
DroPEとは?SakanaAI発の位置埋め込みを削除してLLMの文脈長制約を突破する新手法を解説

- 位置埋め込みを学習後に外すことで未学習の文脈長へ一般化可能
- 再キャリブレーションは低コストで既存の事前学習モデルを活かせる
- 長文処理でも性能劣化が緩やかな長文タスク向け設計
2026年1月、SakanaAIから新たな文脈長拡張手法を公開しました。
今回公開された「DroPE」は位置埋め込みを削除することで事前学習済みLLMのコンテキストを拡張するというものです。
従来のLLMでは文脈長が問題になっていましたが、多くのモデルは学習時の文脈長を超えると性能が落ちるという弱点がありました。DroPEはこの弱点を克服するために開発されています。
本記事ではDroPEの概要から仕組み、実際の使い方について解説をします。本記事を最後までお読みいただければDroPEについて理解が深まります。
ぜひ最後までお読みください!
\生成AIを活用して業務プロセスを自動化/
DroPEの概要
LLMで長文を扱うとき、まず壁になるのが「学習時に想定した文脈長を超える入力」への弱さです。この弱点を克服するために開発されたのが、事前学習後に位置埋め込みを取り除くことで文脈長の一般化を狙うDroPE。
DroPEは「位置埋め込みを事前学習の誘導バイアスとして使い、学習後は外してしまう」という発想に基づく手法です。位置埋め込みを外した後は、元の事前学習データを用いた短いキャリブレーションを、元々の文脈長のままで実施します。
DroPEの仕組み
ここではDroPEがどのような仕組みで文脈長の一般化を行っているのかを解説します。
DroPEは単なる入力長の拡張ではなく、事前学習済みモデルをどう扱うかが重要です。
位置埋め込みを「学習用バイアス」として扱う設計
DroPEの基本的な前提は、位置埋め込みを事前学習時の補助情報としてのみ利用する点です。多くのLLMでは、RoPEなどの位置埋め込みがトークン順序を表現する役割を担ってきました。
一方でDroPEでは、事前学習が完了した段階でこの位置埋め込みをモデルから取り除きます。
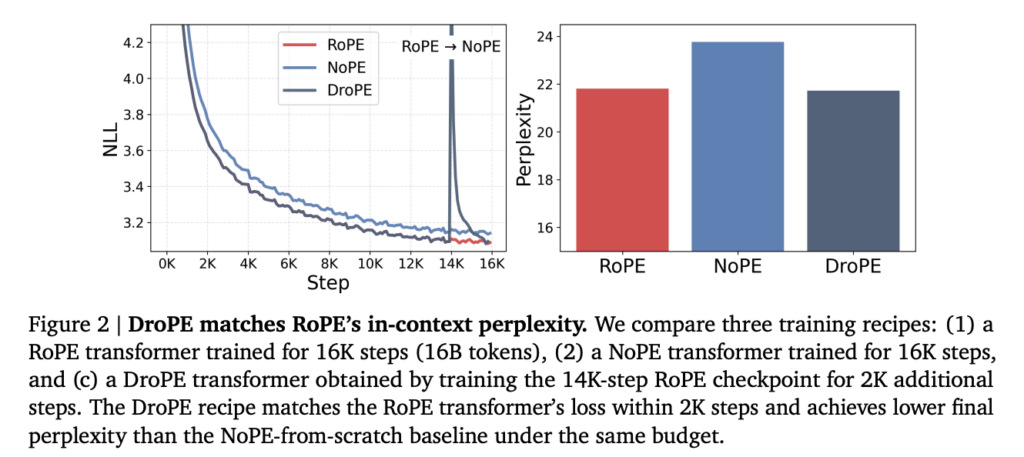
位置埋め込みを取り除くことで、一度性能は不安定になるため、後工程でキャリブレーションが必要になります。
学習後に行われるキャリブレーション工程
位置埋め込みを削除した直後のモデルは、そのままでは性能が安定しません。
そこでDroPEでは、元の事前学習データを用いた短時間のキャリブレーションを実施。この再学習は、事前学習と同じ文脈長のままで行われます。
再キャリブレーションの計算量は、全体の事前学習と比べてごくわずかであり、少量の追加学習で性能を回復させることが可能。


DroPEの特徴
DroPEは学習済みモデルに対して処理を行う手法です。ここではDroPEの特徴をいくつか解説します。
位置埋め込みを前提としない文脈長一般化
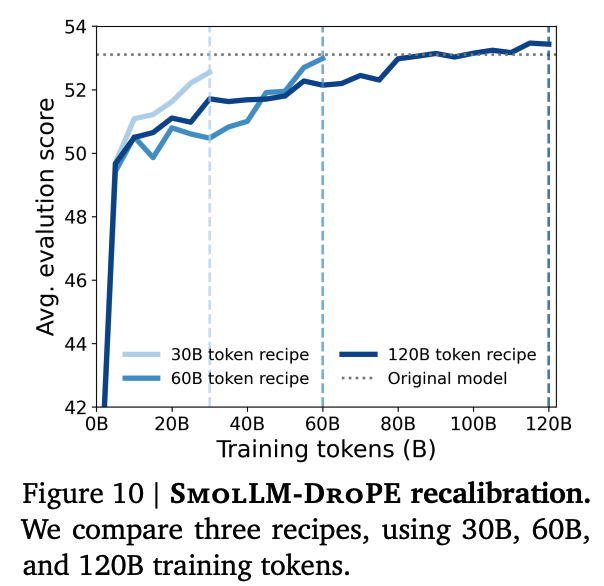
DroPE最大の特徴は、推論時に位置埋め込みを一切使用しない点です。
事前学習ではRoPEなどの位置情報を用いる一方で、学習後にそれを完全に取り除く設計がされています。この設計により、学習時に見ていないシーケンス長へのzero-shot一般化が成立。
その結果、ベンチマークでは、長い入力に対しても性能劣化が緩やかである傾向が見て取れます。
低コストな再キャリブレーション手法
DroPEでは、位置埋め込み削除後に事前学習と同じデータ分布・同じ文脈長で短時間の再キャリブレーションを行います。
大規模な再学習を必要とせず、計算コストは事前学習全体のごく一部。
