
Stable Diffusion ローカル環境の構築方法!自由に遊ぶための完全ガイド

- Stable Diffusionのローカル構築でプロンプト・生成枚数の制限なく自由に画像生成
- AUTOMATIC1111 Web UI対応でプログラミング不要、GUIで簡単に操作可能
- 拡張機能や学習モデルの追加が自在で、高度なカスタマイズにも対応
Stable Diffusionは、テキストを入力するだけで高品質な画像を生成できる無料のAIです。ローカル環境を構築すれば、生成枚数やプロンプトの制限なく使い放題になります。
とはいえ「何から始めればいい?」「PCのスペックは足りる?」と悩む方も多いのではないでしょうか。この記事では、ローカル環境構築のメリット・デメリットから手順・エラー対処まで詳しく解説します。ぜひ最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
Stable Diffusionとは?
Stable Diffusionとは、誰でも無料で使える画像生成AIです。2022年8月に公開され、テキストや簡単な線画を入力するだけで高解像度の画像を生成できます。
「Web UI / AUTOMATIC1111」がおすすめ
Stable Diffusion Web UI(AUTOMATIC1111)は、GUIで手軽に画像生成ができる無料のアプリケーションです。プログラミング不要で操作でき、ローカルPCとクラウドサーバーのどちらにもインストールして使えます。
なお、AUTOMATIC1111以外にもStable Diffusion Web UIを使えるツールは複数あるため、それぞれの違いをまとめました。
| ツール名 | 特徴 | おすすめな人 |
|---|---|---|
| AUTOMATIC1111 | 最も普及している定番WebUIで、拡張機能や情報量が圧倒的に豊富。 | まずは安定した定番環境で始めたい初心者〜中級者。 |
| WebUI Forge | A1111を高速・省メモリ化した軽量版で、低VRAMでも動かしやすい。 | VRAMが少ないGPUやノートPCで効率よく生成したい人。 |
| SD.Next | A1111互換で拡張機能が充実し、高速化・最適化が進んだ強化フォーク。 | 最新機能を幅広く使いながら快適に運用したい中級〜上級者。 |
| ComfyUI | ノードベースでワークフローを自在に構築できる高機能UI。 | 生成工程を細かく制御したいクリエイター・上級者。 |
| Lavo.AI | Stable Diffusionをインストール不要で使えるオールインワンパッケージ。 | コマンドラインや設定に不安があり、とにかく手軽に始めたい初心者。 |
Stable Diffusion Web UIのツール比較表基本的には、定番のAUTOMATIC1111がおすすめですが、使用PCのスペックや用途によっては別のツールも検討してみてください。
「Web UI / AUTOMATIC1111」で利用できる機能
AUTOMATIC1111の主な機能は以下の3つです。
- txt2img:テキスト(プロンプト)から画像を生成
- img2img:既存の画像をもとに別の画像を生成(スタイル変更、スケッチからの描画など)
- Inpainting / Outpainting:画像の一部を修正したり、背景の拡張したりする機能
ゼロからの画像生成だけでなく、既存画像の加工・修正も可能です。拡張機能(Extensions)をインストールして機能を追加することもできます。
Stable Diffusion Web UIについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Stable Diffusionの特徴
Stable Diffusionの特徴について解説します。
リアル調からアニメ調まで画像生成が可能

上記は筆者が「Cute dog」で生成した犬の画像。
Stable Diffusionはリアルな人物像からアニメ風の美少女まで、多岐にわたる画像を生成できます。リアル調は映画のVFXやCG技術並の美しさを誇り、遠目から見れば現実と虚構の見分けがつかないほど精密な作りです。
アニメ調は流行りのグラデーションを用いており、イラストレーター風から平坦なVtuber風の色合いまで幅広く対応しています。Stable Diffusionが画像生成AIの中で人気な理由も、リアル調からアニメ調まで1つの技術で網羅できるからです。
ブラウザ&ローカル環境にて無料で使える
Stable DiffusionはWebブラウザもしくはローカル環境で無料で使うことが可能。ブラウザ上でStable Diffusionを使うメリットとしては、所有しているパソコンのスペックを問わず使用できること・特別な準備を必要とせず、すぐにStable Diffusionをブラウザ上で使えることです。
Stable Diffusionをブラウザで使う方法は、この後のWebブラウザ編で詳しく解説をします。
また、ローカル環境でもStable Diffusionは使えます。ローカル環境でStable Diffusionを使うメリットは完全無料で利用可能・生成枚数に制限なし・プロンプト制限なし・最新機能が試せるなどです。
より自由度の高い画像生成を行いたい場合にはローカル環境でStable Diffusionを使うのがおすすめ。ローカル環境でStable Diffusionを構築する方法をお伝えします!


ローカルで環境構築するメリット
この章では、Stable Diffusionをローカルで環境構築するメリットを解説していきます。
主なメリットは以下の3つです。
- 画像生成だけに集中できる
- 枚数・プロンプト制限がない
- 機能の追加も自由
それぞれを見ていきましょう!
画像生成だけに集中できる
Stable Diffusionをローカルで環境構築するメリットは、画像生成だけに集中できることです。仮にローカルで環境構築しなかった場合、以下の手間が発生することが多くあります。
- 作業中に課金が必要なケースがあり、手を止めなければならない
- クラウド環境を立ち上げるたびに10分程度待つ必要がある
- 制作中にセッションが切れて、成果物が保存されていない可能性がある
