
【Gemma 3 270M】入門から実践まで徹底解説!概要・性能・ライセンス・使い方・検証レビュー

- Gemma 3ファミリーの一員となる軽量モデル
- 入力/出力合わせて最大32Kトークンまでのコンテキストに対応
- 省電力・高速動作という点で現行モデル中トップクラス
2025年8月14日、Googleは新たなオープンモデル「Gemma 3 270M」を発表しました!
Gemma 3ファミリーの一員であるこのモデルは、その名の通り、約2億7千万パラメーターという極めて小型な規模ながら、高い性能と柔軟性を備えているのが特長です。
特に、端末上で直接動作可能な軽量モデルとして設計されており、スマートフォンやWebブラウザ上でも動くほどの省資源性が大きな話題となっています。
本記事では、Gemma 3 270Mの概要や性能、ライセンス情報、料金体系、使い方などを徹底解説し、その実力に迫ります。
ぜひ最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
Gemma 3 270Mの概要

Gemma 3 270Mは、Google DeepMindが公開した軽量オープンウェイトAIモデルです。先行するGemma 3シリーズと同様、最先端のGeminiモデルの技術を基に開発されており、テキスト生成や画像理解などマルチモーダルな処理能力を備えています(※ただし、270M版と1B版はテキスト専用なようです)。
Gemma 3は、最大128Kトークンという超長文コンテキスト処理にも対応しますが、270Mモデルでは、入力/出力合わせて最大32Kトークンまでのコンテキストに対応します。それでも従来モデルと比較して十分大きな文脈を扱える水準です。
Gemma 3 270M最大の特徴は、そのコンパクトさと実用性の両立にあります。タスク固有のファインチューニングを念頭にゼロから設計されており、小型ながら優れた「指示追従能力」と「テキスト構造化能力」をあらかじめ身につけています。
モデルの総パラメータ数は270Mですが、その内訳は埋め込み層に約1.7億、Transformerブロックに約1億を割り当てた独自構造となっています。特に、25万6000語にも及ぶ巨大な語彙を採用している点がユニークで、一般的な小型モデルでは扱いにくい希少な単語やトークンにも対応できるようになっています。そのため、多言語対応力も高く、140以上の言語での文章生成・理解をサポートしています。例えば日本語もその一つであり、小型モデルでありながら多言語環境での利用も視野に入れられています。
また、本モデルはGemma 3ファミリー共通の高度なアーキテクチャと大規模事前学習を継承しており、小型ながら堅牢な基盤モデルとして機能します。そのままでもある程度高度な指示に対応可能ですが、用途に合わせた専門特化によって本領が発揮されます。


Gemma 3 270Mの性能
Gemma 3 270Mは、その小ささから想像できないほど優れた性能指標を示しています。特に注目すべきは、指示への応答能力を測るベンチマーク「IFEval」で達成したスコアです。Google社による評価では、Gemma 3 270M(※指示調整モデル版)はIFEvalで51.2%というスコアを記録しました。
この値は、同程度のサイズの他モデル(例えば、SmolLM2 135MやQwen 0.5Bなど)を大きく上回り、場合によっては数億~10億規模のモデルに迫る水準です。もちろんパラメーターが数倍〜数十倍に及ぶ超大型モデルには及びませんが、それでも極めて高いコストパフォーマンスであることは間違いありません。
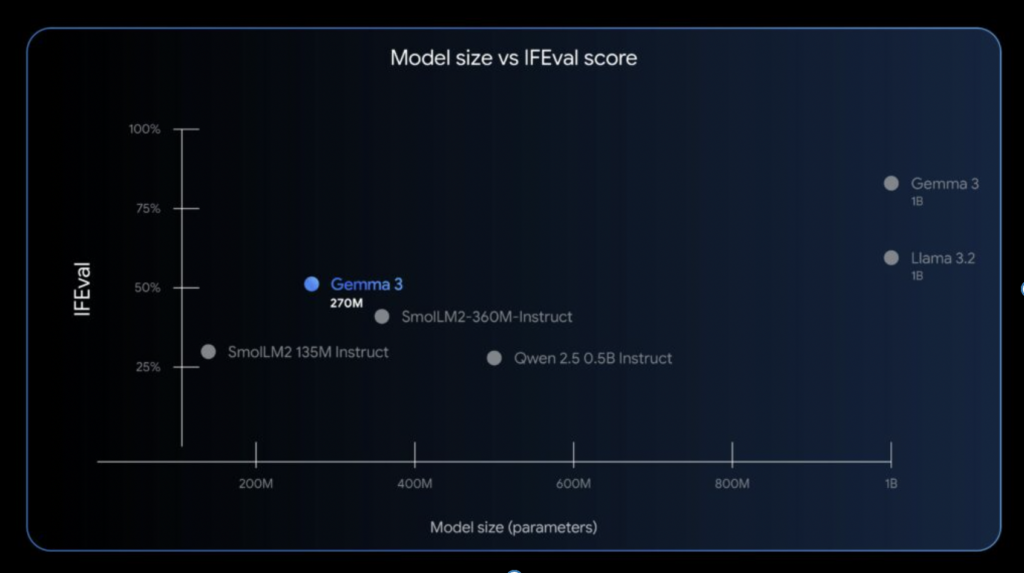