既存モデルを活かしたまま適用できる点が大きな利点。
実運用を想定したときの現実的な選択肢として評価できる特徴です。
既存モデル構造を変更しない互換性
DroPEは、モデルアーキテクチャ自体を変更しない点も特徴的です。注意機構や層構成を作り替える必要はなく、調整対象は位置埋め込みの扱いに限定されています。
新規モデルをゼロから設計し直す必要がないことは、導入コストを大きく下げます。
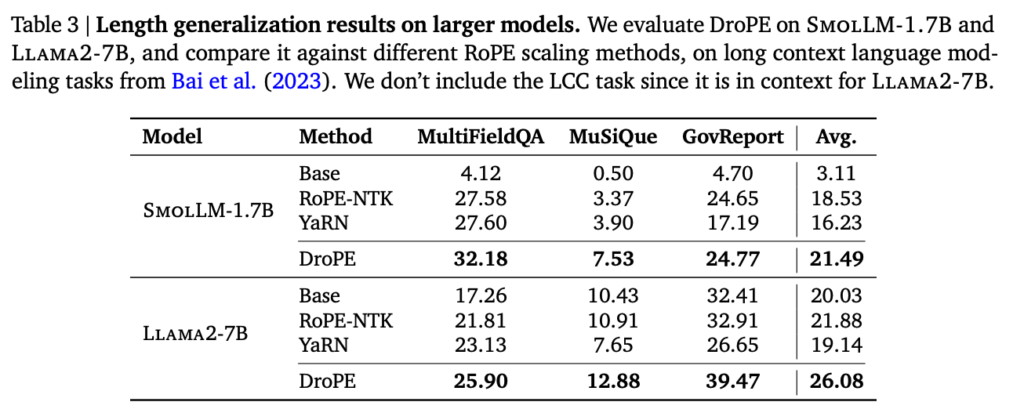
実際に異なるモデル規模にDroPEを後付けで適用した評価結果を、既存のRoPE拡張手法と比較したものが下記の表です。
DroPEの安全性・制約
ここでは、Extending the Context of Pretrained LLMs by Dropping Their Positional Embeddingsを参考にDroPEを利用する際に理解しておくべき制約や注意点を解説します。
セキュリティ・安全性に関する位置付け
DroPEは学習アルゴリズムおよびモデル設計に関する手法であり、セキュリティ機構そのものを提供するものではありません。
入力データの暗号化やアクセス制御、ログ管理といった仕組みについては、公式情報では明示されていません。
そのため、実運用では基盤となるLLMや実装環境側のセキュリティ設計に依存します。
位置情報を明示的に扱えない制約
DroPEでは、推論時に位置埋め込みを使用しない設計が採られています。
このため、トークンの絶対位置や厳密な順序情報が重要なタスクでは影響が出る可能性があります。
DroPEの料金
DroPE自体は特定のサービスやプロダクトとして提供されているものではなく、論文で提案された学習・再キャリブレーション手法であり、利用料金という概念は公式には設定されていません。
そのため、DroPEを使うこと自体に対して直接的な利用料が発生することはありません。
DroPEのライセンス
DroPEは論文として公開された学習手法であり、単体のソフトウェア製品ではありません。そのため、DroPE自体に対する独立した商用ライセンス条項は公式には提示されていません。
具体的な利用許諾条件や制限についても、詳細な記述は見当たりませんでした。
なお、SakanaAIのわずか15ドルでアイデア生成、実験、論文執筆をしてくれるAIであるAI-Scientistsについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

DroPEの実装方法
DroPEを使うためには、学習コードにアクセスできる必要があります。ローカル環境やクラウドGPUなどの環境にオープンウェイト・学習モデルをダウンロードし、DroPEを適用。
適用した後に再キャリブレーションを行うことで、DroPE適用モデルが出来上がり、このモデルを推論に使う、という流れになります。

GitHubに再キャリブレーション用の設定ファイルが用意されているモデルが書かれているので、こちらを使って実装してみたいと思います。
まずはGitHubからクローンします。
!git clone https://github.com/SakanaAI/DroPE drope
%cd dropeその後、必要ライブラリをインストール。
!python -m pip install --upgrade pip
!bash ./scripts/install.shインストールが完了したら!find cfgs/run_cfg -type f | grep -i smolで.yamlファイルを探します。
findの結果はこちら
