
【DiffusionGemma】テキスト生成が4倍速に!Googleの拡散型オープンモデルの仕組み・使い方を徹底解説

- Google DeepMindが、テキスト拡散(Diffusion)方式を採用した実験的オープンモデル「DiffusionGemma」を公開
- 従来の自己回帰型LLMと比較して、専用GPU上で最大4倍の高速テキスト生成を実現
- Apache 2.0ライセンスで公開され、量子化すれば18GB VRAMのコンシューマGPUでもローカル実行が可能
2026年6月11日、Google DeepMindはテキスト拡散ベースの実験的オープンモデル「DiffusionGemma」を公開しました!
トークンを1つずつ生成する従来のLLMとは根本的に異なり、256トークンのブロック全体を同時に生成するという新たなアプローチで、専用GPU上では最大4倍の高速推論を達成しています。
「ローカルGPUでそこまで速くなるのか」と驚く方も多いのではないでしょうか。この記事では、DiffusionGemmaの概要から技術的な仕組み、料金・ライセンス体系、具体的な使い方、業界別の活用シーンまで徹底的に解説します。ぜひ、最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
DiffusionGemmaとは?

DiffusionGemmaは、Google DeepMindが2026年6月11日に公開したテキスト拡散(Text Diffusion)ベースの実験的オープンモデルです。
従来の大規模言語モデル(LLM)は、トークンを1つずつ左から右へ順番に生成する「自己回帰(Autoregressive)」方式を採用してきました。DiffusionGemmaはこの発想を根本から覆し、256トークンのブロック全体を同時並行で生成するという新しいアプローチを採用しています。
モデルの基盤にはGemma 4ファミリーのアーキテクチャが使われており、総パラメータ数は26B(260億)のMixture of Experts(MoE)構成です。推論時に実際に動作するのはわずか3.8Bパラメータにとどまるため、量子化することでNVIDIA GeForce RTX 5090やRTX 4090といったハイエンドコンシューマGPUの18GB VRAM内に収まる設計となっています。
DiffusionGemmaの仕組み
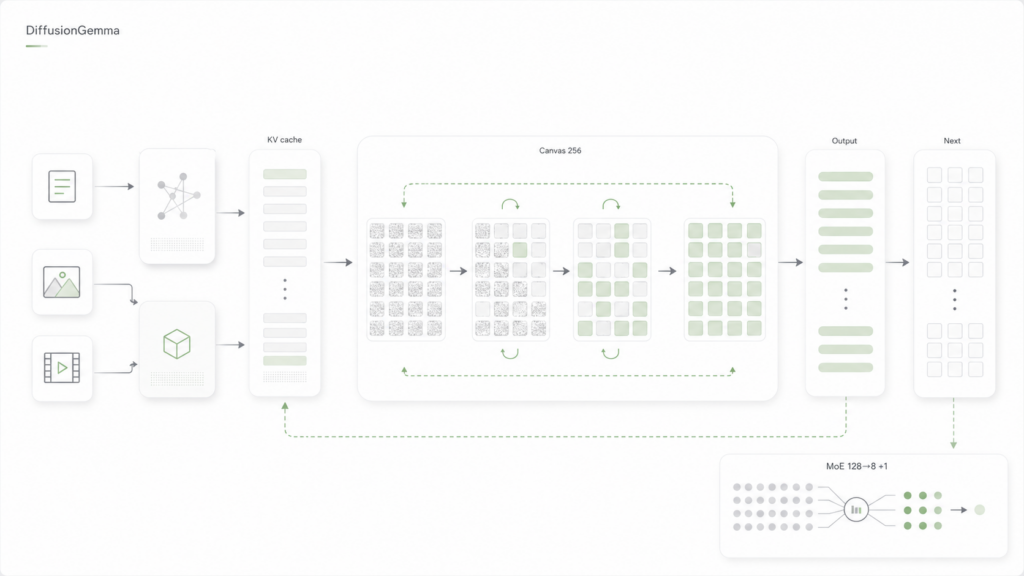
DiffusionGemmaの動作原理は、画像生成AIでおなじみの拡散モデル(Diffusion Model)をテキスト生成に応用した「離散拡散(Discrete Diffusion)」がベースになっています。
具体的には、エンコーダ・デコーダアーキテクチャとブロック自己回帰拡散(Block Autoregressive Diffusion)という2つの仕組みが組み合わされています。
まずエンコーダがプロンプトを処理してKVキャッシュ(コンテキスト情報)を生成し、デコーダが256トークン分の「キャンバス(Canvas)」と呼ばれる生成領域に対して双方向アテンション(Bidirectional Attention)を適用します。

