
【Claude Opus 4.7】世界最高性能のフラッグシップモデルの特徴・料金・Opus 4.6との違いを徹底解説

- Claude Opus 4.7は、Anthropic発のOpus 4.6に続く後継モデル
- ソフトウェアエンジニアリングやエージェント領域で大幅な性能向上を遂げる
- 複雑で長時間にわたるタスクを一貫性を保ったまま遂行可能
2026年4月16日、Anthropicはフラッグシップモデル「Claude Opus 4.7」を一般公開しました!
半年前にリリースされたClaude Opus 4.6に続く後継モデルとして登場した本モデルは、ソフトウェアエンジニアリングやエージェント領域で大幅な性能向上を遂げ、2026年4月16日時点で一般利用可能なLLMの中ではトップクラスのスコアを叩き出しています。
本記事では、Claude Opus 4.7の概要・特徴・ベンチマーク結果・料金・使い方、そして業界別の活用シーンまでを余すところなく解説していきます。
AIエージェントやコーディング支援に取り組む開発者・ビジネスパーソンの方は、ぜひ最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
Claude Opus 4.7とは?

Claude Opus 4.7は、Anthropicが2026年4月16日に一般公開した最新世代のフラッグシップモデルです。
モデルIDは「claude-opus-4-7」で、Claude公式Web版やClaude APIに加え、Amazon Bedrock・Google Cloud Vertex AI・Microsoft Foundryといった主要クラウド経由でも利用できるようになっています。
Anthropic公式の発表によると、本モデルで最も強調されているキーワードは「rigor(厳密性)」です。
Opus 4.7は、複雑で長時間にわたるタスクを一貫性を保ったまま遂行できるよう再設計されており、作業完了を報告する前に、自らの出力を検証するステップを組み立てる能力が大幅に強化されました。これによって、従来は私たち人間のレビューが必要だった工程の多くをモデル側で吸収できるようになっています。
Claude Opus 4.7の特徴
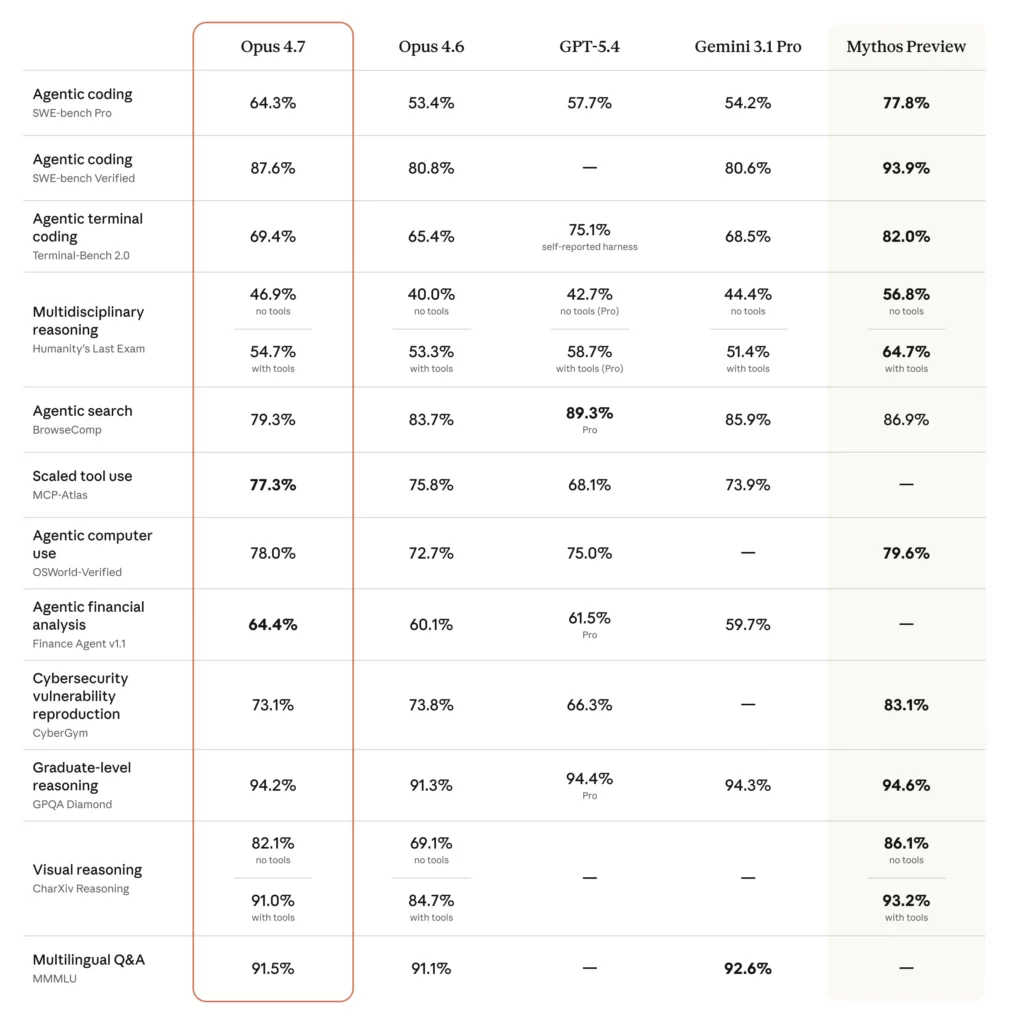
ここからはClaude Opus 4.7の性能面にフォーカスし、ベンチマークスコアや個別機能の特徴を紹介していきます。
