
Z-Imageとは?単流Diffusion Transformerで実現する高速・高効率な画像生成モデルを解説

- Z-Imageは6Bパラメータで効率と品質を両立した画像生成モデル
- 単流Diffusion Transformerによる高速推論と低VRAM対応
- 研究用途から実務活用まで視野に入る拡張性の高い設計
2026年1月、Alibabaから新たな画像生成モデルが公開されました。
今回リリースされた「Z-Image」は、単流Diffusion Transformerという新しい設計を採用。6Bパラメータという比較的コンパクトな規模でありながら、高い生成品質と計算効率を両立することを目指したモデルです。
一方で、新たに発表される画像生成AIは、「従来の拡散モデルと何が違うのか」「なぜ単流構成が重要なのか」「実務やプロダクト開発でどう活用できるのか」が分かりにくいケースも少なくありません。
そこで本記事では、Z-Imageの概要や仕組み、活用事例について解説します。本記事を最後までお読みいただければ、Z-Imageがどのような画像生成モデルなのか、そしてどのような場面で活用できるのかが理解できるはずです。
ぜひ最後までお読みください。
\生成AIを活用して業務プロセスを自動化/
Z-Imageの概要
テキストから画像を生成するモデルは高性能化が進む一方で、巨大なパラメータ数によって推論や微調整のハードルが上がっています。
Z-Imageは、そうした「大規模化ありき」の流れに対して、6Bパラメータの効率設計で勝負する画像生成の基盤モデルとして開発されました。
Z-ImageはAlibabaがリリースしており、Diffusion TransformerをベースにしたS3-DiTが土台になっています。学習パイプライン全体を最適化し、総学習コストを314K H800 GPU hours(USD換算で約$628K)に抑えています。

