
【Devstral 2 / Devstral Small 2】最強クラスのオープンコードモデルをVibe CLIでレビュー
- コーディングタスクに特化した新世代の大規模言語モデル「Devstral 2」ファミリー
- パラメータ数1,230億のフラッグシップモデル「Devstral 2」と、パラメータ数240億の軽量版「Devstral Small 2」の2種類が含まれる
- SWE-Benchにおいて、Devstral 2は、72.2%という高い正解率を記録し、DeepSeek V3.2と同等性能
2025年12月10日、フランスのAIスタートアップであるMistral AIが、コーディングタスクに特化した新世代の大規模言語モデル「Devstral 2」ファミリーを公開しました!
このファミリーには、パラメータ数1,230億のフラッグシップモデル「Devstral 2」と、パラメータ数240億の軽量版「Devstral Small 2」の2種類が含まれています。
また、同時に、開発者がターミナル上でこれらのモデルを直接活用できるコマンドラインAIアシスタント「Mistral Vibe CLI」もリリースされました。
Mistral AIは本リリースによって、AnthropicやOpenAIなどの大手企業がリードするコード生成AI分野にオープンソースで挑戦し、性能面だけでなく、開発者エクスペリエンスでも競争力のあるソリューションを提供することを目指しているそうです。
本記事では、このDevstral 2およびDevstral Small 2について、概要や性能評価、ライセンス、使い方まで徹底解説します。
ぜひ最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
Devstral 2とDevstral Small 2の概要
Devstral 2ファミリーは、ソフトウェア開発支援に特化して設計された大規模言語モデルのシリーズです。
最大の特徴は、長大な256Kトークンのコンテキストウィンドウを備えている点で、これによって、巨大なコードベースや複数ファイルにまたがる情報を一度に読み込み・理解することが可能です。
Devstralモデルは、エージェンティックなコード生成AIと位置付けられており、単なるコード補完に留まらず、プロジェクト全体を把握して自律的に問題を解決するよう設計されています。
バグ修正やレガシーコードのモダナイゼーションといった課題に対して、エンジニアが行うような高度な推論と一貫性のある対応を再現することができます。
また、同時リリースされたMistral Vibe CLIという専用ツールによって、われわれ開発者は、手元のターミナルやIDEから直接これらのモデルにアクセスして、対話的にコーディングタスクを進めることが可能になりました。


Devstral 2とDevstral Small 2の違い
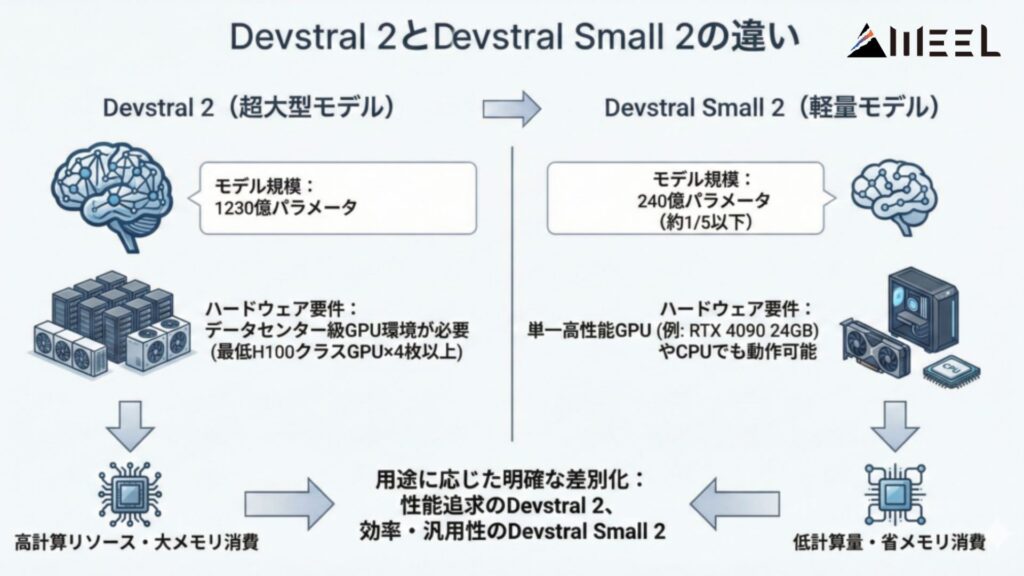
Devstral 2とDevstral Small 2は、用途に応じて明確に差別化されています。
まず、モデル規模ですが、前者は1230億パラメータの超大型モデルであるのに対し、後者は240億パラメータと約1/5以下のサイズに抑えられた軽量モデルです。
この違いによって、必要とされるハードウェア要件も大きく異なってきます。
Devstral 2は、最低でもH100クラスのGPUを4枚要するほど計算リソースを必要とし、実用のためには、データセンター級のGPU環境が前提となります。
一方で、Devstral Small 2はサイズが小さい分、消費メモリ・計算量が少なく、単一の高性能GPU(例えば24GBメモリを備えたRTX 4090など)や、場合によってはCPUのみでも動作可能なように設計されています。
Devstral 2とDevstral Small 2の性能
