
Maya1とは?感情豊かな音声を生成できるオープンソースTTSモデルの全貌を解説
- 完全オープンソースかつ無料で使える感情制御対応の高品質TTSモデル・Maya1
- 自然言語による音声デザインと20種以上の感情表現をリアルタイム生成で実現
- 商用利用可能なApache 2.0ライセンスで、個人から企業まで低コスト導入が可能
AIの進化、すごいですよね。特に音声を生成する分野(Text-to-Speech、TTS)は、人間と見分けがつかないほどになっていて、自然な音声を生成するモデルが次々と登場しています。
しかし現在主流となっているTTSの多くはクローズドソースの高価な商用サービスです。また、オープンソースであっても感情表現やリアルタイム性に課題があります。
本記事では、こうした状況を打破する可能性を秘めた画期的なオープンソース音声生成AI「Maya1」について、その概要から仕組み、具体的な使い方までを徹底解説します。
\生成AIを活用して業務プロセスを自動化/
Maya1の概要
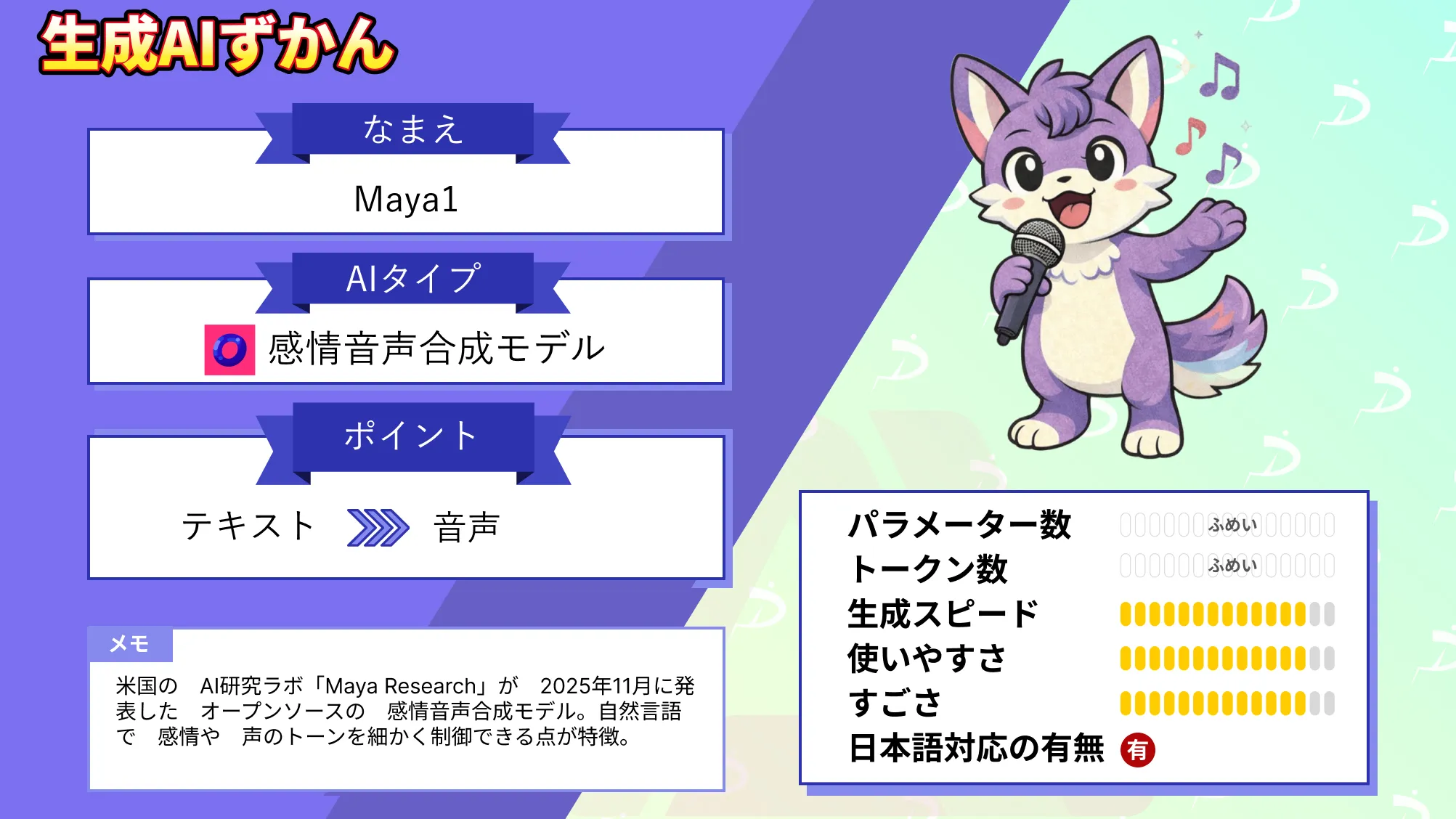
米国のAI研究ラボ「Maya Research」が2025年11月に発表したオープンソースの感情音声合成モデルです。自然言語で感情や声のトーンを細かく制御できる点が特徴で、従来の高価な商用サービスと、感情表現に乏しいオープンソースモデルの「いいとこ取り」を実現しています。プロダクション品質の音声合成を完全無料で提供し、音声AI技術の民主化を目指しているようです。
なお、声の常識を変えるElevenLabsに関しては、下記の記事をご覧ください。

Maya1の仕組み
パラメータを30億個持つLlama(LLM)ベースのトランスフォーマーアーキテクチャという仕組みを採用しています。一般的な言語モデルがテキストトークンを予測するのに対し、Maya1は「SNAC」と呼ばれるニューラル音声コーデック(AIを使って音声データを高品質に圧縮・復元する技術)のトークンを予測する点が特徴的です。この仕組みにより、約0.98kbpsという低ビットレートでもリアルタイムストリーミングが可能となります。
Maya1の特徴
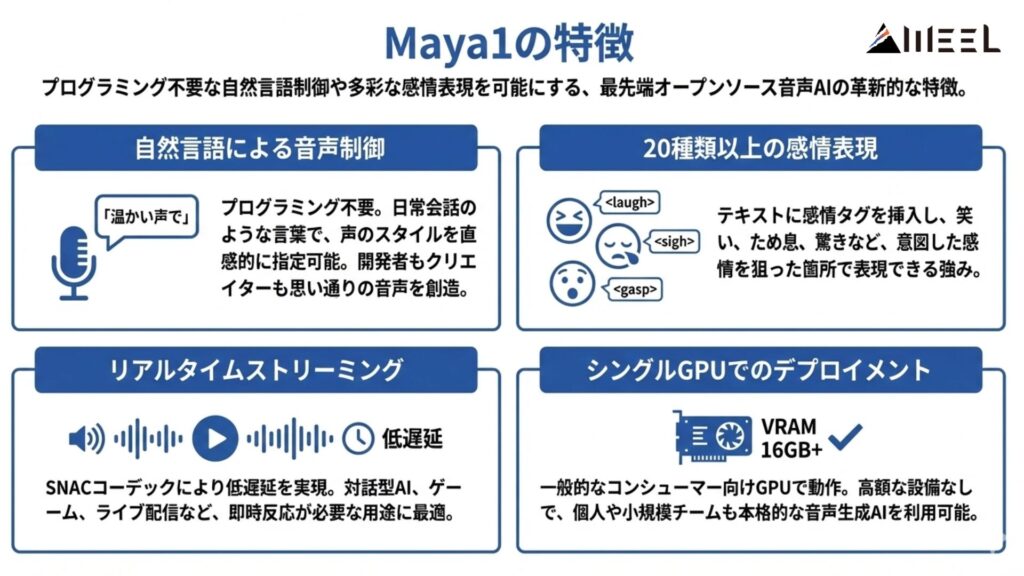
最先端のオープンソース音声AI「Maya1」は、プログラミング不要な 自然言語での声制御や、20種類超の感情表現を可能にします。開発者もクリエイターも、思いのままの音声を直感的に創造できる、その革新的な特徴をご紹介します。
自然言語による音声制御
最大の特徴は、難しいプログラミングや音声学の専門知識がなくても、日常会話のような言葉で音声スタイルを指定できることです。たとえば、「30代のアメリカ人男性で、温かみがあって会話的な雰囲気の声」と英語で指示すれば、その通りの音声が生成されます。これなら、開発者だけでなくクリエイターも、思い描いた通りの音声を直感的に作れるわけです。
20種類以上の感情表現
Maya1では、笑い(<laugh>)、ため息(<sigh>)、ささやき(<whisper>)といった感情タグを、テキストの好きな場所に入れられます。感情タグは20種類以上用意されており、台本の狙った箇所で意図した感情を表現できるのが強みです。実際、「信じられない! <gasp> なんてことだ!」と書くだけで、驚いて息をのむ瞬間が音声に反映されます。
リアルタイムストリーミング
SNACコーデックのおかげで、Maya1は低遅延のリアルタイムストリーミングが可能になっています。これは、対話型AIエージェントやゲームキャラクターの声、ライブ配信のナレーションなど、すぐに反応が必要なアプリケーションでは欠かせない機能といえるでしょう。
シングルGPUでのデプロイメント
30億パラメータという規模の大きさを考えると驚きですが、Maya1は一般的なコンシューマー向けGPU(VRAM 16GB以上)で動かせるよう設計されています。つまり、データセンターのような高額な設備がなくても、個人開発者や小規模なスタートアップが、本格的な音声生成AIを自分たちの環境で使えるということです。
同企業では、プロダクション品質の音声合成を完全無料で提供し、音声AI技術の民主化を目指しているようです。
