
高速な文章生成を実現する日本語拡散言語モデル「ELYZA-LLM-Diffusion」を徹底解説!

- 東京大学松尾研発のスタートアップELYZA社が公開した、日本語特化の新しい大規模言語モデル
- これまで主流だった自己回帰型(AR)とは異なる拡散モデルの手法をテキスト生成に応用
- より少ないステップで文章を生成でき、高速化や消費電力削減が期待されている
2026年1月16日、東京大学松尾研発のスタートアップであるELYZA社が、日本語特化の新しい大規模言語モデル「ELYZA-LLM-Diffusion」を公開しました!
このモデルの最大の特徴は、これまで主流だった自己回帰型(AR)とは異なる拡散モデルの手法をテキスト生成に応用している点です。
拡散モデルは、本来画像生成AIで発展した技術で、テキストを左から右へ順番に生成せずに、ノイズから徐々に文章を生成します。
そのため、より少ないステップで文章を生成でき、高速化や消費電力削減が期待されています。ELYZA-LLM-Diffusionは、この拡散型アプローチで日本語での知識応答や対話能力を高めたモデルで、商用利用も可能なオープンな形で提供されています。
そこで本記事では、ELYZA-LLM-Diffusionの概要や性能、使い方まで徹底的に解説します。
ぜひ最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
ELYZA-LLM-Diffusionの概要

ELYZA-LLM-Diffusionは、日本語に特化して性能を高めた拡散大規模言語モデル(dLLM)のシリーズです。
従来の自己回帰(AR)モデルでは、文章を先頭から一方向に生成するため、途中で言葉の修正や追記ができないという制限がありました。
一方、本モデルが採用する拡散モデルでは、文章全体をマスクした状態から徐々にトークンを書き換えていくことで、自由度の高いテキスト生成を可能にしています。
例えば、人が長文を考える際に重要なフレーズから書き始めることがあるように、拡散モデルでは文章の途中からでも一気に内容を埋めていける点が特徴です。
ELYZA-LLM-Diffusionは、香港大学HKU NLPグループが公開していたオープンソースの拡散LM「Dream-7B (Dream-v0-Instruct-7B)」をベースモデルに採用しています。
このベースに対して、約620億トークンもの日本語コーパスで追加事前学習を行い、日本語の知識を大幅に強化しました。
さらに、その日本語適応モデルを元に、約1.8億トークン規模の日本語データでInstructionチューニング(指示調整)を施し、指示への応答性能や対話能力を高めたのが「ELYZA-Diffusion-Instruct-1.0-Dream-7B」です。
一方、指示チューニングを行っていない追加学習のみのモデルは「ELYZA-Diffusion-Base-1.0-Dream-7B」として公開されています。モデルのパラメータ数はいずれも約70億(7B)規模で、日本語拡散LMとしては初の商用利用可能なオープンモデルとなっています。

本モデル公開の背景には、生成AIの普及による電力消費の増大問題があります。
自己回帰型LLMは、長文生成時にステップ数(推論回数)が多く時間と電力を要するため、より効率的な生成手法が求められていました。拡散モデルは、設計次第で同じ長さの文章でも推論ステップ数を大幅に削減できる可能性があり、将来的に高速かつ省電力なLLM実現への鍵として注目されています。
なお、Google発の拡散モデルについて詳しく知りたい方は、以下の記事も参考にしてみてください。

ELYZA-LLM-Diffusionの性能
ELYZA-LLM-Diffusionシリーズの性能について、ELYZA社は各種ベンチマークで詳細な評価を実施しています。評価は日本語での知識応答や対話品質、プログラミング能力、数学的推論能力など多岐にわたっています。
こうした幅広いタスクで、ELYZA-Diffusion-Instruct-1.0-Dream-7を既存モデルと比較した結果、日本語の一般的な知識問答や対話品質において、同種の拡散モデルよりも高い性能を出しているそうです。
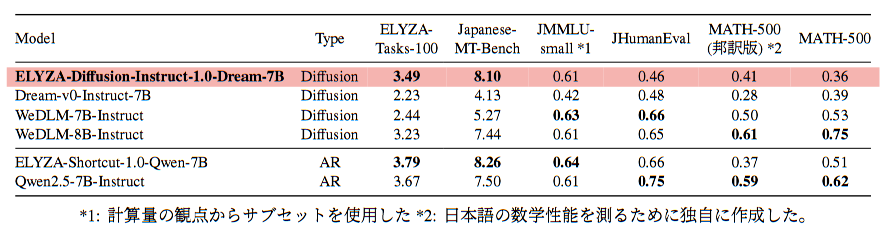
例えば、日本語指示応答の総合ベンチマークでは、本モデルが他の拡散LM(Dream 7BやWeDLM 7B/8Bなど)を上回るスコアを記録しており、2026年1月時点で日本語拡散モデル中トップクラスの性能と言えます。
一方で、最新の自己回帰型モデル(ELYZA社が別途日本語特化しているQwenベースの7Bモデルなど)と比較すると、一部のベンチマークで若干スコアが下回る結果も報告されています。
これは、拡散モデルとARモデルの構造上の差や、ベースにした事前モデルの性能差に起因すると考えられていて、今後の改良で詰めていくべき課題とも言えそうです。