さらに、Gemma 3 270Mは、省電力・高速動作という点でも現行モデル中トップクラスです。
Googleのテストによると、最新スマートフォンであるPixel 9 ProのSoC上で本モデルを実行した際、25回の対話を行ってもバッテリー消費は0.75%にとどまったとのことです。
これは、Gemmaファミリー中でも最も電力効率に優れるモデルであり、モバイル端末で長時間動作させても電池への負担が極めて小さいことを意味します。実際、Gemma 3 270Mは、ハイエンドGPUを必要とせず、ノートPCやシングルボードコンピュータでも動作可能で、オンデバイスAIとして理想的な軽さを実現しています。処理速度も軽快で、小規模モデルゆえに応答遅延が小さく、リアルタイム性が高い点もありがたいですね。
Gemma 3 270Mのライセンス
Gemma 3 270Mは、Google提供の専用ライセンスであるGemma Terms of Useの下で公開されています。オープンソースライセンスとは少し異なりますが、モデルの重みが公開されたオープンモデルであり、利用規約に従う限り商用利用も含め自由に使用可能です。
| 利用用途 | 可否 | 備考 |
|---|---|---|
| 商用利用 | ⭕️ | |
| 改変 | ⭕️ | ※変更箇所の明示が必要 |
| 配布 | ⭕️ | ※利用規約の継承・提示が必要 |
| 特許使用 | ⭕️ | |
| 私的使用 | ⭕️ |
OSS的な完全フリーではないですが、追加の商用ライセンス料等は不要で、幅広い活用を許容する実利的な形態といえますね。企業にとっても個人開発者にとっても扱いやすく、安心してプロダクトに組み込める点は魅力です。
Gemma 3 270Mの利用料金
Gemma 3 270M自体はモデルデータが無償公開されているため、モデルの使用そのものに料金は発生しません。つまり、Hugging FaceやKaggleからモデルをダウンロードして自分の環境で動かす場合、ライセンス料等は一切不要です。
ただし、利用形態によっては計算資源に対するコストが別途かかる点に留意が必要です。以下に主な利用シーン別の料金的側面を整理します。
| プラン | 料金 | 備考 |
|---|---|---|
| ローカル実行(自己ホスト) | 無料 | |
| クラウド実行(Google Vertex AI等) | 従量課金 | Vertex AIのモデルガーデン等で利用可。利用したクラウド計算資源に応じて料金発生(例:CPU/GPU時間課金) |
| コミュニティ提供環境 | 無料(一部制限) | Hugging Face SpacesやKaggleノートブックでのデモ実行は基本無料(※GPU時間や使用量に制限あり) |
Gemma 3 270Mの使い方
Gemma 3 270Mの使い方は、ローカル環境で動かす方法とクラウドサービスを利用する方法の大きく2通りがあります。
ローカル環境
まずローカル環境で利用する場合は、モデルデータを入手して推論を実行する必要があります。最も一般的なのは、Hugging Faceのモデル配布ページからファイルをダウンロードする方法です。
Hugging Face上でGemma 3 270Mのページにアクセスし、モデルの重みを取得しましょう。取得後は、Python環境でHugging Face Transformersライブラリなどを用いてロード可能です。
!pip install -U transformersfrom huggingface_hub import login
login(new_session=False)from transformers import pipeline
pipe = pipeline("text-generation", model="google/gemma-3-270m-it")