なお、日本語含む10言語対応の多言語に対応したQwen3-TTS-Flashに関しては、下記の記事をご覧ください。

類似サービスとの比較
| 機能 | Maya1 | ElevenLabs | OpenAI TTS | Coqui TTS |
|---|---|---|---|---|
| オープンソース | はい | いいえ | いいえ | はい |
| 感情 | 20種類以上 | モデルによる | 一部対応(話し方、トーン調整など) | 感情/話し方のスタイル指定 |
| 音声デザイン | 自然言語 | 音声ライブラリ | カスタムボイス | 音声クローン / スタイル学習 |
| ストリーミング | リアルタイム | リアルタイム | ストリーミング可能 | ストリーミング可能 |
| 費用 | 原則無料 | サブスクリプション/従量課金 | 従量課金 | 原則無料 |
| カスタマイズ | 高い(自然言語でスタイル指定) | 高い(カスタムボイス、デザイン) | 高い(カスタムボイス作成) | 非常に高い(モデル学習/微調整) |
| パラメータ | 30億 | 非公開 | 非公開 | 様々(学習に使用するモデルによる) |
Maya1の安全性・制約
非常に強力な技術である一方、Maya1にはいくつかの制約と、悪用に対する懸念が存在します。
| 項目 | 内容 |
|---|---|
| 多言語対応 | 今のところ、公式モデルが対応しているのは英語だけです。日本語のように音の特徴が英語と大きく違う言語については、まだこれからの課題となっています。 |
| ディープフェイク | どんな声でも真似できてしまうため、悪意を持った人が「声のディープフェイク」として悪用する危険性は否定できません。Maya Research側もこのリスクは把握していて、倫理的な使い方を守るよう呼びかけています。 |
| データバイアス | 学習に使われたデータが特定地域の英語話者に偏っている可能性もあり、世界中のさまざまなアクセントや話し方を完璧に再現するのは難しいかもしれません。 |
Maya1の料金
Apache 2.0ライセンスの下で公開されている完全なオープンソースプロジェクトであり、無料で利用できます。初期費用、ランニングコスト、生成した音声の量に応じた従量課金などは原則として一切発生しません。
ただし、モデルの動作に必要なハードウェアや、クラウド環境でMaya1を利用する場合のインフラ利用料(サーバー代、電力費、ネットワーク通信費など)は、ご利用者様のご負担となりますのでご注意ください。
Maya1のライセンス
Maya1に採用されているApache 2.0ライセンスは、非常に寛容なオープンソースライセンスとして知られています。以下に、主要な権利をまとめました。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | 可能 |
| 改変 | 可能 |
| 配布 | 可能 |
| 特許使用 | 可能 |
| 私的使用 | 可能 |
Maya1の実装方法(手順・環境)
Maya1を実際に動かすための基本的な構築手順を説明します。
ローカル環境への構築(Windows OS)
実装した環境
- OS: Windows11 64bit
- GPU: NVIDIA GeForce RTX 4060 Ti 16GB
- ソフトウェア: Python 3.10.11
前提条件
- Pythonの事前インストールが必要
- Windows OSのみ
実装手順
- 以下のサイトからコードをコピーし、.pyファイルを作成(筆者はtest.pyという名前で作成)
実際のコードはこちら↓
#!/usr/bin/env python3
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from snac import SNAC
import soundfile as sf
import numpy as np
CODE_START_TOKEN_ID = 128257
CODE_END_TOKEN_ID = 128258
CODE_TOKEN_OFFSET = 128266
SNAC_MIN_ID = 128266