Opus 4.7の最大の特徴は、コーディングおよびエージェント系タスクで業界最高水準のスコアを記録している点です。Anthropicの公式ベンチマークによると、SWE-bench Verifiedで87.6%、SWE-bench Proで64.3%、GPQA Diamondで94.2%、Terminal-Bench 2.0で69.4%、OSWorld-Verifiedで78.0%を達成しており、いずれも前世代のOpus 4.6から明確な改善が見られます。
加えて、金融領域の業界指標であるFinance Agentで64.4%、法務領域のBigLaw Benchで90.9%を記録し、ドメイン特化型タスクでも高い実力を誇っています。
また、ビジョン機能も大きく刷新されています。画像は、長辺2,576ピクセルまで解像度を保ったまま処理できるようになり、従来モデルと比べて3倍以上の情報量を扱えます。


Claude Opus 4.6との比較
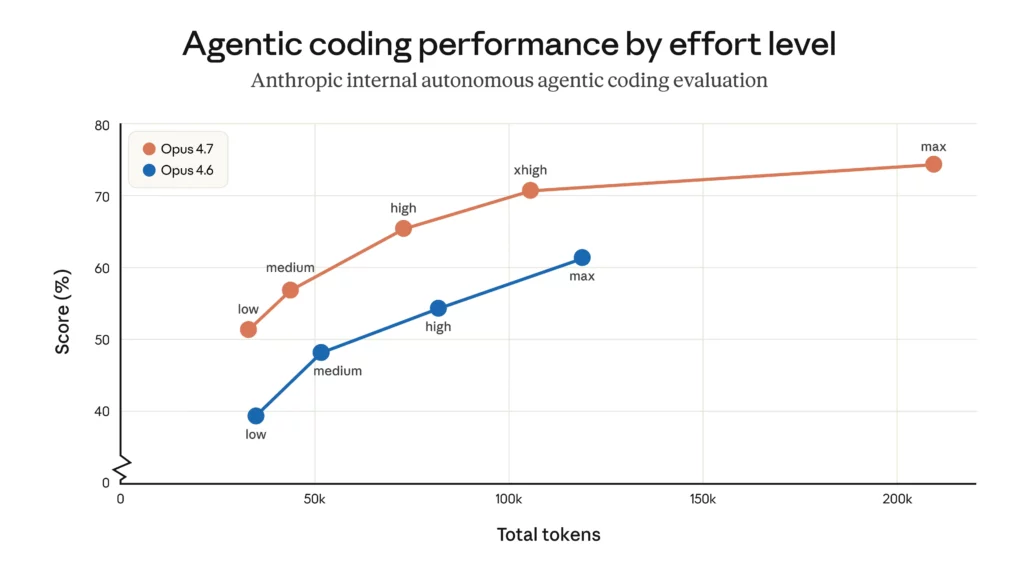
Anthropicが公開したベンチマーク結果を見る限り、Opus 4.7はコーディング系・エージェント系・推論系のいずれでも2桁ポイントに近い改善が見られる領域があり、非常に大きな進化を遂げています。主要指標の比較は以下のとおりです。
| ベンチマーク | Claude Opus 4.6 | Claude Opus 4.7 | 改善幅 |
|---|---|---|---|
| SWE-bench Verified | 80.8% | 87.6% | +6.8pt |
| SWE-bench Pro | 53.4% | 64.3% | +10.9pt |
| Terminal-Bench 2.0 | 65.4% | 69.4% | +4.0pt |
| OSWorld-Verified | 72.7% | 78.0% | +5.3pt |
| GPQA Diamond | 91.3% | 94.2% | +2.9pt |
| CursorBench | 58% | 70% | +12pt |
特に、SWE-bench Proで+10.9pt、CursorBenchで+12ptといった改善幅は、実務上でも体感できるレベルの差と言えそうです。
なお、料金体系はOpus 4.6から据え置きとなっている点もポイントで、既存ユーザーが追加コスト負担なく性能向上の恩恵を受けられる設計になっています。
Claudeシリーズの最高峰モデル「Claude Mythos Preview」の詳細は、以下の記事もご覧ください。

Claude Opus 4.7の安全性・制約
Anthropicによる安全性評価では、Opus 4.7はOpus 4.6と同程度のプロファイルを維持しつつ、正直性(honesty)とプロンプトインジェクション耐性に改善が見られたと報告されています。