このような状況になってしまっては、画像生成に集中できませんよね。
一方で、ある程度のスペックを持ったパソコンを用意しローカルで環境構築した場合は、上記に記載の手間はかかりません。
- クレジットのような制限がないため、夜中も動かしていても料金の心配がいらない
- 立ち上げに時間がかからないため、すぐ作業が行える
- デバッグができるため、成果物の進み具合を把握できる
このようにローカルで環境構築することで、画像生成だけに集中しやすくなるメリットがあるのです。
枚数・プロンプト制限がない
Stable Diffusionをローカルで環境構築すると、枚数・プロンプト制限がありません。クラウド環境で利用する場合は、使用量に応じた料金が発生するか、利用できる範囲が限られます。
しかし、ローカルで環境構築すれば、枚数やプロンプトの制限はありません。プロジェクトを進めるうえで制限があると進めづらいこともあるため、ローカル構築で使用制限がなくなるのは、大きなメリットの1つです。
機能の追加も自由
Stable Diffusionはオープンソースで公開されているため、必要に応じて機能の追加が自由にできます。必要な機能を開発して追加したり、システム同士を連携させたりという改良もしやすく、開発の自由度が高いのが魅力です。
さらには、Stable Diffusionの利用者も増加しているため、利用者同士で情報共有が行われており、その中で便利な使い方やカスタマイズのヒントを紹介していることもあります。


ローカルで環境構築するデメリット
この章では、Stable Diffusionをローカルで環境構築するデメリットを解説していきます。
- 環境構築に手間がかかる
- 高スペック&GPU搭載型PCでないと画像生成の速度が遅くなる
環境構築に手間がかかる
Stable Diffusionをローカルで環境構築するためにかなりの手間がかかるのが、大きなデメリットです。
1つのツールをインストールするだけでは、Stable Diffusionを使えないため、初心者には難しいと感じられるかもしれません。詳しい環境構築の方法は別の章で解説しますが、ローカル環境構築の主な流れは以下のとおりです。
なお、扱うツールはStable Diffusion Web UIです。
- Pythonのインストール
- gitのインストール
- Stable Diffusion Web UIのインストール
高スペック&GPU搭載型PCでないと画像生成の速度が遅くなる
ローカルで環境構築する場合、高スペック&GPU搭載型のPCでなければ、Stable Diffusionの画像生成速度が遅くなります。Stable Diffusion Web UIをインストールするローカルPCのスペックは以下のとおりです。
| Windows | Mac | |
|---|---|---|
| 必要スペック | CPU:6コア以上(Core i5-11400/Ryzen 5 5600以上) メモリ:16GBGPU(VRAM):4GB(GTX 1650以上) ストレージ:250GB | チップ:Apple M1 メモリ:16GB ストレージ:256GB |
| 推奨スペック | CPU:8コア(Core i7-9700T/Ryzen 7 1700以上) メモリ:32GBGPU(VRAM):12GB(RTX 3060以上) ストレージ:512GB | チップ:Apple M1 Pro以上 メモリ:32GBストレージ:512GB |
動作スペックに関する公式情報はGitHubに記載されていますが、「NVIDIA GPU 推奨」「4GBのビデオカードをサポート」といった最低限のスペックしか記載されていません。上記は、あくまで公式情報を基に、現実的なスペックに置き換えた場合の動作スペックをまとめて記載しています。
Stable Diffusionをローカルで構築するための推奨環境
| Windows | Mac | |
|---|---|---|
| 必要スペック | CPU:6コア以上(Core i5-11400/Ryzen 5 5600以上) メモリ:16GBGPU(VRAM):4GB(GTX 1650以上) ストレージ:250GB | チップ:Apple M1 メモリ:16GB ストレージ:256GB |
| 推奨スペック | CPU:8コア(Core i7-9700T/Ryzen 7 1700以上) メモリ:32GBGPU(VRAM):12GB(RTX 3060以上) ストレージ:512GB | チップ:Apple M1 Pro以上 メモリ:32GB ストレージ:512GB |
Stable Diffusionをローカル環境で構築するためには上記の推奨環境を整える必要があります。なお、求められるスペックは、使用モデルによっても異なるので注意が必要です。
- SD1.5→VRAM 4〜6GBでもなんとか動く
- SDXL→VRAM 8GB 以上推奨
- SD3・SD3.5→VRAM 12GB 以上あると安心
推奨環境を確認せずインストールを進めてしまうと、使った時間が無駄になって後悔するかもしれません。必ず推奨環境は確認するようにしましょう。
Windowsのバージョン確認方法
まずはWindowsのバージョンを確認しましょう。確認は以下の流れで行います。
- 「Windows」アイコン→「設定」アイコンを選択
- 「システム」を選択
- 「バージョン情報」を選択
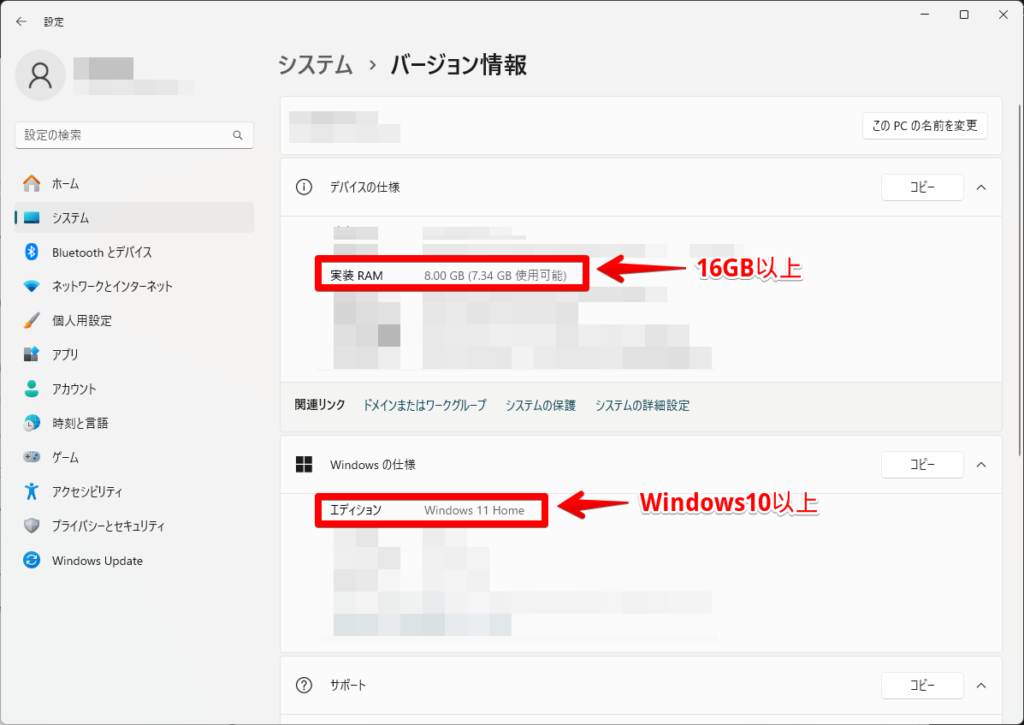
- Windowsのバージョンを確認
この時、以下のバージョン以上が搭載されていれば、Windowsのバージョン確認は完了です。
- 実装RAM:16GB以上
- エディション:Windows10以上
PCスペックの確認方法
Stable Diffusionをローカル環境で構築する場合のPCスペックの確認方法を紹介します。
- 「Windows」アイコン→「dxdiag」と入力し選択
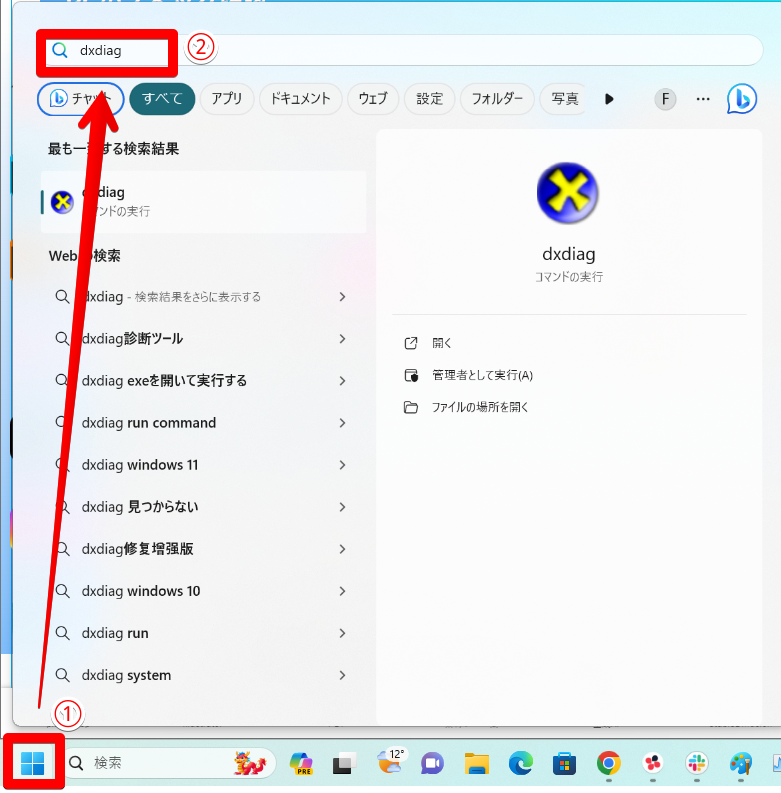
- 「ディスプレイ1」を選択
- 「チップの種類」と「表示メモリ(VRAM)」を確認
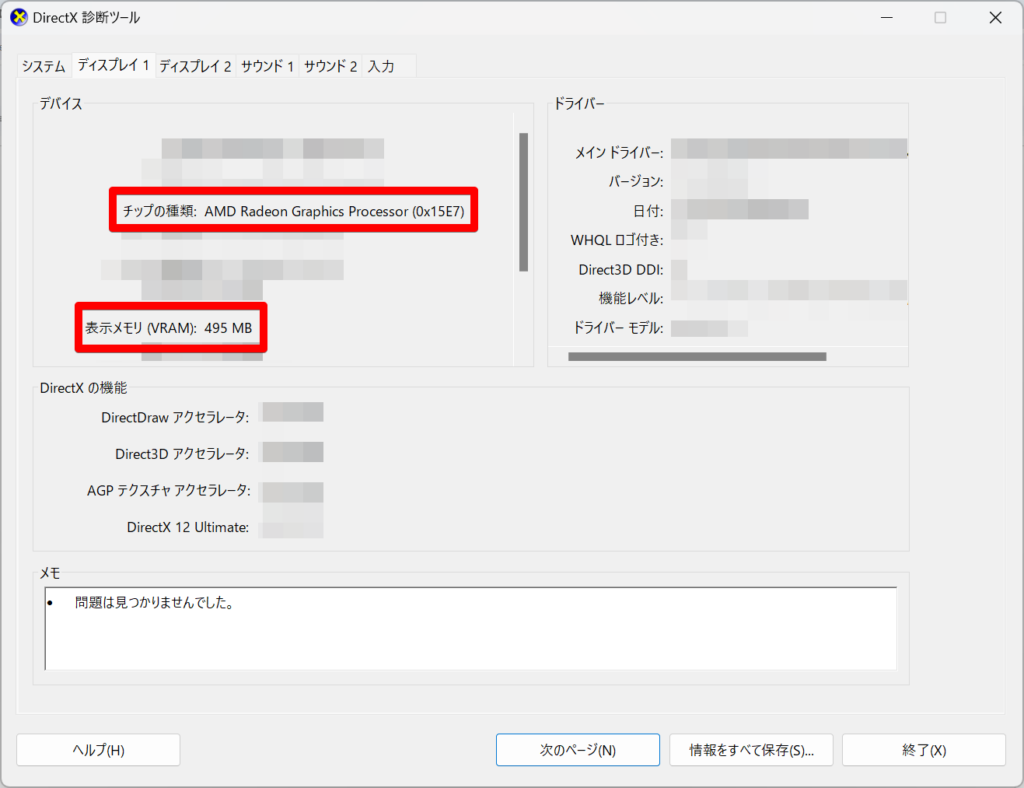
チップの種類が、NVDIA製のものが推奨です。
