
Open Responsesとは?LLM開発をベンダーロックインから解放する共通API仕様を解説
- ベンダー非依存の共通API仕様により複数LLMを同一設計で扱える
- ストリーミングとツール連携を前提にしたイベント指向設計
- 将来のモデル変更や拡張に耐える長期運用向け基盤としての位置付け
2026年1月、OpenAIから新たなエコシステムが公開されました!
今回公開された「Open Responses」はこれまでバラバラだったLLMのAPIフォーマットを統一するシステムです。このおかげでそれぞれのSDKに依存することなくLLMを利用できます。
本記事ではOpen Responsesの概要から仕組み、実際の使い方について解説をします。本記事を最後までお読みいただければOpen Responsesの理解が深まります。
ぜひ最後までお読みください!
\生成AIを活用して業務プロセスを自動化/
Open Responsesの概要
Open Responsesは、大規模言語モデル向けAPIを「複数プロバイダーで共通に扱える形」にするための、オープンな仕様とエコシステム。
OpenAIの/v1/responses APIをベースに、特定ベンダーに依存しない形での相互運用を目指す取り組みになります。
Open Responsesが公開された理由として、LLM APIが「メッセージ」「ツール呼び出し」「ストリーミング」「マルチモーダル入力」といった共通要素へ収束しつつも、各社で表現やデータ形状がズレているためです。
Open Responsesは入力と出力を共有スキーマにし、ストリーミング結果やエージェント的なワークフローも、プロバイダー差を気にせずに組み立てやすくする設計です。こうした共通化により、同じ設計思想のまま、異なるモデル提供元へ移行しやすくなります。

Open Responsesの仕組み
ここでは、Open Responsesがどのような仕組みで構築されているのかを解説します。ポイントは「入力の統一」「出力の分解」「ストリーミングとツール実行を前提にした設計」の3つです。
入力から出力までの基本構造
Open Responsesでは、単純なテキスト生成だけでなく、会話、ツール呼び出し、マルチモーダル入力を同一のresponse単位で扱います。
入力は「instructions」「input」「tools」などの要素に分解され、モデルに渡されます。これにより、従来のチャット形式同じインターフェースで呼び出せる構成になっています。
出力も1つのテキストとして返すのではなく、複数のイベントやコンテンツブロックに分解。
例えば、モデルが生成したテキスト、ツール実行の指示、ツール実行結果の反映といった流れが、時系列で出力されます。そのため、開発者は「どの段階で何が起きたのか」を明らかにすることができます。
ストリーミングとイベント指向の設計
Open Responsesは、ストリーミングを前提としたイベント指向モデルを採用。下記の図は、ユーザーからのリクエストをもとに、APIサーバーがLLMとツールを行き来しながら処理を進めるエージェント的な実行フローを示しています。
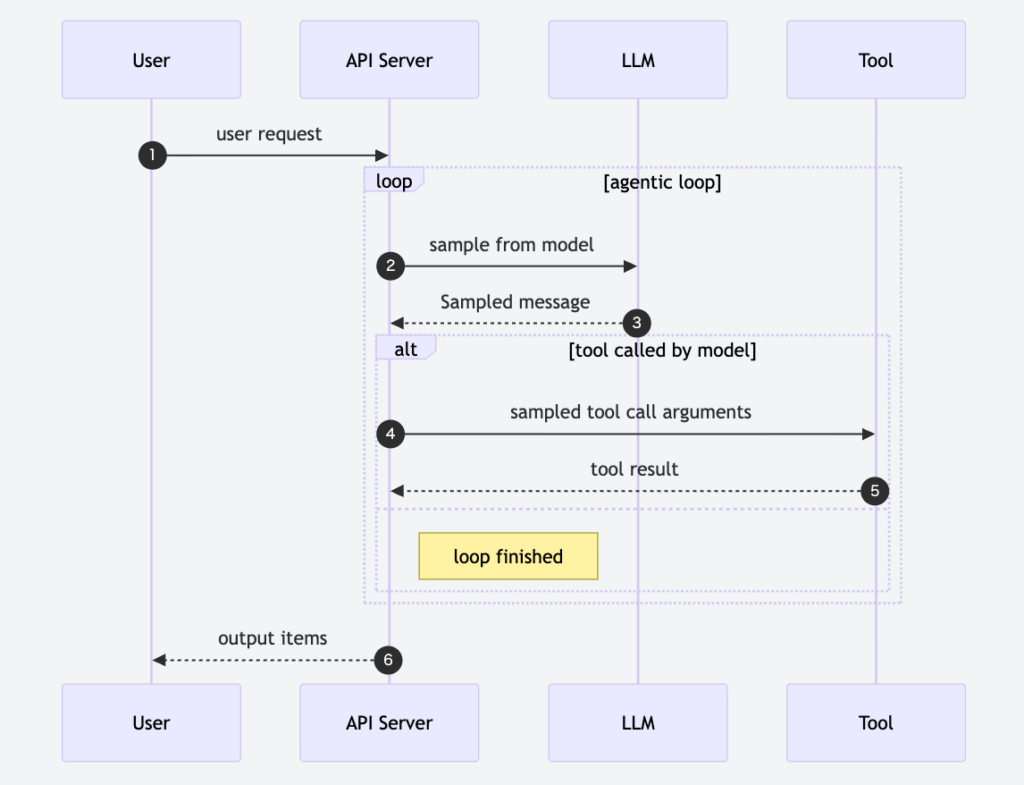
生成途中のトークンやツール呼び出し指示が逐次イベントとして送られ、クライアント側で順に処理されます。この方式により、UIへの即時反映やリアルタイム処理が実装しやすくなっています。
また、イベントは型付きで定義されており、「生成中」「ツール要求」「完了」といった状態を区別。単にレスポンスを受け取るだけでなく、処理フロー全体を制御できる点が重要です。
ベンダー非依存を意識した抽象レイヤー
Open Responsesの仕組みで特徴的なのは、特定モデルや提供元の内部仕様をAPIレベルに持ち込まない点です。
リクエストやレスポンスの形式は共通で定義され、どのモデルバックエンドを使うかは実装側に委ねられています。そのため、同じコード構造のまま、異なるLLMプロバイダーへ切り替えられる設計になっています。


Open Responsesの特徴
ここでは、Open Responsesの主な特徴を解説します。特徴としては「相互運用性」「拡張性」「実装のしやすさ」です。
共通スキーマによる高い相互運用性
Open Responsesの最大の特徴は、入力と出力を共通スキーマで定義している点。
テキスト生成、会話、ツール呼び出しといった用途が同一の枠組みになっています。これにより、特定プロバイダー固有のレスポンス形式に依存せず、アプリケーション側の実装を共通化できます。
これにより、モデルや提供元の切り替えに伴う修正コストを抑えやすくなります。
API設計を固定したままバックエンドを差し替えられる点は、長期運用を前提とするプロダクトでは大きなメリットと言えるでしょう。
イベント指向・ストリーミング前提の設計
Open Responsesは、レスポンスを1回で返す従来型APIとは異なり、イベントの集合として扱います。
