
【MedGemma 1.5】Googleの医療特化AIの性能や使い方を徹底解説!

- MedGemmaは、2025年に公開された医療特化型の生成AIモデルで、病院や研究機関の開発者が自由に活用・改変できる大規模言語モデル
- MedGemma 1.5では、CTやMRIなど高次元の医用画像データを扱う能力が飛躍的に強化
- 医療用音声認識モデル「MedASR」も同時公開され、音声入力からMedGemmaへの連携も可能
2026年1月14日、Googleが医療分野向けの最新AIモデル「MedGemma 1.5」を発表しました!
MedGemmaは、前年に公開されたオープンな医療特化型の生成AIモデルで、病院や研究機関の開発者が自由に活用・改変できる点が大きな特徴です。
医療業界におけるAI導入は、他業界の約2倍という驚異的なスピードで進んでおり、その流れを受けて登場したのがこのMedGemmaシリーズです。
今回リリースされたMedGemma 1.5では、CTやMRIなど高次元の医用画像データを扱う能力が飛躍的に強化されており、テキストや一般的な2D画像も含めたマルチモーダルな医療情報を総合的に解釈することができるようです。
さらに、医療用音声認識モデル「MedASR」も同時に公開され、音声入力からMedGemmaへの連携も可能になりました。
そこで本記事では、このMedGemma 1.5の概要、性能評価、使い方、そして実際に使ってみた所感まで詳しく解説していきます。
医療AIの最前線に興味がある方は、ぜひ最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
MedGemma 1.5の概要
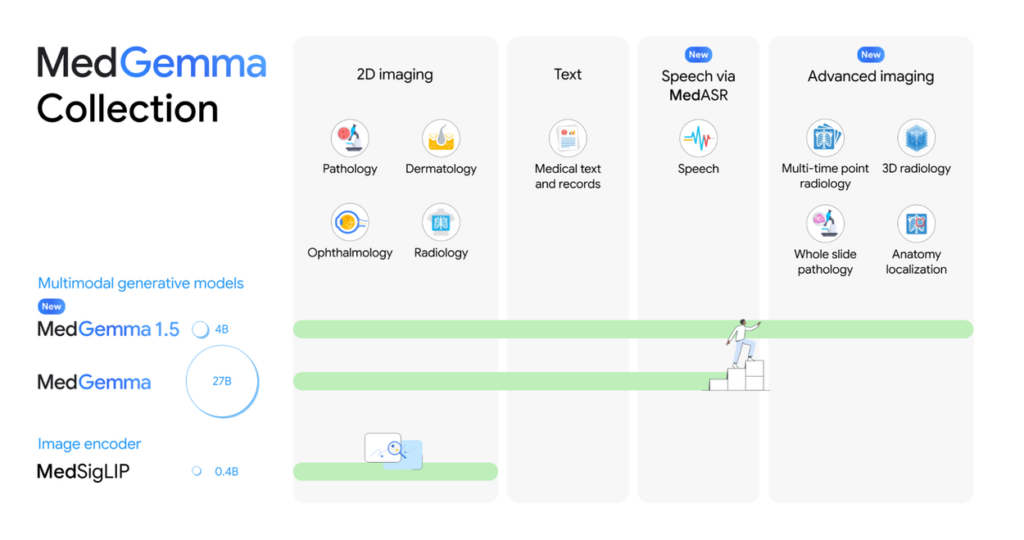
MedGemma 1.5は、Google ResearchのHealth AI Developer Foundations(HAI-DEF)プログラムから提供されるオープンモデルで、医療用に特化した大規模言語モデルです。
基本となるモデルアーキテクチャは、Googleの汎用LLMである「Gemma 3」をベースとしており、そこに医療分野のテキストデータと画像データでの追加訓練を施すことで、医療テキストの理解や医用画像の解析に高い性能を発揮するよう最適化されています。
例えば、研究段階のMedGemma 1シリーズでは、27億パラメータ版と4億パラメータ版が提供されていましたが、今回リリースされたMedGemma 1.5は、4億パラメータのマルチモーダル版のみがアップデートされています。
4B版はモデルサイズが小さく扱いやすいため、開発者がオフライン環境でも動作させやすいのがメリットですね。
また、MedGemma 1.5は以下のような機能強化が図られています。
| 機能 | 詳細 |
|---|---|
| 高次元(3次元)医用画像の解析 | ・複数断面からなるCTスキャンやMRIボリュームをまとめて入力し、病変の有無や特徴を判断可能 ・3Dデータを直接解釈できる公開LLMはMedGemma 1.5が初とされている |
