
「もうPhotoshopはいらない?」Googleの『Nano Banana(Gemini 2.5 Flash Image)』が変える画像編集の未来を徹底解説
-3.webp)
- Google発の最新の画像生成AIモデル
- 高品質・低遅延で生成と精密編集、合成や人物一貫性も強化されている
- AI Studio・API・Vertexから簡単に利用でき、既存ワークフローにも組み込みやすい
2025年8月27日、Google DeepMindは新たな画像生成AIモデル「Nano Banana(Gemini 2.5 Flash Image)」を発表しました!
このモデルはテキストで指示を与えるだけで、高品質な画像の生成や既存画像の編集を行える最先端のAIです。従来モデルの低遅延かつ低コストな強みはそのままに、画像の合成や細部の編集、キャラクターの一貫性維持などクリエイティブな制御能力が大幅に向上しています。
開発コードネーム「Nano Banana」として、事前の評価サイトで話題を呼んでいたこのモデルは、正式名称とともに公開され、生成AI界隈で大きな注目を集めています。
本記事では、Nano Banana(Gemini 2.5 Flash Image)の概要や性能、使い方まで徹底的に解説します。
ぜひ最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
Nano Banana(Gemini 2.5 Flash Image)の概要
Nano Banana(Gemini 2.5 Flash Image)は、Googleの次世代AIであるGeminiファミリーにおける画像生成・編集専用のモデルです。ユーザーはテキストプロンプトを入力するだけで、新たな画像の生成や既存の画像の編集が可能です。
たとえば、数枚の画像を融合して単一の新しい画像を作り出すことや、キャラクターの外見を変えずに別シーンに登場させること、画像内の特定オブジェクトだけを差し替える精密な編集など、多彩な機能を備えています。さらに、Geminiモデルならではの世界知識を活かし、写真に写った文字や図形を理解して編集することも可能になっているとのこと。


本モデルは、今年前半に登場したGemini 2.0 Flashの後継となります。前バージョンは、応答の低レイテンシーやコストの安さ、使いやすさが好評なモデルでしたが、巷では「画像のクオリティをもっと向上させてほしい」「編集の自由度を高めてほしい」といった声があがっていました。
Nano Banana(Gemini 2.5 Flash Image)は、こうした声に応えて、出力画像の解像感・精細さの向上や高度な編集コントロールを実現しているようです。実際、写真のようにリアルな質感からアニメ風のスタイルまで幅広く対応し、複雑な指示に対しても論理的に破綻しない画像を生成できる柔軟性を備えています。


Nano Banana(Gemini 2.5 Flash Image)の特徴
Nano Banana(Gemini 2.5 Flash Image)はこれまでの画像生成とは一味違った特徴がいくつかあります。ここではNano Banana(Gemini 2.5 Flash Image)の特徴についてご紹介します。