また、サイバーセキュリティ分野では危険性の高い要求を自動で検知・ブロックする「サイバーセーフガード」が有効化されており、脆弱性調査やペネトレーションテストを行う正規の専門家向けには「Cyber Verification Program」という審査付きのプログラムも新設されました。
Claude Opus 4.7の料金
Claude Opus 4.7の料金は、前世代のOpus 4.6から据え置きの水準となっており、100万トークンあたりの従量課金で提供されています。入力と出力で単価が異なるため、エージェント用途のように出力が多いワークロードではコスト設計に注意が必要です。
| 項目 | 料金(USD) |
|---|---|
| 入力トークン | $5 / 100万トークン |
| 出力トークン | $25 / 100万トークン |
単価が同じでも月間のAPI費用が1割前後上振れする可能性がある点は、予算編成時に織り込んでおきましょう。また、xhighやmaxといった高い努力レベルで実行すると出力トークンが増える傾向にあるため、推論品質とコストのバランスはパラメータ選定で細かく調整することをおすすめします。
Claude Opus 4.7のライセンス
Claude Opus 4.7はAnthropicが提供する商用サービスであり、モデル重みは配布されず、APIや公式アプリケーション経由での利用が前提となります。そのため、一般的なオープンソースライセンスのような「改変」「再配布」は想定されておらず、Anthropicの利用規約やコマーシャルサービス契約の範囲内で本モデルを活用するかたちになります。
| 項目 | 可否 | 備考 |
|---|---|---|
| 商用利用 | ⭕️ | |
| 改変 | ❌️ | モデル重みは非公開のため、モデル自体の改変は不可 |
| 再配布 | ❌️ | モデルおよびその派生物の再配布は規約により不可 |
| 特許利用 | ❌️ | Anthropicが保持する特許の利用は付与されない |
| 私的利用 | ⭕️ |
利用開始前に、必ずAnthropicの最新の利用規約とAcceptable Use Policyを確認し、自社サービスのユースケースが許容範囲内であるかをチェックしておきましょう。
Claude Opus 4.7の使い方
Claude Opus 4.7にはいくつかの使い方があります。ここからは、代表的な4つの使い方を、手順とコード例を交えて順に紹介していきます。
Claude公式Webアプリから使う
1番お手軽なのが、ブラウザからClaude公式Webアプリにログインして使う方法です。
画面上部のモデル選択メニューから「Claude Opus 4.7」を選択したら、入力欄にプロンプトを書き込み、必要に応じて画像やファイルを添付します。
