
【Stable Diffusion WebUI Forge】省エネ・高速・高解像度の画像生成モデルを使ってみた

WEELメディア事業部LLMリサーチャーの中田です。
2月7日、Stable Diffusionの新webUI「Stable Diffusion WebUI Forge」が公開されました。このモデルを使うことで、省エネかつ高速な画像生成が可能になるんです、、、!
Stable Diffusion WebUI Forgeに関するXの投稿のいいね数は、すでに1100を超えており、国内だけでもかなり注目されていることが分かります。
この記事ではStable Diffusion WebUI Forgeの使い方や、有効性の検証まで行います。本記事を熟読することで、Stable Diffusion WebUI Forgeの凄さを実感し、今後の画像生成AIで標準使用したくなるでしょう。
ぜひ、最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
今回解説する事例において、弊社がX(旧Twitter)で発見した参考となるツイートを紹介させていただいております。取り下げなどのご連絡は、弊社公式X(旧Twitter)からご連絡ください。
Stable Diffusion WebUI Forgeの概要
Stable Diffusion WebUI Forgeは、Stable DiffusionのWebUIのForge版であり、画像生成AIの高速化と省VRAM化を実現したツールです。
本ツールは、ControlNetやFooocusを手がけられたlllyasviel氏によって作られました。元のWebUIと比較して、推論速度が約30~75%向上しているそう。
ユーザーはテキストプロンプトを入力し、必要に応じて生成パラメータ(解像度、ステップ数など)を設定するだけ。その後、指定されたプロンプトに基づいて、生成された画像が出力されます。
Forge版の最大の売りは、画像生成の高速化とVRAM使用量の削減です。これにより、より低スペックのGPUでも、高品質の画像を高速に生成できます。さらに、UNet Patcher Systemの導入により、新しい拡張機能を簡単に追加できる柔軟性も大きな特長です。
それに加えて、本家のStable Diffusion WebUIよりも、多くの機能が利用できます。例えば、ControlNetやStable Video Diffusionも、デフォルトで利用可能です。
なお、Stable Diffusionの40倍速い画像生成AIについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
→【InstaFlow】Stable Diffusionの40倍の速さで画像生成できるAIの使い方〜実践まで
Stable Diffusion WebUI Forgeのライセンス
GNU Affero General Public License v3.0 (AGPLv3)の下、誰でも無償で商用利用することが可能です。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
\画像生成AIを商用利用する際はライセンスを確認しましょう/

Stable Diffusion WebUI Forgeのインストール方法