| ホールスライド病理画像の解析 | ・病理組織スライド全体を複数のパッチ画像に分割して入力し、所見や診断内容を推論可能 |
| 長期比較が必要な画像解析 | ・時系列の胸部X線画像を入力し、過去画像と比較して病変が改善・悪化したかを評価可能(例:肺炎の陰影が拡大しているか) |
| 解剖学的部位の特定 | ・胸部X線画像上で臓器や病変の位置をバウンディングボックスで示す「位置特定」機能 |
| 医療文書の理解 | ・検査レポートや紹介状などの非構造化テキストから、項目名・数値・単位などの構造化データを抽出する機能 |
| 電子カルテ(EHR)解析 | ・患者の電子カルテから必要な情報を読み取り、質問に答える能力(入院記録の要約やQAなど) |
こうした新機能により、従来は扱えなかったCTやMRIなどの高度な画像データや、複数画像を用いる経時的な判断まで、MedGemma 1.5ひとつで包括的に対応できるようになっているそうです。


MedGemma 1.5の性能
MedGemma 1.5は、多岐にわたる医療タスクのベンチマーク評価結果が公開されています。
その結果によると、前バージョンのMedGemma 1(4B版)に比べて、あらゆる評価項目で性能向上が見られます。特に、前述の新機能に関連する医用画像解析タスクで向上していて、例えば、CTスキャン画像における疾患分類では正答率が58.2%→61.1%と約3ポイント向上し、MRI画像での異常所見検出では51.3%→64.7%と13.4ポイント(約26%相対向上)もの大幅な改善が達成されました。
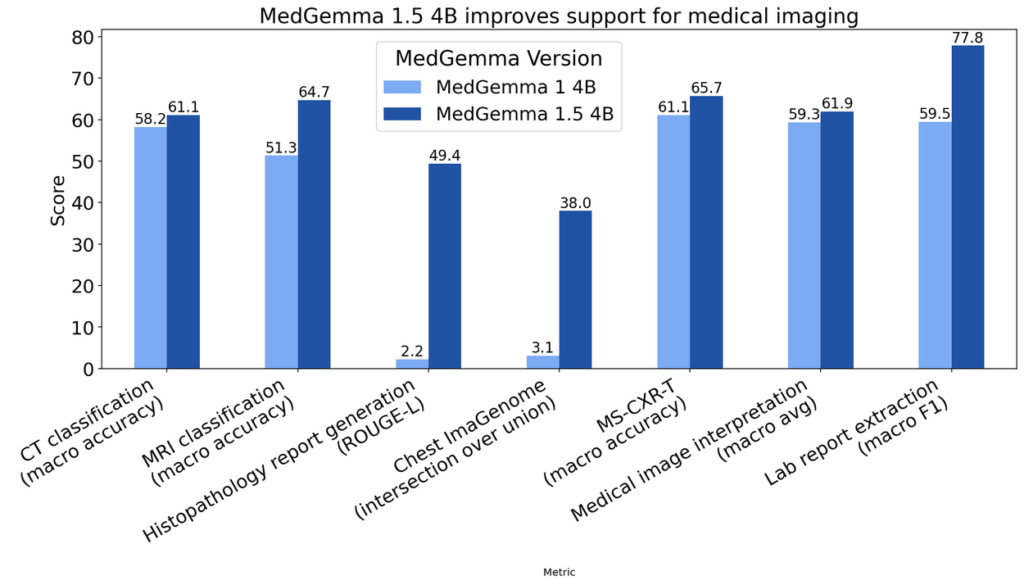
病理組織画像の診断に至っては、自由記述の所見文章と正解の類似度を測るROUGE-Lスコアが、0.02から0.49へと飛躍的に上昇し、病理画像専用モデルであるPolyPathのスコア(0.498)に匹敵するレベルに達しています。
この向上幅は驚異的で、MedGemma 1では事実上困難だった高度な病理画像の解釈を、1.5がある程度こなせるようになったことを示しています。
Gemmaシリーズ最新のGemma 4の特徴・性能を解説

MedGemma 1.5のライセンス
MedGemma 1.5は、Google独自の提供条件(HAI-DEF利用規約)に基づいて公開されています。
オープンソースソフトウェアのようにソースコードやモデル重みが公開されている点では「オープンモデル」ですが、ライセンス形態は、Apache-2.0やMITのような一般的なOSSライセンスではなく、Googleの定める利用規約に同意して利用するスタイルです。
| 利用用途 | 可否 | 備考 |
|---|---|---|
| 商用利用 | ⭕️ | 規約遵守の範囲で可能 |
| 改変 | ⭕️ | |
| 配布 | ⭕️ | 規約の付帯と通知が必要 |