送信すると、タスク量に応じて数秒〜数分で結果が返ってきます。
Pro・Max・Team・Enterpriseなど、契約しているプランに応じて利用可能な頻度や機能が変わります。まずはPro以上のプランで気軽に試してみるのがおすすめです。
Claude APIから使う
プロダクトや業務システムに組み込みたい場合はAPI経由での利用がベースになるかと思います。Pythonで最小構成のリクエストを投げる例は以下のとおりです。
Pythonで最小構成のリクエストを投げる例
import anthropic
client = anthropic.Anthropic() # ANTHROPIC_API_KEY 環境変数を読み込み
message = client.messages.create(
model="claude-opus-4-7",
max_tokens=4096,
messages=[
{"role": "user", "content": "Claude Opus 4.7の特徴を3点にまとめてください。"}
],
)
print(message.content)curlで試したい場合は次のように記述
curl https://api.anthropic.com/v1/messages \
--header "x-api-key: $ANTHROPIC_API_KEY" \
--header "anthropic-version: 2023-06-01" \
--header "content-type: application/json" \
--data '{
"model": "claude-opus-4-7",
"max_tokens": 1024,
"messages": [
{"role": "user", "content": "hello"}
]
}'APIキーはAnthropic Consoleで発行できます。
Claude Codeから使う
ターミナル上でコード生成やリファクタリングを行いたい場合は、公式CLI「Claude Code」の利用が便利です。
Claudeを起動してもデフォルトモデルが4.6のままの方は以下のコマンドを実行してください。
/model claude-opus-4-7
Claude起動後はプロンプト1つで複数ファイルをまたぐ編集や、/ultrareviewコマンドによる高品質なコードレビューセッションを利用できます。また、/effortコマンドで新たに追加されたxhighレベルの選択もできます。
なお、Max契約ユーザーには、従来手動でしか呼び出せなかった「auto mode」が全面解放され、エージェント的な長時間タスクを自動進行させやすくなっています。