生成中のトークン、ツール呼び出し要求、完了通知といった状態を分離して定義。この構造により、リアルタイムUIや逐次処理との相性が高くなっています。
特にストリーミングは待ち時間の短縮や途中結果の活用がしやすくなり、ユーザー体験の改善につながる可能性があります。
ツール実行を含む統一的なワークフロー
Open Responsesでは、モデルの生成結果とツール実行を同じレスポンス文脈で扱えます。
モデルが「どのツールを、どの引数で呼ぶべきか」を出力し、その結果を再びモデル入力へ戻します。これにより、複雑なオーケストレーションを外部で組み立てる手間が減ります。
Open Responsesでは、ツール実行をAPIの例外的処理としてではなく、標準的なイベントとして位置付けている点が特徴的です。
なお、OpenAIのワークフロー構築AIエージェントであるAgentKitについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
Open Responsesの安全性
ここでは、Open Responsesを利用する際に押さえておきたい安全性の考え方と仕様上の制約について解説します。
セキュリティとデータ取り扱いの前提
Open ResponsesはAPI仕様とスキーマを定義する取り組みであり、データ保存や暗号化といった実装レベルのセキュリティは各プロバイダーに委ねられています。
仕様自体が「入力データをどう保存するか」「どの期間保持するか」を規定しているわけではありません。そのため、実際の運用では、利用するモデル提供元やホスティング環境のポリシー確認が必須になります。
一方で、入出力の構造が明確に定義されている点は、セキュリティ設計の観点でメリットと言えます。どのデータがモデルに渡り、どのイベントがクライアントへ返るのかが明示的になるため、ログ管理やマスキング処理を組み込みやすいです。
モデル依存となる安全対策の限界
Open Responsesはベンダー非依存を前提としているため、出力内容の安全性やフィルタリングはモデル側に委ねられています。
有害表現の抑制やコンテンツポリシーの適用が、仕様として一律に定義されているわけではありません。この点は、利用者側が特に注意すべき制約でしょう。
仕様準拠と実装差異に関する注意点
Open Responsesは共通仕様を定めていますが、全ての実装が完全に同一挙動になることを保証しているわけではありません。
特にストリーミングイベントの粒度や順序、ツール呼び出しの扱いは、実装ごとの差が生じる可能性があります。このため、厳密な動作に依存するロジックは注意が必要です。
Open Responsesの料金
Open Responsesの仕様そのものに対する利用料金は設定されていません。Open ResponsesはAPIやスキーマの共通仕様を定義する取り組みであり、商用サービスとして課金するプロダクトではないためです。


Open Responsesのライセンス
Open ResponsesはApache 2.0ライセンスで公開されていて、商用利用・改変・再配布・特許利用・私的利用のすべてが許可されています。Apache 2.0ライセンスはオープンな条件で利用を認められているライセンスです
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
Apache 2.0ライセンスのもと、商用利用を含めて幅広い用途で利用できますが、生成物の内容や利用方法については利用者側が責任を負う点に注意が必要です。
まず、違法・有害なコンテンツの生成や法令に反する利用は認められていません。また、既存IPや実在人物を用いた生成物を商用利用する場合は、権利者のガイドラインや肖像権・プライバシーへの配慮が不可欠です。
なお、OpenAIの次世代ヘルスケアであるChatGPT Healthについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Open Responsesの実装方法
そしたら実際にOpen Responsesを使っていきます。
google colaboratoryで実装をしていきますが、ローカル環境でも実行可能です。
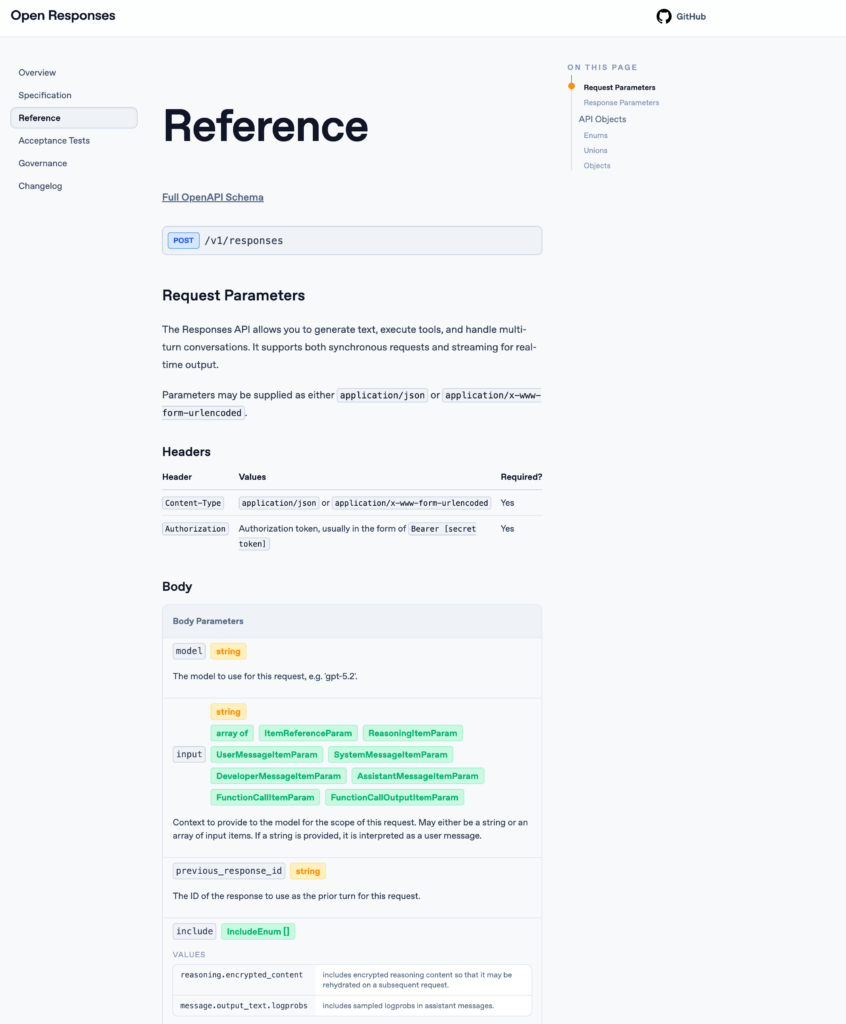
まずは必要ライブラリのインストール。
!pip install requests環境変数にAPIキーを設定する場合には設定をしていただき、下記を実行すればOKです。
サンプルコードはこちら
import os
import requests
API_URL = "https://api.openai.com/v1/responses"
API_KEY = ''
def get_answer_text(resp: dict) -> str:
texts = []