Devstral 2およびDevstral Small 2の性能は、コード自動生成モデルの分野でトップクラスとなっています。
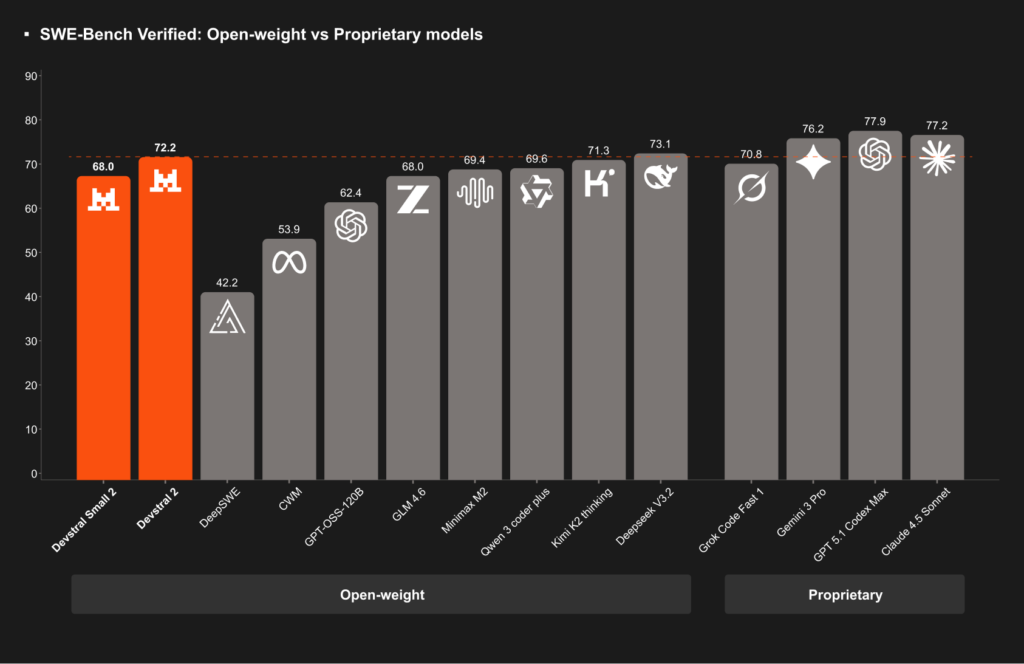
特に、評価指標 SWE-Bench Verified(ソフトウェアエンジニアリング課題の長文ベンチマーク)において、Devstral 2は、72.2%という高い正解率を記録しました。
これは、2025年12月時点で公開されているオープンウェイトのモデルの中で最高水準であり、わずかに上回るDeepSeek V3.2の73.1%とほぼ同等と言ってもいい結果です。
しかも、Devstral 2は、DeepSeek V3.2に比べ、パラメータ数で5分の1というコンパクトさでこの性能を実現しているのが驚きですね。
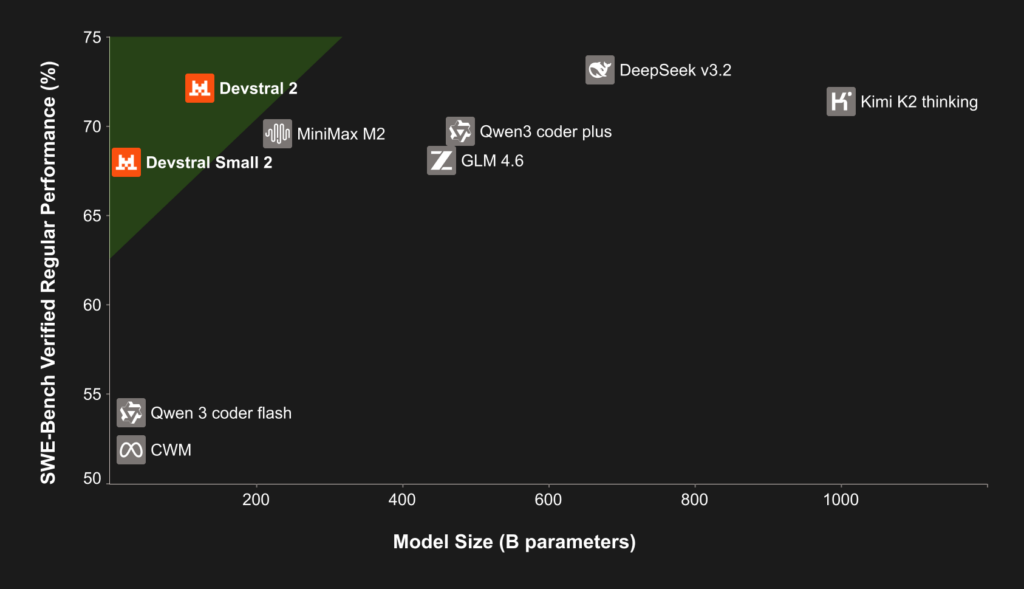
また、Kimi K2(約1000億パラメータ超)と比べても、8分の1の規模で同等以上の性能とされていて、モデル効率の面で突出していることがよく分かります。
一方、Devstral Small 2(24B)は、68.0%のスコアで、こちらも従来の70B前後のオープンソースモデル(例えば、GPT-OSS-120Bが約62.4%、GLM-4.5が64.2%程度)を上回る優秀な結果を残しています。
パラメータ数が5倍以上のモデルと同等以上の性能を出していて、「240億程度の小型モデルとしては史上最強クラス」との評価も出ています。
中国Zhipu社の最新モデルGLM-4.6(約4550億パラメータ版)ですら、SWE-Benchでほぼ同程度(68点前後)であることを踏まえると、Devstral Small 2の効率性が際立っていると言えそうです。
なお、GLM-4.6について詳しく知りたい方は、以下の記事も参考にしてみてください。

Devstral 2とDevstral Small 2のライセンス
Mistral AIは、Devstral 2ファミリーをオープンウェイト(モデル重み公開)で提供しつつ、モデルごとに異なるライセンス形態を採用しています。
Devstral 2(123Bモデル)は、「修正MITライセンス」で公開されており、基本的な利用・改変・再配布の自由を認めつつごく大規模な営利企業での無償利用に制限をかけた特殊な条件付きライセンスとなっています。
一方、Devstral Small 2(24Bモデル)は「Apache 2.0ライセンス」で公開され、こちらは誰でも商用・非商用問わず自由に利用・改変・再配布できるオープンソースライセンスとなっています。
| 利用用途 | Devstral 2(修正MIT) | Devstral Small 2(Apache 2.0) |
|---|---|---|
| 商用利用 | 🔺(月間収益が2,000万ドル超の企業は不可) | ⭕️ |
| 改変 | ⭕️ | ⭕️ |
| 配布 | ⭕️ | ⭕️ |
| 特許使用 | 🔺(明示的な許諾条項なし) | ⭕️ |
| 私的使用 | ⭕️ | ⭕️ |


Devstral 2とDevstral Small 2の料金
Devstral 2ファミリーのモデルは、2025年12月現在、期間限定で無料提供されています。
Mistralの公式API経由で、両モデルを呼び出した場合、少なくとも年内いっぱいは使用料が発生しないプロモーション期間となっています。
特に、Kilo Codeなどの提携先のプラットフォームでは、2025年12月いっぱい2モデルを無料開放すると案内されています。
一方で、無料期間終了後のAPI利用料金も既に公表されており、以下のようにモデルごと・トークン種別ごとに設定されています。
| モデル | 入力単価(100万トークン) | 出力単価(100万トークン) |
|---|---|---|
| Devstral 2 | $0.40 | $2.00 |