Stable Diffusion Web UIは、もともとNVDIA製のグラフィックボード向けに作られているため、NVDIA製のものが推奨されています。
AMD製のグラフィックボードでも動作しないわけではないですが、不具合があったときの情報が得られない可能性があります。また、表示メモリ(VRAM)は12GB以上が推奨です。
生成AIでの自動化について詳しく知りたい方は、下記の記事を合わせてご確認ください

Stable Diffusionの環境構築方法
実際にStable Diffusionをローカル環境にインストールする方法を解説します。
環境構築の手順を間違えると、上手く動作しなかったり、最悪の場合は再構築が必要になったりしますので、この章の内容を確認しながら、進めるようにしてください。
Pythonのインストール
Stable Diffusionを使うために、まずは、Pythonをインストールします。WebUIが安定して動作するバージョンは「3.10.6」のため、他のバージョンが入っている場合は、「3.10.6」を改めてインストールしましょう。
Pythonのバージョン確認方法
Stable DiffusionをインストールしようとしているPCに入っているPythonのバージョンを確認する方法を解説します。
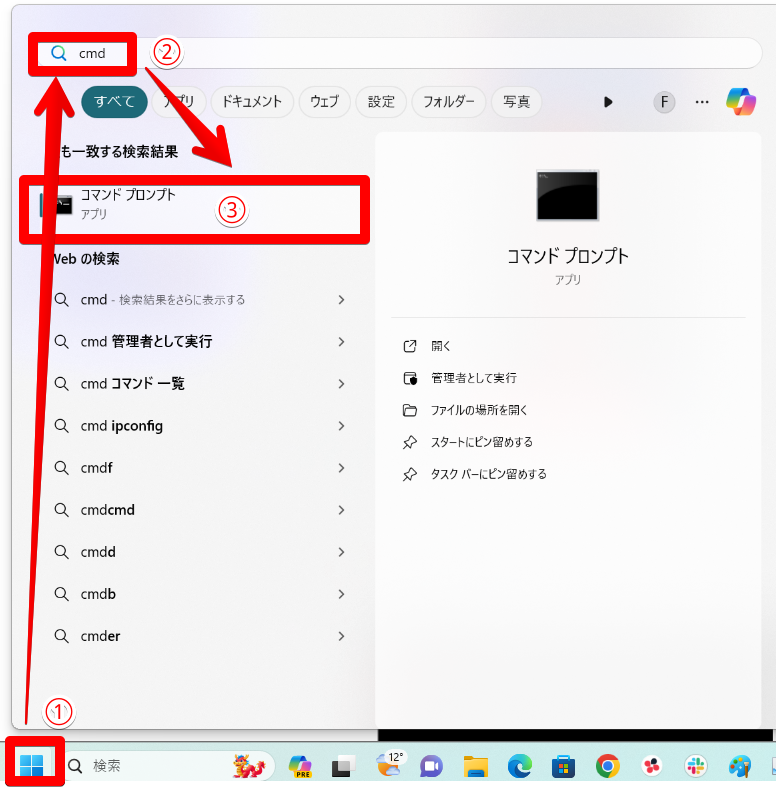
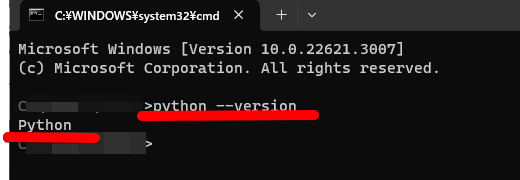
上記画像のように「Python」とだけ表示されている場合は、インストールされていません。バージョンが表示されている場合、「3.10.6」であればStable Diffusionをインストールできます。表示されているバージョンが「3.10.6」以外の場合は、アンインストールが必要です。
違うバージョンが入っていてPythonをアンインストールする方法
Pythonのバージョンで「3.10.6」以外が入っている場合は、基本的にアンインストールが必要です。Pythonをアンインストール方法を解説します。
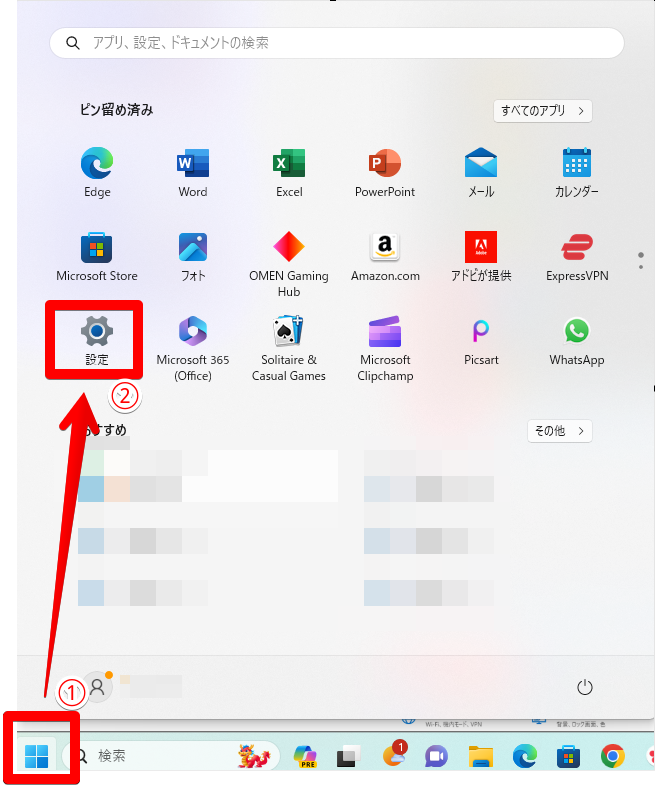
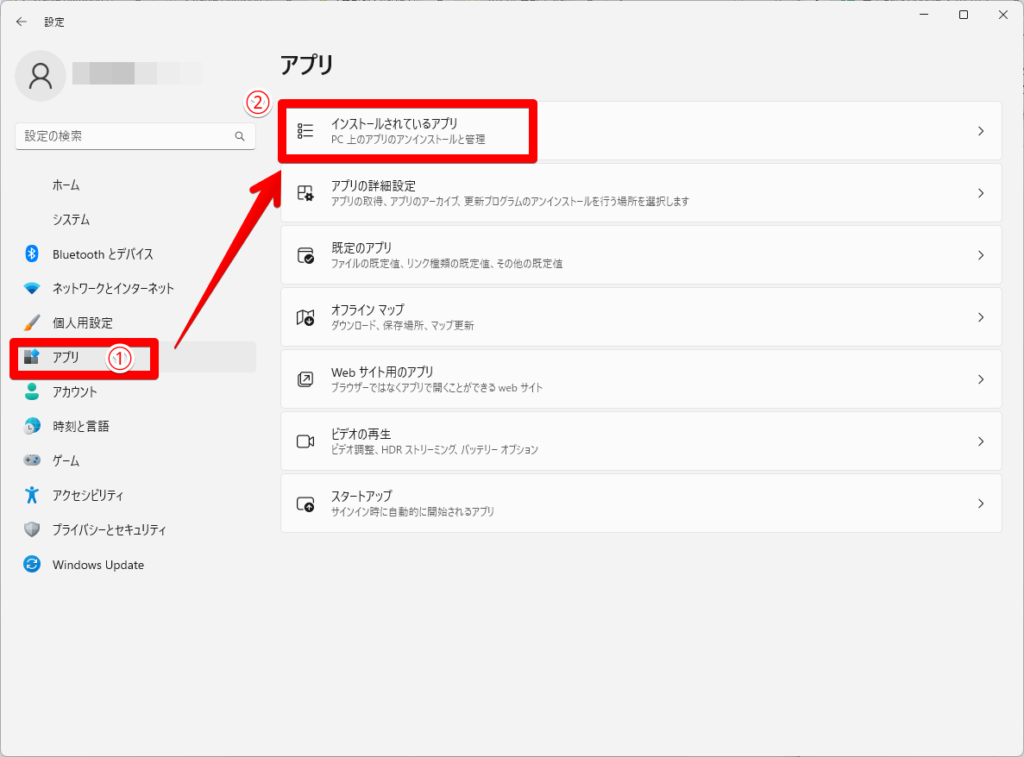
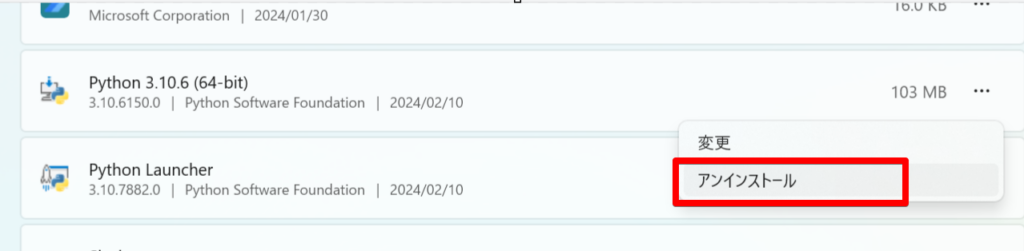
これでPythonのアンインストールは完了です。
Pythonのインストール方法
Python「3.10.6」をインストールする方法を解説します。
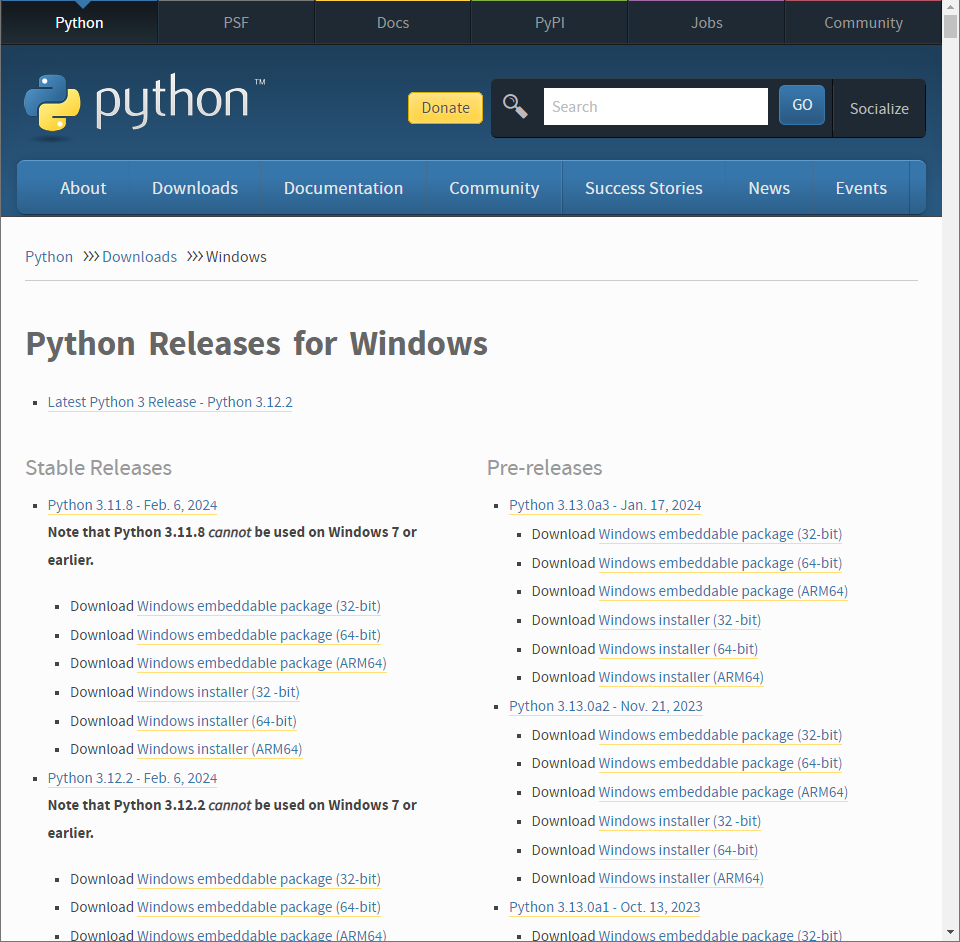
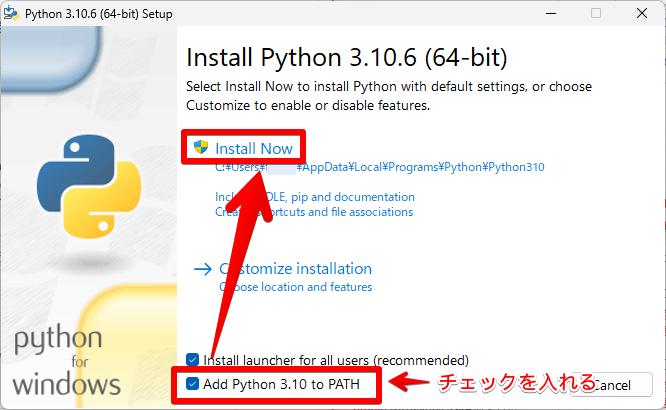
「Add Python 3.10 to PATH」にチェックを入れ「Install Now」を選択
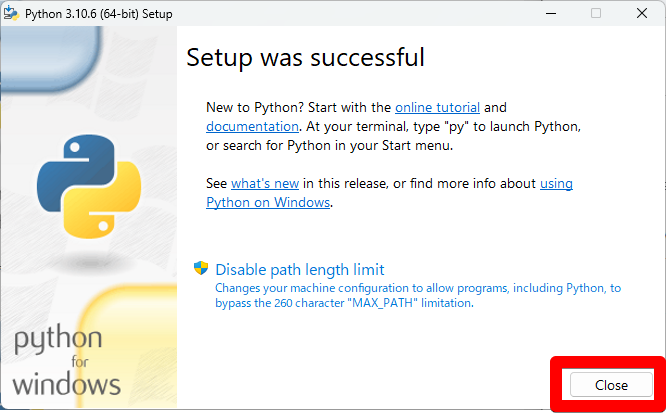
これでPythonのインストールは完了です。
gitのインストール
Pythonのインストールが完了したら、次にgitをインストールします。
これで、gitのインストールは完了です。
Stable Diffusion Web UIのインストール
Stable Diffusion Web UIのインストール方法を解説します。
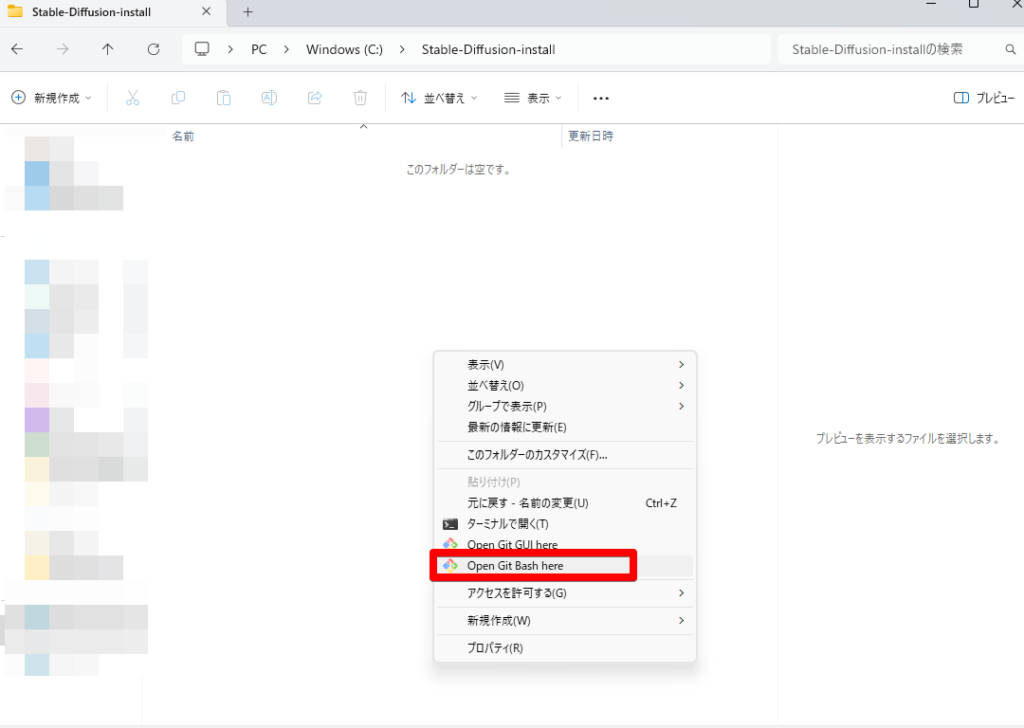
容量に余裕がある場所に作成するのがおすすめです。
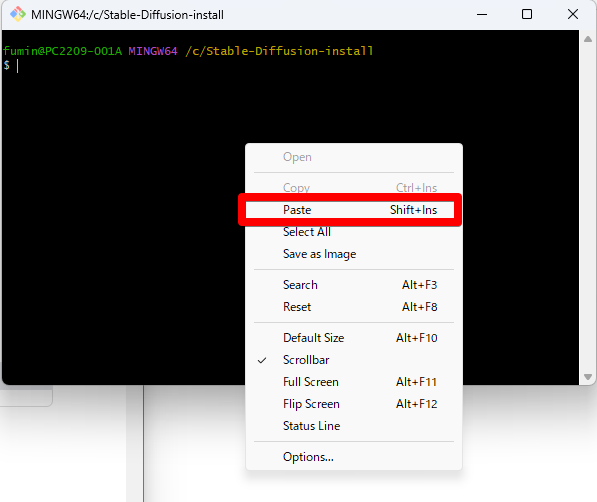
コマンド「git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git」※貼り付けは、右クリック→「Paste」で行いましょう。
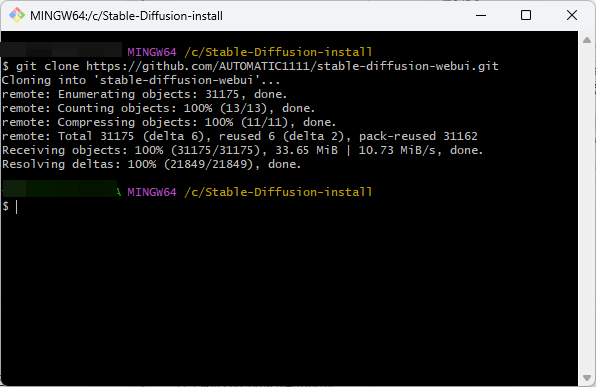
Stable Diffusion Web UIを使うために、作成したフォルダ→「stable-diffusion-webui」→下から2番目の「webui-user.bat」をクリックします。
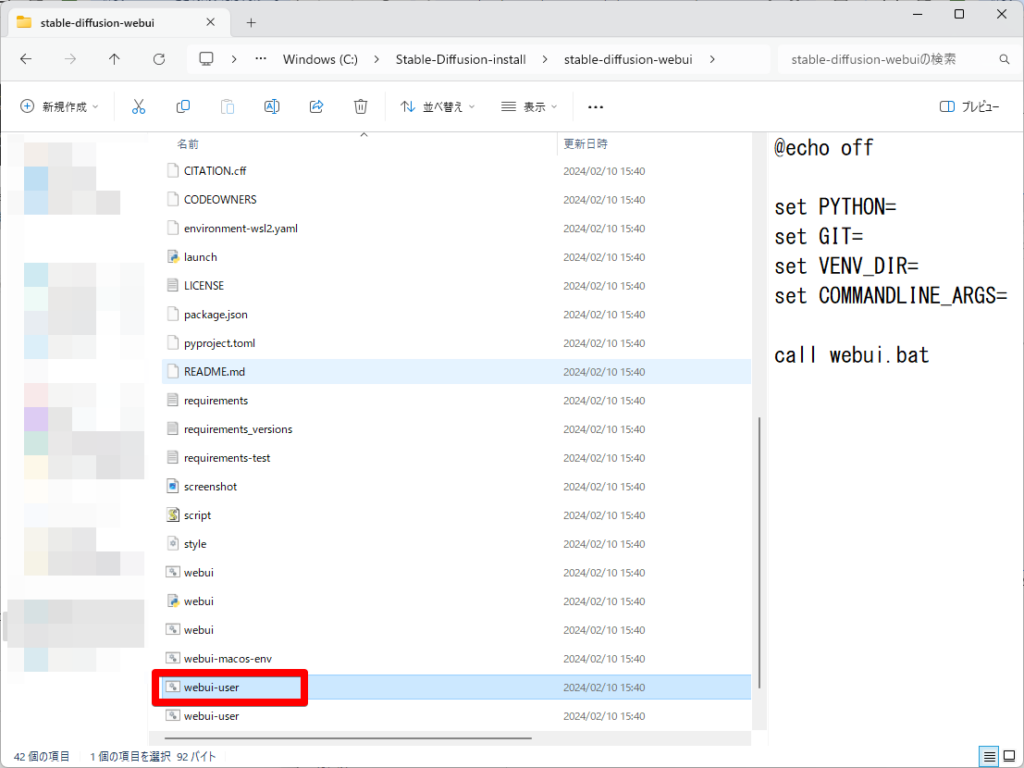
Stable Diffusion Web UIの起動プロンプトが立ち上がり、完了するまで待ちます。
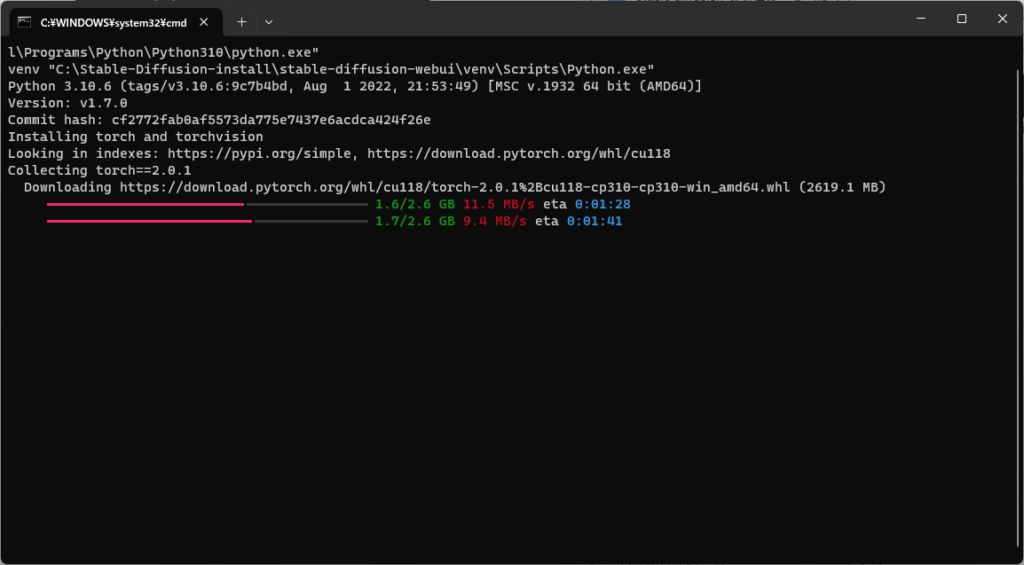
実行し終わったら「http://127.0.0.1:7860/」をブラウザ上に入力するとStable Diffusionを使えるようになります。
パソコンによって上記の方法ではうまくインストールされないケースがあります。その際は、以下の手順を試してみてください。
- Stable Diffusion Web UIを使うために、作成したフォルダを開く
- 「stable-diffusion-webui」を選択
- 下から2番目の「webui-user.bat」をテキストで開く
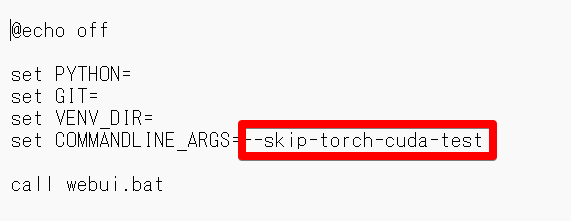
- 「set COMMANDLINE_ARGS=」の後ろに「–skip-torch-cuda-test」と入力し、保存
- 下から2番目の「webui-user.bat」を実行
WebUI Forgeで構築したい場合
VRAMが少ないPCや、より高速に生成したい場合はWebUI Forgeも選択肢の1つです。AUTOMATIC1111と操作感はほぼ同じで、既存の拡張機能もほとんど動作します。
インストール手順はAUTOMATIC1111と同様で、クローン先のURLが異なるだけです。
git clone https://github.com/lllyasviel/stable-diffusion-webui-forge.gitあとはAUTOMATIC1111と同じく `webui-user.bat` を実行して起動します。VRAM 4〜6GB環境でも動かせることが多く、A1111では重くて使えなかったモデルを試せるのが利点です。
生成AIを使った業務効率化について詳しく知りたい方は、下記の記事を合わせてご確認ください

構築後にやるべき初期設定とカスタマイズ
Stable Diffusionをローカル環境に入れたあと、最初に少し設定を見直すだけで、かなり使いやすくなります。生成した画像をどこに保存するか、ファイル名をどう付けるかを自分のやり方に合わせておくと、あとで探す手間が減ります。