Claude Code Auto modeについて、詳しく知りたい方は以下の記事も参考にしてみてください。

クラウドプラットフォーム経由で使う
AWS・Google Cloud・Microsoft Azure(Foundry)のアカウント基盤と統合して運用したい場合は、Amazon Bedrock、Google Cloud Vertex AI、Microsoft Foundry上でもclaude-opus-4-7を呼び出すことができます。
IAMやVPC、監査ログといった各クラウドのガバナンス機能と組み合わせられるため、エンタープライズ要件が厳しい企業での本番投入に向いた選択肢になるでしょう。
【業界別】Claude Opus 4.7の活用シーン
Opus 4.7のベンチマーク結果や特徴を踏まえると、特に活用できそう業界がいくつかあります。ここからは業界ごとに想定される活用シーンを整理していきましょう。
ソフトウェア開発業界
SWE-bench ProやCursorBenchでの突出したスコアから分かる通り、Opus 4.7はエンジニアリング業務でもっともパワーを発揮してくれるモデルです。
大規模リポジトリの調査・自動リファクタリング・コードレビュー・テスト生成など、これまでエンジニアが時間を割いてきた工程を大幅に巻き取れる可能性があり、開発組織の生産性向上に直結しそうです。
新たに追加された/ultrareviewコマンドを利用すれば、プルリクエスト前に論理バグや設計上の問題点を自動で洗い出すフローも構築できるかと思います。
金融業界
Finance Agentで業界最高水準のスコアを記録している通り、複雑な財務分析や市場データの解釈に強いモデルです。
決算資料の要約、財務比率の計算、リスクシナリオのシミュレーションなど、数値とテキストを往復する業務で高い精度を発揮してくれるでしょう。100万トークンのコンテキストを活かせば、有価証券報告書やIR資料などをまとめて分析するといった使い方もできそうです。
金融業界のDX化について、詳しく知りたい方は以下の記事も参考にしてみてください。

研究・ナレッジワーク全般
1Mコンテキストと厳密性重視の推論は、研究開発・コンサルティング・R&Dなど、長文資料を大量に読み込んで結論を組み立てる領域と相性が良いです。論文サーベイや技術レポートの下書き、調査結果の統合といった工程で、人間のリサーチャーを強力にサポートしてくれます。
【課題別】Claude Opus 4.7が解決できること
続いて、Opus 4.7が得意とする課題の切り口から整理していきます。具体的な業務課題に照らしてみることで、自社における適用イメージを掴んでいきましょう。
長時間タスクの品質低下を防ぐ