テキスト生成のプロセスは、画像の拡散モデルと非常に似ています。最初にランダムなプレースホルダートークンで埋められたキャンバスを用意し、そこから複数回のデノイジング(ノイズ除去)パスを繰り返します。各パスで確信度の高いトークンを確定させ、それらをヒントとして残りのトークンをさらに精製していく流れです。最終的には、キャンバス全体が高品質なテキストに収束します。
256トークンを超える長い出力を生成する場合は、1つのキャンバスが完全にデノイジングされた時点でKVキャッシュに追加し、次の新しいキャンバスの生成に移行します。これがブロック自己回帰拡散の仕組みで、並列処理の速度と自己回帰型モデルの安定性を両立させています。
MoE構成は128個のエキスパートのうち8個をアクティブにする設計(+共有エキスパート1個)で、ビジョンエンコーダ(約550Mパラメータ)も搭載しており、テキストだけでなく画像や動画の入力にも対応するマルチモーダルモデルです。


DiffusionGemmaの特徴
DiffusionGemmaには、従来の自己回帰型モデルにはない独自の強みがいくつもあります。
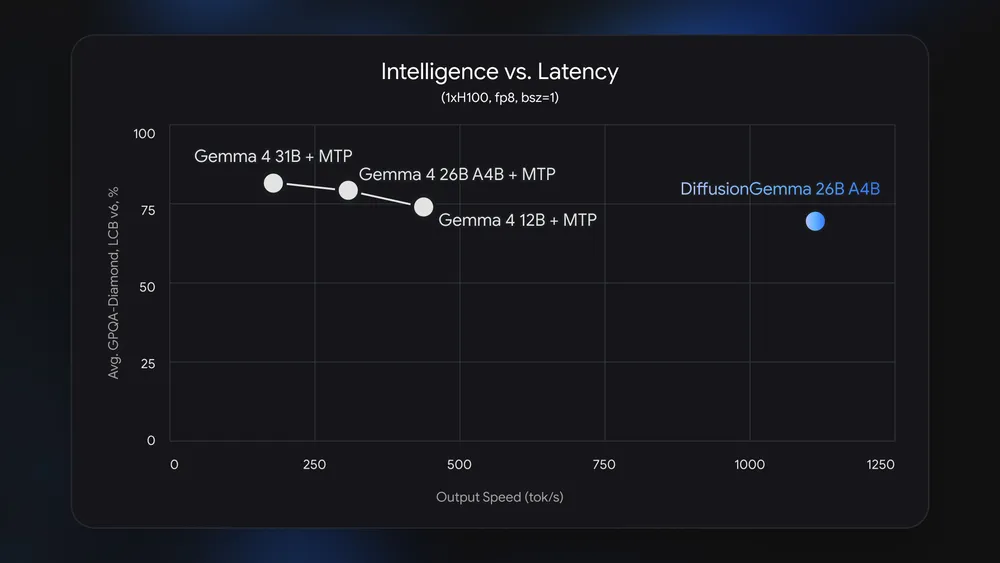
まず注目すべきは圧倒的な推論速度です。NVIDIA H100上で毎秒1,000トークン以上、コンシューマ向けのRTX 5090でも毎秒700トークン以上という数値が公式に報告されています。1回のフォワードパスで15〜20トークンを同時に生成できるため、ローカル推論時のレイテンシが大幅に削減されます。
次に、双方向アテンションによるインテリジェントな自己修正が挙げられます。自己回帰型モデルは左から右への一方向的な処理しかできませんが、DiffusionGemmaはキャンバス上の全トークンが互いを参照できます。この仕組みにより、生成途中の文脈矛盾を自動的に検知・修正し、複雑なMarkdownフォーマットやコードブロックをリアルタイムで整形することが可能です。
さらに、適応的推論時間計算(Adaptive Inference Time Computation)という特徴もユニークです。単純なプロンプトやコード生成のような構造化タスクではデノイジングステップが少なく済むため、タスクの複雑さに応じて動的に処理速度が変化します。

