、永劫回帰や力への意志などの概念を提唱しました。
ニーチェは「神は死んだ」という言葉で知られるドイツの哲学者で、永劫回帰や力への意志などの概念を提唱しました。
🔍 Q2: シェイクスピアの代表作は?
1位 🌟 D2 (スコア: 0.7044): ウィリアム・シェイクスピアの四大悲劇には、『ハムレット』、『オセロ』、『リア王』、『マクベス』があります。
ウィリアム・シェイクスピアの四大悲劇には、『ハムレット』、『オセロ』、『リア王』、『マクベス』があります。
2位 📄 D6 (スコア: 0.3158): 夏目漱石は明治・大正期の日本の小説家で、『こころ』や『吾輩は猫である』、『坊っちゃん』などの作品を残しました。
夏目漱石は明治・大正期の日本の小説家で、『こころ』や『吾輩は猫である』、『坊っちゃん』などの作品を残しました。
🔍 Q3: 自由意志に関する議論について教えて。
1位 🌟 D3 (スコア: 0.6640): 自由意志とは、人間の行動が外的要因や必然的な法則によって決定されるのではなく、自らの意思によって選択されるという思想です。
自由意志とは、人間の行動が外的要因や必然的な法則によって決定されるのではなく、自らの意思によって選択されるという思想です。
2位 📄 D1 (スコア: 0.4340): イマヌエル・カントの批判哲学では、純粋理性批判、実践理性批判、判断力批判の三部作が主要であり、義務論が重要な概念です。
イマヌエル・カントの批判哲学では、純粋理性批判、実践理性批判、判断力批判の三部作が主要であり、義務論が重要な概念です。
🔍 Q4: 徒然草の作者は誰ですか?
1位 🌟 D4 (スコア: 0.6264): 兼好法師は鎌倉時代末期から南北朝時代の歌人で、随筆『徒然草』の作者として知られています。
兼好法師は鎌倉時代末期から南北朝時代の歌人で、随筆『徒然草』の作者として知られています。
2位 📄 D6 (スコア: 0.3587): 夏目漱石は明治・大正期の日本の小説家で、『こころ』や『吾輩は猫である』、『坊っちゃん』などの作品を残しました。
夏目漱石は明治・大正期の日本の小説家で、『こころ』や『吾輩は猫である』、『坊っちゃん』などの作品を残しました。
🔍 Q5: シェークスピアの作品?
1位 🌟 D2 (スコア: 0.6891): ウィリアム・シェイクスピアの四大悲劇には、『ハムレット』、『オセロ』、『リア王』、『マクベス』があります。
ウィリアム・シェイクスピアの四大悲劇には、『ハムレット』、『オセロ』、『リア王』、『マクベス』があります。
2位 📄 D6 (スコア: 0.3369): 夏目漱石は明治・大正期の日本の小説家で、『こころ』や『吾輩は猫である』、『坊っちゃん』などの作品を残しました。
夏目漱石は明治・大正期の日本の小説家で、『こころ』や『吾輩は猫である』、『坊っちゃん』などの作品を残しました。
🔍 Q6: 徒然草のさくしゃはだれ?
1位 🌟 D4 (スコア: 0.5380): 兼好法師は鎌倉時代末期から南北朝時代の歌人で、随筆『徒然草』の作者として知られています。
兼好法師は鎌倉時代末期から南北朝時代の歌人で、随筆『徒然草』の作者として知られています。
2位 📄 D6 (スコア: 0.3431): 夏目漱石は明治・大正期の日本の小説家で、『こころ』や『吾輩は猫である』、『坊っちゃん』などの作品を残しました。
夏目漱石は明治・大正期の日本の小説家で、『こころ』や『吾輩は猫である』、『坊っちゃん』などの作品を残しました。
🔍 Q7: ニーチェについて知りたい。
1位 🌟 D5 (スコア: 0.6267): ニーチェは「神は死んだ」という言葉で知られるドイツの哲学者で、永劫回帰や力への意志などの概念を提唱しました。
ニーチェは「神は死んだ」という言葉で知られるドイツの哲学者で、永劫回帰や力への意志などの概念を提唱しました。
2位 📄 D1 (スコア: 0.2522): イマヌエル・カントの批判哲学では、純粋理性批判、実践理性批判、判断力批判の三部作が主要であり、義務論が重要な概念です。
イマヌエル・カントの批判哲学では、純粋理性批判、実践理性批判、判断力批判の三部作が主要であり、義務論が重要な概念です。
🔍 Q8: カントのテツガク。
1位 🌟 D1 (スコア: 0.4325): イマヌエル・カントの批判哲学では、純粋理性批判、実践理性批判、判断力批判の三部作が主要であり、義務論が重要な概念です。
イマヌエル・カントの批判哲学では、純粋理性批判、実践理性批判、判断力批判の三部作が主要であり、義務論が重要な概念です。
2位 📄 D5 (スコア: 0.3538): ニーチェは「神は死んだ」という言葉で知られるドイツの哲学者で、永劫回帰や力への意志などの概念を提唱しました。