for item in resp.get("output", []):
if item.get("type") != "message":
continue
for content in item.get("content", []):
if content.get("type") == "output_text":
texts.append(content.get("text", ""))
return "\n".join(texts)
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json",
}
payload = {
"model": "gpt-4.1-mini-2025-04-14",
"input": "Open Responsesとは何ですか",
"text": {"format": {"type": "text"}},
}
res = requests.post(API_URL, headers=headers, json=payload)
res.raise_for_status()
data = res.json()
print(get_answer_text(data))結果はこちら
「Open Responses(オープンレスポンス)」とは、一般的に教育や調査、評価の文脈で使われる用語で、「自由回答」や「自由記述形式の回答」を指します。つまり、回答者があらかじめ用意された選択肢から選ぶのではなく、自分の言葉で自由に答える形式のことです。
例えば:
- **学校のテストやアンケート**で、「あなたの意見を自由に書いてください」という問いがあった場合、それはOpen Responsesです。
- **調査やフィードバック**においても、選択肢で答える代わりに自由記述で詳細な意見を述べる場面があります。
Open Responsesの特徴は、回答者の考えや感情、詳しい説明が得られる点にあり、単純な選択肢回答よりも深い洞察が期待できます。ただし、集計や分析に手間がかかるというデメリットもあります。
もし特定の文脈(例えばあるシステム名やサービス名など)での「Open Responses」についての説明が必要でしたら、その詳細を教えてください。
ただ、これだけだとOpen Responsesの良さがいまいち実感できないですね。記事後半のOpen Responsesを実際に使ってみたでも試してみます。
Open Responsesの活用事例
ここでは、Open Responsesの仕組みや特徴を踏まえて活用事例を考えてみます。
マルチLLM対応アプリケーション基盤
Open Responsesは、複数のLLMプロバイダーを横断して扱える点が大きな特徴です。
このため、用途やコスト条件に応じてバックエンドモデルを変更したり、1つのアプリケーションで複数モデルを切り替える設計に向いています。
特定ベンダーのAPI仕様に縛られないため、モデルの性能比較や段階的な移行を行いやすくなります。
エージェント型ワークフローの実装
イベント指向かつツール連携を前提とした設計は、エージェント型処理との相性が良いです。
モデルが状況に応じてツールを呼び出し、その結果を受けて次の判断を行う流れを、単一のレスポンス文脈で構築できます。検索や計算、外部システム連携を組み合わせた業務自動化では、Open Responsesの構造が活きると考えられます。制御フローが明示的なイベントとして扱えるため、デバッグや拡張もしやすいでしょう。
リアルタイムUI・対話システム
ストリーミング前提のAPI設計は、リアルタイム性が求められるUIで特に活用しやすいでしょう。
生成途中のテキストを即座に表示したり、ツール実行中の状態をユーザーへ通知したりといったUI/UXを実装しやすくなります。チャットボットや対話型アシスタントだけでなく、IDE連携ツールやカスタマーサポート支援など、即時応答が重視される分野でも活用が考えられます。
Open Responsesを実際に使ってみた
もう少しOpen Responsesを使ってみたいと思います。
まずは非ストリーミングでOpenAIとAnthropicを切り替えて使ってみます。
サンプルコードはこちら
import os
import json
import requests
from typing import Dict, Generator, Optional
from google.colab import userdata
# provider: "openai" or "anthropic"
PROVIDER = os.environ.get("PROVIDER", "openai").lower()
OPENAI_API_KEY = userdata.get("OPENAI_API_KEY")
ANTHROPIC_API_KEY = userdata.get("ANTHROPIC_API_KEY")