また、用途に合わせてモデルがいくつか用意されています。
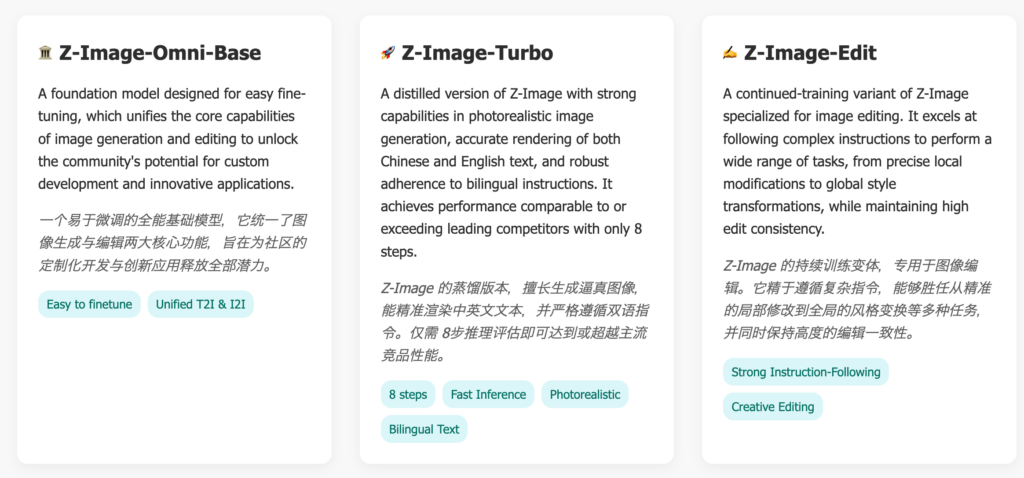
Z-Imageシリーズについて
Z-Imageは用途に応じて3つのモデルが提供されており、それぞれ異なる特徴を持っています。
Z-Image-Omni-Base
ファインチューニングを前提とした基盤モデル。
画像生成と編集の機能を有しており、カスタム開発やアプリケーション構築に向けた設計になっています。Text-to-ImageとImage-to-Imageの両方に対応し、柔軟な拡張が可能です。
Z-Image-Turbo
高速推論に特化した蒸留版モデルで、2025年11月にリリースされています。
フォトリアリスティックな画像生成、中国語・英語テキストの正確なレンダリング、バイリンガル指示への高い追従性を備えています。
わずか8ステップの推論で主要な競合モデルと同等以上の性能を実現しており、高速性が求められる用途に適しています。
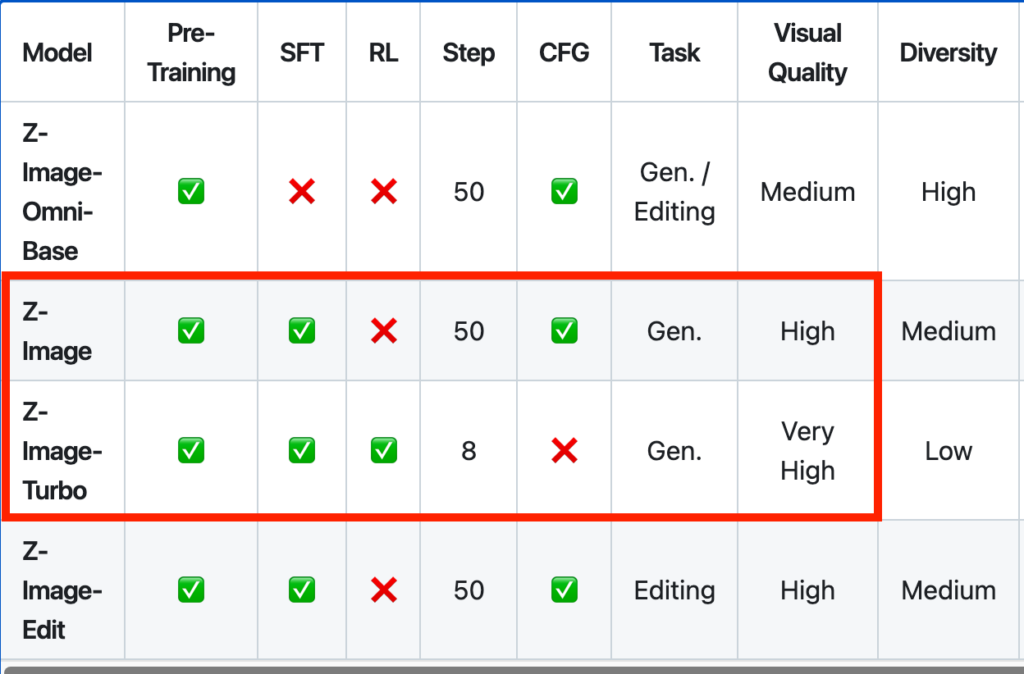
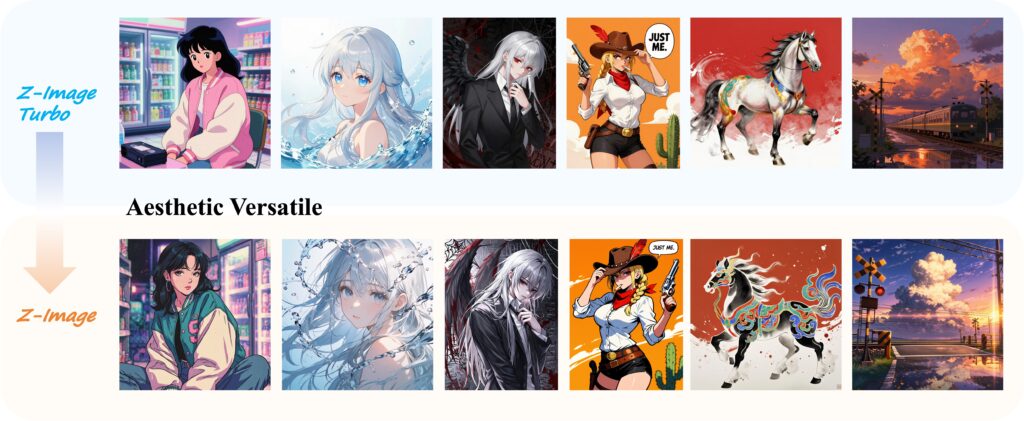
なお、GitHub掲載の比較表では品質がZ-ImageよりもZ-Image-Turboの方が高いと書かれていますが、実際に比較してみるとZ-ImageもZ-Image-Turboも遜色ないように思います。
Z-Image-Edit
画像編集に特化して継続学習されたモデルです。
複雑な指示に従い、局所的な細かい修正からスタイル変換まで幅広い編集タスクを実行できます。高い編集性を維持しながら、指示追従性に優れています。