画像サイズやステップ数、使うサンプラーなども、毎回設定し直すのは面倒なので、よく使う値をあらかじめデフォルトにしておくと良いでしょう。
| 項目 | 初心者向けおすすめ値 | 補足 |
|---|---|---|
| 画像サイズ | 512×768(縦) / 768×512(横) | 解像度が大きいほどVRAMを消費するため、まずは中程度のサイズが安全。 |
| Steps(ステップ数) | 20〜30 | ステップを増やすほど描写は細かくなるが、生成が遅くなる。20前後で十分安定。 |
| CFG Scale | 7 前後 | プロンプトの忠実度を調整する値。高すぎると破綻しやすいので7〜8が標準。 |
| Sampler | DPM++ 2M Karras | 品質・速度のバランスが良く、2024〜2025年の標準的な推奨サンプラー。 |
初期設定でやっておくべきおすすめ項目は以下の通りです。
- 出力フォルダの変更(用途ごとにフォルダを分けると管理しやすい)
- ファイル名フォーマットの設定([seed]_[sampler]_[steps]など)
- 履歴保存をON(生成設定・プロンプトを自動保存)
- xformers / Triton など高速化オプションの有効化(可能な環境のみ)
- VAEの選択・固定(色味・コントラストが安定する)
- ControlNet の ON/OFF・モデル軽量化設定の確認(VRAMの使いすぎ防止)
- Clip Skip の調整(通常は1)
画面レイアウトも自由に変えられるので、作業しやすい配置にしておくと快適です。
環境構築ができない時の対処方法
Stable Diffusionをローカル環境にインストールしようとしたものの、うまく起動しなかったり、エラーが出たりして困っていませんか?
ここでは、よくあるトラブルとその対処法を分かりやすく解説します。
事前チェック
トラブルの原因を特定するために、以下のポイントをチェックしましょう。
- Pythonのバージョンが3.10.6になっているか
- Gitが正しくインストールされているか、git –version で確認
- GPUドライバが最新か確認し、NVIDIAの公式サイトでアップデート
- CUDAとcuDNNのバージョンが適切か(NVIDIAのGPUを使用する場合)
- 十分なVRAM(4GB以上)とストレージの空き(20GB以上)があるか
もしここで問題が見つかった場合は、適切に対応してから次のステップに進んでください。
Python関連のエラー
エラーメッセージ「Python was not found」は、Pythonがインストールされていない、または環境変数に登録されていないこと(実行ファイルを正しく認識できていない状態)を意味します。前の章で解説している「Pythonのインストール方法」を見ながらインストールをしてください。
また、「No module named ‘torch’」はPyTorchが正しくインストールされていないことを意味します。この場合、「pip install torch torchvision torchaudio –index-url https://download.pytorch.org/whl/cu121」コマンドを実行して、PyTorchを手動でインストールしてみてください。
Git関連のエラー
エラーメッセージ「git is not recognized as an internal or external command」は、Gitがインストールされていない、または環境変数に登録されていないことを意味します。前の章で解説している「gitのインストール」を見ながらインストールをしてください。
Web UIが起動しないときの対処法
| エラーメッセージ例 | 主な原因 | 対処法(要点のみ) |
|---|---|---|
| CUDA out of memory | VRAM不足で、指定の解像度・バッチサイズ・モデルがGPUに載り切らない | 画像サイズを下げる/Batchを1にする/steps削減/–medvram・–lowvram 起動/xformersを有効化する |
| Torch not compiled with CUDA enabled | PyTorchがCPU版になっている/GPUドライバ・CUDA Toolkitとの不整合でGPUを認識できない | NVIDIAドライバ更新/CUDA Toolkit再インストール/PyTorch(CUDA版)再インストール/venvを作り直して自動セットアップ |
| 黒画像・緑画像になる/NansException | half精度計算とモデル・VAEの相性でNaNが発生し、推論が破綻している | –precision full –no-half/–no-half-vae でフル精度に切り替え/モデル・VAEを変更/ドライバ・PyTorch更新 |
Web UIが起動しないときの原因と対処法一覧を上記表にまとめました。
まず、webui-user.bat を実行しても何も起こらない、または画面が真っ黒なままの場合は、依存ライブラリのインストールが失敗している可能性があります。解決するために、stable-diffusion-webui フォルダを開き「git pull」コマンドを実行します。さらに、venv フォルダを削除し、依存関係を再インストール(本記事「Stable Diffusion Web UIのインストール」の章で解説)してみてください。
また、「CUDA out of memory. Tried to allocate X GiB」というエラーメッセージが出る場合は、GPUのメモリが足りないことを意味します。stable-diffusion-webui/webui-user.bat をメモ帳で開き、「set COMMANDLINE_ARGS=–medvram」を1行追加することで改善可能です。
それでも解決しない場合
もし上記の方法を試してもVRAM不足の問題が解決しない場合は、エラーメッセージをGoogleで検索してみるのも有効です。同じエラーに直面したユーザーが解決策を共有していることが多いため、具体的な対処法が見つかる可能性があります。
【Webブラウザ編】Stable Diffusionの使い方4選!