ベンチマークスコアに目を向けると、MMLU Proで77.6%、GPQA Diamondで73.2%、LiveCodeBench v6で69.1%と、スピード特化モデルとしてはかなりの実力を持っています。ただし、標準のGemma 4 26B A4Bと比較するとすべてのベンチマークでスコアが下回っている点は覚えておくべきでしょう。
X上で話題沸騰!「ローカルLLMの常識を変える」と注目される理由
DiffusionGemmaの公開直後から、X上では開発者やAIリサーチャーの間で大きな反響が広がっています。
GGUF量子化モデルの提供をいち早く発表した上記のポストは大きな注目を集め、「18GB RAMでローカル実行可能な拡散テキストモデル」という手軽さが話題の中心になっています。
Google CEOのSundar Pichai氏も自身のXアカウントで「DiffusionGemmaは競走馬(racehorse)だ」と表現し、トークンを1つずつ予測する従来方式と比較してテキストブロック全体を一括生成する速度感をアピールしています。
特にX上で盛り上がっているのは、ファインチューニングで数独(Sudoku)を解けるようになった事例です。
自己回帰型モデルでは各セルの値が後続のセルに依存するため数独の解法が困難でしたが、DiffusionGemmaの双方向アテンションを活用することで正答率が0%から80%にまで向上したという結果が報告されています。この事例は「拡散モデルが推論タスクでも優位性を持つ」ことを示す具体例として衝撃を与えています。
DiffusionGemmaの安全性・制約
DiffusionGemmaは、Google DeepMindの自社プロプライエタリモデルであるGeminiと同等の安全性評価プロセスを経て公開されています。
さらに、Apple Siliconのようなユニファイドメモリアーキテクチャのデバイスでは、メモリ帯域幅がボトルネックとなりやすいため、自己回帰型モデルと比較した速度向上が限定的になる可能性がある旨も公式の注釈として明記されています。
DiffusionGemmaの料金
DiffusionGemmaはオープンウェイトモデルとして公開されているため、ローカル環境で実行する場合は基本的に無料で利用できます。ただし、クラウド経由でのアクセスにはプラットフォームごとの料金体系が適用されるため、利用方法に応じた費用感を把握しておくことが大切です。
| 利用方法 | 料金 | 備考 |
|---|---|---|
| Hugging Faceからウェイトをダウンロード | 無料 | Apache 2.0ライセンス |
| ローカルGPU実行(vLLM、Transformers、llama.cpp等) | 無料 | 対応GPUが必要(推奨:RTX 5090/4090/H100等) |
| Google Cloud Model Garden | Google Cloud料金に準拠 | Gemini Enterprise Agent Platform経由 |
| NVIDIA NIM | NVIDIA利用規約に準拠 | NVIDIA NIMカタログ経由 |
| NVIDIA build.nvidia.com API | 無料枠あり | テスト・プロトタイピング用 |
DiffusionGemmaのライセンス
DiffusionGemmaはApache 2.0ライセンスのもとで公開されているため、オープンソースモデルの中でも特に利用条件が寛容です。商用プロジェクトや独自モデルの開発基盤として採用する際にも、法的なハードルが低い点は大きなメリットといえるでしょう。
| 項目 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 再配布 | ⭕️ |
| 特許利用 | ⭕️ |
| 私的利用 | ⭕️ |
DiffusionGemmaの使い方
DiffusionGemmaは複数の方法で実行できます。今回は、代表的な3つの方法をステップバイステップで解説していきます。