Z-Image-Turboとの違い
ここでは、今回公開されたZ-Imageと先行して登場していたZ-Image-Turboの違いを解説します。
Z-Imageは、画像生成全般を支える基盤モデルです。
単流Diffusion Transformer(S3-DiT)をベースに、生成・編集・高速化といった下流タスクへ展開する前提の構成です。そのため、汎用性や拡張性を重視した設計になっており、用途に応じた最適化や派生モデルの開発が想定されています。
一方でZ-Image-Turboは、Z-Imageをベースに高速推論へ特化した派生モデルです。
蒸留技術と強化学習を組み合わせることで、推論ステップを8回まで削減し、リアルタイム性を最優先に設計。

品質の最大値よりも、安定した速度と実運用での使いやすさを重視しています。
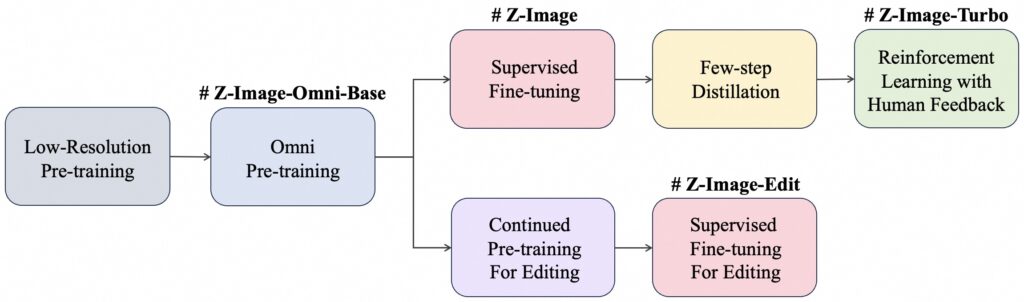
Z-Imageの仕組み
ここでは、Z-Imageがどのような技術構成で画像生成を行っているのか、その仕組みを解説します。ポイントは「単流(single-stream)」という設計であり、従来の拡散モデルとは異なるアプローチが採られています。
S3-DiTによる単流設計
Z-Imageの基盤は、S3-DiTと呼ばれるScalable Single-Stream Diffusion Transformerです。
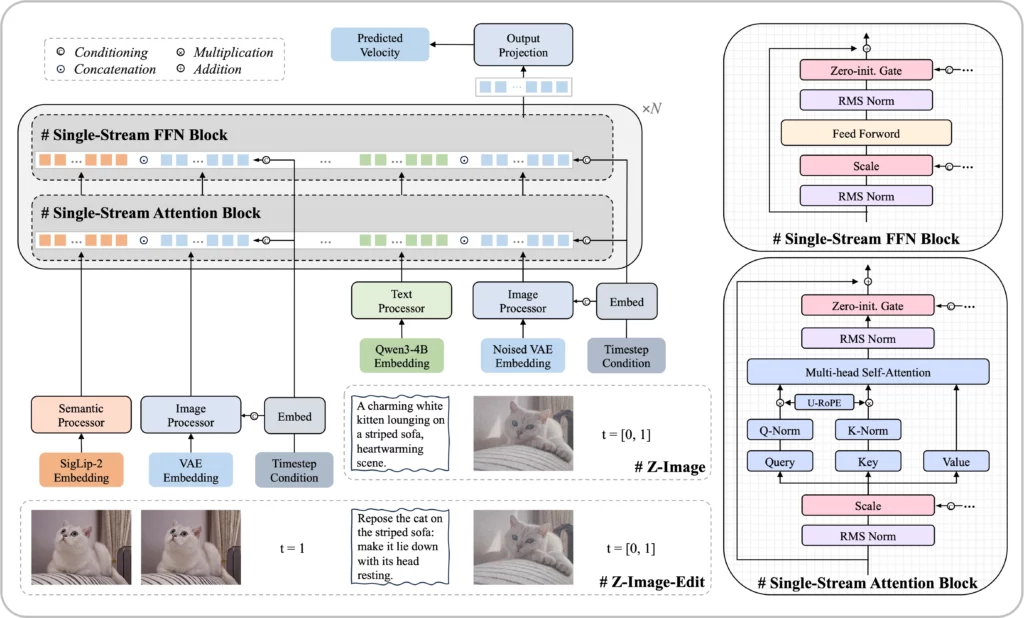
一般的な拡散型Transformerでは、テキスト条件と画像表現を別系統で処理する構成が多かったです。
これに対してZ-Imageでは、テキストと画像トークンを単一ストリームに統合し、同一のTransformerブロックで処理します。
画像生成の処理フロー
処理の流れとしては、まず入力テキストがトークン化され、ノイズが付加された画像トークンと併せてTransformerに投入されます。
モデル内部では、拡散ステップごとにノイズ除去を行いながら、テキスト条件に整合した画像表現へと更新されていく仕組みです。
最終的にノイズが十分に除去された段階で、高解像度の画像が出力される流れとなっています。
なお、生成画像っぽさを抑え、日本語描画も試せるQwen-Image-2512について詳しく知りたい方は、下記の記事を合わせてご確認ください。