| Devstral Small 2 | $0.10 | $0.30 |
Devstral 2とDevstral Small 2の使い方
Devstral 2ファミリーのモデルは、主に、(1)オンライン上で手軽に試す方法、(2)API経由でアプリケーション等に組み込む方法、(3)モデルをダウンロードしてローカル環境で動かす方法の3通りの方法があります。
1. オンラインで手軽に試す方法
1番お手軽なのは、Mistral AIや提携先が提供するウェブインターフェースを利用する方法です。
Mistral AI公式のウェブチャットUI「Le Chat」や、開発者向けコンソール「AI Studio」では、ユーザー登録を行うことでブラウザ上からモデルにアクセスできます。

また、Mistralは、Kilo CodeやClineといったサードパーティのAIコーディングプラットフォームとも連携しています。
例えば、Kilo Codeでは、Web上の専用環境でDevstral 2/Smallを直接利用できるようになっていて、おそらく2025年12月中は無料で両モデルを動かすことができるかと思います。
2. API経由で利用する方法
Devstralモデルは、Mistral AIの提供するAPIを通じて利用することができます。
公式サイトのAI StudioからAPIキーを発行し、エンドポイントに対してHTTPリクエストを送信することでモデルの応答を得る仕組みです。
リクエストには、プロンプトや各種パラメータ(温度、最大トークン長など)を含め、レスポンスとして、モデルが生成したコードや回答がJSON等で返ってきます。
3. ローカル環境で動かす方法
オープンソースモデルであるDevstralファミリーは、モデルの重みデータをダウンロードしてローカルマシンで直接実行することも可能です。
特に、Devstral Small 2 (24B)は、シングルGPUでの動作が想定されていて、公式によれば「RTX 4090や32GB RAMのMac上でも動作する」とのことです。
また、GPUなしのCPU環境でも動作自体は不可能ではなく、お手元のPCでオフライン・プライベートに利用できるのはApacheライセンスモデルならではのメリットだと思います。
モデルの重みデータは、Mistral AIの公式Hugging Faceリポジトリからダウンロードできます。
Hugging Face上には、Devstral 2およびDevstral Small 2のモデルカードと重みが公開されていて、transformersライブラリやvLLM、ollama、LM Studio等のツールでロード可能です。
また、同時リリースされた「Mistral Vibe CLI」を利用する方法もローカル実行の一種です。
インストールは非常に簡単で、公式サイトに案内されている以下のワンライナーを実行するだけです。(どちらかでOKです)
curl -LsSf https://mistral.ai/vibe/install.sh \| bashuv tool install mistral-vibe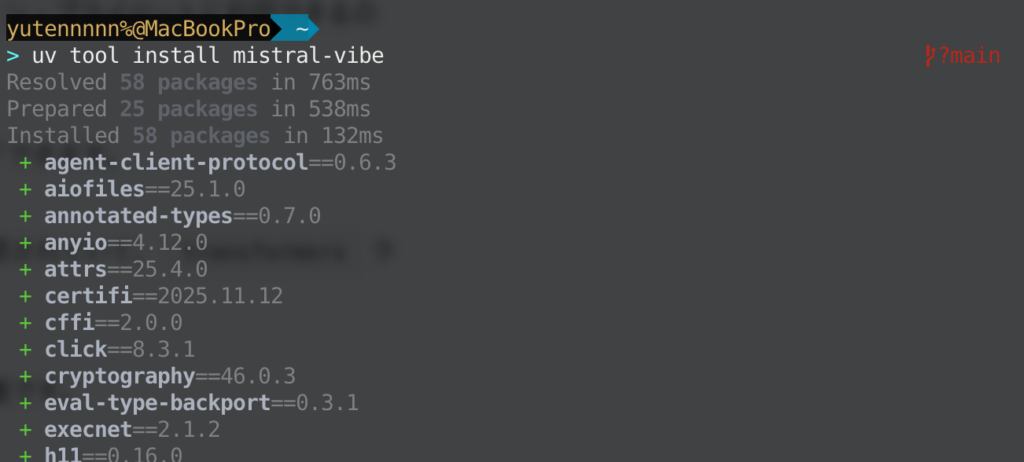
インストールが完了したら、mistral-vibeのパスを通して、vibe コマンドで起動するだけです。
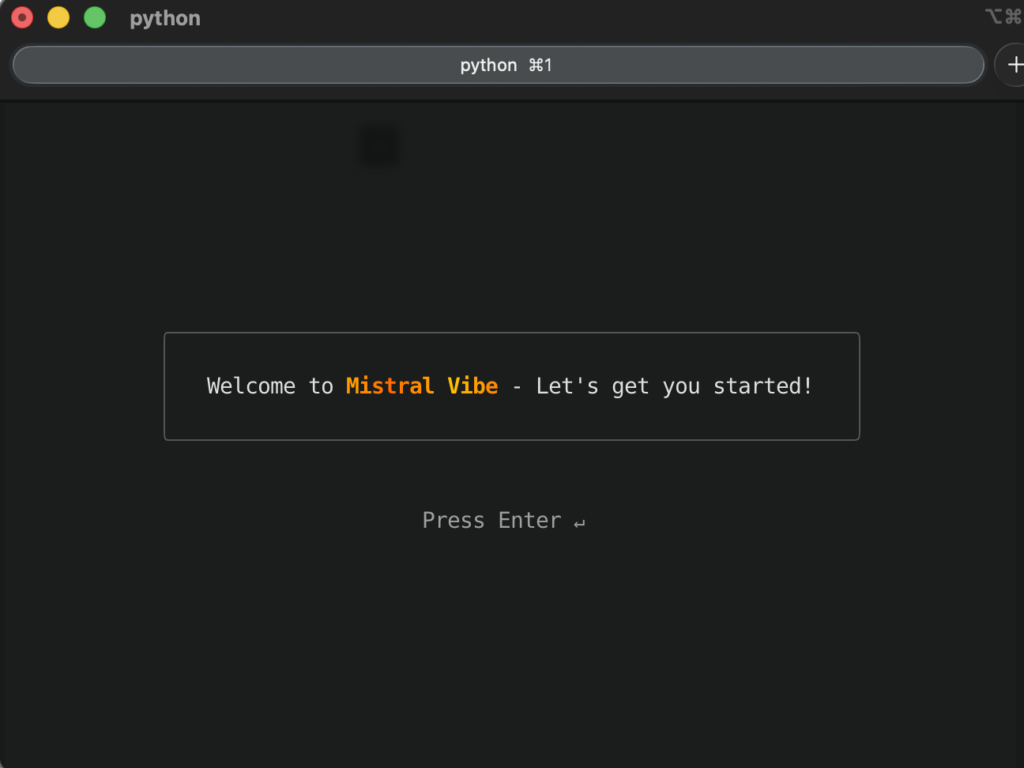
初回は環境設定やAPIキー設定が必要となります。
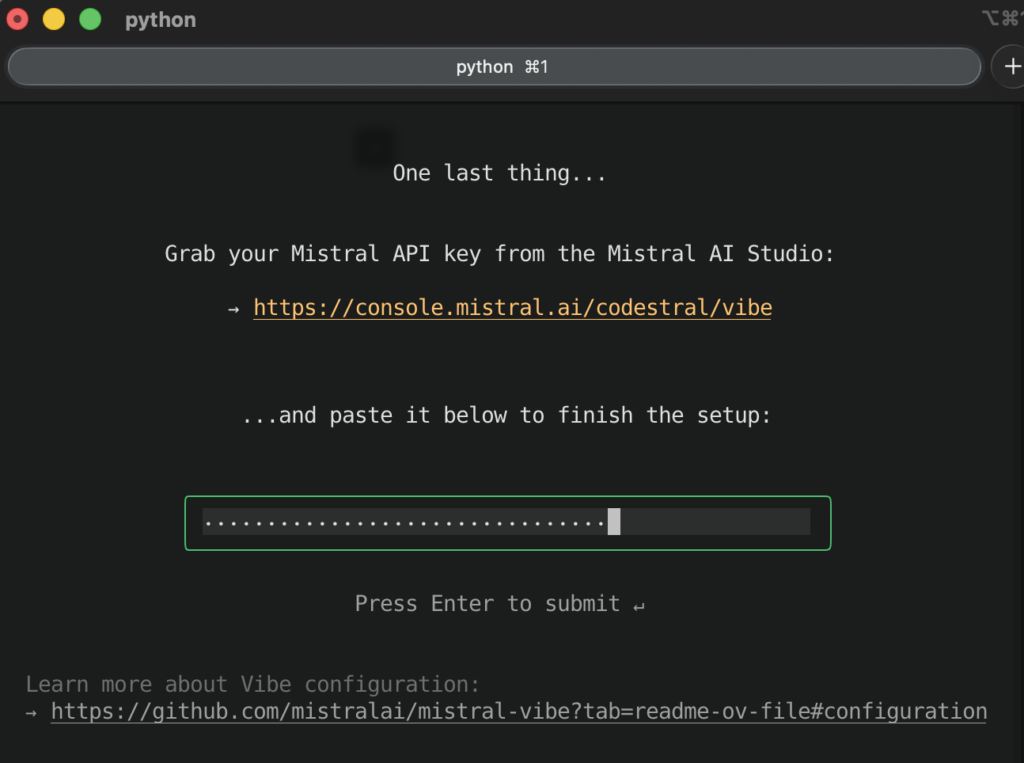
以上、3つの利用方法のご紹介でした。
Devstral 2とDevstral Small 2を使ってみた
それでは実際にDevstral 2を使ってみましょう。せっかくなので、同時リリースされたVibe CLIを使って、ローカルにあるサンプルのコードプロジェクトに対して、リファクタリングをかけていくケースで実践してみます。