# OpenAI
OPENAI_URL = "https://api.openai.com/v1/responses"
OPENAI_MODEL = os.environ.get("OPENAI_MODEL", "gpt-4.1-mini-2025-04-14")
# Anthropic (Claude)
ANTHROPIC_URL = "https://api.anthropic.com/v1/messages"
ANTHROPIC_MODEL = os.environ.get("ANTHROPIC_MODEL", "claude-sonnet-4-5-20250929")
ANTHROPIC_VERSION = os.environ.get("ANTHROPIC_VERSION", "2023-06-01")
PROMPT = os.environ.get(
"PROMPT",
"『箇条書き3つで』Open Responsesのメリットを、プロダクト開発目線で説明して"
)
def render_events(events: Generator[Dict, None, None]) -> str:
out = []
for ev in events:
t = ev.get("type")
if t == "text_delta":
chunk = ev.get("text", "")
print(chunk, end="", flush=True)
out.append(chunk)
elif t == "done":
print() # 改行
break
return "".join(out)
def openai_events(prompt: str) -> Generator[Dict, None, None]:
if not OPENAI_API_KEY:
raise RuntimeError("OPENAI_API_KEY が未設定です")
headers = {
"Authorization": f"Bearer {OPENAI_API_KEY}",
"Content-Type": "application/json",
}
payload = {
"model": OPENAI_MODEL,
"input": prompt,
"text": {"format": {"type": "text"}},
}
r = requests.post(OPENAI_URL, headers=headers, json=payload)
r.raise_for_status()
data = r.json()
texts = []
for item in data.get("output", []):
if item.get("type") != "message":
continue
for c in item.get("content", []):
if c.get("type") == "output_text":
texts.append(c.get("text", ""))
full = "\n".join([t for t in texts if t])
if full:
yield {"type": "text_delta", "text": full}
yield {"type": "done"}
def anthropic_events(prompt: str) -> Generator[Dict, None, None]:
if not ANTHROPIC_API_KEY:
raise RuntimeError("ANTHROPIC_API_KEY が未設定です(Claude切替には必要)")
headers = {
"x-api-key": ANTHROPIC_API_KEY,
"anthropic-version": ANTHROPIC_VERSION,
"content-type": "application/json",
}
payload = {
"model": ANTHROPIC_MODEL,
"max_tokens": 500,
"messages": [{"role": "user", "content": prompt}],
}
r = requests.post(ANTHROPIC_URL, headers=headers, json=payload)
r.raise_for_status()
data = r.json()
texts = []
for c in data.get("content", []):
if c.get("type") == "text":
texts.append(c.get("text", ""))
full = "\n".join([t for t in texts if t])
if full:
yield {"type": "text_delta", "text": full}
yield {"type": "done"}