Z-Imageの特徴
ここでは、Z-Imageの主な特徴を整理し、他の画像生成モデルとの違いについて解説します。
単流アーキテクチャによる高い計算効率
Z-Imageの最大の特徴は、テキストと画像を単一ストリームで処理するS3-DiTを採用している点。従来のように複数の処理経路を持たないため、モデル構造がシンプルになっています。
その結果、同規模クラスのモデルと比べて計算効率が高い構成になっています。
6Bパラメータでも競争力のある生成品質
Z-Imageは約6Bパラメータという比較的コンパクトなサイズで設計されています。一方で、公開ベンチマークでは同クラスのオープンモデルに対してランキング上位に組み込む性能を発揮。
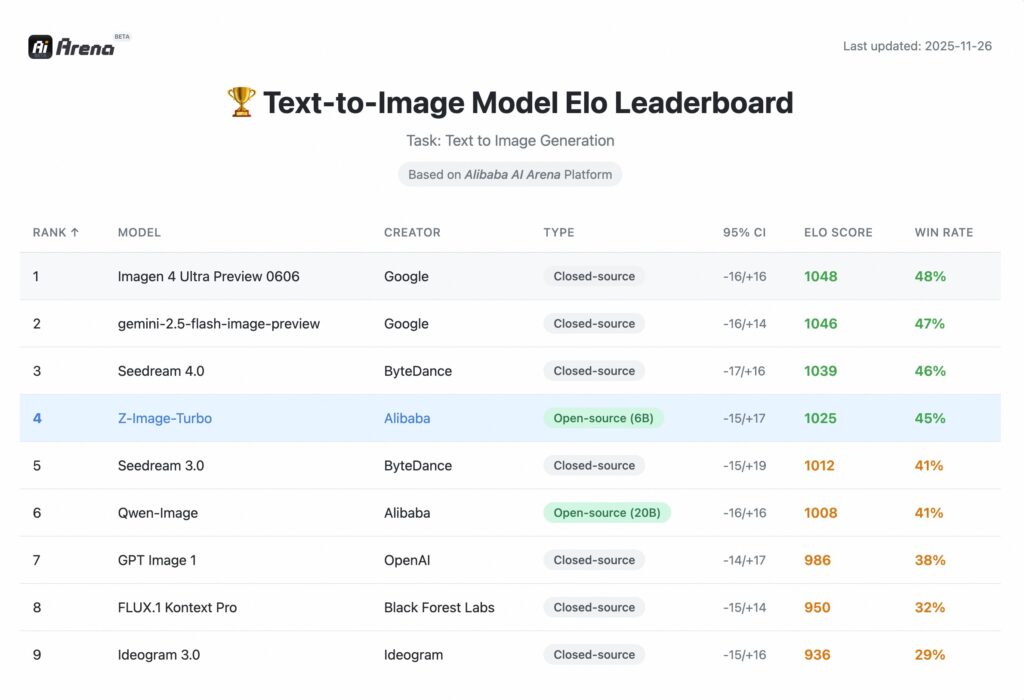
特に、視覚的な整合性やテキスト指示への追従性が評価対象になっています。
編集タスクまで視野に入れたモデル展開
Z-Imageファミリーには、指示に基づく画像編集を目的としたZ-Image-Editも含まれています。生成専用にとどまらず、編集タスクへ拡張している点が特徴です。
テキスト指示による部分修正や内容変更を想定した構成が示されています。生成と編集を同一系列で扱える点は、実運用での柔軟性につながります。