Stable Diffusionは2025年7月11日時点で7つのブラウザ版があります。
- Clipdrop
- Hugging Face
- Dream Studio
- Mage.space
- Stable Diffusion Online
- Fotographer.ai
- romptn Image Generator
まずは最も有名なClipdropの使い方から説明します。
Clipdropでの使い方基礎
Clipdropは3つの方法で画像を生成できます。
- Stable Diffusion XL
- Reimagine XL
- Stable Doodle
まずは王道のプロンプト記述で画像を生成する「Stable Diffusion XL」からお伝えします。
Stable Diffusion XL
Stable Diffusion XLはプロンプト(指示)を出して、AI画像を生成する方法です。指示出しが細かくできる方法のため、生成画像の出来にこだわりたい方におすすめ。対応している指示言語は英語のみでしたが、2023年11月17日より「Japanese Stable Diffusion XL」として日本語対応版もリリースされました。
ただし、2023年11月21日から有料化されたため、現在は無料版の利用ができません。ブラウザ版を使いたい方は、1ヶ月または1年の有料課金が必要です。
Reimagine XL
Reimagine XLは画像をアップロードして、類似した画像をAIで生成する方法です。3つの方法の中では、最も手軽なため初心者におすすめの手法です。
フリー画像サイトで取得した画像、ご自身の手元にある写真、オリジナルで描いた絵をアップロードすると、Stable Diffusionが自動で変換してくれます。
ただしStable Diffusion XLやStable Doodleとは違い、細かい指定ができません。AIが生成した画像を出力するだけなので、こだわりたい方には不向きです。
Stable Doodle
Stable DoodleはStable Diffusion XLより直感的な手法です。スケッチしたラフ絵を元に、ご自身が描いた絵の内容をプロンプトで説明し、AIで生成させます。生成する際もピクセルアート、3D、写真、ファンタジーなど複数の描き方から選べます。
※Stable DoodleはStable Diffusion XLと同じく、すでに有料化されてしまっています。
Hugging Faceでの使い方基礎
Hugging Faceの使い方は簡単です。
- Hugging Face(https://huggingface.co/spaces)にアクセス
- 検索窓に「Stability AI」と入力
- 「stable-diffusion-2」を探す
- Inputの箇所にプロンプトを英語で記述
- 送信ボタンを押す
上記手順で画像が自動で生成されます。実際に上記手順に従い、画像を自動生成する流れを示します。詳しい利用方法は画像を使いながらご説明します。
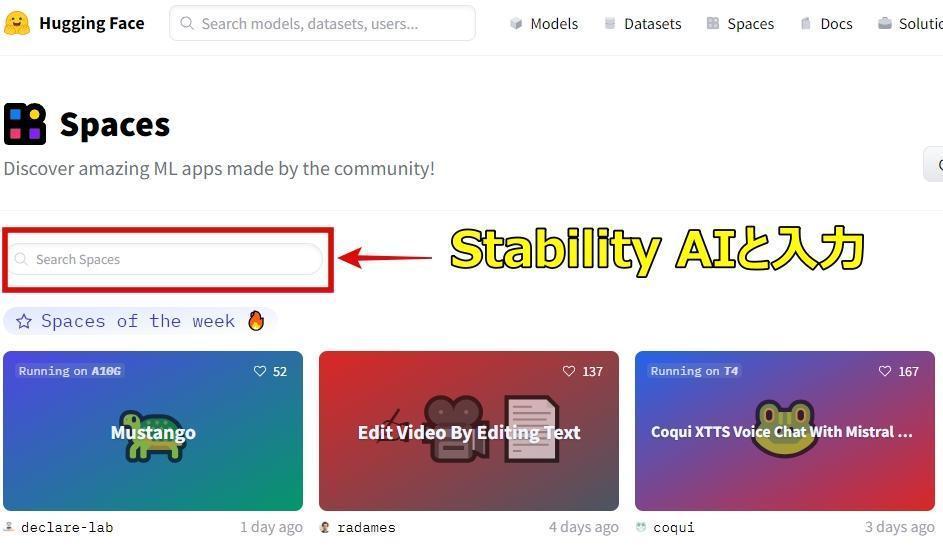
1:Hugging Faceのトップページを開き、検索窓にStability AIと入力
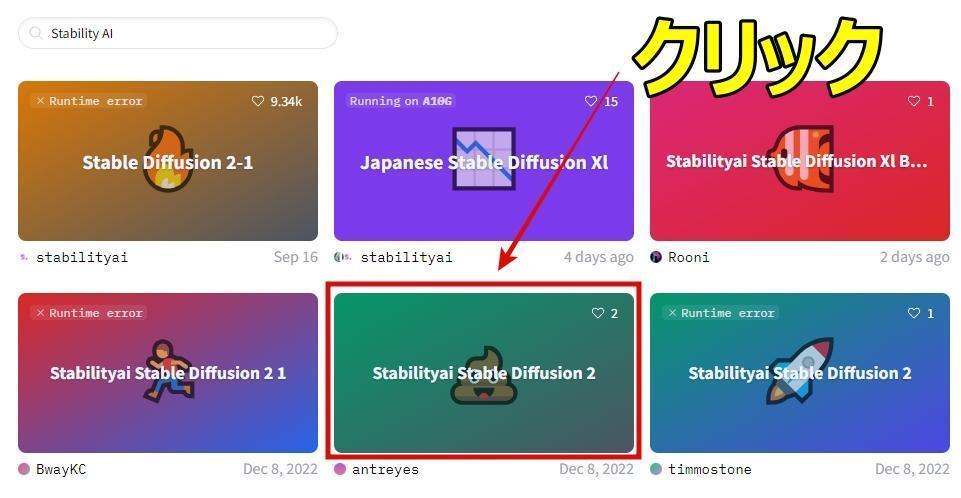
2:stable-diffusion-2のアイキャッチをクリック
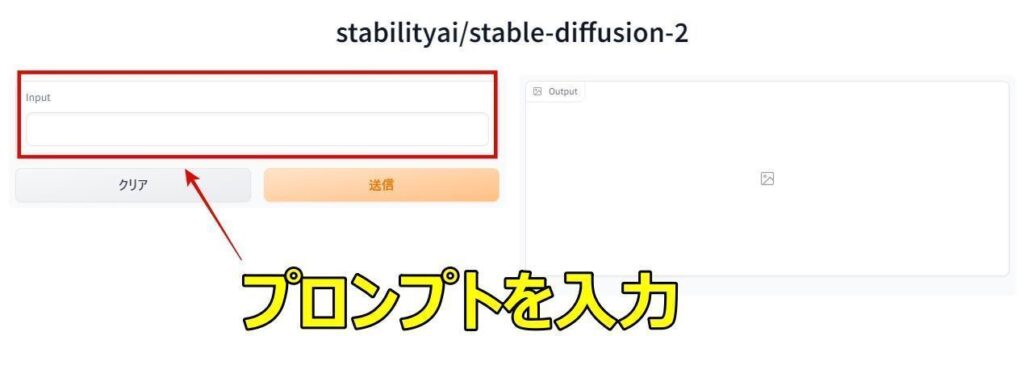
3:Inputの箇所にプロンプトを英語で記述
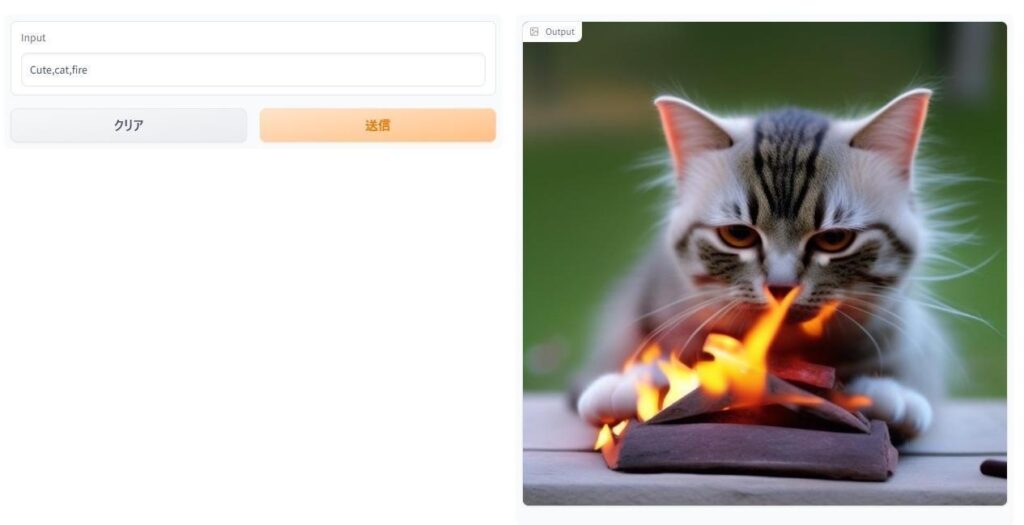
4:プロンプトを送信したら自動で画像が生成される
Dream Studioでの使い方基礎
DreamStudioはStable Diffusionのオープンβ版として公開されたサービスです。
使い方も簡単で、以下の手順を踏んでください。
- DreamStudioにアカウントを作ってログイン
- 画像生成のスタイルを選択
- プロンプトを入力
- ネガティブプロンプトを入力
- イメージ画像をアップロード
- 解像度の調整
- 生成枚数や大きさなど微調整
- 所持クレジットを消費して画像を生成
複雑なように見えますが、一連の手順自体は簡素です。一度操作に慣れれば、簡単に感じられるでしょう。ここからは、分かりやすいように画像を用いて利用方法をご紹介します。
1:DreamStudioトップページに遷移
2:アカウント作成
Googleアカウント、Discord、新規作成から選びましょう。
筆者はGoogleアカウントでログインしました。
3:画像生成を開始
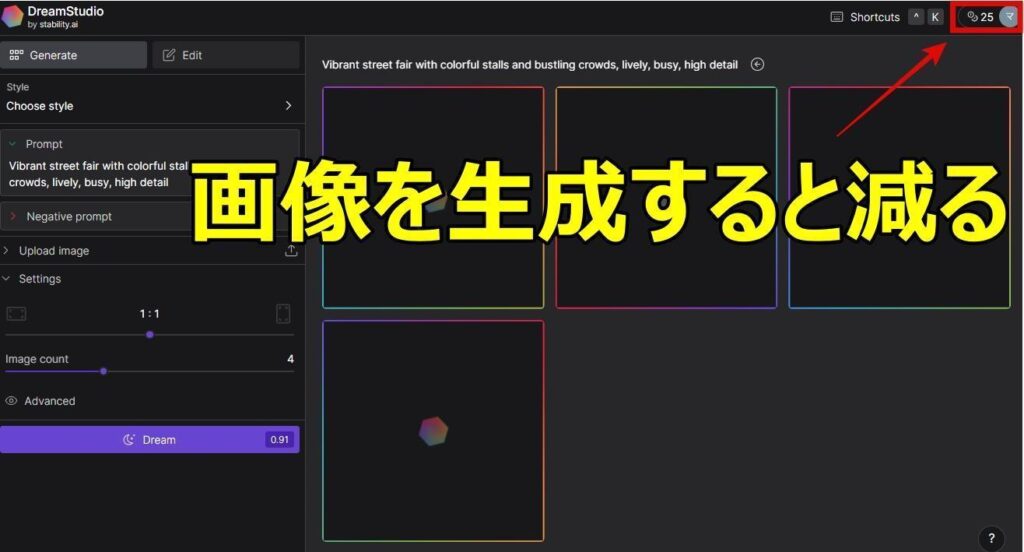
無事にログインすると、画面右上に「25」と「アカウントマーク」が出ます。
「25」という数字はクレジットです。
DreamStudioは画像生成する度に、一定のクレジット数を消費していくシステム。ゼロになれば画像が生成できません。
Mage.spaceでの使い方基礎
Mage.spaceもStable Diffusionをオンライン上で使えるサービスの一つです。使い方もシンプルで、以下の手順を踏めば、すぐに画像が生成できます。
- 「https://www.mage.space/」へアクセス
- 「create anything」の下にプロンプトを記述
- 「→」マークを押せば画像生成開始
Mage.spaceも無料版、有料版の2つがあります。有料版は月額15ドルになりますが、切り替えるとモデル数も136に増えます。
Fotographer.ai
Fotographer.aiは広告クリエイターやEC事業者などの業務に関わる人向けにサイト内やマーケティングに使用する商品の画像を生成できるAIサイトです。