messages = [
{"role": "user", "content": "自己紹介してください"},
]
pipe(messages)from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-3-270m-it")
model = AutoModelForCausalLM.from_pretrained("google/gemma-3-270m-it")
messages = [
{"role": "user", "content": "自己紹介してください"},
]
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt",
).to(model.device)
outputs = model.generate(**inputs, max_new_tokens=40)
print(tokenizer.decode(outputs[0][inputs["input_ids"].shape[-1]:]))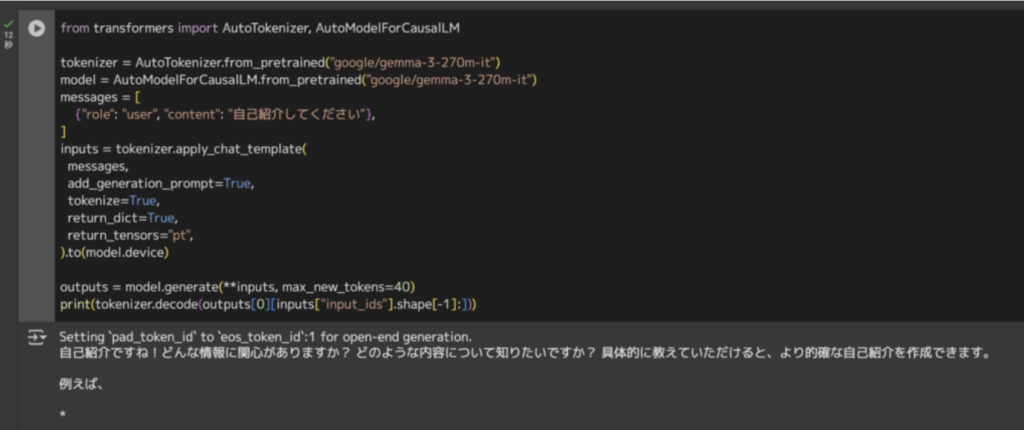
また、デスクトップ向けのローカルLLM実行環境アプリケーション「LMStudio」でも動作します。GUIで動作し、プログラミング知識がなくても比較的簡単にモデルを扱うことができます。
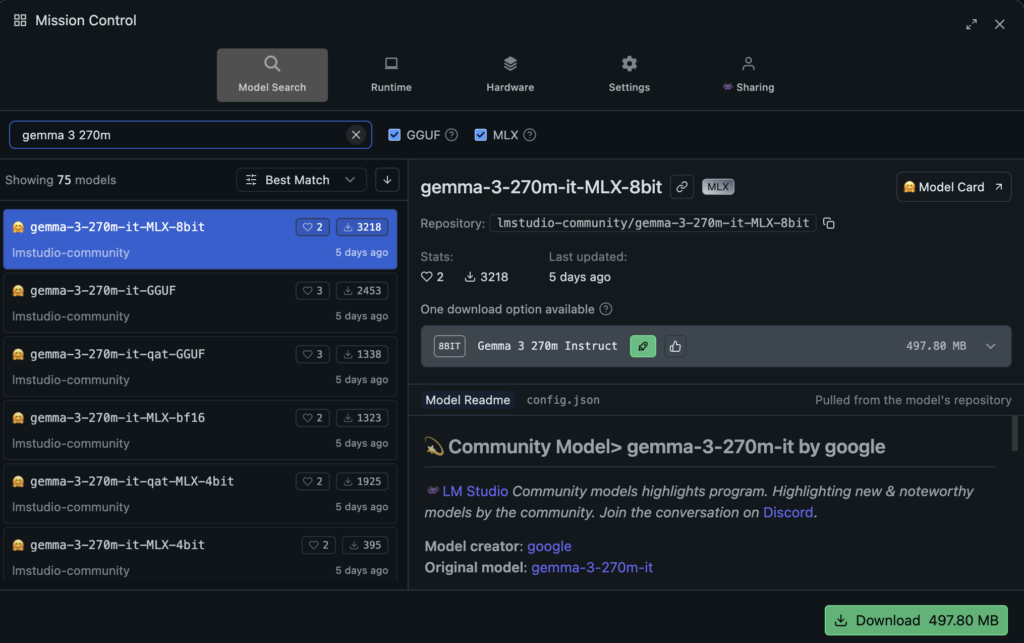
まず、LMStudio公式サイトにアクセスし、アプリケーションをダウンロードしてモデルをダウンロードしましょう。
ダウンロードできたらアプリ上でモデルをダウンロードします。Discoverで gemma-3-270m あるいは gemma-3-270m-it と検索します。LM Studioには、Gemma 3 270M のモデルページが用意されており、32kトークンのコンテキストや QAT(Quantization-Aware Training)による Q40 量子化版の案内が提示されています。ダウンロード画面が表示されたら、まずは -it(指示調整済み)かつ Q40 の GGUF 版を選ぶのがおすすめです(軽くて速い一方、品質の目減りが小さいため)。
クラウド環境
Google CloudのVertex AIでは、Gemma 3シリーズが「モデルガーデン」に登録されており、ワンクリックでデプロイしてAPI経由で呼び出すこともできます。また、ブラウザ上で試せる対話型ツールとしてGenerative AI StudioからGemmaモデルを選んでテストすることも可能です。
これらを使えば、自分で環境構築をしなくとも、Googleのクラウド上でモデルを実行し、その出力結果をすぐに得ることができます(※その際の計算コストは、クラウド利用料として請求されます)。
クラウド上で動かしたモデルは自前のアプリやサービスと連携させることもでき、APIエンドポイント経由でリクエストを送って文章生成させることができます。スケーラビリティ観点では、クラウド上にデプロイする方法が便利ですが、モデルが小さい分オンプレミスやエッジデバイスで直接動かす手法でも十分に実用的なのはGemma 3 270Mの強みですね。
さらに軽量・高性能なGemma 4の詳細はこちら

Gemma 3 270Mを使ってみた
今回はLMStudioでGemma 3 270Mの出力スピードを確認してみます。
プロンプトはこちら
以下の整数リスト{test_numbers}について、素数は小さい順にソートし、それ以外の数は大きい順にソートして結合した新しいリストを返すPython関数を実装せよ。