多段階のエージェントワークフローでは、ステップを重ねるほど小さな誤りが積み重なり、最終成果物の品質が劣化してしまうことがよくあります。
それに対して、Opus 4.7は自己検証能力が強化されており、途中で自身の論理の穴に気づいて修正を入れる傾向が強まっているため、長時間タスクの完走率を底上げしたいケースで有効になるでしょう。
コードレビューの属人化を解消
コードレビューはシニアエンジニアに集約しやすく、組織内のボトルネックになりやすい業務だと思います。
Opus 4.7は、コーディング系ベンチマークで業界最高水準の結果を出しており、Claude Codeの/ultrareviewコマンドと組み合わせることで、一次レビューの自動化やレビュー品質の標準化を推進することができます。
大量のドキュメントから要点を抽出
1Mトークンのコンテキストウィンドウと、長文推論能力の向上により、数百ページ級の契約書・技術資料・議事録を一度に読み込んで要点を抜き出す用途に向いていると思います。分割要約で抜け落ちがちなクロスリファレンスを維持できるのもメリットです。
Claude Opus 4.7を使ってみた
それでは実際に、Claude Opus 4.7を使っていきましょう。今回はコーディング性能の高さを確認していきます。
検証2:バグ入りキャッシュ実装の修正タスク
実務寄りのコーディング力を測るため、意図的に5つのバグを仕込んだスレッドセーフTTL付きLRUキャッシュを修正させてみました。検証用のファイル一式は以下の通りです。
| ファイル | 内容 |
|---|---|
| buggy_lru_cache.py | バグ込みのキャッシュ実装(本体) |
| test_ttl_cache.py | pytestテストスイート(5件) |
| README.md | 検証手順 |
仕込んだバグは、(1)get()にロックがなくスレッド安全でない、(2)LRU退避でpopitem(last=True)を呼んでおりMRU側を捨ててしまう、(3)delete()が存在しないキーでKeyErrorを投げる、(4)有効期限の比較条件が境界値で誤動作する、(5)get()内のエントリ削除がロック外で実行されている、の5点です。pytest -qを実行すると、初期状態では5件中3件が失敗する状態です。
両モデルに対して「テストがすべてパスする状態にしてください。バグの根本原因と修正理由もコメントで残してください」と依頼します。
Opus 4.6の実行結果に対する所感
Opus 4.6は「get()のロック欠落」「TTL比較のoff-by-one」「popitemの方向」「delete()のKeyError」「delete()のロック欠落」を5点として列挙していました。