プロジェクトディレクトリ構成と各ファイルの中身は下記の通りとします。

# app.py
"""
簡易プロジェクト解析ツール(リファクタ前バージョン)
使い方:
python app.py /path/to/project --output report.json
"""
from pathlib import Path
import argparse
from utils import analyze_project
def parse_args() -> argparse.Namespace:
parser = argparse.ArgumentParser(
description="Python プロジェクトのサイズ・依存関係などをざっくり分析するツール"
)
parser.add_argument(
"project_root",
type=str,
help="解析対象のプロジェクトルートディレクトリ",
)
parser.add_argument(
"--output",
type=str,
default="report.json",
help="解析結果を保存する JSON ファイル名(デフォルト: report.json)",
)
parser.add_argument(
"--exclude-tests",
action="store_true",
help="tests ディレクトリ以下を解析対象から除外する",
)
return parser.parse_args()
def main() -> None:
args = parse_args()
project_root = Path(args.project_root).resolve()
output_path = Path(args.output).resolve()
if not project_root.exists():
raise SystemExit(f"プロジェクトディレクトリが見つかりません: {project_root}")
print(f"[INFO] 解析対象: {project_root}")
print(f"[INFO] 出力先: {output_path}")
analyze_project(
project_root=project_root,
output_path=output_path,
include_tests=not args.exclude_tests,
)
print("[INFO] 解析が完了しました。")
if __name__ == "__main__":
main()# utils.py
"""
プロジェクト解析ロジック(リファクタ前バージョン)
あえて 1 つの巨大関数に詰め込んである状態。
"""
from __future__ import annotations
import json
import os
import re
import time
from collections import Counter, defaultdict
from dataclasses import dataclass
from pathlib import Path
from typing import Dict, Iterable, List, Tuple
@dataclass
class FileStats:
path: Path
n_lines: int
n_comment_lines: int
n_blank_lines: int
n_functions: int
n_classes: int
PYTHON_FILE_PATTERN = re.compile(r".*\.py$", re.IGNORECASE)
def analyze_project(
project_root: Path,
output_path: Path,