Fotographer.aiでも画像生成が可能であり、長いプロンプトを書かずとも自動で高品質な画像が出力されます。また、簡単な操作でLoRAの生成も可能。数枚の画像をAIが自動学習して、画像生成に使うことができます。
Stable Diffusion Online
Stable Diffusion OnlineはStable DiffusionをWebブラウザで使うことができるサービスです。
無料でも使うことができますが、生成した画像にウォーターマークが入ってしまいます。また、モデルの変更もできません。自由度は低いですが、手軽にStable Diffusionを使ってみたい・Stable Diffusionをはじめて使うからどんなもんなのか試してみたい、という方にStable Diffusion Onlineはおすすめです。
年間支払いだと以下の金額です。
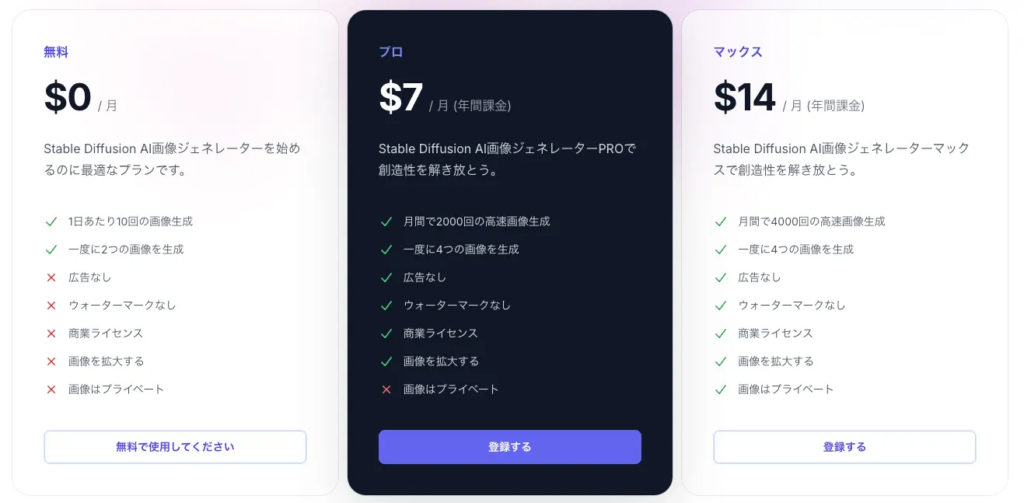
月額でこちら。
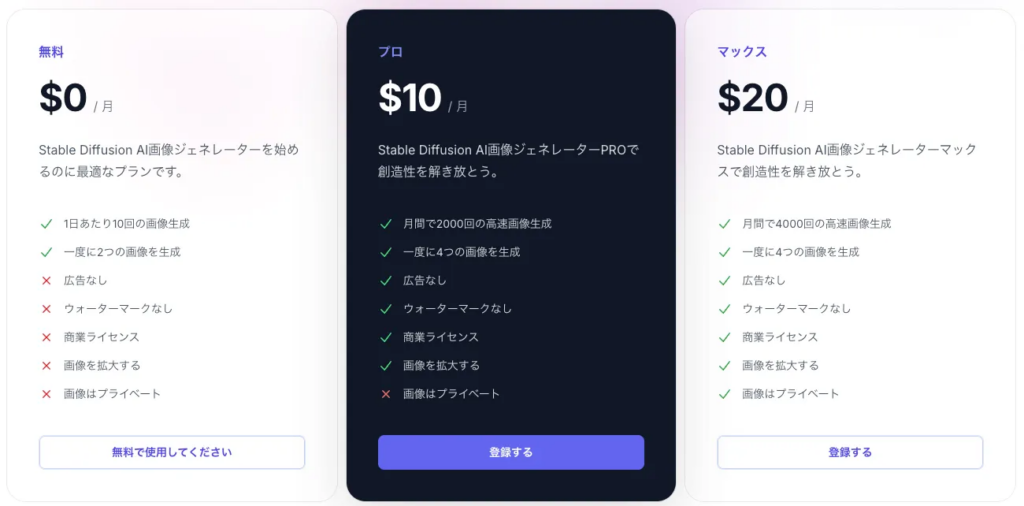
romptn Image Generator
「romptn Image Generator」はなんと、登録不要・完全無料で何回でもStable Diffusionによる画像生成が楽しめるサービスです。こちらの使い方は超簡単で、以下のとおりプロンプト・ネガティブプロンプト・スタイルの3項目を指定するだけで画像が生成できちゃいます。
- romptnのImage Generatorのページにアクセス
- プロンプト(必須)とネガティブプロンプト(任意)を入力
- 「アニメ」か「リアル」のスタイルを選択
- 「無料で画像を生成する」をクリックして1分ほど待つ
ちなみに、生成できる画像はどんな感じなのかというと……

このように、かなりのクオリティ。以下の簡単設定だけで、萌えイラストが生成できちゃいました。
- プロンプト:A girl with pink twintail is dancing in a city
- ネガティブプロンプト:bad face , worst quality
- 「アニメ」スタイルを選択
こちらのromptn Image Generatorは、初めてStable Diffusionに触れてみる方におすすめです。
【API編】Stable Diffusion 3の使い方
APIでStable Diffusion 3を使えるようになったので、APIを使って実装をしていきたいと思います。コードはStability AIに掲載されているgoogle colaboratoryのコードを使っていきます。
また、使用する際にはAPIキーが必要になるので、Stability AIにログイン後にAPIキーを作成しておきましょう。リンク先に飛ぶと「Create API Key」が表示されるはずなので、そちらをクリックすればOKです。
基本的には掲載されているコードを実行していくだけでOKです。「Connect to the Stability API」で自身のAPIを入力しておくようにしましょう。
【2025年2月追記】
モデルファイルの選び方と注意点
Stable Diffusionでは、どんな画像ができるかは「モデルファイル」で決まります。モデルごとに得意なテイストや絵柄があり、どれを選ぶかで仕上がりが変わります。
モデルの形式には「.ckpt」や「.safetensors」などがあり、CivitaiやHugging Faceなどのサイトから手に入ります。商用利用できるかどうかやライセンスの条件は必ず確認しておきましょう。中には著作権に関わるモデルもあるので注意が必要です。
モデルファイルはサイズが大きいものも多く、数GBあるのが普通です。ダウンロード前にストレージの空きを確認しておきましょう。
モデルの入れ方
モデルファイルの配置手順は以下のとおりです。
- CivitaiやHugging Faceからモデルファイル(`.safetensors` または `.ckpt`)をダウンロード
- `stable-diffusion-webui/models/Stable-diffusion/` フォルダに配置
- Web UIを再起動し、画面左上のモデル選択ドロップダウンから追加したモデルを選択
追加学習「LoRA」
Stable Diffusionのデフォルトのモデルは汎用的な画像生成が得意ですが、特定のキャラクターやスタイル、オリジナルのデザインを反映させるには追加学習が必要です。追加学習を行うことで、特定のアニメキャラの再現、独自のイラストスタイルの学習、企業向けのカスタム画像生成など、より自由度の高い画像生成が可能になります。
Stable Diffusionの追加学習には他にもDreamBoothやFine-tuningがありますが、LoRAはVRAMの消費が少なく、学習時間も短いため、個人でも扱いやすい方法として広く活用されています。
LoRAの入れ方
LoRAファイルの追加手順は以下のとおりです。
- CivitaiなどからLoRAファイル(`.safetensors`)をダウンロード
- `stable-diffusion-webui/models/Lora/` フォルダに配置
- Web UIを再起動後、txt2imgの「LoRA」タブから追加したファイルを選択
- プロンプトに `<lora:ファイル名:0.8>` の形式で記述して適用(数値は適用強度で0〜1の範囲で調整)
LoRAについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Stable Diffusionはスマホでも使える!