Hugging Face Transformersで実行する方法
最もシンプルにDiffusionGemmaを試す方法は、Hugging Face Transformersを使ったPythonコードからの実行です。
まず、transformersライブラリの最新版をインストールします。
pip install -U transformers続いて、以下のPythonコードでモデルをロードし、テキスト生成を実行します。
from transformers import AutoProcessor, AutoModelForMultimodalLM
processor = AutoProcessor.from_pretrained("google/diffusiongemma-26B-A4B-it")
model = AutoModelForMultimodalLM.from_pretrained("google/diffusiongemma-26B-A4B-it")
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": "Pythonでフィボナッチ数列を生成する関数を書いてください"}
]
},
]
inputs = processor.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt",
).to(model.device)
outputs = model.generate(**inputs, max_new_tokens=256)
print(processor.decode(outputs[0][inputs["input_ids"].shape[-1]:]))画像入力を伴うマルチモーダルなプロンプトにも対応しています。その場合は、contentに{"type": "image", "url": "画像URL"}を追加するだけでOKです。
vLLMでサーバーとして起動する方法
高スループットの推論サーバーを構築したい場合は、vLLMの利用が便利です。DiffusionGemmaはvLLMのDay-Zeroサポートに対応しています。
まず、vLLMをインストールします。
pip install vllm次に、以下のコマンドでモデルをサーバーとして起動します。
vllm serve "google/diffusiongemma-26B-A4B-it"サーバーが起動したら、OpenAI互換のAPIとしてリクエストを送信できます。
curl -X POST "http://localhost:8000/v1/chat/completions" \
-H "Content-Type: application/json" \
--data '{
"model": "google/diffusiongemma-26B-A4B-it",
"messages": [
{
"role": "user",
"content": "DiffusionGemmaの特徴を3つ教えてください"
}
]
}'llama.cpp(GGUF量子化版)でローカル実行する方法
VRAMの制約がある環境では、Unslothが提供するGGUF量子化版を使ったllama.cppでの実行が最適です。4-bit量子化(UD-Q4_K_XL)で約18GBのRAMに収まります。
まず、llama.cppのDiffusionGemma対応ブランチをクローン・ビルドします。
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp
gh pr checkout 24423
cmake -B build -DGGML_CUDA=ON
cmake --build build -j --config Release --target llama-diffusion-cli続いて、モデルのダウンロードと実行です。
pip install huggingface_hub hf_transfer
huggingface-cli download unsloth/diffusiongemma-26B-A4B-it-GGUF \
--include "diffusiongemma-26B-A4B-it-UD-Q4_K_XL*" \
--local-dir models最後に、以下のコマンドで対話的に生成を開始します。
./build/bin/llama-diffusion-cli \
-m models/diffusiongemma-26B-A4B-it-UD-Q4_K_XL.gguf \
-p "日本語で自己紹介をしてください" \
-n 256拡散プロセスをリアルタイムで可視化したい場合は、--diffusion-visualオプションを追加すると、トークンがノイズから収束していく様子を確認できます。


【業界別】DiffusionGemmaの活用シーン
DiffusionGemmaの高速かつ双方向的なテキスト生成という特性は、さまざまな業界で新しい活用の可能性を開きます。ここからは、特に相性の良い業界別のシーンを見ていきましょう。
ソフトウェア開発・エンジニアリング
DiffusionGemmaの最大の強みであるコードインフィリング機能は、IDEのインラインコード補完をリアルタイムで行う場面に最適です。
既存コードの途中に新しいロジックを挿入する際、双方向アテンションにより前後の文脈を同時に参照できるため、自己回帰型モデルよりも自然な補完結果が得られます。ローカルGPU上で毎秒数百トークンの速度で動作するため、クラウドAPIへのレイテンシを気にする必要がなく、開発の反復サイクルを大幅に短縮できるでしょう。
生成AIを搭載したSaaSについて、詳しく知りたい方は以下の記事も参考にしてみてください。