SNAC_MAX_ID = 156937
SNAC_TOKENS_PER_FRAME = 7
SOH_ID = 128259
EOH_ID = 128260
SOA_ID = 128261
BOS_ID = 128000
TEXT_EOT_ID = 128009
def build_prompt(tokenizer, description: str, text: str) -> str:
"""Build formatted prompt for Maya1."""
soh_token = tokenizer.decode([SOH_ID])
eoh_token = tokenizer.decode([EOH_ID])
soa_token = tokenizer.decode([SOA_ID])
sos_token = tokenizer.decode([CODE_START_TOKEN_ID])
eot_token = tokenizer.decode([TEXT_EOT_ID])
bos_token = tokenizer.bos_token
formatted_text = f'<description="{description}"> {text}'
prompt = (
soh_token + bos_token + formatted_text + eot_token +
eoh_token + soa_token + sos_token
)
return prompt
def extract_snac_codes(token_ids: list) -> list:
"""Extract SNAC codes from generated tokens."""
try:
eos_idx = token_ids.index(CODE_END_TOKEN_ID)
except ValueError:
eos_idx = len(token_ids)
snac_codes = [
token_id for token_id in token_ids[:eos_idx]
if SNAC_MIN_ID <= token_id <= SNAC_MAX_ID
]
return snac_codes
def unpack_snac_from_7(snac_tokens: list) -> list:
"""Unpack 7-token SNAC frames to 3 hierarchical levels."""
if snac_tokens and snac_tokens[-1] == CODE_END_TOKEN_ID:
snac_tokens = snac_tokens[:-1]
frames = len(snac_tokens) // SNAC_TOKENS_PER_FRAME
snac_tokens = snac_tokens[:frames * SNAC_TOKENS_PER_FRAME]
if frames == 0:
return [[], [], []]
l1, l2, l3 = [], [], []
for i in range(frames):
slots = snac_tokens[i*7:(i+1)*7]
l1.append((slots[0] - CODE_TOKEN_OFFSET) % 4096)
l2.extend([
(slots[1] - CODE_TOKEN_OFFSET) % 4096,
(slots[4] - CODE_TOKEN_OFFSET) % 4096,
])
l3.extend([
(slots[2] - CODE_TOKEN_OFFSET) % 4096,
(slots[3] - CODE_TOKEN_OFFSET) % 4096,
(slots[5] - CODE_TOKEN_OFFSET) % 4096,
(slots[6] - CODE_TOKEN_OFFSET) % 4096,
])
return [l1, l2, l3]
def main():
# Load the best open source voice AI model
print("\n[1/3] Loading Maya1 model...")