スマホでもStable Diffusionを使えるサービスがいくつかあり、iPhoneやAndroidでも無料で画像生成が可能になっています。
以下が、初心者の方でも簡単に試せる4つのサービスです。
- Stable Diffusion Online
- DreamStudio
- Hugging Face
- Mage.space
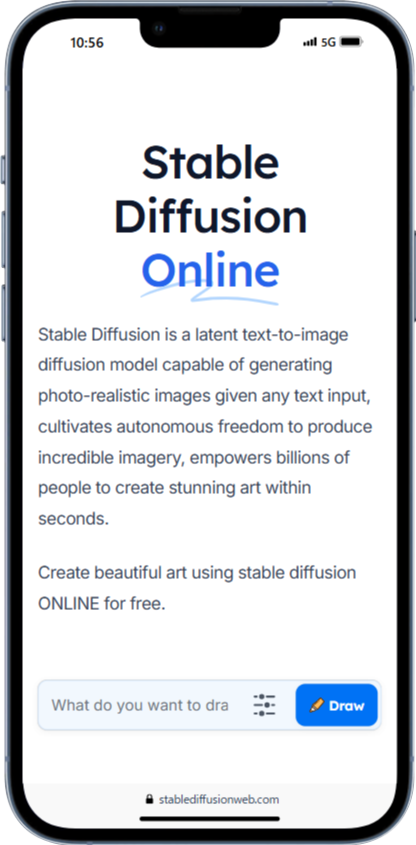
Stable Diffusion Onlineは、ブラウザ上で動作するので、スマホからもアクセスできます。画面上部の入力欄にプロンプトを入力し、「Draw」ボタンをタップするだけで画像が生成されます。無料版では画像に透かしが入るので注意が必要です。
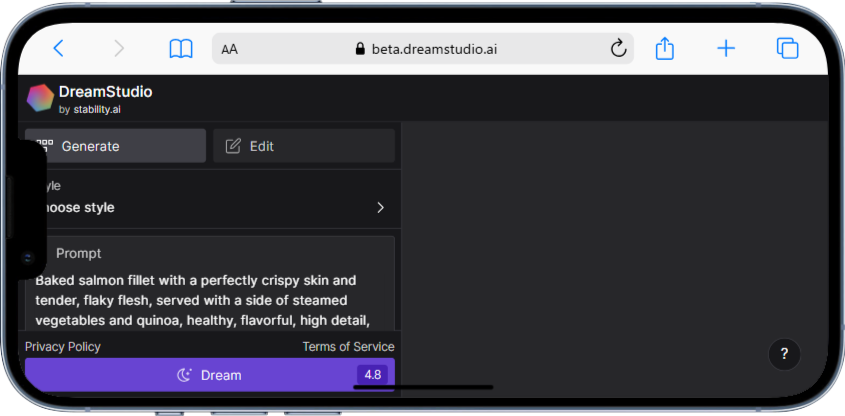
DreamStudioもスマホのブラウザから利用可能なサービスの一つで、アカウント登録後、画面中央の「Prompt」に指示を入力して画像を生成します。画面下部のスライダーで画像サイズや生成数を調整も可能です。初回は無料クレジットがもらえるので、気軽に試せるでしょう。
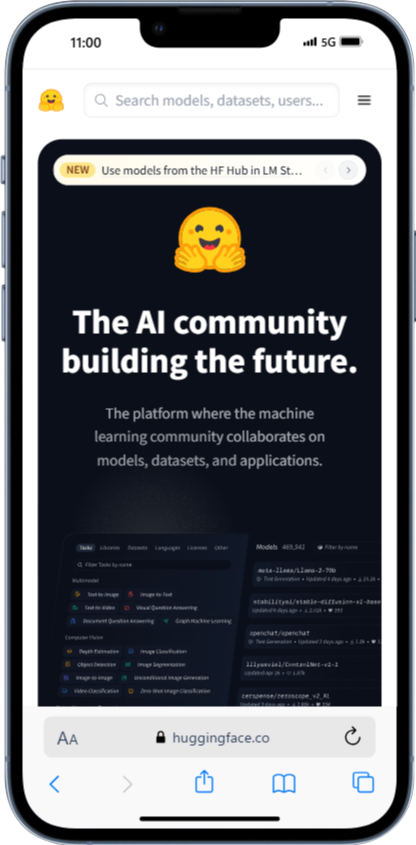
Hugging Faceは、多くのAIモデルを試せるプラットフォームです。スマホからアクセスし、「Stable Diffusion」で検索すると、さまざまなバージョンが見つかります。使いたいモデルを選び、プロンプトを入力して「Run」をタップすれば、画像が生成されます。他のサービスより少し手順は多いですが、多くのモデルを試せる点が魅力です。
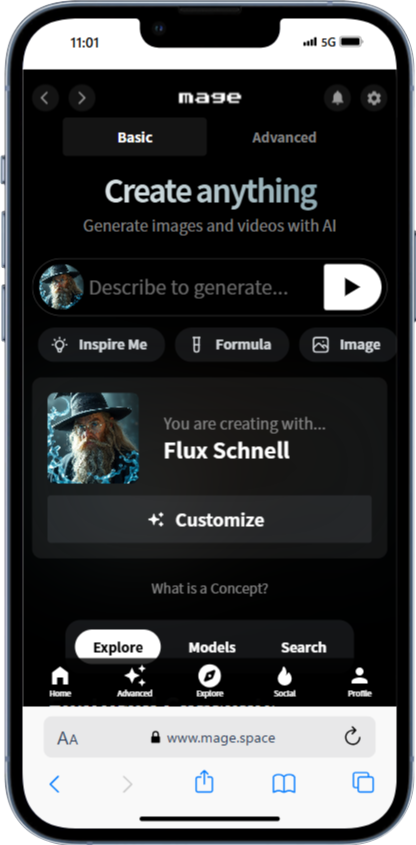
Mage.spaceは、シンプルな操作が特徴のサービスです。スマホのブラウザからアクセスして画面中央の入力欄にプロンプトを入力、右側の矢印アイコンをタップするだけで画像生成が始まります。無料版でも高品質な画像が生成できるので、初心者の方におすすめです。
Stable Diffusionを使う時のテクニック・コツ
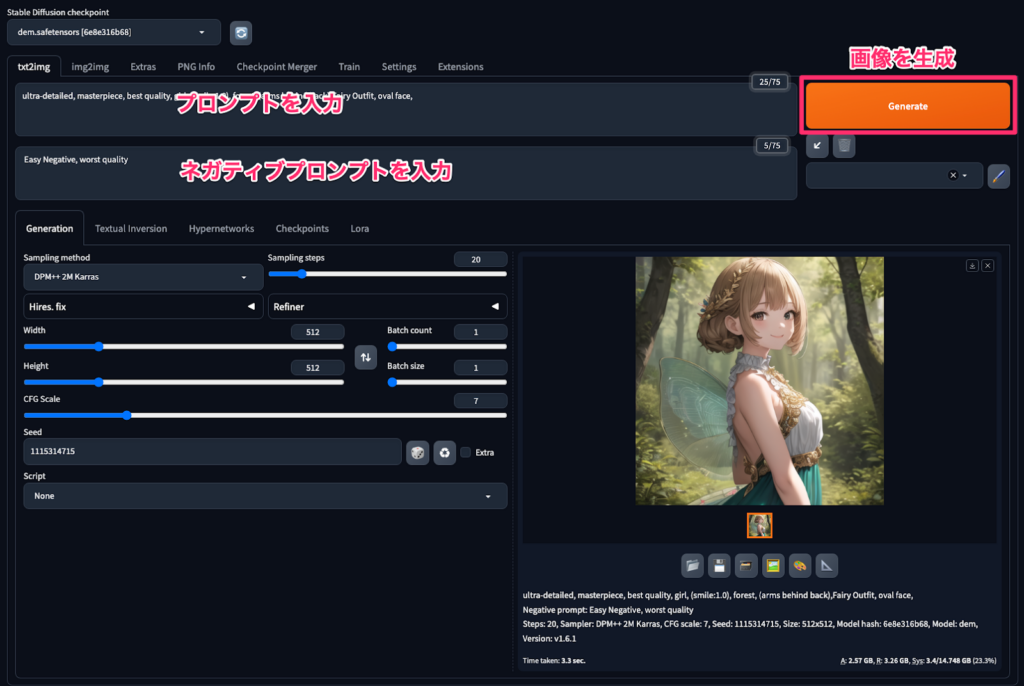
問題なくStable Diffusion web UIが起動したら下記のようになっていると思います。基本的な使い方としては、「Prompt」にプロンプトを、「Negative prompt」にネガティブプロンプトを入力します。
複数のプロンプトを入力する際はコンマで区切るのを忘れないようにしましょう。
最後に右の「Generate」ボタンをクリックして画像を生成します。
優先させたい内容から順に記入する
入力するプロンプトの順番は決まったものはありませんが、一般的には下記の順番で入力することが多いとされています。
- 画質など全体に関わる要素
- 人物に関する要素
- 髪型、服装などの外観
- 画像の構図やシーン
ただ、Stable Diffusionは入力されたプロンプトの順番に処理していきます。もし、優先度が高めの指示があれば一番最初に入力しておきましょう。
重要箇所は括弧とコロンで強調する
プロンプト内の要素を()でくくり、コロンでの後に数字を指定する事により、その要素を強調できます。
例として、smile要素の数字を変えて生成された画像を比較してみましょう。

1.0をベースに、0.5に下げたものは笑顔がなく、1.5に上げたものは笑顔が強調されていますね。
同じモデルを使用したのですが、値を変えるとキャラクターに若干の変化があるところも注意が必要です。
単語を75個以内に抑える
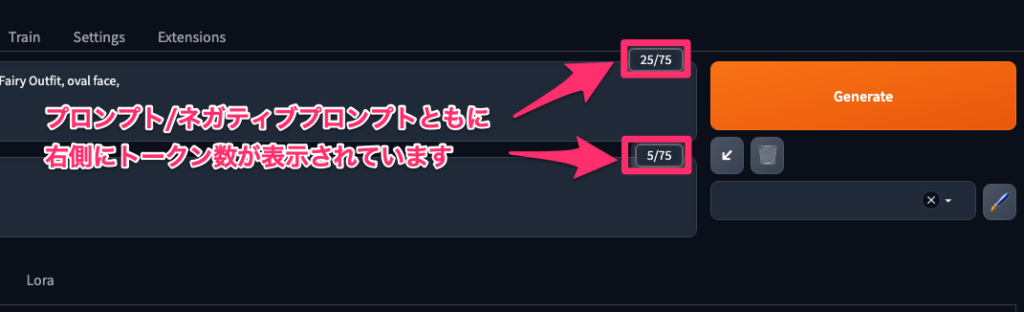
Stable Diffusionのプロンプトに入力するトークン数は75個を超えても入力できるようになっていますが、その分精度が落ちると言われていますので、75個以内に収めるようにしましょう。
入力したトークン数は入力フォームの右側に表示されているので確認しておきましょう。
ネガティブプロンプトで除きたい要素を指定する
ネガティブプロンプトとは大きく分けて「品質に関わるもの」と「生成したくないもの」の2つにわけられます。例えば、低品質を避ける「low quality」やピンボケ対策の「out of focus」などは品質に関わるものになります。
生成したくないものには指の欠損を意味する「missing fingers」や意図しない切り取りを防ぐ「cropped」などが挙げられます。プロンプトとネガティブプロンプトを組み合わせることによって、理想の画像を生成できるのでいろいろ試してみてください。
モデル&Loraは生成したい画像に合わせる
Stable Diffusionにはアニメ調のものからリアル調のものまで様々なモデルを利用できます。同じプロンプトを入力しても、モデルによって生成される画像がガラッと変わるので目的に応じたモデルを探してください。
下の画像は先程と同じプロンプトで違うモデルを選択して生成したものです。

さらに、モデルごとに推奨されるプロンプト/ネガティブプロンプトや設定が存在します。
例えば今回使用したDivineEleganceMixには下記のような記述がありました。
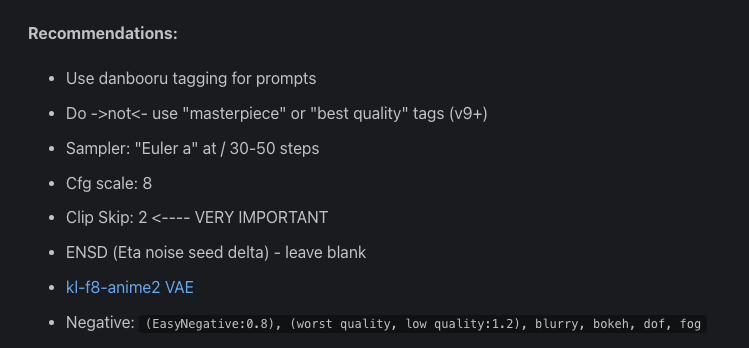
プロンプトだけでなく、おすすめのサンプラーなど、詳細に書かれていますね。利用しているモデルのサンプルのような画像を生成したい場合は推奨の設定を反映させるようにしましょう。
また、Loraという追加学習ができるパッケージを使い学習させることで、より柔軟に画像を生成できます。
Loraを利用するには、指定ディレクトリにLoraのファイルを設置したあと、web UIの「Lora」のタブをクリックします。正常にファイルが設置されていれば、表示されているLoraを選択するとプロンプトに自動で入力されるので、あとはGenerateボタンを押すだけです。
今回は8bitとkimonoというLoraを使ってみました。

8bitはドット絵みたいになる予定だったのですが、プロンプトをいじっていないので微妙にしか反映されていませんね。kimonoはキャラクターの雰囲気はそのままで少し着物っぽい感じになったかな? という仕上がりになりました。
用途にあったモデルやLoraを選択するのは大切ですが、それ以上にプロンプトや設定もしっかり勉強しないといけないようです。
なお、モデルやLoraを利用する際にはそれぞれライセンスがあるので、商用利用をしたいと考えている方は使用するモデルのライセンスを必ず確認しましょう。
特に、Loraに関しては既存のアニメっぽくするようなものもあり、Lora自体は利用フリーでも商用利用不可などが記載されている場合がありますのでご注意ください。
画像入力での生成機能「img2img」も駆使する
Stable Diffusionはテキストから画像を生成するだけでなく、画像から画像を生成できます。
画像から画像を生成・・・? 文字にするとよくわからないので実際に試してみましょう!
使い方は上部のタブより「img2img」を選択し、画像をアップロードしたあと、プロンプトを入力してGenerateするだけ。簡単ですね!