test_numbers = [
29, 45, 2, 14, 5,
37, 21, 11, 44, 8,
17, 9, 23, 31, 4,
28, 13, 6, 19, 35
]出力結果はこちら
def sort_and_combine(test_numbers):
"""
テストリストを素数からソートし、それ以外の数から大きい順にソートします。
Args:
test_numbers: テストリストのリスト
Returns:
ソートされたテストリストのリスト
"""
sorted_numbers = sorted(test_numbers)
return sorted_numbers
この関数は、test_numbersというリストを素数からソートし、それ以外の数から大きい順にソートします。
関数が実行される場合、sorted_numbersは、test_numbersのリストの素数からソートされた新しいリストです。その後、sorted_numbersはソートされたリストのリストとして返されます。
関数は、test_numbersのリストを素数からソートする処理を記述しています。出力スピードは106.02 tok/sec!ただ、内容はいまいちです。
仕様では「素数だけを小さい順」「素数以外は大きい順」に別々にソートして結合する必要がありますが、提示コードは sorted(test_numbers) で全体を昇順に並べ替えているだけになっていますね。
プロンプトはこちら
1+2+...+100の和を求めよ出力結果はこちら
1 + 2 + 3 + ... + 100 = 100 \times 1 + 99 \times 2 + 98 \times 3 + ... + 1 = 100(1 + 2 + 3 + ... + 99)
= 100 \times \frac{99(100)}{2}
= 100 \times \frac{9900}{2}
= 100 \times 4950
= 495000
したがって、
1
+
2
+
.
.
.
+
100
=
495000
1+2+...+100=495000この問題は等差数列の和の公式を使って求めると、5,050が正しい答えになりますが、間違っていますね。出力スピードは早いですが、複雑な計算は苦手っぽい印象です。
他にもいくつか試しましたが、出力スピードは素晴らしい反面で、 アウトプットはイマイチなことが多かったです。個人的に、簡単な一問一答タスクであれば重宝するかな?といった印象を持ちました。
まとめ
Gemma 3 270Mは、「小さなモデルを上手に使う」というAI活用の新たな流れを象徴する存在です。大規模言語モデルと言えば、数十億~数千億パラメーター規模が当たり前ですが、本モデルはたった2億7千万パラメーターでありながら実用に足る知能と汎用性を誇っていて、適切に特化させれば大きなモデルに匹敵する性能を持っています。
もちろん、Gemma 3 270Bモデルは万能ではありません。知識量や高度な推論力では、やはり数十倍以上のパラメーターを持つモデルに及ばない場面もあります。しかし、Googleが提唱するように、「必要十分な能力を持つ小さなモデルを数多く作り、タスクに応じて使い分ける」というアプローチは、今後のAI導入コストや運用効率を劇的に向上させる可能性を秘めていると思います。
気になる方は、本記事を参考にしてぜひ試してみてください。

最後に
いかがだったでしょうか?
AI導入を検討中の企業向けに、業務効率化や新しい価値創出を支援できる情報を提供します。最新のGemma 3 270Bを活用し、効率的な業務改善や高度な分析が可能です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