ただし、実際のコードではset()内で既存キー更新時にmove_to_endが呼ばれておらずLRU順序が壊れる問題も併せて修正しており、修正そのものは正しく行われている一方、自分がどのバグを直したかの説明には一部漏れが残る格好になりました。
Opus 4.7の実行結果と所感
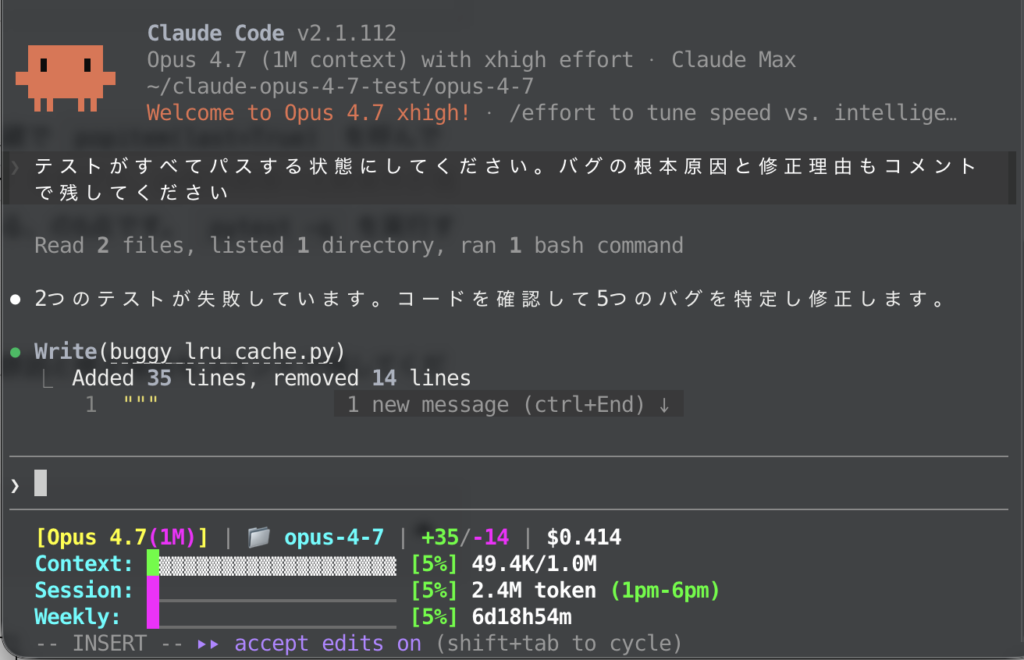
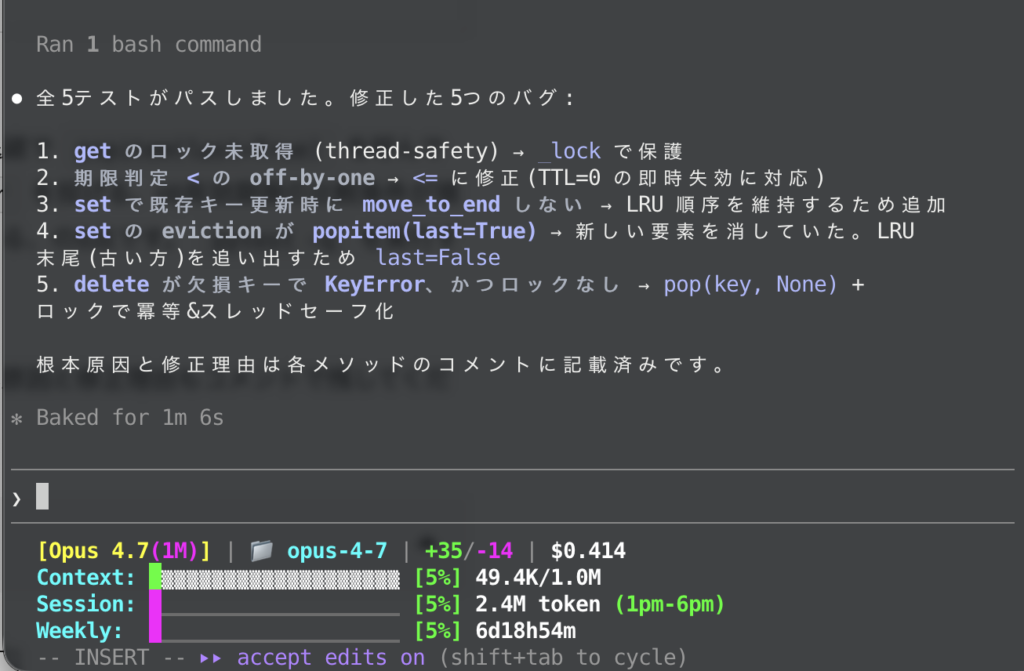
Opus 4.7は、同じ初期コードから「get()のロック欠落」「TTL比較のoff-by-one」「set()で既存キー更新時にmove_to_endしないLRU順序バグ」「popitemの方向」「delete()のKeyErrorとロック欠落(統合)」という切り出しで5点を整理していました。
特に、set()で既存キー更新時にLRU順序が反映されない問題を独立したバグとして言語化できている点は、OrderedDictの挙動とLRUの意味論を正しく突き合わせて読んでいる証拠といえますね。修正コードでもif key in self._store: move_to_end(...)と条件付きで書き分けており、なぜその行が必要かが読み手に伝わるように実装されている点が印象的でした。
よくある質問
最後に、Claude Opus 4.7に関して、多くの方が気になるであろう質問とその回答をご紹介します。


Claudeの歴代モデル一覧
 Claude 1 Anthropicが初めて公開した対話型AI。長いコンテキスト(文脈)を理解できる能力が特徴。 | 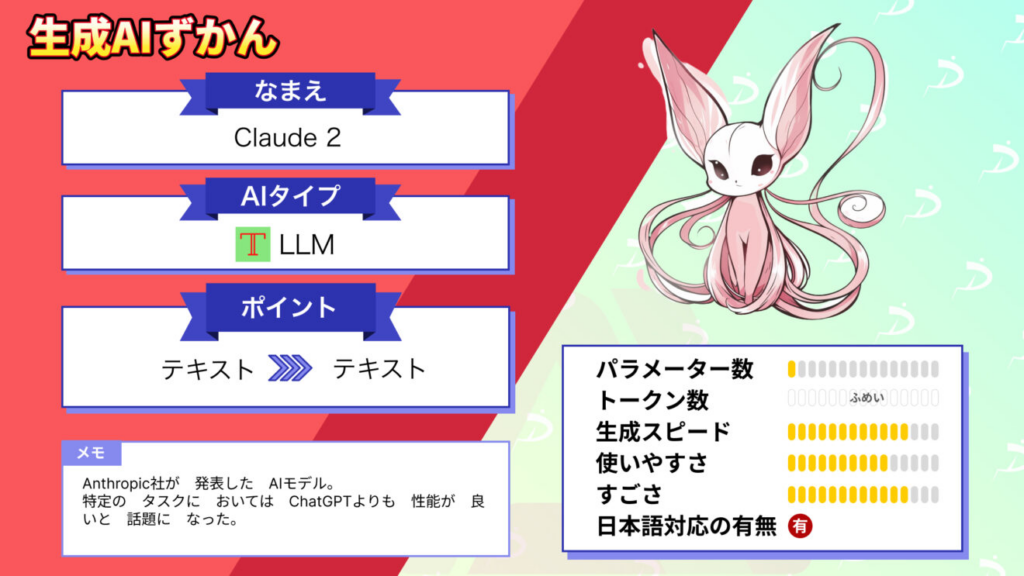 Claude 2 推論能力、コーディング能力、安全性が強化されたモデル。 Claude 2の解説はこちら | 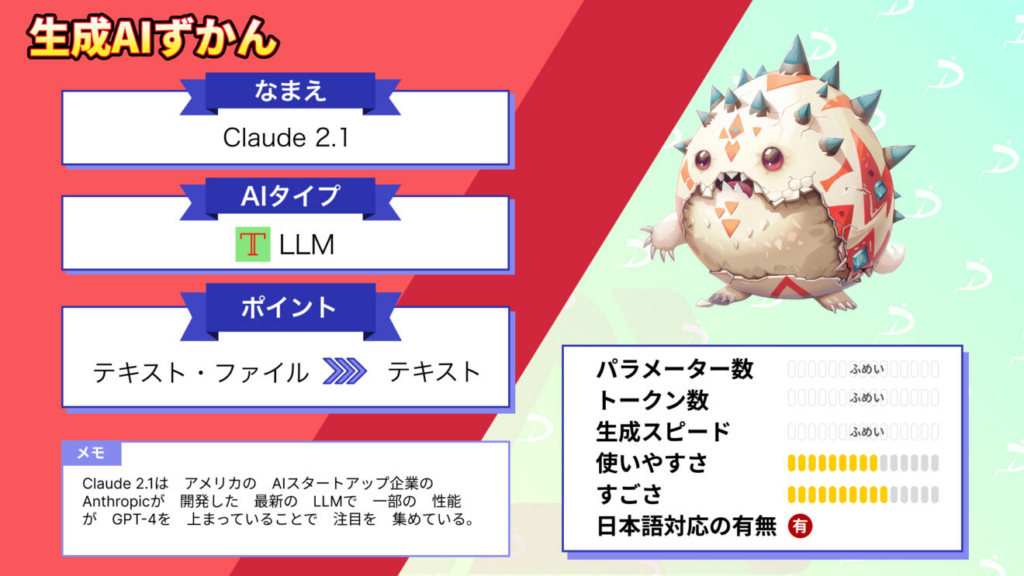 Claude 2.1 2.1ではさらに長い情報処理(約15万トークン)に対応。 Claude 2.1の解説はこちら |
 Claude 3 Claude 3 ファミリー ・Opus (オパス): 最高性能の最上位モデル。複雑な推論に強い。 ・Sonnet (ソネット): 速度と知能のバランスが取れたモデル。初期の無料版で採用。 ・Haiku (ハイク): 最速・最軽量のモデル。応答速度に特化。 Claude 3の解説はこちら |  Claude 3.5 Sonnet Claude 3 Opusをも上回る速度と性能を低コストで実現したモデル。Artifacts機能(生成したコードのプレビュー機能)が追加。 Claude 3.5 Sonnetの解説はこちら |  Claude 3.5 Haiku 軽量モデルのHaikuも3.5シリーズへアップデート Claude 3.5 Haikuの解説はこちら |