公式のGitHubページによると、Stable Diffusion WebUI Forgeをインストールするには、以下の2通りがあるとのこと。
- GitHubリポジトリをクローンする方法
- 圧縮ファイルをダウンロードして使用する方法
また、今回はローカルで実行するので、GPUを使用できることを確認する必要があります。
GitHubリポジトリをクローンする方法
あらかじめ、Python3.10やGitをインストールしておきましょう。
次に、コマンドプロンプトで以下を実行して、公式のリポジトリをクローンしましょう。
git clone https://github.com/lllyasviel/stable-diffusion-webui-forge.git続いて、以下のコマンドを実行することで、WebUIに移動できます。
cd stable-diffusion-webui-forge
webui-user.bat
最初は時間がかかります。
ちなみに、デフォルトでは「realisticVisionV51_v51VAE.safetensors」をダウンロードする仕様になっています。そのため、好きなモデルを使いたい場合は、「stable-diffusion-webui-forge\models\Stable-diffusion」の直下に、モデルを置きましょう。
圧縮ファイルをダウンロードして使用する方法
圧縮ファイルをダウンロードして使用する方法では、まず公式のGitHubページに移動し、以下の「Click Here to Download One-Click Package」をクリックしましょう。
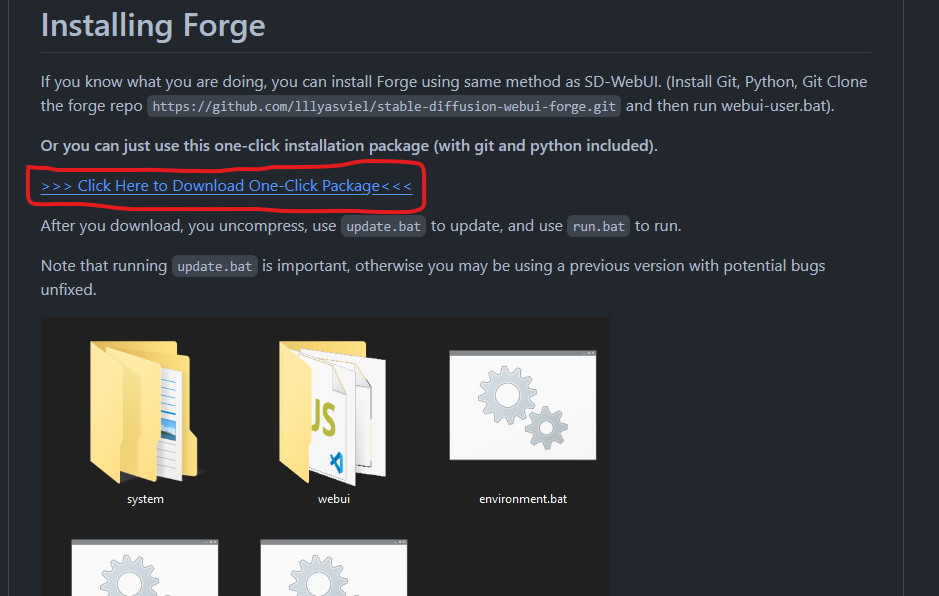
そうすることで、圧縮ファイルのダウンロードが開始します。ダウンロードが済んだら、ファイルを解凍し、「update.bat」ファイルをダブルクリックしてください。

次に、「run.bat」をダブルクリックすると、以下のようにWebUI画面に移動します。
Stable Diffusion WebUI Forgeの使い方
ここでは、Stable Diffusion WebUI Forgeの基本操作について解説します。必要なPCスペックについても紹介するので、ぜひ参考にしてみてください。
WebUIの基本的な使い方
基本的な操作は、本家のStable Diffusion WebUIと同じです。
以下の画像が参考になります。
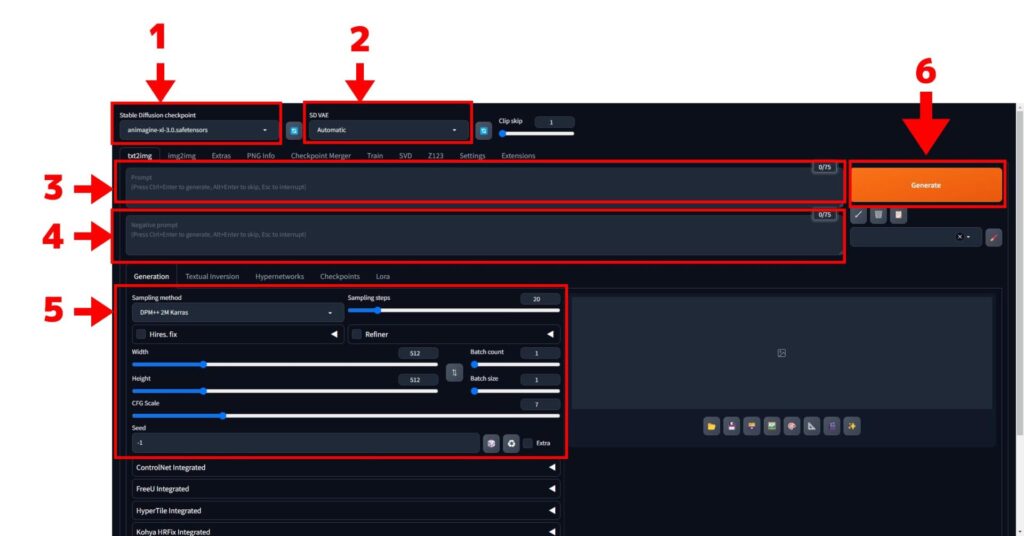
- モデル選択メニュー
- VAE選択メニュー
- プロンプト欄
- ネガティブプロンプト欄
- 各種パラメータ
- 生成ボタン
5の各種パラメータについては、以下のような項目があります。
| パラメータ | 意味 |
|---|---|
| Sampling method | サンプリング手法。手法によって生成速度や画像の品質が変わる。 |
| Sampling steps | サンプリングステップ数で、値が大きいほど画像の品質が良くなり、生成速度が落ちる。 |
| Width、Height | 画像のサイズ。 |
| Batch Size | 生成する画像枚数。 |
| Batch Count | 一度に生成する画像の何枚。 |