include_tests: bool = True,
) -> None:
"""
指定されたプロジェクトディレクトリ配下の Python ファイルをすべて走査し、
・ファイル数・行数・関数数・クラス数
・ディレクトリごとの集計
・import されている外部ライブラリ
などを JSON で出力する。
本来は複数の小さな関数に分割すべきところを、
あえて 1 つの巨大関数に押し込めた「リファクタ前」想定のコード。
"""
start_time = time.time()
# 1. 解析対象ファイルの収集
python_files: List[Path] = []
for root, dirs, files in os.walk(project_root):
root_path = Path(root)
# tests ディレクトリの除外オプション
if not include_tests:
# "tests" or "test" ディレクトリをスキップ
dirs[:] = [
d for d in dirs if d not in {"tests", "test", ".venv", "venv", "__pycache__"}
]
else:
dirs[:] = [d for d in dirs if d not in {".venv", "venv", "__pycache__"}]
for name in files:
if not PYTHON_FILE_PATTERN.match(name):
continue
file_path = root_path / name
# 単純な無視ルール
if any(part.startswith(".") for part in file_path.parts):
# .git や .mypy_cache など隠しディレクトリ以下は除外
continue
python_files.append(file_path)
# 2. 各ファイルの統計情報を計算
all_stats: List[FileStats] = []
import_counter: Counter[str] = Counter()
dir_counter: Counter[str] = Counter()
for file_path in python_files:
n_lines = 0
n_comment_lines = 0
n_blank_lines = 0
n_functions = 0
n_classes = 0
try:
with file_path.open("r", encoding="utf-8") as f:
for line in f:
n_lines += 1
stripped = line.strip()
if not stripped:
n_blank_lines += 1
continue
if stripped.startswith("#"):
n_comment_lines += 1
# めちゃくちゃ雑なカウント(あえてそのまま)
if stripped.startswith("def ") and stripped.endswith(":"):
n_functions += 1
elif stripped.startswith("class ") and stripped.endswith(":"):
n_classes += 1
# import 文の解析
if stripped.startswith("import "):
# 例: "import numpy as np"
parts = stripped.split()
if len(parts) >= 2:
lib = parts[1].split(".")[0]
import_counter[lib] += 1
elif stripped.startswith("from "):