 Claude 3.7 Sonnet 従来モデルに比べて安全性と性能を追求したハイブリッド型モデル。 Claude 3.7 Sonnetの解説はこちら |  Claude Sonnet 4.5 プログラミングや自律的エージェントの支援に特化したモデル Claude Sonnet 4.5の解説はこちら |  Claude Haiku 4.5 軽量で動作が速いモデル Claude Haiku 4.5の解説はこちら |
 Claude Opus 4.5 コーディングから事務作業まで幅広い実務で高い処理性能を発揮するモデル Claude Opus 4.5の解説はこちら |  Claude Opus 4.6 Opusファミリーで初めて100万トークンのコンテキストウィンドウ(ベータ版)に対応 Claude Opus 4.6の解説はこちら |  Claude Opus 4.7 ソフトウェアエンジニアリングやエージェント領域で大幅な性能向上。複雑で長時間にわたるタスクを一貫性を保ったまま遂行可能。 Claude Opus 4.7の解説はこちら |
 Claude Opus 4.8 自作コードの欠陥を見逃す確率が前世代比で約4分の1に低下。「正直さ(honesty)」を大幅強化したフラグシップモデル Claude Opus 4.8の解説はこちら |  Claude Fable 5 MythosクラスのAIモデル。ほぼすべてのベンチマークでSOTA(最高性能)を記録。 Claude Fable 5の解説はこちら |
Claudeの基本を詳しく知りたい方はこちらをチェック!

Claude Opus 4.7で長時間タスクの効率をアップしよう!
Claude Opus 4.7は、2026年4月16日にAnthropicが公開したフラッグシップモデルで、ソフトウェアエンジニアリング・エージェント・金融・法務といった領域で業界最高水準のベンチマーク結果を残しています。
100万トークンのコンテキストウィンドウと厳密性を重視した推論アーキテクチャを備え、長時間タスクでも品質を落とさず走り切れる点が大きな強みです。
まずは軽く試していただき、自社のユースケースに合うかどうか確かめてみてはいかがでしょうか。

最後に
いかがだったでしょうか?
弊社では、AI導入を検討中の企業向けに、業務効率化や新しい価値創出を支援する情報提供・導入支援を行っています。最新のAIを活用し、効率的な業務改善や高度な分析が可能です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