| CFG Scale | プロンプトの影響の強さ。 |
サンプラーに関しては、本家よりも豊富な種類が存在します。
とりあえず、シンプルなプロンプト「Beautiful girl holding a flower(花を持っている美少女)」で試してみます。
結果は以下の通りです。

100枚の画像を生成させたところ、1分ほどで生成されました。
Stable Diffusion WebUI Forgeを動かすのに必要なPCのスペック
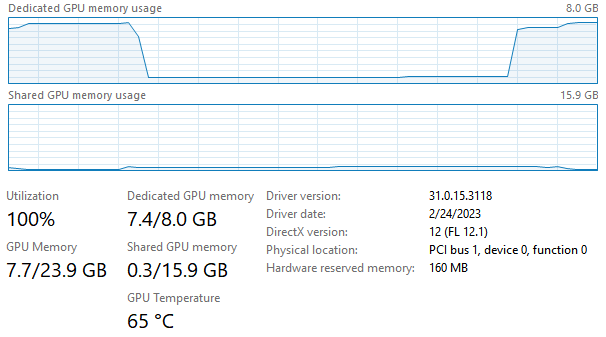
もともとのStable Diffusion WebUIにおいて、8GB VRAM (3070ti laptop)上でSDXLを動かした場合の、メモリ使用量は以下の通り。
それに対して、Stable Diffusion WebUI Forgeの場合、メモリ使用量は以下の通り。
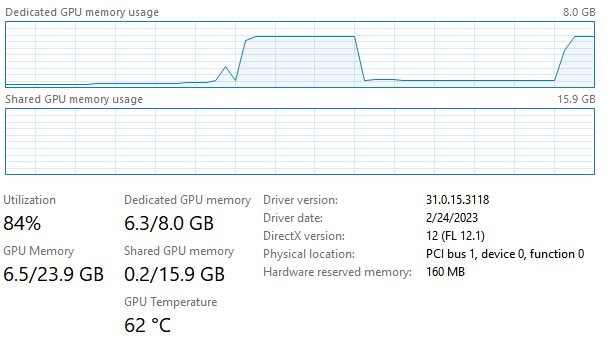
ご覧の通り、本家だと、例えば専用メモリの使用量7.4GB/8GBに対して、Forge版だと6.3GB/8GBと、1.1GBも使用量が削減されていることが分かります。
■Pythonのバージョン
Python 3.10(environment-wsl2.yamlにpython=3.10と記載あり)
■使用ディスク量
5.4GB
■RAMの使用量
6.1GB
なお、Stable Diffusion Web UIの2倍速い画像生成ツールについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
→【TensorRT】Stable Diffusion Web UIを倍速にできるNVIDIA製の神AIツール!使い方〜実践まで
Stable Diffusion WebUI Forgeで可愛い人物作ってみた
ここでは、美少女画像を生成してみます。使用したプロンプトは、以下の通りです(ChatGPTで生成)。
Imagine a serene and picturesque scene where a beautiful young girl stands in a lush, vibrant garden full of blooming flowers of various colors. The girl, with long, flowing hair that gently sways in the soft breeze, is dressed in a delicate, flowing dress that mirrors the colors of the garden around her. Her expression is one of tranquility and contentment, as she gazes into the distance, lost in thought. The sun is setting, casting a warm, golden light over the scene, enhancing the natural beauty of the garden and giving the girl an almost ethereal glow. This image captures a moment of perfect harmony between human and nature, embodying a sense of peace and timeless beauty.