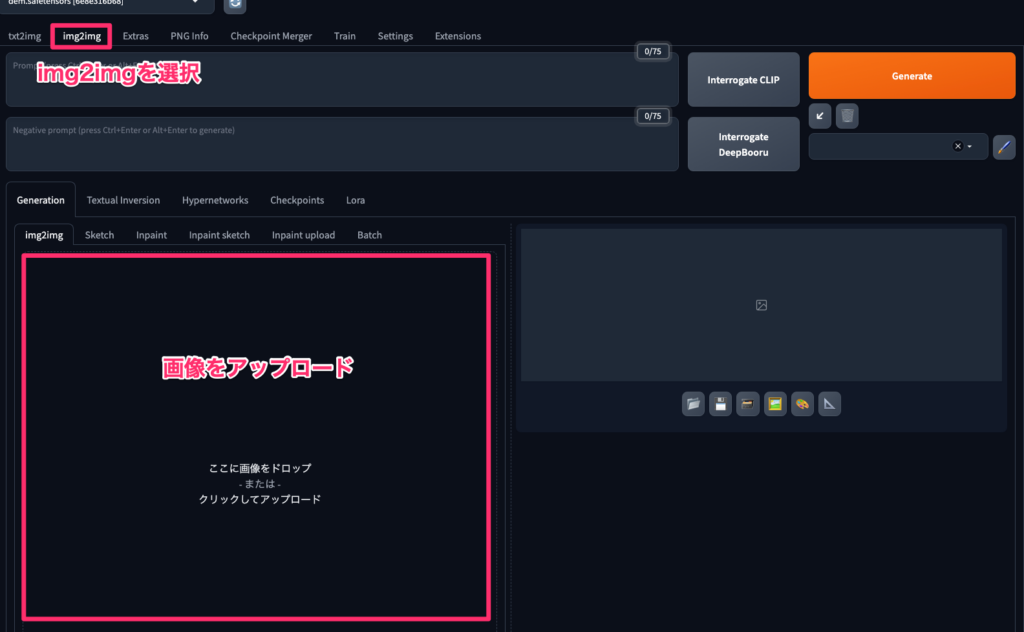
今回はリアル風の画像をアニメ風に再生成してもらいましょう!
生成結果はこちら!
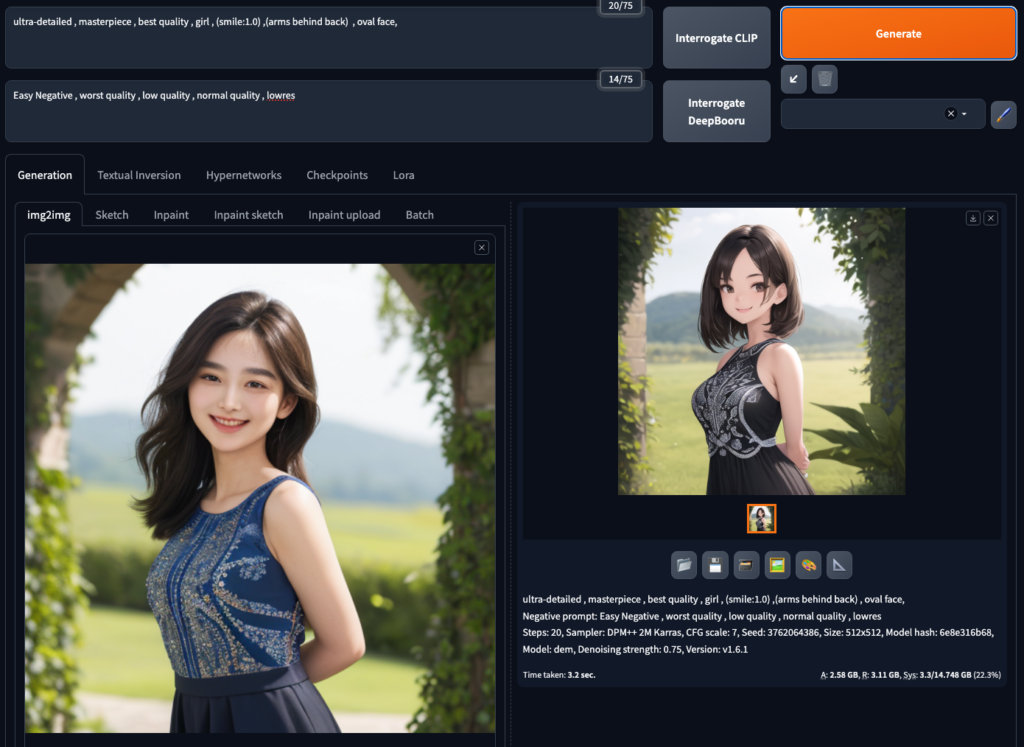
構図や服装の雰囲気まで完璧ですね!
img2imgは、「ゼロから何かを生成するより「手元にある素材を使って新たなものを創り出す」という使い方があっているようです。
【活用事例】実際に使ってみた人の声
Stable Diffusionをローカルで動かしているユーザーの声は、実際の活用イメージを深めるうえでとても参考になります。ここではX(旧Twitter)に投稿された方の事例を紹介します。目的や使い方の違いに注目すると、自分に合った導入方法が見えてくるかもしれません。
ゲーム制作に活用できる万能ツールとして使う
「ずっとやりたかった」という熱意とともに、Stable Diffusionのローカル環境を構築した方の投稿では、AI画像生成の面白さが語られていました。キャラクターの立ち絵や背景、アイテムのデザインなど、ゲーム制作に必要なアートワークが幅広く対応できるとのことです。
自分のPCで自由に画像を生成できる環境があると、構想をすぐにビジュアルにできるため、個人開発者にとっては大きな武器になります。時間や回数の制限がないというのもローカル環境の大きな利点といえるでしょう。
月額課金からの解放。クリエイターに嬉しいコスト削減効果
あるユーザーは「毎月のAI利用料、もうやめませんか?」という呼びかけとともに、ローカルAIのメリットを具体的に紹介していました。クラウド型のサービスは手軽に使える反面、毎月の利用料が積み重なってしまいます。
その点、十分な性能のPCがすでにあれば、追加の費用なしで継続的に使い続けることが可能です。新しく専用のPCを用意する場合でも、一度の初期投資で月額課金から解放されるので、長い目で見ればコストを抑えられる選択と言えるでしょう。
さらに、プライバシー保護や情報漏えいのリスクを気にせず使えるのも安心です。自宅に「自分専用のAI」を持つような感覚で、創作の幅を大きく広げていけます。
高性能GPUを活かして風景生成を楽しむ活用スタイル
別のユーザーは、自作PCに「4060Ti」という高性能なグラフィックボードを搭載し、その性能を活かしてStable Diffusionを試していました。キャラクターではなく、富士山のような自然風景を題材にした画像生成を楽しんでいる点が印象的です。イラストだけでなく、写真のようなリアルな景色も自在に作れるのがStable Diffusionの魅力。目的に応じて題材を変えながら、幅広いジャンルで表現できるのはローカル環境ならではの強みです。
料金プラン・商用利用ライセンスについて
Stable Diffusionは、基本的に自分のパソコンにインストールして使う分には無料で利用できます。趣味や個人の作品づくりに使う程度であれば、追加料金を気にせず楽しめるでしょう。
ただし、仕事やビジネスに活用する場合はライセンス規約に目を通す必要があります。標準モデルによってライセンスが異なり、Stable Diffusion 1.5などは「CreativeML OpenRAIL-M」が適用され、収益制限なく商用利用できます。
一方、SDXL・SD3・SD3.5などのモデルでは「Stability AI Community License」が適用され年間収益が100万米ドル(約1.5億円)未満であれば商用利用が可能です。それ以上の規模になるとエンタープライズ向けのライセンス契約が必要です。
\画像生成AIを商用利用する際はライセンスを確認しましょう/

他の画像生成AIとの違い
Stable Diffusionは、他の画像生成AIと比べていくつかの特徴があります。ここでは、他の画像生成AIとの違いを説明します。
| サービス名 | 費用 | 作成枚数 | 商用利用 |
|---|---|---|---|
| Stable Diffusion | 無料(PC版) | 無制限 | 可能(モデルによる制限あり) |
| Midjourney | 有料(月額約10ドルから) | 無制限(ただし有料プラン内で) | 可能 |
| Canva | 無料プランあり(有料プランあり) | 制限あり(プランによる) | 可能(素材による制限あり) |
| Adobe Firefly | Adobe Creative Cloudに含まれる | 制限あり(プランによる) | 可能 |
| DALL-E | 有料(クレジット制) | 制限あり(クレジットによる) | 可能(条件付き) |
Stable Diffusionと各種画像生成AIの比較
- 費用面での違い
- Stable Diffusionは基本的に無料で使用可能
- 多くの他のAIは有料サービスか利用回数に制限がある
- PC版なら誰でも画像生成が可能
- 作成枚数の制限
- Stable Diffusionは作成枚数に制限なし
- 他のAIサービスでは枚数制限がある
- 所有権に関する違い
- Stable Diffusionで生成した画像には基本的に権利が発生しない
- 人に悪影響を与えない内容なら自由に使用可能
- ほとんどの場合、商用利用も認められている
- 使いやすさ
- キーワード入力だけで高品質な画像生成が可能
- 絵を描くスキルがなくても作品作りできる
Stable Diffusionは無料で使えて、作品の権利も自由度が高いのが特徴ですが、注意すべき点もあります。学習モデルによってはライセンスの問題で商用利用ができないケースもあるので、事前にはライセンス条項を必ず確認しましょう。
Stable Diffusionを使うときの注意点
Stable Diffusionをローカル環境で動かす際には、事前に気をつけておきたいことがいくつかあります。
著作権や肖像権の問題、不適切な画像が生成されてしまうリスク、パソコンの性能や環境の準備、プロンプト(指示文)の書き方などです。ポイントを押さえておくと、安心してスムーズに活用できるでしょう。
著作権・肖像権について
基本的に、Stable Diffusionで作った画像は自分で自由に使えます。ただし、公式モデルや追加学習したモデルによっては利用制限がある場合も。
特に有名キャラクターやアーティストの作品をそのまま参考にしてしまうと、思わぬトラブルにつながることがあります。必ずライセンス内容を確認しておきましょう。
不適切な画像ができてしまうリスク
AIは指示次第でとてもリアルな画像を作れますが、その一方で暴力的な表現や差別的な内容、過激な描写も生成できてしまいます。もしそうした画像をうっかり公開すると、予期せぬ問題になる可能性もあります。プロンプトを入力する際は、不適切な表現が含まれていないか意識することが大切です。
パソコン環境と準備
ローカルで安定して使うには、ある程度のPC性能とストレージ、そして安定したネット環境が必要です。特にGPUとVRAMの性能は、生成速度やクオリティに大きく影響します。
モデルファイルだけで10GB以上使うこともあるので、容量にも余裕を持たせましょう。事前に準備しておくと途中で作業が止まる心配が減ります。
利用規約や有料サービスについて
ローカルで動かしていても、拡張機能や外部サービスを使う場合は有料プランが必要になることがあります。Web版のサービスを利用するときも、無料枠と有料枠の違いをよく確認して選びましょう。
特に長時間の利用や高画質の生成をしたい場合は、有料プランでないと制限に引っかかることが多いので注意してください。
Stable Diffusionの導入支援について詳しく知りたい方は、以下の記事をご覧ください。

Stable Diffusionの構築でよくある質問
Stable Diffusionをローカル環境で使い始めるときに、多くの方が気になるポイントをまとめました。初めて触れる方も、すでに導入している方もぜひ参考にしてください。
Stable Diffusionのローカルでの環境構築はメリットが多い
Stable Diffusionのローカルでの環境構築には多少の手間はかかるものの、インストール自体の手順はクリックしていくだけなので比較的容易にできます。
ローカルで環境構築するには、デメリットもありますが、無料で生成する画像の制限がないのは、非常に大きなメリットといえるでしょう。
Stable Diffusionについて詳しく知りたいという方は、ぜひこの記事を参考にして、ローカルで環境構築してみるのがおすすめです!

最後に
いかがだったでしょうか?
Stable Diffusionを業務で活用するには、ローカル環境の構築が鍵となります。貴社の用途に最適な環境設定や運用方法について、専門的な視点からサポートいたします。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、弊社紹介資料もご用意しておりますので、併せてご確認ください。