| 特許使用 | ⭕️ | |
| 私的使用 | ⭕️ |


MedGemma 1.5の料金
MedGemma 1.5そのものの利用料金は無料です。
モデルデータおよび推論・学習ソフトウェアは無償で提供されており、ライセンス料やサブスクリプション費用といったものは一切ありません。Hugging Face上でモデルをダウンロードしたり、Google CloudのVertex AI経由で利用する場合でも、モデル使用自体に料金は発生しません。
MedGemma 1.5の使い方
MedGemma 1.5はオープンモデルのため、基本的には自分でモデルを動かす形で利用することになります。
ここでは代表的な利用方法として、Hugging Face経由でローカル環境で実行する方法を紹介します。
Hugging Face経由でローカル環境で実行
モデルへのアクセス許可
まず、Hugging Faceのサイトで無料アカウントを作成し、「google/medgemma-1.5-4b-it」のモデルページにアクセスします。
MedGemmaの利用規約(Health AI Developer Foundationsの規約)を確認し、「Acknowledge license」のボタンをクリックして同意します。
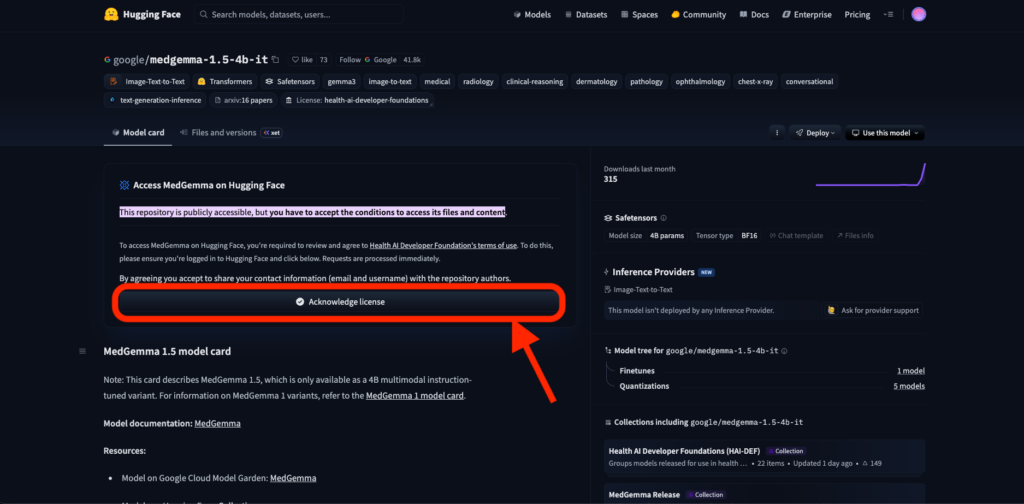
同意が完了すると、モデルのファイル一式(重みデータ約8GBなど)がダウンロード可能になります。
実行環境の準備
モデルを動かすには、Pythonベースの機械学習ライブラリ「Transformers」などが必要です。
公式には、Transformersライブラリのバージョン4.50.0以上でGemma 3ファミリーに対応しているとされるため、最新のTransformersをインストールします。
python -m venv .venv
source .venv/bin/activate
pip install -U "transformers>=4.51.3" accelerate torch pillow requests huggingface_hub
さらに、Hugging Faceへログインします。この際、アクセストークンが必要となりますので、Hugging Face Access Tokenページから新規作成しておきましょう。
huggingface-cli login
推論の実行
ログインが済んだら、推論はPythonで行います。例えば、run_medgemma.pyというファイルを作って、以下を保存します。
from transformers import pipeline
from PIL import Image
import requests
import torch
model_id = "google/medgemma-1.5-4b-it"
pipe = pipeline(
"image-text-to-text",
model=model_id,