さまざまな色の花が咲き乱れる青々とした鮮やかな庭に、美しい少女が佇んでいる静謐で絵のような光景を想像してほしい。流れるような長い髪をそよ風になびかせ、繊細で流れるようなドレスを着ている。彼女の表情は、物思いにふけりながら遠くを見つめているような静けさと満足感に満ちている。太陽が沈み、暖かな金色の光がこの光景を照らし、庭園の自然の美しさを引き立て、少女に幽玄な輝きを与えている。この写真は、人間と自然が完璧に調和した瞬間をとらえ、平和と永遠の美しさを体現している。
試しに、サンプリングステップを、最大の150stepにして、4枚の画像を生成させてみました。

どれもプロンプト通りですが、左上の画像に関しては顔がつぶれてしまっています。
次は、「Stable Diffusionでリアル・実写系の生成に使える呪文(プロンプト)を紹介」のプロンプトテクニックにならって、以下のプロンプトで生成してみます。ちなみに、ネガティブプロンプトも追加しました。
8k, RAW photo, best quality, masterpiece, realistic, photo-realistic, clear, professional lighting, beautiful face, best quality, ultra high res<br>BREAK<br>(full body 1.5),<br>BREAK<br>realistic Japanese cute, girl,18 years old,<br>long hair, smile,<br>BREAK<br>school uniform,<br>BREAK<br>standing<br>BREAK<br>class room<br><br>和訳:<br>8k, RAWフォト, 最高画質, 傑作, リアル, 写実的, クリア, プロの照明, 美しい顔, 最高品質, 超高解像度<br>ブレイク<br>(全身1.5)、<br>ブレイク<br>リアルな日本人、かわいい、女の子、18歳、<br>ロングヘア、笑顔、<br>ブレイク<br>制服<br>ブレイク<br>スタンディング<br>ブレイク<br>教室ネガティブプロンプト:
<br>EasyNegative, deformed mutated disfigured, missing arms, 4 fingers, 6 fingers,<br>extra_arms , mutated hands, bad anatomy, disconnected limbs, low quality, worst quality, out of focus, ugly,<br>error, blurry, bokeh, Shoulder bag, bag, multiple arms, nsfw.<br>EasyNegative, 変形した突然変異の醜い, 腕がない, 4本の指, 6本の指、
extra_arms , 変異した手, 悪い解剖学, 切断された手足, 低品質, 最悪品質, ピンボケ, 醜い、
エラー, ボケ, ショルダーバッグ, バッグ, 複数の腕, nsfw.