cfgs/run_cfg/smollm2_1_7b_drope_qk_norm.yaml
cfgs/run_cfg/smollm2_1_7b_drope.yaml
cfgs/run_cfg/smollm_1_7b_drope_qk_norm.yaml
cfgs/run_cfg/smollm_1_7b_drope.yaml
cfgs/run_cfg/smollm_360m_drope.yaml
cfgs/run_cfg/smollm_360m_drope_qk_norm.yaml今回は最も容量の小さいsmollm_360m_drope_qk_norm.yamlを使っていきます。
サンプルコードはこちら
!./launch.sh 1 cfgs/run_cfg/smollm_360m_drope.yaml zero1 \
max_steps=100 \
per_device_train_batch_size=1 \
train_batch_size=1 \
gradient_accumulation_steps=1 \
report_to=none \
tf32=false \
model_args.attn_implementation=sdpa結果はこちら
12885
2026-01-14 07:33:28.850282: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:467] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
E0000 00:00:1768376009.135127 3140 cuda_dnn.cc:8579] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
E0000 00:00:1768376009.232457 3140 cuda_blas.cc:1407] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
W0000 00:00:1768376010.897423 3140 computation_placer.cc:177] computation placer already registered. Please check linkage and avoid linking the same target more than once.
W0000 00:00:1768376010.897490 3140 computation_placer.cc:177] computation placer already registered. Please check linkage and avoid linking the same target more than once.
W0000 00:00:1768376010.897499 3140 computation_placer.cc:177] computation placer already registered. Please check linkage and avoid linking the same target more than once.
W0000 00:00:1768376010.897505 3140 computation_placer.cc:177] computation placer already registered. Please check linkage and avoid linking the same target more than once.