model = AutoModelForCausalLM.from_pretrained(
"maya-research/maya1",
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained(
"maya-research/maya1",
trust_remote_code=True
)
print(f"Model loaded: {len(tokenizer)} tokens in vocabulary")
# Load SNAC audio decoder (24kHz)
print("\n[2/3] Loading SNAC audio decoder...")
snac_model = SNAC.from_pretrained("hubertsiuzdak/snac_24khz").eval()
if torch.cuda.is_available():
snac_model = snac_model.to("cuda")
print("SNAC decoder loaded")
# Design your voice with natural language
description = "Realistic male voice in the 30s age with american accent. Normal pitch, warm timbre, conversational pacing."
text = "Hello! This is Maya1 <laugh_harder> the best open source voice AI model with emotions."
print("\n[3/3] Generating speech...")
print(f"Description: {description}")
print(f"Text: {text}")
# Create prompt with proper formatting
prompt = build_prompt(tokenizer, description, text)
# Debug: Show prompt details
print(f"\nPrompt preview (first 200 chars):")
print(f" {repr(prompt[:200])}")
print(f" Prompt length: {len(prompt)} chars")
# Generate emotional speech
inputs = tokenizer(prompt, return_tensors="pt")
print(f" Input token count: {inputs['input_ids'].shape[1]} tokens")
if torch.cuda.is_available():
inputs = {k: v.to("cuda") for k, v in inputs.items()}
with torch.inference_mode():
outputs = model.generate(
**inputs,
max_new_tokens=2048, # Increase to let model finish naturally
min_new_tokens=28, # At least 4 SNAC frames
temperature=0.4,
top_p=0.9,
repetition_penalty=1.1, # Prevent loops
do_sample=True,
eos_token_id=CODE_END_TOKEN_ID, # Stop at end of speech token
pad_token_id=tokenizer.pad_token_id,
)
# Extract generated tokens (everything after the input prompt)
generated_ids = outputs[0, inputs['input_ids'].shape[1]:].tolist()
print(f"Generated {len(generated_ids)} tokens")
# Debug: Check what tokens we got
print(f" First 20 tokens: {generated_ids[:20]}")
print(f" Last 20 tokens: {generated_ids[-20:]}")
# Check if EOS was generated
if CODE_END_TOKEN_ID in generated_ids:
eos_position = generated_ids.index(CODE_END_TOKEN_ID)
print(f" EOS token found at position {eos_position}/{len(generated_ids)}")
# Extract SNAC audio tokens
snac_tokens = extract_snac_codes(generated_ids)
print(f"Extracted {len(snac_tokens)} SNAC tokens")
# Debug: Analyze token types
snac_count = sum(1 for t in generated_ids if SNAC_MIN_ID <= t <= SNAC_MAX_ID)
other_count = sum(1 for t in generated_ids if t < SNAC_MIN_ID or t > SNAC_MAX_ID)
print(f" SNAC tokens in output: {snac_count}")
print(f" Other tokens in output: {other_count}")
# Check for SOS token
if CODE_START_TOKEN_ID in generated_ids:
sos_pos = generated_ids.index(CODE_START_TOKEN_ID)
print(f" SOS token at position: {sos_pos}")
else:
print(f" No SOS token found in generated output!")
if len(snac_tokens) < 7:
print("Error: Not enough SNAC tokens generated")
return
# Unpack SNAC tokens to 3 hierarchical levels
levels = unpack_snac_from_7(snac_tokens)
frames = len(levels[0])
print(f"Unpacked to {frames} frames")
print(f" L1: {len(levels[0])} codes")
print(f" L2: {len(levels[1])} codes")
print(f" L3: {len(levels[2])} codes")
# Convert to tensors
device = "cuda" if torch.cuda.is_available() else "cpu"
codes_tensor = [
torch.tensor(level, dtype=torch.long, device=device).unsqueeze(0)
for level in levels
]
# Generate final audio with SNAC decoder
print("\n[4/4] Decoding to audio...")
with torch.inference_mode():
z_q = snac_model.quantizer.from_codes(codes_tensor)
audio = snac_model.decoder(z_q)[0, 0].cpu().numpy()
# Trim warmup samples (first 2048 samples)
if len(audio) > 2048:
audio = audio[2048:]
duration_sec = len(audio) / 24000
print(f"Audio generated: {len(audio)} samples ({duration_sec:.2f}s)")
# Save your emotional voice output
output_file = "output.wav"
sf.write(output_file, audio, 24000)
print(f"\nVoice generated successfully!")