すると、結果は以下の通りです。

このように、デフォルトのモデル、設定値でも、ある程度高い品質の画像を生成できます。
ちなみに、この時のメモリの使用量は、以下の通りです。
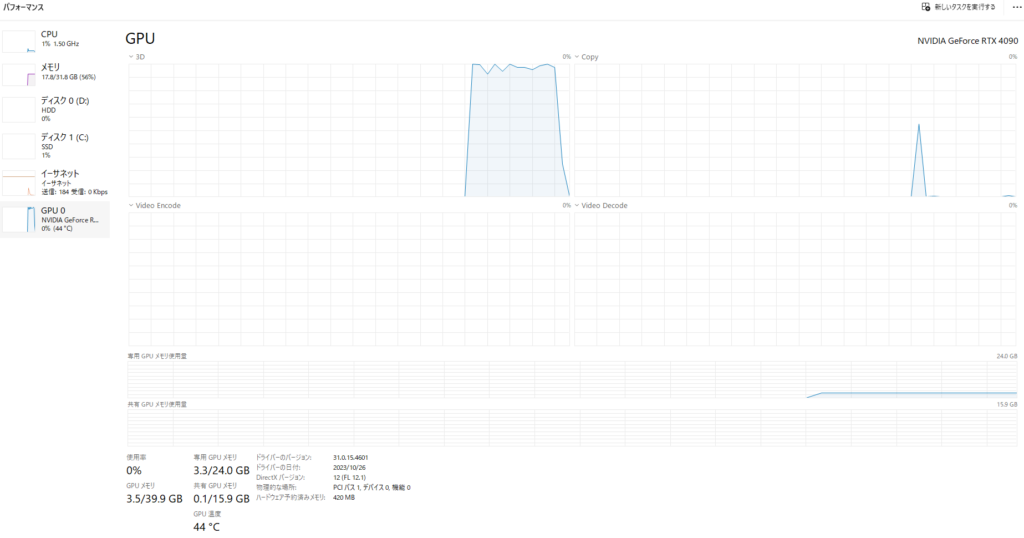
なお、今回はグラフィックボードに「RTX4090」を利用しています。
ControlNetも最初から導入されている
Stable Diffusion WebUI Forgeでは、デフォルトでControlNetが利用できます。
そこで、先ほど生成した以下の画像をもとに、ControlNetで編集してみましょう。

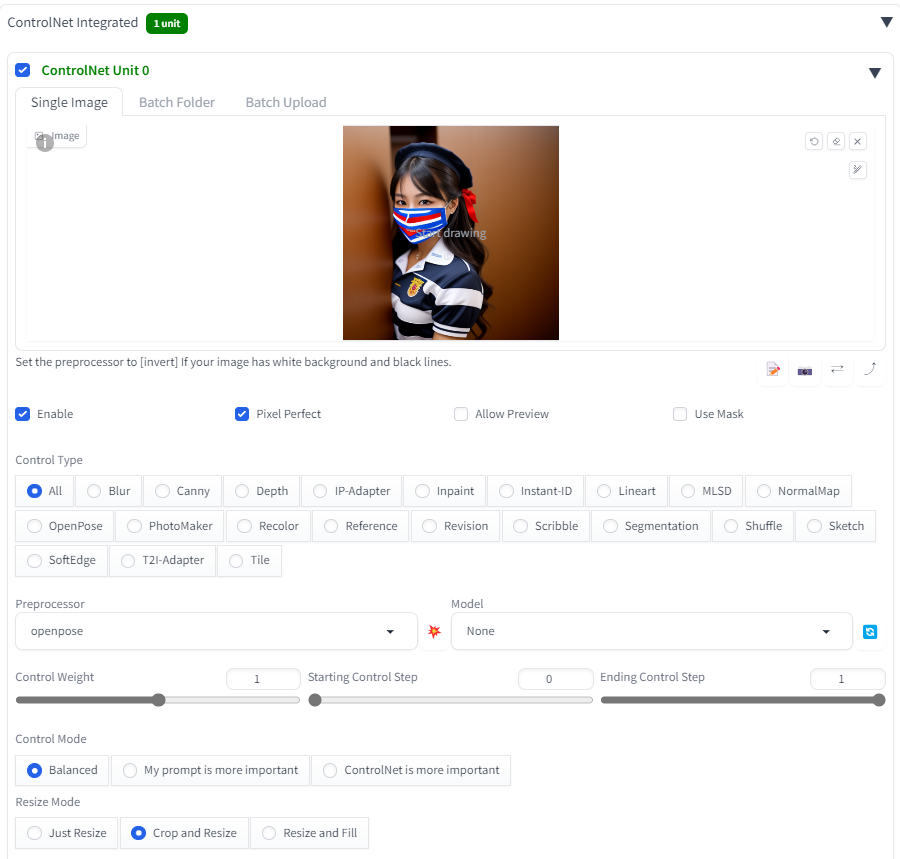
画像を挿入し「Enable」にチェックを入れたうえで、Preprocessor、Modelの2つを選択してください。ここでは、Preprocessorに「openpose」を使います。openposeは、画像から人体などのキーポイント(棒人間)を検出し、それをもとに画像を生成する機能です。
結果は以下の通りです。

SVD(Stable VideoDiffusion)で動画生成をしてみた
最後に、Stable Diffusion WebUI ForgeのSVD(Stable VideoDiffusion)を使ってみましょう。SVDもデフォルトで利用できます。

先ほど用いた以下の画像に対して、動きを付けてみます。

まずは、以下のURLから、SVDモデルをダウンロードしてください。
stabilityai/stable-video-diffusion-img2vid-xt
次に、「stable-diffusion-webui-forge\models\svd」の中に、ダウンロードしたモデルを置いてください。そして、update.batを実行し、run.batで再起動しましょう。
すると、SVDモデルをStable Diffusion WebUI Forge内で利用できるようになっているはずです。そして、以下の画像の赤枠の部分で、モデルを選択しましょう。
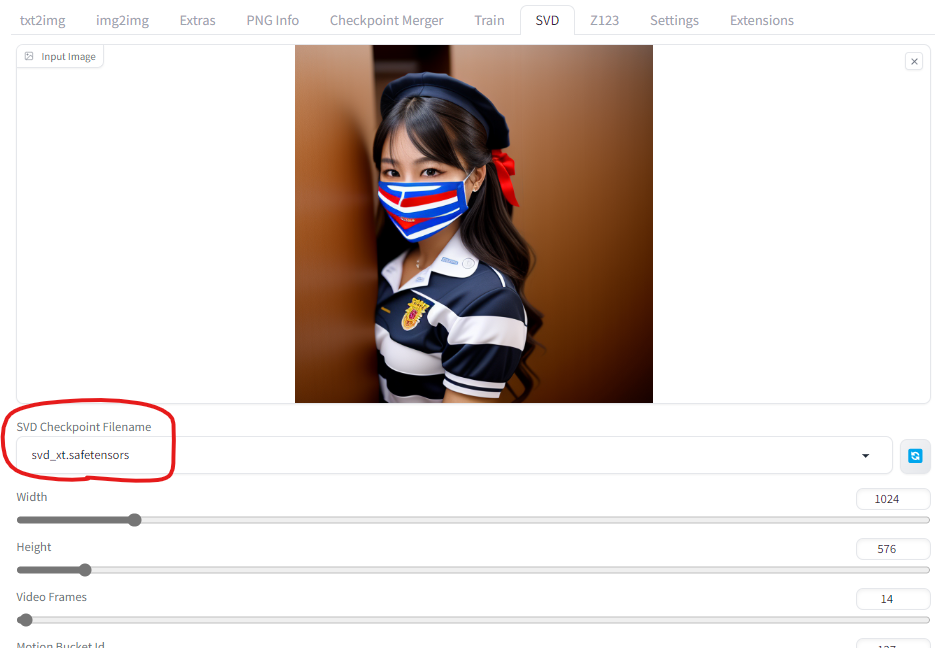
デフォルトで実行したところ、以下のような動画が生成されました。
なお、今回使った動画生成AIのSVDについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
→【Stable Video Diffusion】ローカルでの使い方や料金体系、商用利用について解説
Stable Diffusion WebUI ForgeにLoRAを導入する方法