ニーチェは「神は死んだ」という言葉で知られるドイツの哲学者で、永劫回帰や力への意志などの概念を提唱しました。
🔍 Q9: 倫理的な選択の自由について。
1位 🌟 D3 (スコア: 0.5750): 自由意志とは、人間の行動が外的要因や必然的な法則によって決定されるのではなく、自らの意思によって選択されるという思想です。
自由意志とは、人間の行動が外的要因や必然的な法則によって決定されるのではなく、自らの意思によって選択されるという思想です。
2位 📄 D1 (スコア: 0.3725): イマヌエル・カントの批判哲学では、純粋理性批判、実践理性批判、判断力批判の三部作が主要であり、義務論が重要な概念です。
イマヌエル・カントの批判哲学では、純粋理性批判、実践理性批判、判断力批判の三部作が主要であり、義務論が重要な概念です。
🔍 Q10: 義務に関する哲学的な考え方。
1位 🌟 D1 (スコア: 0.4936): イマヌエル・カントの批判哲学では、純粋理性批判、実践理性批判、判断力批判の三部作が主要であり、義務論が重要な概念です。
イマヌエル・カントの批判哲学では、純粋理性批判、実践理性批判、判断力批判の三部作が主要であり、義務論が重要な概念です。
2位 📄 D3 (スコア: 0.4009): 自由意志とは、人間の行動が外的要因や必然的な法則によって決定されるのではなく、自らの意思によって選択されるという思想です。
自由意志とは、人間の行動が外的要因や必然的な法則によって決定されるのではなく、自らの意思によって選択されるという思想です。
🔍 Q11: 日本の有名な近代文学の作家。
1位 🌟 D6 (スコア: 0.5319): 夏目漱石は明治・大正期の日本の小説家で、『こころ』や『吾輩は猫である』、『坊っちゃん』などの作品を残しました。
夏目漱石は明治・大正期の日本の小説家で、『こころ』や『吾輩は猫である』、『坊っちゃん』などの作品を残しました。
2位 📄 D4 (スコア: 0.4416): 兼好法師は鎌倉時代末期から南北朝時代の歌人で、随筆『徒然草』の作者として知られています。
兼好法師は鎌倉時代末期から南北朝時代の歌人で、随筆『徒然草』の作者として知られています。
🔍 Q12: ドイツの思想家の永劫回帰説。
1位 🌟 D5 (スコア: 0.6490): ニーチェは「神は死んだ」という言葉で知られるドイツの哲学者で、永劫回帰や力への意志などの概念を提唱しました。
ニーチェは「神は死んだ」という言葉で知られるドイツの哲学者で、永劫回帰や力への意志などの概念を提唱しました。
2位 📄 D3 (スコア: 0.3416): 自由意志とは、人間の行動が外的要因や必然的な法則によって決定されるのではなく、自らの意思によって選択されるという思想です。
自由意志とは、人間の行動が外的要因や必然的な法則によって決定されるのではなく、自らの意思によって選択されるという思想です。
🎉 全てのテストが完了しました!
Qwenモデルが、単なるキーワード一致だけでなく、多様な表現、軽微なノイズ、
そして抽象度の異なるクエリに対しても、意味的な類似性をどの程度捉えられているかを確認できたことと思います。
特に、ノイズを含むクエリや、文書内容を直接示唆しない抽象的なクエリに対して、
どれだけ正確に適切な文書が上位に抽出されているかに注目すると良いでしょう。結果を見ると「カントのテツガク。」としかクエリを与えていないにも関わらず適切に抽出してくれていたり、「日本の有名な近代文学の作家」というかなり抽象的な質問に対してもちゃんと回答をしてくれています。
テキストベースのものから検索などを行う場合には、Qwen3-Embeddingはかなり効果的なのではないでしょうか。
なお、Qwenベースの推論モデル【QwQ-32B-preview】について詳しく知りたい方は、下記の記事を合わせてご確認ください。

まとめ
本記事ではQwen3-Embeddingの概要からモデルの特徴、性能、使い方について解説をしました。検証で試したように、関連性の高いテキストを効率的に「検索・特定する」ことが可能でした。
これくらい高精度で検出できれば、精度の高いRAGも構築できそうですね。
ぜひ皆さんも本記事を参考にQwen3-Embeddingを使ってみてください。
最後に
いかがだったでしょうか
多言語かつ明示タスク対応。高精度な埋め込みモデルを活用し、RAGや検索体験を次のレベルへ進化させたい方へ。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