2026-01-14 07:33:30.944739: I tensorflow/core/platform/cpu_feature_guard.cc:210] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
[2026-01-14 07:33:42,802][__main__][INFO] - Configuration:
save_strategy: steps
save_steps: 50
push_to_hub: false
tags: null
eval_strategy: 'no'
eval_steps: null
per_device_train_batch_size: 1
vllm_gpu_memory_utilization: 0.3
vllm_mode: colocate
logging_strategy: steps
logging_steps: 5
report_to: none
wandb_project: drope
wandb_group_name: ${data_log_name}/${model_log_name}
wandb_run_name: ${trainer_log_name}_${model_log_name}_${max_steps}steps_lr${learning_rate}
results_dir: results
exp_name: ${now:%Y.%m.%d}${now:%H%M%S}
output_dir: ${results_dir}/${wandb_group_name}/${wandb_run_name}/${exp_name}
call_post_training: null
resume_from: null
seed: 42
model_log_name: smollm360m
model_name_or_path: HuggingFaceTB/SmolLM-360M
tokenizer_name_or_path: ${model_name_or_path}
model_args:
_target_: hydra_utils.trl.ModelConfig
model_name_or_path: ${model_name_or_path}
trust_remote_code: true
use_peft: ${use_peft}
load_in_4bit: ${load_in_4bit}
model_revision: main
torch_dtype: bfloat16
attn_implementation: sdpa
use_peft: false
load_in_4bit: false
model_custom_config:
_target_: custom_models.drope.DroPELlamaConfig.from_pretrained
pretrained_model_name_or_path: ${model_name_or_path}
attention_type: nope
tokenizer:
_target_: hydra_utils.transformers.AutoTokenizer.from_pretrained
pretrained_model_name_or_path: ${tokenizer_name_or_path}
trust_remote_code: true
model_revision: ${model_args.model_revision}
force_override_pad_token: false
make_tokenizer_fn:
_target_: hydra_utils.fix_pad_token
tokenizer: ${tokenizer}
model_name: ${model_name_or_path}
force_override_pad_token: true
generate_compatible_tokenizer: false
peft_config:
_target_: hydra_utils.trl.get_peft_config
model_args: ${model_args}
data_log_name: fineweb_edu_shuffled
dataset_id_or_path: PrimeIntellect/fineweb-edu
dataset_local_directory: ${dataset_id_or_path}
dataset_configuration: null
make_dataset_fn:
dataset_id_or_path: ${dataset_id_or_path}
dataset_local_directory: ${dataset_local_directory}
name: ${dataset_configuration}
_target_: custom_data.pretraining_data.load_pretraining_dataset
dataset_config_name: ${dataset_configuration}
max_seq_length: ${max_seq_length}
manually_add_eos: ${manually_add_eos}
validation_split_percentage: ${validation_split_percentage}
streaming: ${streaming}
do_train: ${do_train}
do_eval: ${do_eval}
load_dataset_kwargs: ${load_dataset_kwargs}
skip_samples: ${data_skip_samples}
preprocessing_num_workers: ${data_preprocessing_num_workers}
attention_implementation: ${model_args.attn_implementation}
mask_past_sequences: ${mask_past_sequences}
validation_split_percentage: null
trust_remote_code: true
streaming: true
load_dataset_kwargs: null
data_skip_samples: null
manually_add_eos: true
mask_past_sequences: false
data_preprocessing_num_workers: 52
custom_class: custom_models.drope.DroPELlamaForCausalLM
from_pretrained: true
drope: true
loaded_model:
_target_: hydra_utils.load_model
model_args: ${model_args}
config: ${model_custom_config}
custom_class: ${custom_class}
from_pretrained: ${from_pretrained}
drope: ${drope}
max_steps: 100
num_train_epochs: 1
train_batch_size: 1
gradient_accumulation_steps: 1
gradient_checkpointing: true
gradient_checkpointing_kwargs:
_target_: builtins.dict
use_reentrant: false
learning_rate: 0.0003
weight_decay: 0