LoRAとは、Stable Diffusionの追加学習が行えるモデルのことです。導入することで特定のジャンルや画風に特化した画像を生成できるようになるので、画像生成の幅が広がります。
そんなLoRAをStable Diffusion WebUI Forgeに導入する際は、以下の手順に沿って行います。
- CivitaiかHugging FaceでLoRAをダウンロードする
- ダウンロードしたLoRAをファイルの正しい場所に格納する
- Stable Diffusion WebUI Forgeで使用するLoRAを選択する
まずは、CivitaiかHugging FaceでLoRAをダウンロードする必要があります。
ダウンロードするLoRAを決めたら、右側のダウンロードアイコンをクリックしましょう。
次に、「stable-diffusion-webui」→「models」→「LoRA」の順にファイルを開き、ここにダウンロードしたLoRAを格納します。
あとはStable Diffusion WebUI Forgeで使用するLoRAを選択すれば、学習内容が生成画像に反映されるようになります。
なお、LoRAについて詳しく知りたい方は、以下の記事を参考にしてみてください。
→【LoRA】画像生成がさらに進化!イラストや写真表現の可能性を広げるAI学習モデルを徹底解説
Stable Diffusion WebUI Forgeでおすすめの拡張機能
デフォルトでも利便性の高いStable Diffusion WebUI Forgeですが、拡張機能を導入すれば、さらに操作性が向上します。
そこで、Stable Diffusion WebUI Forgeでおすすめの拡張機能を以下にまとめました。
- FreeU Integrated
- ADetailer
- Config-Presets
以下でそれぞれみていきましょう。
FreeU Integrated
FreeUは、B1・B2・S1・S2の4つのパラメーターを使用して、画質を手軽に調整できる拡張機能です。「有効化」にチェックを入れたあと、各パラメータをいじれば生成画像に反映されます。
パラメーターは0.01単位で細かく設定できるのが特徴。ベストなパラメーターはプロンプトによって異なるので、色々試しながらベストなパラーメーターを探してみてください。
ADetailer
ADetailerは、顔のパーツ・表情・手など、人物やキャラクターの細部を修正できる拡張機能です。
すでに生成済みの人物やキャラに軽微な修正を加えられるので、生成画像を崩さずに修正できます。
通常、プロンプトを丸ごと変えると生成される人物やキャラクターも変わってしまうため、これを防ぎたいときに便利です。
Config-Presets