if __name__ == "__main__":
main()
- 作成したファイルを任意のフォルダに配置
- PowerShellを開き、2のフォルダに移動する
- 以下のコマンドを実行し、関連パッケージをインストール
pip install torch transformers snac soundfile torchvisionクラウド環境への構築(Google Colaboratory)
実装した環境
Google Colaboratory
前提条件
Googleアカウントの作成
実装手順
- Google Colab画面にアクセスし、Googleアカウントでログインします。
- 画面右上の「New Notebook」をクリックし、新しいノートを作成します。
- メニューバーの「ランタイム」→「ランタイムのタイプを変更」を開き、ハードウェアアクセラレーションを「GPU」に設定して保存します。
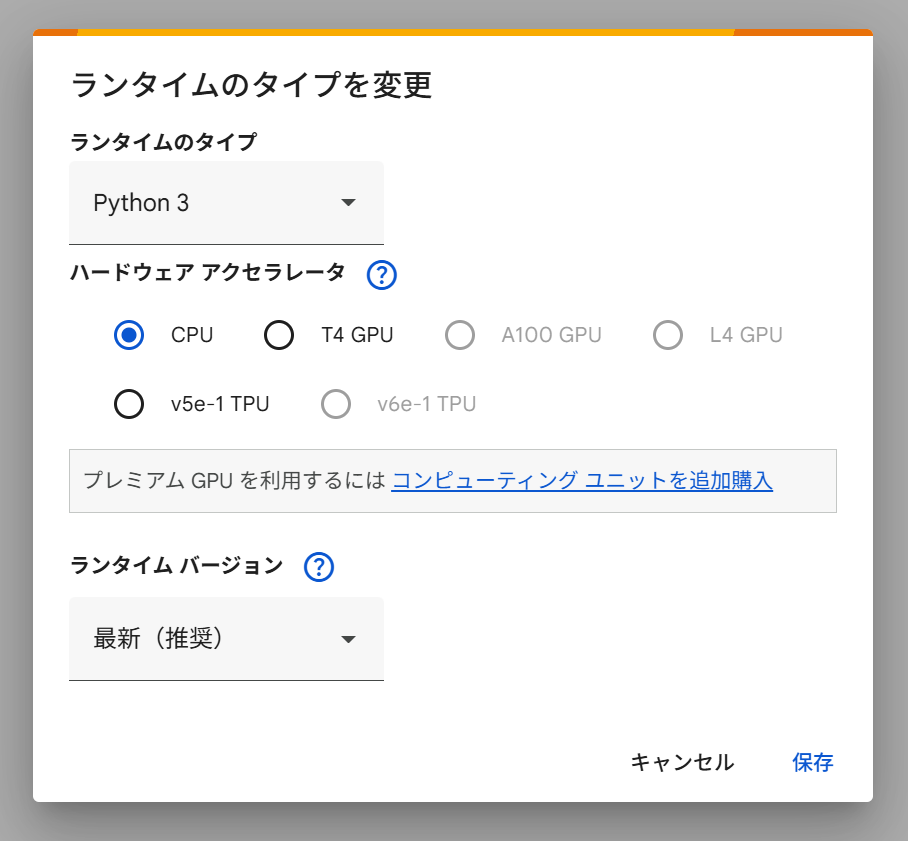
- Maya1の動作に必要なPythonライブラリをインストールします。
入力欄に以下のコードを入力し、実行します。
!pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu118
!pip install transformers snac
- Maya1の公式GitHubリポジトリまたは配布されている場所からコードを取得します。
以下のコードを実行します。
!git clone https://github.com/MayaResearch/maya1-fastapi.git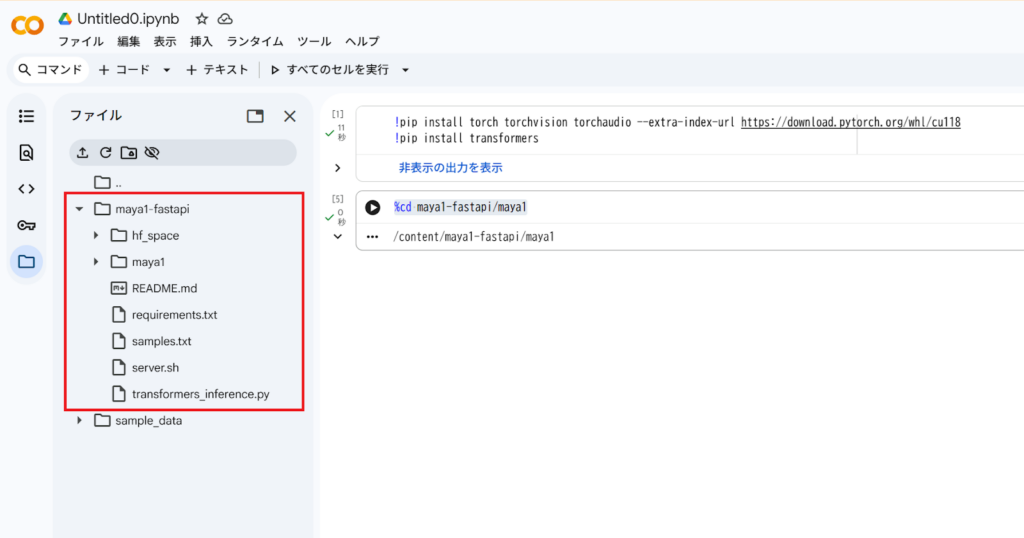
Maya1の活用シーン
Maya1の持つ表現力と柔軟性は、様々な分野での応用が期待されます。
| 用途 | 内容 |
|---|---|
| ゲーム開発 | NPCのセリフを作る際、感情がこもった自然な音声を、コストを抑えながら大量に用意できるのは大きな魅力です。キャラクターごとに声の雰囲気を変えることで、ゲーム世界の臨場感がぐっと増します。 |