torch_dtype=torch.bfloat16,
device="cuda",
)
image_url = "ここに画像URLを挿入してください"
image = Image.open(requests.get(image_url, headers={"User-Agent": "example"}, stream=True).raw)
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": image},
{"type": "text", "text": "Describe this X-ray"},
],
}
]
out = pipe(text=messages, max_new_tokens=512)
print(out[0]["generated_text"][-1]["content"])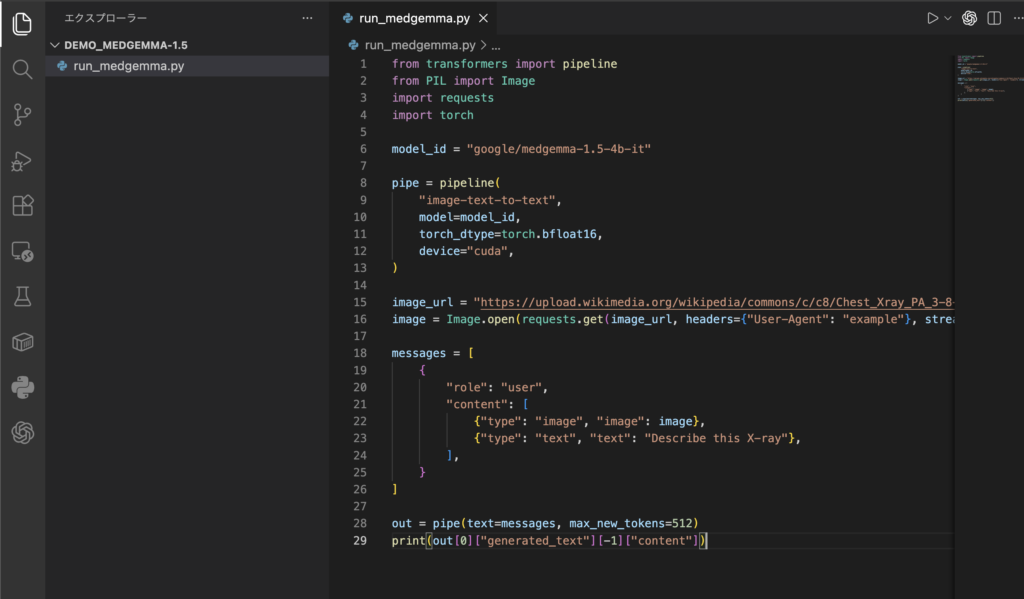
上記のコードによって、ユーザーからのメッセージとして1枚の画像と質問文がモデルに与えられます。以下コマンドで実行すると、モデルからの回答が得られます。
python run_medgemma.pyちなみに、Hugging FaceのTransformersではより簡易的にモデルを使う方法としてPipeline APIも提供されています。例えば、以下のように数行で推論を実行することも可能です。
from transformers import pipeline
pipe = pipeline("image-text-to-text", model="google/medgemma-1.5-4b-it")
result = pipe(image=image, text="Describe the image.")出力結果の確認
モデルから得られたテキスト回答が期待通りか確認します。
MedGemma 1.5は医療知識に基づく解説や所見の羅列を返してくれますが、そのまま診断確定とはせず参考意見として扱うようにしましょう。
必要に応じて、専門家が内容をチェックしたり、追加の質問を投げかけてモデルの回答の一貫性を確認したりすると良いと思います。
以上、Hugging Face経由での使い方のご紹介でした。
他にもGoogle Colabチュートリアルや、vLLMでの利用など様々ありますので、気になる方は、公式ドキュメントを参照してください。
MedGemma 1.5をGoogle Colabで使ってみた
それでは実際に、MedGemma 1.5をGoogle Colabで使ってみましょう。
今回は、「ある架空の患者の時系列の胸部X線画像から肺炎の経過を評価するタスク」を想定します。入力画像として、1枚目は入院時、2枚目は治療開始後のフォローアップX線画像という想定で、「肺炎は改善したか、それとも悪化しているか?」という質問をモデルに投げかけます。