def get_events(provider: str, prompt: str) -> Generator[Dict, None, None]:
if provider == "anthropic":
return anthropic_events(prompt)
return openai_events(prompt)
print(f"=== provider: {PROVIDER} ===")
print(f"=== prompt: {PROMPT} ===\n")
events = get_events(PROVIDER, PROMPT)
final_text = render_events(events)
print("\n---\n[final_text]\n")
print(final_text)実際に動いてる様子がこちら。
続いてストリーミングをオンにします。
サンプルコードはこちら
import os
import json
import requests
from typing import Dict, Generator, Optional
from google.colab import userdata
# provider: "openai" or "anthropic"
PROVIDER = os.environ.get("PROVIDER", "anthropic").lower()
OPENAI_API_KEY = userdata.get("OPENAI_API_KEY")
ANTHROPIC_API_KEY = userdata.get("ANTHROPIC_API_KEY")
# OpenAI
OPENAI_URL = "https://api.openai.com/v1/responses"
OPENAI_MODEL = os.environ.get("OPENAI_MODEL", "gpt-4.1-mini-2025-04-14")
# Anthropic (Claude)
ANTHROPIC_URL = "https://api.anthropic.com/v1/messages"
ANTHROPIC_MODEL = os.environ.get("ANTHROPIC_MODEL", "claude-sonnet-4-5-20250929")
ANTHROPIC_VERSION = os.environ.get("ANTHROPIC_VERSION", "2023-06-01")
PROMPT = os.environ.get(
"PROMPT",
"『箇条書き3つで』Open Responsesのメリットを、プロダクト開発目線で説明して"
)
def render_events(events: Generator[Dict, None, None]) -> str:
out = []
for ev in events:
t = ev.get("type")
if t == "text_delta":
chunk = ev.get("text", "")
print(chunk, end="", flush=True)
out.append(chunk)
elif t == "done":
print() # 改行
break
return "".join(out)
def openai_events(prompt: str) -> Generator[Dict, None, None]:
if not OPENAI_API_KEY:
raise RuntimeError("OPENAI_API_KEY が未設定です")
headers = {
"Authorization": f"Bearer {OPENAI_API_KEY}",
"Content-Type": "application/json",
}
payload = {
"model": OPENAI_MODEL,
"input": prompt,
"stream": True,
"text": {"format": {"type": "text"}},
}
with requests.post(OPENAI_URL, headers=headers, json=payload, stream=True) as r:
r.raise_for_status()
for line in r.iter_lines(decode_unicode=True):
if not line:
continue
if line.startswith("data:"):
data = line[len("data:"):].strip()
if not data:
continue
ev = json.loads(data)
if ev.get("type") == "response.output_text.delta":
yield {"type": "text_delta", "text": ev.get("delta", "")}