ELYZA-LLM-Diffusionのライセンス
ELYZA-LLM-DiffusionのライセンスはApache License 2.0です。
Apache 2.0は、オープンソースソフトウェアで広く使われるライセンスで、商用プロダクトへの組み込みや改変・再配布などが自由に許可されています。
| 利用用途 | 可否 | 備考 |
|---|---|---|
| 商用利用 | ⭕️ | |
| 改変 | ⭕️ | |
| 配布 | ⭕️ | |
| 特許使用 | ⭕️ | |
| 私的使用 | ⭕️ |
ELYZA-LLM-Diffusionの料金
ELYZA-LLM-Diffusionはオープンソース公開モデルのため、基本的に利用料は一切かかりません。
モデルデータ自体はHugging Face上で無償提供されており、ライセンスも前述の通り商用含め自由利用可能なので、ソフトウェアとしての料金は発生しません。


ELYZA-LLM-Diffusionの使い方
LYZA-LLM-Diffusionの利用方法として、①ブラウザ上のデモを使う方法と②ローカル環境でモデルを動かす方法の2通りがあります。
①デモ利用
まずは、ELYZA社が公開しているHugging Face Spaces上のデモを利用する方法がおすすめです。
デモページにブラウザでアクセスします。ログインや環境構築は特に必要ありません。
ページが表示されたら、画面左側の入力ボックスにモデルに投げかけたい質問や指示を日本語で入力します。例えば「日本史に関する面白い豆知識を教えてください。」のような質問でも構いません。
入力ができたら「Send」ボタンをクリックします。
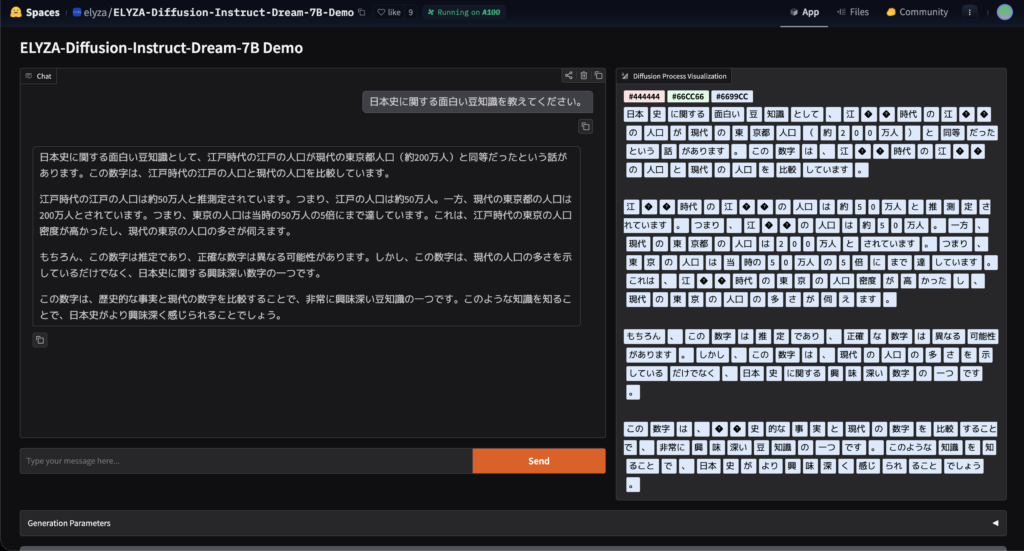
こちらのページ上だと、文章全体がマスクされた状態から徐々に単語が埋まっていく様子が可視化されます。
各ステップで、[MASK]トークンが日本語単語に置き換わっていく様子が色分けされて表示され、リアルタイムで文章が精緻化されていくビジュアルが確認できるので、一度試していただくとおもしろいと思います。
②ローカル環境での利用
自分のPCやサーバー上でモデルを動かす場合、Hugging Faceのモデルリポジトリから重みデータをダウンロードし、Transformersライブラリ経由で読み込むのが基本になります。
まず環境として、Python (3.8以上推奨) とPyTorch、Transformersライブラリを用意します。GPU上での実行が望ましいため、CUDA対応の環境をご用意ください。
pip install torch transformers accelerate続いて、Hugging Faceからモデルをロードします。
モデル名は、elyza/ELYZA-Diffusion-Instruct-1.0-Dream-7Bです。読み込み時にtrust_remote_code=Trueを指定する点がポイントで、これによりモデル固有のカスタムコード(拡散による生成処理など)が正しく適用されます。
import torch
from transformers import AutoModel, AutoTokenizer
model_path = "elyza/ELYZA-Diffusion-Instruct-1.0-Dream-7B"
model = AutoModel.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
trust_remote_code=True
).to("cuda").eval()
tokenizer = AutoTokenizer.from_pretrained(
model_path,
trust_remote_code=True
)指示チューニング済みモデルは、ChatGPTのようなメッセージ形式で入力を与える仕様になっています。
そのため、ユーザからの質問や指示を適切なテンプレートに当てはめる必要があります。ELYZA公式が提供しているapply_chat_template関数を使うと簡単で、以下のようにメッセージをリストで用意します。
messages = [
{"role": "user", "content": "家事のモチベーションをアップするためのアイデアを5つ挙げてください。"}
]
inputs = tokenizer.apply_chat_template(
messages,
return_tensors="pt",
add_generation_prompt=True