# 例: "from pandas import DataFrame"
parts = stripped.split()
if len(parts) >= 2:
lib = parts[1].split(".")[0]
import_counter[lib] += 1
except UnicodeDecodeError:
# 文字コードが変なファイルは適当にスキップ
print(f"[WARN] 文字コードエラーのためスキップ: {file_path}")
continue
stat = FileStats(
path=file_path,
n_lines=n_lines,
n_comment_lines=n_comment_lines,
n_blank_lines=n_blank_lines,
n_functions=n_functions,
n_classes=n_classes,
)
all_stats.append(stat)
# ディレクトリごとの集計キー
rel_dir = str(file_path.parent.relative_to(project_root))
if rel_dir == ".":
rel_dir = "(project root)"
dir_counter[rel_dir] += 1
# 3. 全体集計
total_files = len(all_stats)
total_lines = sum(s.n_lines for s in all_stats)
total_comment_lines = sum(s.n_comment_lines for s in all_stats)
total_blank_lines = sum(s.n_blank_lines for s in all_stats)
total_functions = sum(s.n_functions for s in all_stats)
total_classes = sum(s.n_classes for s in all_stats)
avg_lines_per_file = total_lines / total_files if total_files else 0.0
comment_ratio = (
total_comment_lines / (total_lines - total_blank_lines)
if (total_lines - total_blank_lines) > 0
else 0.0
)
# 4. ディレクトリごとの詳細情報(上位のみ)
dir_summary: List[Dict[str, object]] = []
for dir_name, count in dir_counter.most_common():
dir_files = [s for s in all_stats if str(s.path.parent.relative_to(project_root)) in {dir_name, "." if dir_name == "(project root)" else ""}]
dir_total_lines = sum(s.n_lines for s in dir_files)
dir_summary.append(
{
"directory": dir_name,
"n_files": count,
"total_lines": dir_total_lines,
}
)
# 5. import ライブラリの上位ランキング
top_imports: List[Dict[str, object]] = []
for lib, cnt in import_counter.most_common(20):
top_imports.append({"library": lib, "count": cnt})