elif ev.get("type") in ("response.completed", "response.incomplete", "response.failed"):
break
yield {"type": "done"}
def anthropic_events(prompt: str) -> Generator[Dict, None, None]:
if not ANTHROPIC_API_KEY:
raise RuntimeError("ANTHROPIC_API_KEY が未設定です(Claude切替には必要)")
headers = {
"x-api-key": ANTHROPIC_API_KEY,
"anthropic-version": ANTHROPIC_VERSION,
"content-type": "application/json",
}
payload = {
"model": ANTHROPIC_MODEL,
"max_tokens": 500,
"stream": True,
"messages": [{"role": "user", "content": prompt}],
}
with requests.post(ANTHROPIC_URL, headers=headers, json=payload, stream=True) as r:
r.raise_for_status()
for line in r.iter_lines(decode_unicode=True):
if not line:
continue
if line.startswith("data:"):
data = line[len("data:"):].strip()
if not data:
continue
ev = json.loads(data)
if ev.get("type") == "content_block_delta":
delta = ev.get("delta", {})
if delta.get("type") == "text_delta":
yield {"type": "text_delta", "text": delta.get("text", "")}
elif ev.get("type") == "message_stop":
break
yield {"type": "done"}
def get_events(provider: str, prompt: str) -> Generator[Dict, None, None]:
if provider == "anthropic":
return anthropic_events(prompt)
return openai_events(prompt)
print(f"=== provider: {PROVIDER} ===")
print(f"=== prompt: {PROMPT} ===\n")
events = get_events(PROVIDER, PROMPT)
final_text = render_events(events)
print("\n---\n[final_text]\n")
print(final_text)実際に動いている様子がこちら。
正直、これだけだとOpen Responsesがどういう面で便利なのかが分かりにくいかもしれません。Open Responsesの便利さを実感するのは、より複雑な開発を行っているときだと考えられます。
これまでのLLM連携は出力されたテキストをもとに制御していましたが、Open Responsesはtype付きオブジェクトの列として定義されているので、文章での制御ではなく、状態での制御といえます。
そのためテキストで制御できてしまうレベルのコーディングではOpen Responsesの便利さを実感しにくいかもしれません。
なお、SWEベンチで新記録を樹立したGPT-5.2について詳しく知りたい方は、下記の記事を合わせてご確認ください。
まとめ
本記事ではOpen Responsesの概要から仕組み、実際の使い方について解説をしました。
Open ResponsesはLLMプロバイダーごとのAPIフォーマットを統一するものです。
また、これまでのLLMとは違い、状態で制御を行う特徴があることから、複雑なコーディングや開発メンバーが増えた場合などに効果を発揮すると考えられます。
ぜひ皆さんも本記事を参考にOpen Responsesを使ってみてください!

最後に
いかがだったでしょうか?
Open Responsesのような新しい仕様は、すぐに便利さを実感できるものではありませんが、中長期的にAI活用を拡張していく企業にとっては、設計段階での判断が大きな差になります。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