adam_beta1: 0.9
adam_beta2: 0.999
adam_epsilon: 1.0e-08
max_grad_norm: 1.0
lr_scheduler_type: constant
lr_scheduler_kwargs: null
warmup_ratio: 0.1
bf16: true
tf32: false
ddp_timeout: 180000000
torch_compile: false
do_train: true
do_eval: true
save_final_model: true
trainer_log_name: trainer
trainer_args:
_target_: hydra_utils.transformers.TrainingArguments
output_dir: ${output_dir}
max_steps: ${max_steps}
num_train_epochs: ${num_train_epochs}
per_device_train_batch_size: ${per_device_train_batch_size}
gradient_accumulation_steps: ${gradient_accumulation_steps}
gradient_checkpointing: ${gradient_checkpointing}
gradient_checkpointing_kwargs: ${gradient_checkpointing_kwargs}
learning_rate: ${learning_rate}
weight_decay: ${weight_decay}
adam_beta1: ${adam_beta1}
adam_beta2: ${adam_beta2}
adam_epsilon: ${adam_epsilon}
max_grad_norm: ${max_grad_norm}
lr_scheduler_type: ${lr_scheduler_type}
lr_scheduler_kwargs: ${lr_scheduler_kwargs}
warmup_ratio: ${warmup_ratio}
logging_strategy: ${logging_strategy}
logging_steps: ${logging_steps}
save_strategy: ${save_strategy}
save_steps: ${save_steps}
report_to: ${report_to}
run_name: ${wandb_run_name}
bf16: ${bf16}
tf32: ${tf32}
torch_compile: ${torch_compile}
seed: ${seed}
ddp_timeout: ${ddp_timeout}
do_train: ${do_train}
do_eval: ${do_eval}
eval_strategy: ${eval_strategy}
eval_steps: ${eval_steps}
dataloader_num_workers: ${dataloader_num_workers}
dataloader_prefetch_factor: ${dataloader_prefetch_factor}
accelerator_config: ${trainer_accelerator_config}
trainer:
_target_: hydra_utils.transformers.Trainer
model: ${loaded_model}
args: ${trainer_args}
max_seq_length: 2048
dispatch_batches: false
trainer_accelerator_config:
_target_: builtins.dict
dispatch_batches: ${dispatch_batches}
dataloader_num_workers: 4
dataloader_prefetch_factor: 2
[2026-01-14 07:33:42,802][__main__][INFO] - Accumulation steps 1 ----
[2026-01-14 07:33:43,000][numexpr.utils][INFO] - NumExpr defaulting to 2 threads.
[2026-01-14 07:33:43,247][datasets][INFO] - TensorFlow version 2.19.0 available.
[2026-01-14 07:33:43,248][datasets][INFO] - JAX version 0.7.2 available.
tokenizer_config.json: 3.69kB [00:00, 15.9MB/s]
vocab.json: 801kB [00:00, 36.6MB/s]
merges.txt: 466kB [00:00, 113MB/s]
tokenizer.json: 2.10MB [00:00, 154MB/s]
special_tokens_map.json: 100% 831/831 [00:00<00:00, 6.30MB/s]
config.json: 100% 725/725 [00:00<00:00, 2.54MB/s]
2026-01-14 07:33:49.148369: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:467] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
E0000 00:00:1768376029.167620 3334 cuda_dnn.cc:8579] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
E0000 00:00:1768376029.174702 3334 cuda_blas.cc:1407] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
W0000 00:00:1768376029.193184 3334 computation_placer.cc:177] computation placer already registered. Please check linkage and avoid linking the same target more than once.
W0000 00:00:1768376029.193221 3334 computation_placer.cc:177] computation placer already registered. Please check linkage and avoid linking the same target more than once.
W0000 00:00:1768376029.193225 3334 computation_placer.cc:177] computation placer already registered. Please check linkage and avoid linking the same target more than once.
W0000 00:00:1768376029.193230 3334 computation_placer.cc:177] computation placer already registered. Please check linkage and avoid linking the same target more than once.