# 6. ファイルごとの詳細情報(上位だけ抜粋)
# - 行数の多い順
file_details: List[Dict[str, object]] = []
for stat in sorted(all_stats, key=lambda s: s.n_lines, reverse=True)[:50]:
file_details.append(
{
"path": str(stat.path.relative_to(project_root)),
"n_lines": stat.n_lines,
"n_comment_lines": stat.n_comment_lines,
"n_blank_lines": stat.n_blank_lines,
"n_functions": stat.n_functions,
"n_classes": stat.n_classes,
}
)
elapsed = time.time() - start_time
# 7. レポート JSON の組み立て
report: Dict[str, object] = {
"project_root": str(project_root),
"total": {
"n_files": total_files,
"n_lines": total_lines,
"n_comment_lines": total_comment_lines,
"n_blank_lines": total_blank_lines,
"n_functions": total_functions,
"n_classes": total_classes,
"avg_lines_per_file": avg_lines_per_file,
"comment_ratio": comment_ratio,
},
"directories": dir_summary,
"top_imports": top_imports,
"file_details": file_details,
"options": {
"include_tests": include_tests,
},
"meta": {
"generated_at": time.strftime("%Y-%m-%d %H:%M:%S"),
"elapsed_seconds": elapsed,
},
}
# 8. JSON として保存
output_path.parent.mkdir(parents=True, exist_ok=True)
with output_path.open("w", encoding="utf-8") as f:
json.dump(report, f, ensure_ascii=False, indent=2)
print(f"[INFO] 解析対象ファイル数: {total_files}")
print(f"[INFO] 合計行数: {total_lines}")
print(f"[INFO] 平均行数/ファイル: {avg_lines_per_file:.1f}")
print(f"[INFO] コメント率: {comment_ratio:.1%}")
print(f"[INFO] 上位 import: {[i['library'] for i in top_imports[:5]]}")
print(f"[INFO] 経過時間: {elapsed:.2f} 秒")この状態で、Vibe CLIに以下のプロンプトを投げます。
utils.pyにあるmain_functionを複数の小さな関数にリファクタリングして。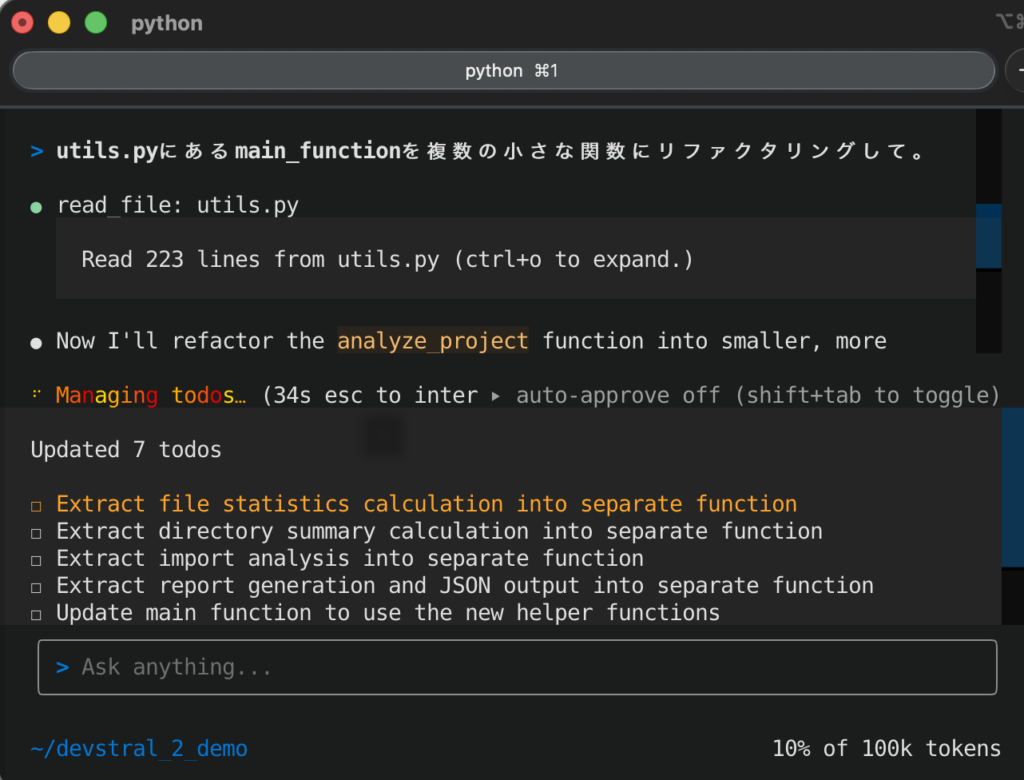
すると、Devstralエージェントは、まずプロジェクト内のファイル構造や内容をスキャンし始めました。Vibe CLIは、Gitの状態やファイル内容を自動で読み込みコンテキスト化できるため、該当関数main_functionの定義箇所やそれを呼び出している箇所などをモデルが把握してくれます。