)
input_ids = inputs.input_ids.to("cuda")
attention_mask = inputs.attention_mask.to("cuda")準備した入力IDとマスクをモデルに与えて推論(文章生成)を実行します。拡散モデル特有のメソッドであるdiffusion_generateを呼び出し、生成ステップ数や温度パラメータを指定します。
例えば、最大512トークン生成、拡散ステップ数256で出力する場合、以下のようにします。
with torch.no_grad():
output = model.diffusion_generate(
input_ids,
attention_mask=attention_mask,
max_new_tokens=512,
steps=256,
temperature=0.5,
top_p=0.95,
alg="entropy",
alg_temp=0.5
)
generated_text = tokenizer.decode(
output.sequences[0][input_ids.size(1):],
skip_special_tokens=True
)
print(generated_text)diffusion_generateでは、通常の自己回帰モデルのgenerateと異なり生成ステップ数 (steps) を明示的にコントロールできます。既定では256ステップですが、短縮することで高速化が可能です。
公式によると、ステップ数を最大8倍まで削減する場合はtemperatureやalg_tempを0.5以上に高めに設定し、多様性と安定性を保つことが推奨されています。
tokenizer.decodeでトークン列を日本語テキストに変換し、最終的な生成結果を確認します。
以上のコードを実行すると、指定した質問に対するモデルの回答テキストが表示されます。あとは通常のPython文字列として扱えるので、コンソール出力したり、アプリケーションに組み込んで表示させたりすることもできます。
ELYZA-LLM-Diffusionを使ってみた
それでは実際に、ELYZA-LLM-Diffusionをデモサイト上で試していきます。
次の文章の [MASK] を、文脈に合う自然な日本語で埋めてください。
語調(ですます)と論理のつながりを崩さないこと。
文章:
『本プロジェクトでは、社内SaaSの利用定着を目的に、[MASK]を最優先で設計します。
具体的には、日々の業務フローに自然に溶け込むよう[MASK]を用意し、利用状況は[MASK]で可視化します。
加えて、問い合わせ対応を減らすため[MASK]を整備し、運用コストの抑制につなげます。』それぞれ別々かつ適切なワードで穴埋めをしてくれました。生成スピードも申し分ないです。
次の文章に、指定した要件を満たす1段落を『ここに追記』の位置へ挿入してください。
挿入後、前後のつながりが自然になるように必要最小限の調整もしてOK(ですます調)。
要件:『なぜ拡散型が高速化に効くのか』を、比喩1つ+技術的説明1つで短く。
文章:
『ELYZA-LLM-Diffusionは拡散モデルをテキスト生成に応用した言語モデルです。
(ここに追記)
そのため、推論ステップ数の設計次第で生成効率の改善が期待できます。』こちらも最適な位置に比喩表現と説明文の追記、前後のつながりを加味した最小限の調整までしてくれました。「絵のきでいうと」の部分が絵の具のことを指しているんですかね。ここだけ惜しいポイントでした。
他にも文章全体のリライトや、制約条件の多いケースにおける破綻しない文章生成でも活用できるかと思いますので、ぜひ一度試してみてください。
まとめ
ELYZA-LLM-Diffusionは、日本語に特化して性能を高めた拡散大規模言語モデルです。
高速なテキスト生成と効率化という利点を持ちながら、7Bという比較的小型なモデルで日本語の理解・応答性能を高い水準にまで引き上げられているのが素晴らしいですよね。
画像生成AIで用いられる拡散技術を言語分野に応用することで、次世代アーキテクチャの可能性がグッと広げられたと思います。
気になる方はぜひ一度試してみてください!

最後に
いかがだったでしょうか?
弊社では、AI導入を検討中の企業向けに、業務効率化や新しい価値創出を支援する情報提供・導入支援を行っています。最新のAIを活用し、効率的な業務改善や高度な分析が可能です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。