| オーディオブック・ポッドキャスト制作 | 登場人物それぞれに違った声質や感情を持たせられるので、聴いている人がストーリーに引き込まれやすくなります。声優を複数人雇う予算がなくても、クオリティの高い作品が作れるわけです。 |
| インタラクティブAIアシスタント | ユーザーと会話するとき、ただ機械的に答えるのではなく、人間らしい感情を込めた返事ができます。これによって、使う人との距離が縮まり、親しみやすいコミュニケーションが生まれます。 |
| 動画コンテンツ制作 | YouTubeの解説動画などで、わざわざプロのナレーターに頼まなくても、高品質なナレーションを自動で作れます。個人クリエイターにとっては、制作コストを大幅に削減できる強い味方になるでしょう。 |
| アクセシビリティ | 視覚に障がいのある方が使うスクリーンリーダーに、感情のニュアンスを加えられます。単調な読み上げではなく、抑揚のある音声で情報が伝わることで、理解しやすさが格段に向上します。 |
なお、OpenAIの新音声合成モデル「GPT-4o Mini TTS」に関しては、下記の記事をご覧ください。
Maya1を実際に使ってみた
ローカル環境での実行(Windows OS)
まずは初期設定のまま実行した結果を紹介します。
| 項目 | 設定内容 |
|---|---|
| 声の雰囲気 | Realistic male voice in the 30s age with american accent. Normal pitch, warm timbre, conversational pacing. 和訳:30代の男性でアメリカ英語アクセント、音程は普通、声の質は温かみがあり、会話のようなテンポ。 |
| 出力 | Hello! This is Maya1 <laugh_harder> the best open source voice AI model with emotions. 和訳:こんにちは!これはMaya1です。<laugh_harder> 感情を持つ最高のオープンソース音声AIモデルです。 |
- 以下のコマンドで、.pyファイルを実行する
python test.py音声データの生成が開始されます。
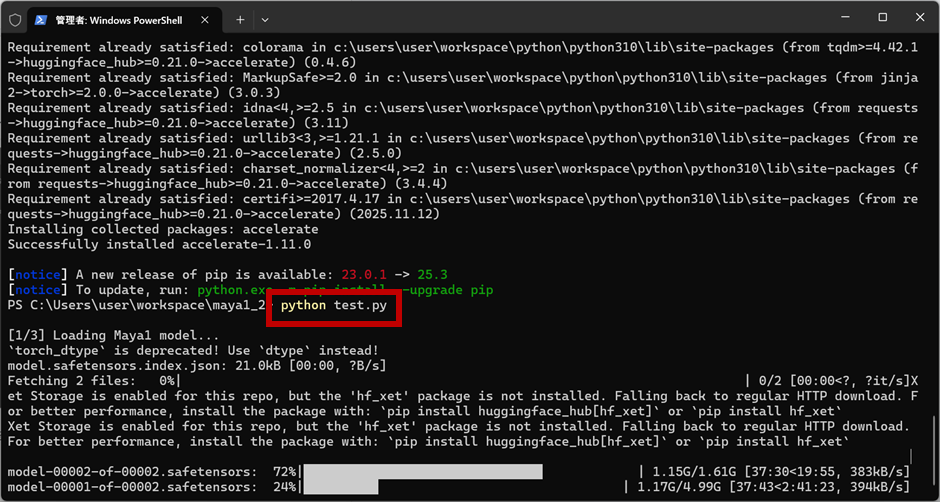