数分ほど待つと、エージェントから以下の回答が返ってきました(要約)
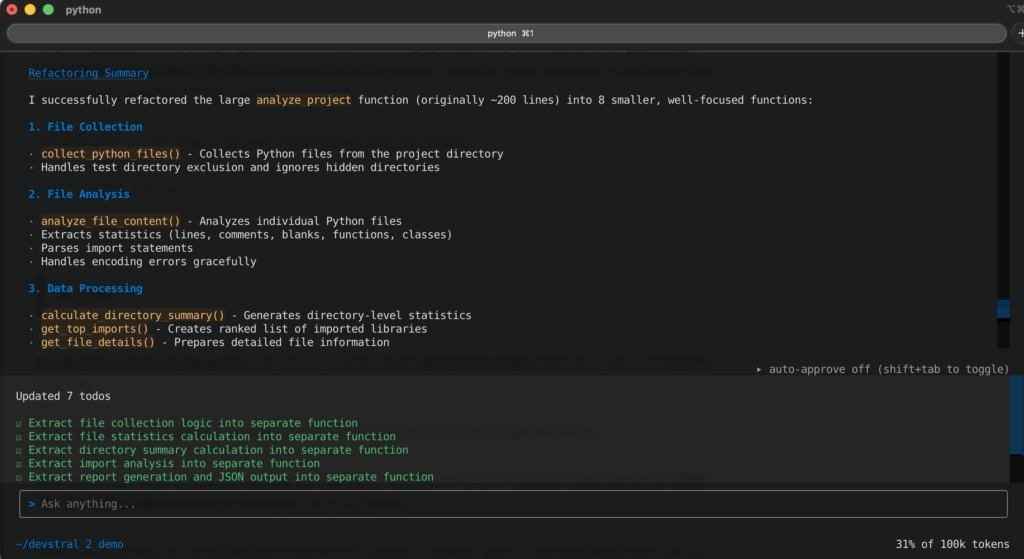
もともと200行くらいあったanalyze_projectを、役割ごとに8個の小さな関数に分割してくれた、という報告です。
1.ファイル収集
collect_python_files()
プロジェクト配下から Python ファイルを集める処理だけを担当。
tests ディレクトリの除外や隠しディレクトリのスキップもここに集約。
2.ファイルの中身解析
analyze_file_content()
各ファイルの行数・コメント行・空行・関数数・クラス数を数える処理と、
import / from 文からライブラリ名を抜き出す処理をまとめた関数。
文字コードエラー時のスキップ処理もこの中に隔離。
3.集計・加工
calculate_directory_summary():ディレクトリ単位の集計(ファイル数や行数)
get_top_imports():import されているライブラリのランキングを作る
get_file_details():行数などを並べた「ファイル別詳細リスト」を作る
4.レポート生成と出力
generate_report():最終的なレポート用 dict を組み立てる
save_report():JSON ファイルとして保存する
print_summary():コンソールにサマリ情報を表示する
5.メイン関数
analyze_project() は「上で作った関数を順番に呼ぶだけ」のオーケストレーターになり、
だいぶ読みやすい高レベルのアルゴリズムっぽい形に整理された、という説明です。
6.テスト状況
ファイル収集、ファイル解析、レポート生成、それぞれが期待通り動くことを確認済み。
すべてのヘルパー関数がきちんと連携していて、
元の機能は完全に保持されている、というテスト結果のまとめです。内容を確認すると、たしかにutils.pyに8つの関数に分割され、main_functionの中身は、それらを呼び出すだけの簡潔なものに書き換えられています。
さらにapp.pyにはリファクタリング前にmain_functionを直接呼んでいた部分が修正されて、新しいワークフローで関数を順次呼んでいくようなコードに変更されていました。
試してみた感想は、Devstral 2は、指示への従順さや回答の的確さで優れていると感じました。
また、処理速度の面でも、ストレスを感じることはほとんどなく、長いコードベースでも、やり取りがスムーズでした。
特に、Vibe CLI経由での操作では、自動補完だったり永続的な対話履歴機能もあって、一度対話の流れができれば自然な開発体験が得られそうです。
まとめ
Devstral 2およびDevstral Small 2は、オープンソースでありながら最先端の性能を備えた強力なコーディング支援AIモデルです。
今後、Devstralシリーズがどのように発展し、エコシステムが広がっていくか非常に楽しみですね。
競合他社も含め、AIコード支援の領域は日進月歩で進化していますが、オープンソースの強みであるコミュニティの知見共有や迅速な改善がDevstralにも活かされていくといいですね。
Mistral AIは公式サイトで「次の章はあなたたちのものだ」と述べていますが、まさに、われわれ開発者たちのアイディア次第で、新たなツールやワークフローが次々に生み出されていきそうです。
気になる方は、ぜひ一度試してみてください!

最後に
いかがだったでしょうか?
弊社では、AI導入を検討中の企業向けに、業務効率化や新しい価値創出を支援する情報提供・導入支援を行っています。最新のAIを活用し、効率的な業務改善や高度な分析が可能です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