なお、X線画像は、ChatGPT Imagesで架空のものを生成し、Hugging Face上に以下のようにアップロードしておりますので、こちらのURLを使用します。
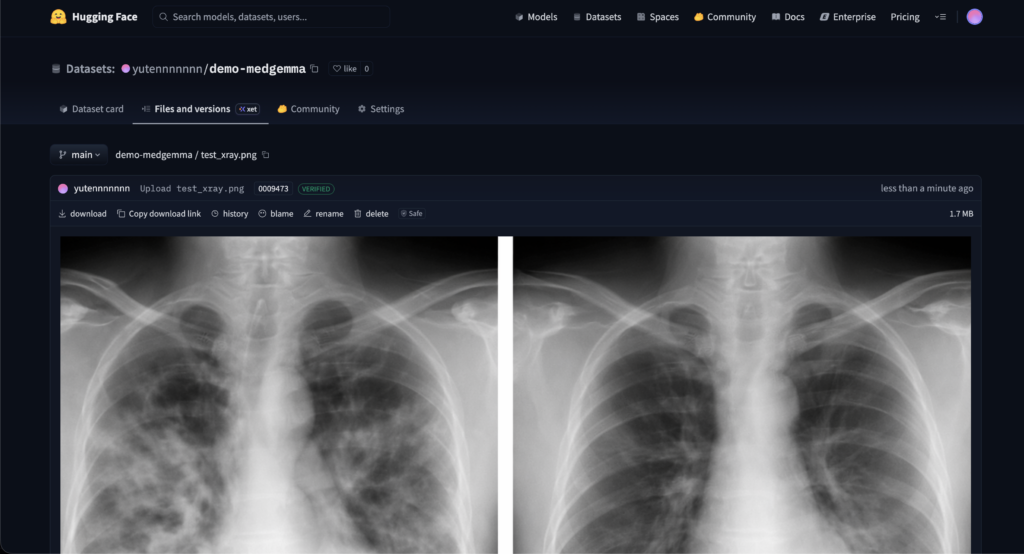
なお、Google Colab実行時、Hugging Faceへのログインが必要となりますので、事前にアクセストークンを発行しておきます。
それでは、推論実行します。
# Use a pipeline as a high-level helper
from transformers import pipeline
pipe = pipeline("image-text-to-text", model="google/medgemma-1.5-4b-it")
messages = [
{
"role": "user",
"content": [
{"type": "image", "url": "https://huggingface.co/datasets/yutennnnnnn/demo-medgemma/resolve/main/test_xray.png"},
{"type": "text", "text": "あなたは放射線科の読影補助AIです。次に示す胸部X線2枚は同一患者の時系列画像です。画像1=入院時(治療前)、画像2=治療開始後のフォローアップです。質問:肺炎は「改善」「悪化」「不変」「判断不能」のどれですか。最初に結論を1語で答え、その後に根拠を2〜4文で述べてください。"}
]
},
]
pipe(text=messages)
実行結果はこちら
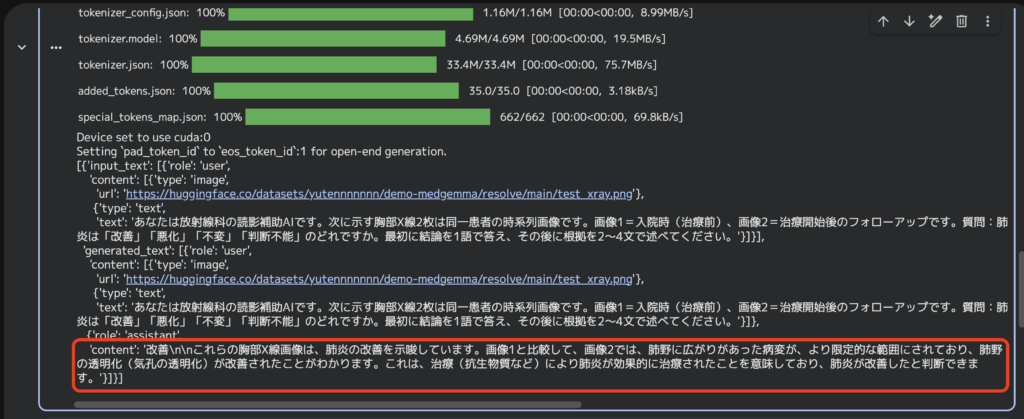
的確に2枚目の治療後で改善がみられているとの回答を得られました。
Google Colabチュートリアルをベースにすれば、あとは画像を準備するだけでかんたんに試すことができますので、気になった方はぜひ一度試してみてください。
なお、ChatGPT Imagesについて詳しく知りたい方は、以下の記事も参考にしてみてください。

まとめ
MedGemma 1.5は、医療分野に特化したオープンAIモデルとして画期的な存在です。CTやMRIの解析から専門的な問いへの回答までこなすその性能は、数年前では考えられなかった水準に達しています。
今後、MedGemmaがさらなる改良を重ねていけば、例えば、臓器ごとの専門モデルが登場したり、マルチモーダル推論の精度が専門医レベルに近づいたりするかもしれません。オープンモデルであるがゆえに、その進化のスピードはコミュニティの力も借りて加速していくと想定されます。
今後の精度向上に期待が高まります!

最後に
いかがだったでしょうか?
弊社では、AI導入を検討中の企業向けに、業務効率化や新しい価値創出を支援する情報提供・導入支援を行っています。最新のAIを活用し、効率的な業務改善や高度な分析が可能です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