- 生成が終わるまでひたすら待つ……
- 実行した.pyファイルと同じフォルダ内に「output.wav」という音声ファイルが生成されます。(初回実行時は、完了まで2時間近くかかりました。)
次に、内容を少し変えて実行してみました。
| 項目 | 設定内容 |
|---|---|
| 声の雰囲気 | Teenage female voice with a British accent, slightly high pitch, a cold and calm tone, and a pacing that feels pressuring or cornering to the listener. 和訳:10代の女性でイギリス英語アクセント、音程は高め、声の質は冷たく冷静なイメージ、相手を追い詰めるようなテンポ。 |
| 出力 | <angry>Why?! Why did you eat my pudding?! I was really, really looking forward to it tonight! How are you going to make up for this?! 和訳:どうして!私のプリンを食べたのですか!今日の夜を楽しみにしていたのに。この埋め合わせはどうやってしますか |
- test.pyを開き、「description」と「text」を修正します。
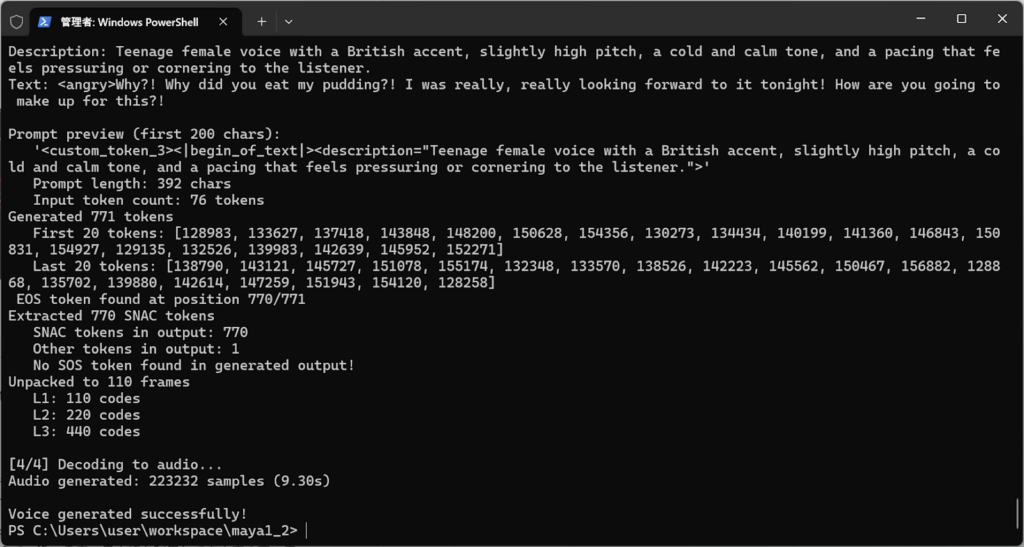
- 保存して、test.pyを実行します。
python test.py- output.wavファイルが作成されます。(2回目以降は、5分程度で完了しました。)
クラウド環境での実行(google colaboratory)
ローカル環境での実行と同様に、初期設定のまま実行しました。
- 以下のコマンドで、pythonファイルを実行する。
!python transformers_inference.py
完了すると「output.wav」ファイルが生成され、ダウンロードして音声を聞くことができます。
- google colaboratoryでの実行時に、声の雰囲気と出力を変えたい場合は、「transformers_inference.py」ファイルの「description」と「text」を修正することで出力結果を変えることができます。