Z-Imageの安全性・制約
ここでは、Z-Imageを利用する上で把握しておきたい安全性の考え方と制約について解説します。
まず安全性に関してですが、データ保存方針やプライバシー保護の詳細な運用ルールは公式には明らかにされていません。
制約については、Z-ImageおよびZ-Image-Turboが汎用的な画像生成モデルであることが前提になっています。
医療画像や法的判断を伴う用途など、結果の正確性が厳密に求められる領域での適用可否については、具体的な指針が示されていません。
Z-Imageの料金
ここでは、Z-Imageの料金について解説をします。
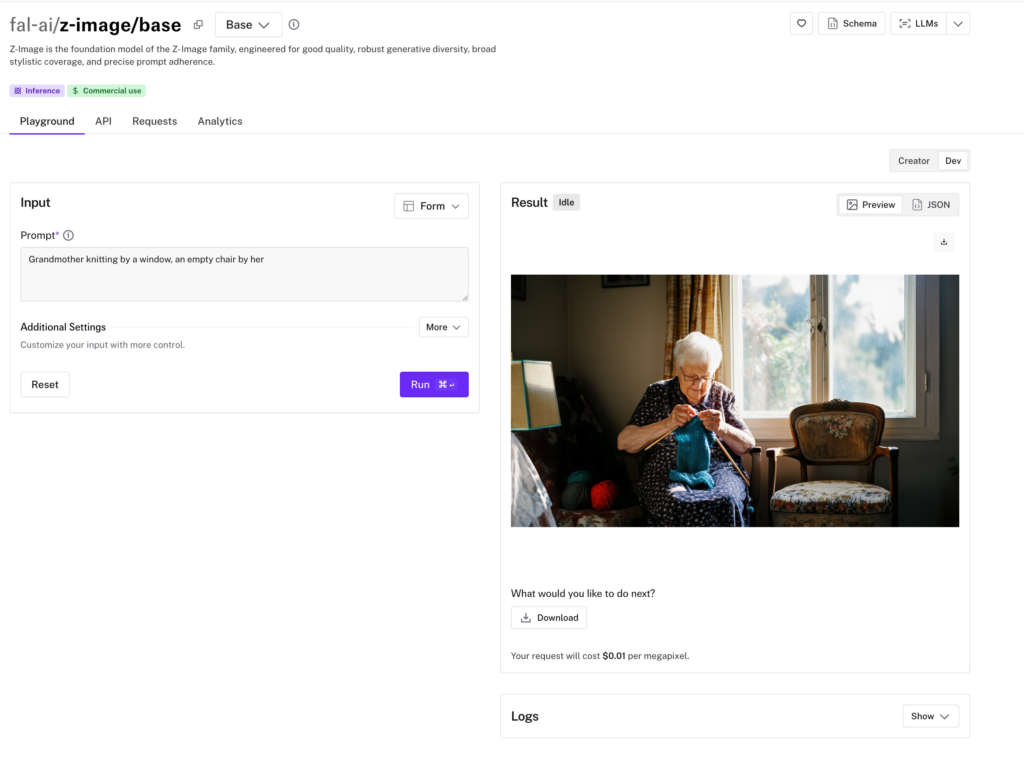
Z-image自体はAPIの提供がなく、Hugging Faceなどからモデルをダウンロードして利用することになります。
ちなみに、fal.aiではZ-Imageを利用できるようになっており、1メガピクセルあたり0.01ドルです。
なお、1秒未満で画像生成できるFLUX.2 [klein]について詳しく知りたい方は、下記の記事を合わせてご確認ください。
Z-Imageのライセンス
Z-ImageはApache 2.0ライセンスで公開されていて、商用利用・改変・再配布・特許利用・私的利用のすべてが許可されています。Apache 2.0ライセンスはオープンな条件で利用を認められているライセンスです
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
Apache 2.0ライセンスのもと、商用利用を含めて幅広い用途で利用できますが、生成物の内容や利用方法については利用者側が責任を負う点に注意が必要です。
まず、違法・有害なコンテンツの生成や法令に反する利用は認められていません。また、既存IPや実在人物を用いた生成物を商用利用する場合は、権利者のガイドラインや肖像権・プライバシーへの配慮が不可欠です。
\画像生成AIを商用利用する際はライセンスを確認しましょう/