Config-Presetsは、Stable Diffusion WebUI Forgeで設定するパラメーターの数値を随時保存できる拡張機能です。
ControlNetやFreeUの数値設定を保存しておけるので、1度高品質な画像をつくれた際に保存すると、以降も安定して高品質な画像を生成できるようになります。
毎回メモしておくのも大変なので、各種パラメーターを細かくいじって画像を生成している方は、ぜひ導入を検討してみてください。
なお、Stable Diffusionで使える画像生成のプロンプトについて知りたい方は、以下の記事が参考になります。
→Stable Diffusionで使える画像生成の呪文一覧!おすすめプロンプトと活用事例を紹介
Stable Diffusion WebUI Forgeを使って高速な画像生成を実現しよう
Stable Diffusion WebUI Forgeは、元のWebUIより推論速度を30~75%改善し、VRAM使用量を削減した画像生成AIの高速化ツールです。
ユーザーはテキストプロンプトと生成パラメータを設定するだけで、高品質な画像を一瞬で得られます。特に低スペックのGPUでも効率的に動作し、UNet Patcher Systemにより新機能の追加も容易です。実際に100枚の画像を、約1分で生成できました。
なお、Stable Diffusion WebUI Forgeは、GNU Affero General Public License v3.0 (AGPLv3)の下、誰でも無償で商用利用することが可能です。
インストールする際は、以下2つの方法があります。
- GitHubリポジトリをクローンする方法
- 圧縮ファイルをダウンロードして使用する方法
Stable Diffusion WebUI Forgeの基本操作は本家のStable Diffusion WebUIと同じです。
LoRAを導入する際は、以下の手順を参考にしてください。
- CivitaiかHugging FaceでLoRAをダウンロードする
- ダウンロードしたLoRAをファイルの正しい場所に格納する
- Stable Diffusion WebUI Forgeで使用するLoRAを選択する
また、Stable Diffusion WebUI Forgeは拡張機能を使うことで、さらに生成画像の精度や操作性が向上します。
- FreeU Integrated
- ADetailer
- Config-Presets
拡張機能で迷ったら、上記の3つを試してみましょう。
本記事を参考に、Stable Diffusion WebUI Forgeを使って、高速画像生成を体験してみてください。

最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