公式のデモ環境での実行(Play Ground)
Maya Researchでは、Maya1の公式デモ環境が準備されています。
デモ環境での実行についても簡単にご紹介します。
- 以下のURLにアクセスします。

- 右上の「Sign in」ボタンをクリックし、サインインします。
- 画面中央の入力欄に出力したいテキストを英語で入力します。
この時、感情については入力欄下の「Try these emotional tags:」をクリックすることで簡単に選択することができます。
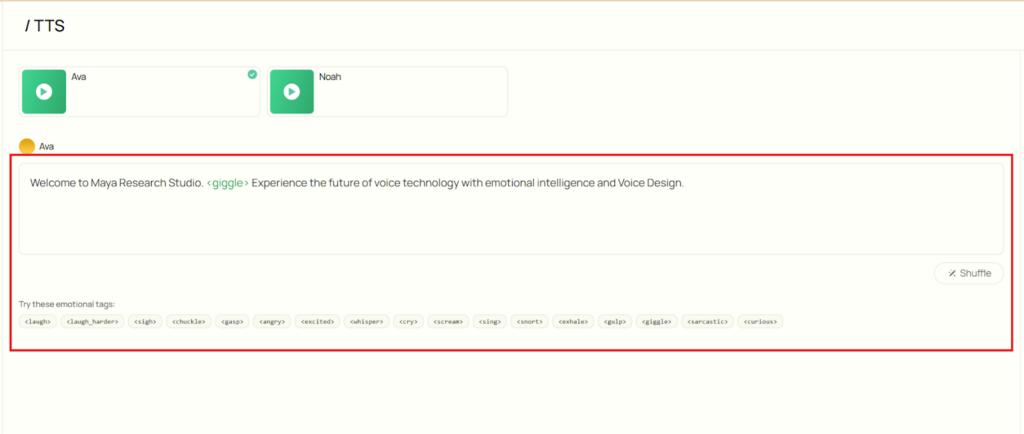
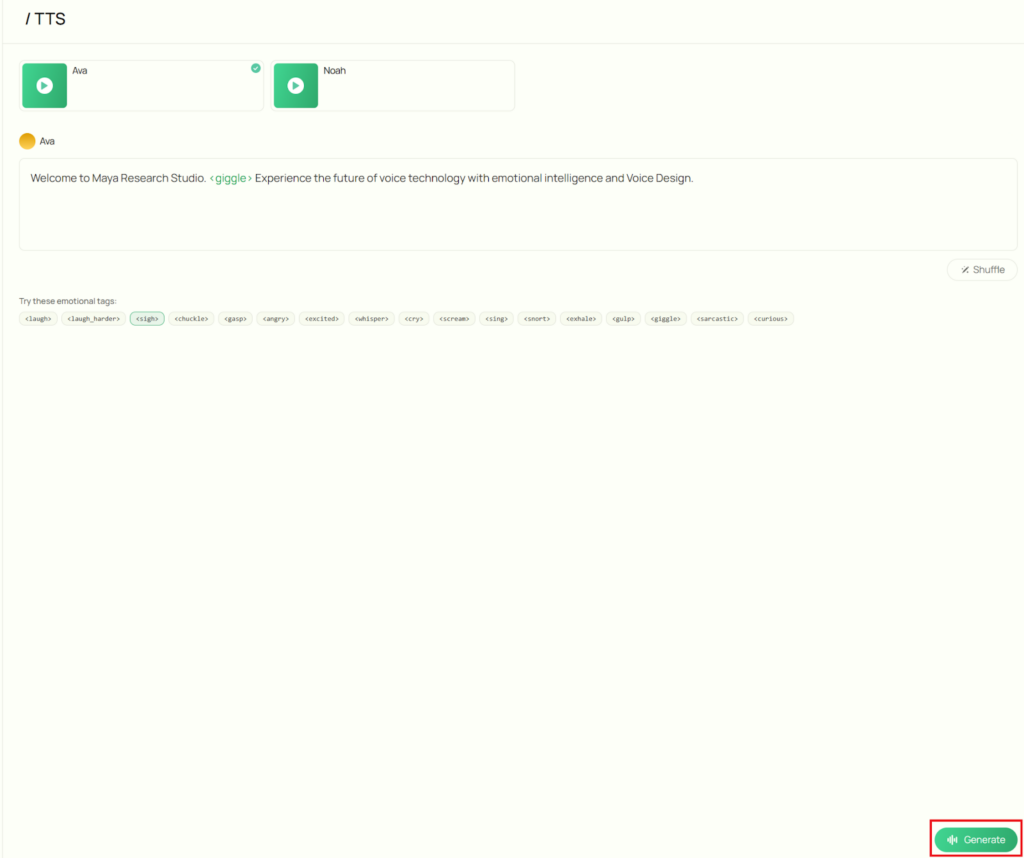
- 入力欄右下の「Shuffle」ボタンで、入力欄のテキストがランダムに変更されます。
- 画面右下の「Generate」ボタンで、音声生成が開始されます。
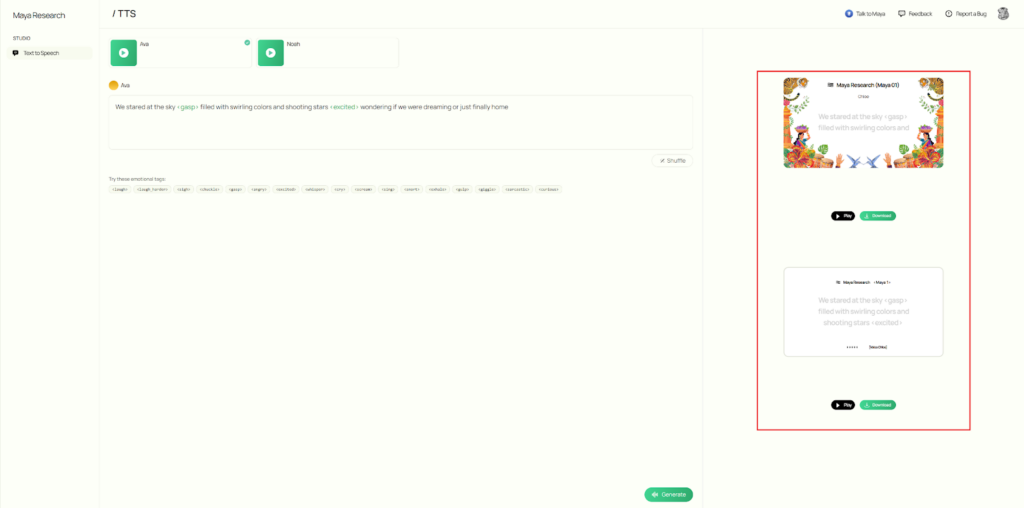
- 画面右側に生成された音声が表示され、その場で音声を再生したり、ファイルをダウンロードすることができます。
まとめ
Maya1は、自然言語による直感的な音声デザインと豊かな感情表現を実現した、オープンソース音声生成技術の画期的なプロジェクトです。商用利用可能なライセンスなので、開発者やクリエイターが自由にカスタマイズして利用することができます。
現在は英語のみの対応ですが、Hugging Faceコミュニティでは多言語対応やファインチューニングモデルの開発が進んでいるので、近い将来、日本語を利用して自由度の高い音声生成体験が可能となるかもしれません。
誰もが使える高品質なツールとして、音声AI技術の未来を加速させるでしょう。

最後に
いかがだったでしょうか?
高品質な感情音声AIを自社プロダクトへどう組み込み、コスト・ライセンス・運用リスクを抑えつつ差別化につなげるか。Maya1を前提に実装・活用戦略を具体化できます。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