創薬・バイオインフォマティクス
アミノ酸配列の生成は、DiffusionGemmaの双方向アテンションが本領を発揮する典型的な非線形構造のタスクです。タンパク質の配列設計では、離れた位置にあるアミノ酸同士が空間的に近接して相互作用するケースが多く、一方向的な生成では考慮しきれない依存関係をブロック全体の同時最適化で捉えられる可能性があります。
研究段階ではありますが、構造予測や候補配列のスクリーニングにおいて新たなアプローチが期待されます。
なお、医療・薬業界における生成AIの活用方法については下記の記事をご覧ください。
医療業界はこちら

薬業界はこちら

教育・学術研究
数学やパズルのような制約充足問題では、DiffusionGemmaの双方向処理が従来モデルにない強みを発揮します。数独のファインチューニング事例が示すように、各セルの値が他のセルに依存する構造的な問題を並列に解く能力は、数学教育用ツールや研究向けの問題解決エンジンとしての活用が見込まれます。
教育業界における生成AI活用について、詳しく知りたい方は以下の記事も参考にしてみてください。

【課題別】DiffusionGemmaが解決できること
日々の業務や開発で直面するさまざまな課題に対して、DiffusionGemmaがどのように役立つのかを課題ごとにご紹介します。
ローカル推論のレイテンシ短縮
従来のLLMをローカルで単一ユーザー向けに実行すると、GPUの計算資源が十分に活用されず、メモリ帯域幅がボトルネックとなって応答速度が制限されていました。DiffusionGemmaは、ボトルネックをメモリ帯域幅から計算処理へとシフトさせることでこの問題を解消し、ローカル環境でもリアルタイムに近い速度でテキスト生成が可能になります。
コードの途中挿入・穴埋めで前後の文脈を反映
自己回帰型モデルでは左から右への一方向生成のため、既存コードの中間に新しいコードを挿入する際、後続の文脈を考慮できないという根本的な限界がありました。DiffusionGemmaの双方向アテンションは、挿入位置の前後両方のコンテキストを同時参照できるため、より整合性の高いコードインフィリングが実現するでしょう。
構造的制約のあるテキスト生成で品質を安定させる
テーブル構造、Markdownの入れ子、数式のフォーマットなど、厳密な構造ルールに従う必要があるテキストの生成は、自己回帰型モデルが苦手とする領域でした。
DiffusionGemmaはブロック全体を一度に見渡して整合性を検証・修正できるため、複雑なフォーマットの生成品質が向上します。
よくある質問
最後に、DiffusionGemmaに関して、多くの方が疑問に感じるポイントをQ&A形式でまとめました。
DiffusionGemmaでローカルAI推論の新時代を切り拓こう
DiffusionGemmaは、テキスト生成の手法を自己回帰からテキスト拡散へと転換し、専用GPU上で最大4倍の速度向上を実現した実験的オープンモデルです。
出力品質の面ではGemma 4に劣るものの、ローカル推論における速度改善やコードインフィリングなどの非線形タスクへの対応力は、従来のLLMにはない新しい価値を提供しています。Apache 2.0ライセンスによるオープンな公開、NVIDIAとの連携によるハードウェア最適化、Unslothやvllmなど主要ツールのDay-Zeroサポートなど、エコシステムの整備も万全です。
今後、テキスト拡散モデルの品質がさらに向上していけば、プロダクション用途での本格採用も視野に入ってくるでしょう。ローカルAI推論の可能性に関心がある方は、ぜひ今のうちにDiffusionGemmaに触れてみてはいかがでしょうか。

最後に
いかがだったでしょうか?
弊社では、AI導入を検討中の企業向けに、業務効率化や新しい価値創出を支援する情報提供・導入支援を行っています。最新のAIを活用し、効率的な業務改善や高度な分析が可能です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