INFO:2026-01-14 07:33:56,818:jax._src.xla_bridge:822: Unable to initialize backend 'tpu': INTERNAL: Failed to open libtpu.so: libtpu.so: cannot open shared object file: No such file or directory
[2026-01-14 07:33:56,818][jax._src.xla_bridge][INFO] - Unable to initialize backend 'tpu': INTERNAL: Failed to open libtpu.so: libtpu.so: cannot open shared object file: No such file or directory
README.md: 100% 259/259 [00:00<00:00, 2.05MB/s]
Resolving data files: 100% 11988/11988 [00:00<00:00, 39503.19it/s]
Resolving data files: 100% 11988/11988 [00:00<00:00, 41472.21it/s]
[2026-01-14 07:34:04,549][custom_data.pretraining_data][INFO] - Grouping data batches into block size (i.e., sequence size) of 2048
Downloading builder script: 4.20kB [00:00, 15.0MB/s]
You are using a model of type llama to instantiate a model of type llama_drope. This is not supported for all configurations of models and can yield errors.
`torch_dtype` is deprecated! Use `dtype` instead!
model.safetensors: 100% 1.45G/1.45G [00:10<00:00, 140MB/s]
generation_config.json: 100% 111/111 [00:00<00:00, 595kB/s]
[2026-01-14 07:34:17,516][root][INFO] - x86_64-linux-gnu-gcc -fno-strict-overflow -Wsign-compare -DNDEBUG -g -O2 -Wall -g -fstack-protector-strong -Wformat -Werror=format-security -g -fwrapv -O2 -fPIC -c /tmp/tmpe2t_vyp6/test.c -o /tmp/tmpe2t_vyp6/test.o
[2026-01-14 07:34:17,561][root][INFO] - x86_64-linux-gnu-gcc /tmp/tmpe2t_vyp6/test.o -laio -o /tmp/tmpe2t_vyp6/a.out
[2026-01-14 07:34:17,958][root][INFO] - x86_64-linux-gnu-gcc -fno-strict-overflow -Wsign-compare -DNDEBUG -g -O2 -Wall -g -fstack-protector-strong -Wformat -Werror=format-security -g -fwrapv -O2 -fPIC -c /tmp/tmpzv4y2y1c/test.c -o /tmp/tmpzv4y2y1c/test.o
[2026-01-14 07:34:17,979][root][INFO] - x86_64-linux-gnu-gcc /tmp/tmpzv4y2y1c/test.o -L/usr/local/cuda -L/usr/local/cuda/lib64 -lcufile -o /tmp/tmpzv4y2y1c/a.out
[2026-01-14 07:34:18,036][root][INFO] - x86_64-linux-gnu-gcc -fno-strict-overflow -Wsign-compare -DNDEBUG -g -O2 -Wall -g -fstack-protector-strong -Wformat -Werror=format-security -g -fwrapv -O2 -fPIC -c /tmp/tmpotfe01s4/test.c -o /tmp/tmpotfe01s4/test.o
[2026-01-14 07:34:18,054][root][INFO] - x86_64-linux-gnu-gcc /tmp/tmpotfe01s4/test.o -laio -o /tmp/tmpotfe01s4/a.out
[2026-01-14 07:34:20,839][__main__][INFO] - No existing checkpoint, initializing new model
[2026-01-14 07:34:20,839][__main__][INFO] - Training 2026-01-14 07:34:20.839600
/usr/local/lib/python3.12/dist-packages/torch/utils/data/dataloader.py:627: UserWarning: This DataLoader will create 4 worker processes in total. Our suggested max number of worker in current system is 2, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
warnings.warn(
Before initializing optimizer states
MA 2.02 GB Max_MA 2.02 GB CA 2.02 GB Max_CA 2 GB
CPU Virtual Memory: used = 4.9 GB, percent = 38.7%
After initializing optimizer states
MA 2.02 GB Max_MA 3.37 GB CA 3.37 GB Max_CA 3 GB
CPU Virtual Memory: used = 4.9 GB, percent = 38.7%
After initializing ZeRO optimizer
MA 2.02 GB Max_MA 2.02 GB CA 3.37 GB Max_CA 3 GB
CPU Virtual Memory: used = 4.9 GB, percent = 38.7%
0% 0/100 [00:00<?, ?it/s]/usr/lib/python3.12/multiprocessing/popen_fork.py:66: RuntimeWarning: os.fork() was called. os.fork() is incompatible with multithreaded code, and JAX is multithreaded, so this will likely lead to a deadlock.
self.pid = os.fork()
`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`.