Z-Imageの実装方法
Z-Imageを利用するにはHugging Faceからモデルをダウンロードするかfalなどで利用することになります。
また、ComfyUIでも利用可能です。
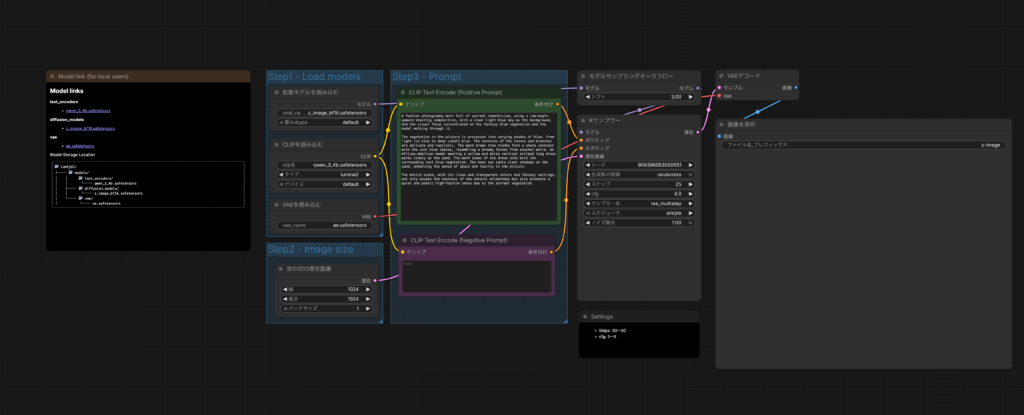
今回はfalを使って画像を生成してみたいと思います。プロンプトは「海を眺める毛の長い猫の親子」です。
生成された画像がこちら。

私の想定では、猫がカメラを見ているのではなく海を見ているものでした。ちなみに同様の内容を英語にした場合がこちら。

またちょっと変わった画像になりました。ただ、画質はすごくいいですね。結構リアリティがあります。
Z-Imageの活用シーン
ここでは、Z-Imageの特性を踏まえて考えられる活用シーンを解説します。
リアルタイム性が求められるコンテンツ生成
Z-Image-Turboは8 NFEsという少ない推論ステップで画像生成を行えます。そのため、待ち時間を極力短くしたいユースケースと相性が良いと考えられます。
例えば、プロトタイピング段階でのビジュアル案出しや、インタラクティブなデザイン検討での活用が想定されます。生成速度を重視する現場では、重宝するのではないでしょうか。
低VRAM環境での開発・検証用途
Z-Image-Turboは16GB未満のVRAM環境でも動作可能。そのため、GPUを用意できない場合でも検証が行いやすいです。
個人開発者や小規模チームによる研究開発、PoC用途での利用が考えられます。インフラコストを抑えながら画像生成モデルを試したいケースに適しています。
テキスト指示に基づく画像編集タスク
Z-Image-Editは、生成に加えて編集タスクを想定したモデルです。既存画像に対してテキスト指示を与え、部分的な修正や内容変更を行うことができます。
そのため、マーケティング素材の微調整や複数パターンのビジュアル作成などで活用が考えられます。生成と編集を同一系列で扱える点は、制作フローの簡素化につながる可能性があります。
Z-Imageを実際に使ってみた
さて、ここではZ-Imageをさらに使っていきたいと思います。
まずは先ほどのプロンプト「海を眺める毛の長い猫の親子」をZ-ImageとZ-Image-Turboで出力してみたいと思います。
一枚目がZ-Imageでの出力、二枚目がZ-Image-Turboの出力結果です。


動画を見ていただくとわかりますが、Z-Image-Turboの方が出力が早いことが確認できます。
次は少し映画っぽい風景を出力させてみます。
プロンプトは「雨上がりの山間部の風景。湿った空気の中に朝霧が漂い、木々の間から差し込む柔らかな光。曲がりくねった道が奥へと続き、静けさと奥行きを感じる構図。映画のワンシーンのような雰囲気、シネマティック、写実的。」です
一枚目がZ-Imageでの出力、二枚目がZ-Image-Turboの出力結果です。


個人的にはZ-Image-Turboの方がリアリティのある画像になっているなという印象です。もちろん、Z-Imageの画質も綺麗だと思います。
なお、Z.ai発のオープンソースかつ商用利用OKの画像生成モデルであるGLM-Imageについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

まとめ
本記事ではZ-Imageの概要から仕組み、実際の使い方、活用事例について解説をしました。Z-Image-Turboは短時間で高品質画像を生成できますが、それはZ-Imageがあってこそです。
今回リリースされたZ-Imageは基盤モデルなので、Z-Imageをベースに用途や要件に応じた派生モデルの開発や最適化が可能です。
ぜひ皆さんも本記事を参考にZ-Imageを使ってみてください!

最後に
いかがだったでしょうか?
最新の生成AIや画像生成技術は、活用次第で業務効率化だけでなく、新たな価値創出にもつながります。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、弊社紹介資料もご用意しておりますので、併せてご確認ください。