{'loss': 5.8272, 'grad_norm': 4.760720729827881, 'learning_rate': 0.0003, 'epoch': 0.05}
{'loss': 5.2858, 'grad_norm': 3.156913995742798, 'learning_rate': 0.0003, 'epoch': 0.1}
{'loss': 5.093, 'grad_norm': 2.826110363006592, 'learning_rate': 0.0003, 'epoch': 0.15}
{'loss': 5.0107, 'grad_norm': 2.292070150375366, 'learning_rate': 0.0003, 'epoch': 0.2}
{'loss': 5.1278, 'grad_norm': 2.2938857078552246, 'learning_rate': 0.0003, 'epoch': 0.25}
{'loss': 4.8992, 'grad_norm': 1.8960566520690918, 'learning_rate': 0.0003, 'epoch': 0.3}
{'loss': 4.9434, 'grad_norm': 2.3043885231018066, 'learning_rate': 0.0003, 'epoch': 0.35}
{'loss': 4.8869, 'grad_norm': 3.0603528022766113, 'learning_rate': 0.0003, 'epoch': 0.4}
{'loss': 5.1166, 'grad_norm': 2.1547794342041016, 'learning_rate': 0.0003, 'epoch': 0.45}
{'loss': 5.0435, 'grad_norm': 1.8623450994491577, 'learning_rate': 0.0003, 'epoch': 0.5}
50% 50/100 [03:33<03:13, 3.86s/it]50%くらいまでは進むのですが、そこから先は全く進みませんでした。容量の少ないモデルで試してみたのですが、やはりgoogle colaboratoryでは限界があるようです。
実行した時のgoogle colaboratory環境は下記です。
システム RAM:11.6 / 12.7 GB
GPU RAM:10.6 / 15.0 GB
ディスク:55.1 / 112.6 GB
プラン:無料
GPT:T4
DroPEの活用シーン
ここでは、DroPEの特性を踏まえて想定される活用シーンを考えてみます。
長文QAやドキュメント理解への応用
DroPEは、未学習の文脈長に対してzero-shotで一般化できる点が特徴です。この特徴から、大量の技術文書や契約書を一度に扱うQAタスクでの活用が考えられます。
入力を分割せずに処理できれば、文脈の断絶による性能低下を抑えられます。特に、文書全体を俯瞰した理解が求められる場面で有効でしょう。
長期依存を伴う生成タスク
物語生成や長編レポート作成など、長い依存関係を維持する生成タスクも活用できそうです。
DroPEでは、入力長の増加に対して性能劣化が緩やかです。このため、途中の情報を忘れにくい生成挙動が期待されます。
従来は分割生成が必要だったケースでも、一貫した出力が可能になるかもしれません。創作や分析レポート用途での可能性が広がります。
既存モデル資産を活かした拡張的活用
DroPEは、既存の事前学習済みモデルを前提としています。そのため、新規モデル開発を行わずに文脈長対応を拡張できます。
これは、すでにモデル運用基盤を持つ組織にとって大きなメリットです。再学習コストを抑えながら性能検証が可能になります。
なお、日本語特化モデル最大級の700億パラメーターLLMであるELYZA-japanese-Llama-2-70bについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

まとめ
本記事ではDroPEの概要から仕組み、実際の使い方について解説をしました。
DroPEを実際に使うには、ローカル環境もしくはクラウドGPU上で学習データにアクセスできる必要があり、手軽に誰でも利用できるものではありません。
しかし、学習データにアクセスできる場合には、短時間でコンテキスト長を拡張することができるので、環境が整っている方はぜひ活用してみてください。

最後に
いかがだったでしょうか?
DroPEのような先進的なLLM研究は、長文処理や高度な情報理解が求められる業務において、大きな可能性を秘めています。
一方で、実務に落とし込むためには、自社環境に適したモデル選定や設計、運用までを見据えた検討が欠かせません。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。