画像生成AIとして高い性能
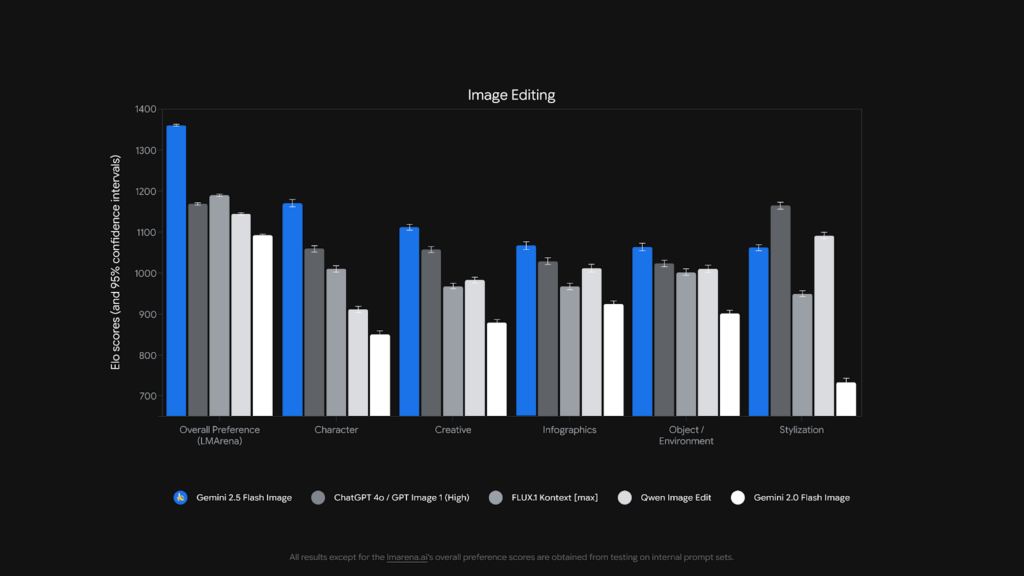
上記はNano Banana(Gemini 2.5 Flash Image)の性能グラフとそのほかの画像生成AIを比較した画像です。
グラフを見てもわかるように、全体を通して、Nano Banana(Gemini 2.5 Flash Image)の性能グラフの性能が高いことがわかります。特にCharacter:キャラクター表現力は飛び抜けており、人物編集(顔、ポーズ、自然さ)が得意と言えます。
一貫性のある画像出力
Nano Banana(Gemini 2.5 Flash Image)はCharacter:キャラクター表現力に秀でており、生成する画像内の人物や構図などに一貫性を持たせて画像を生成することが可能です。
従来の画像生成AIでは、生成するたびに人物や背景が微妙に変わってしまうことが多々ありましたが、Nano Banana(Gemini 2.5 Flash Image)では人物や背景などを統一することができます。
プロンプト指示理解の高さ
また、Nano Banana(Gemini 2.5 Flash Image)はプロンプトの指示理解能力も高く、ユーザーの指示を的確に理解をしてくれます。
例えば、下記のようなプロンプトを入力した際の画像がこちら。
以下の内容に沿って画像を生成してください。
日本の高校生男女2名が制服を着て、楽しそうに入学式に向かっている最中、桜並木続く川沿いで後ろから撮影した時の写真
いや、すごいですよね、かなり忠実にプロンプトに従ってくれています。
Nano Banana(Gemini 2.5 Flash Image)の性能
Nano Banana(Gemini 2.5 Flash Image)の性能は現行トップクラスであり、さまざまなベンチマークで最先端の実力を示しています。Googleによると、本モデルは画像生成・編集の両面で最先端(state-of-the-art)の精度を達成し、しかも他の主要モデルより応答が高速(低レイテンシー)です。
実際、AIモデルの評価サイトLMArenaにおける画像編集部門のランキングでは、“nano-banana”という匿名でテストされ堂々の1位に輝いています。これは第2位以下のモデル(FluxやGPT Imageなど)を大きく引き離す高いスコアであり、現時点で本モデルの性能の高さが人間の評価によって裏付けられています。
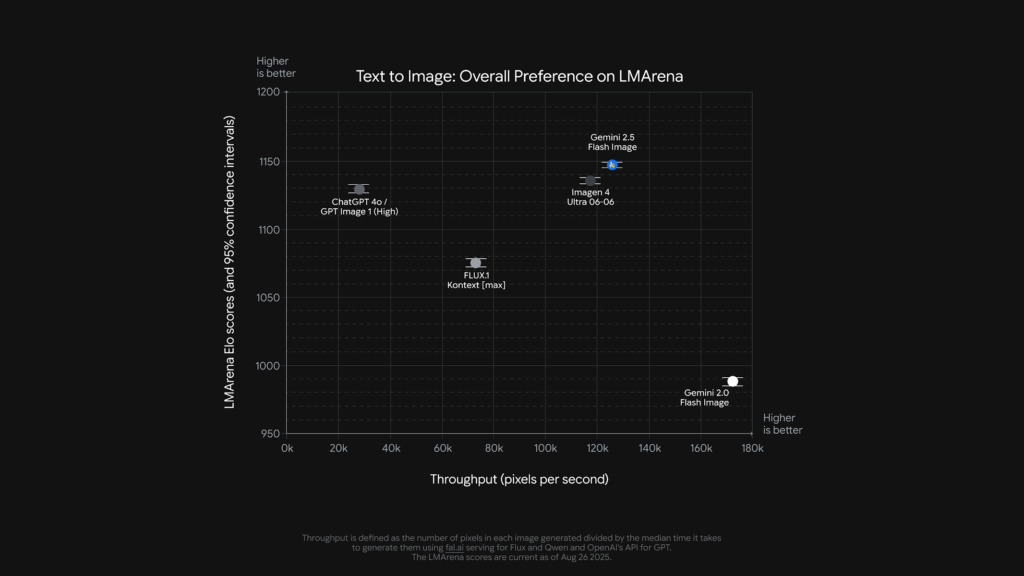
特に優れている点は、画像の細部や文脈をしっかり保ったまま編集を加えられることです。他の画像AIでは難しい「人物のシャツの色だけ変えて顔はそのまま」などの細かな修正も、Nano Banana(Gemini 2.5 Flash Image)なら自然にこなします。
例えば人や動物の顔立ち・表情の一貫性を保ちながら背景だけ変更したり、小物を付け足したりといった高度な編集も得意です。Googleは「本モデルはLMArenaを含む複数のベンチマークで最先端の結果を示している」と述べており、実際その言葉通り画像の画質・忠実さと指示への追従性が非常に高い水準にあります。「我々は視覚的品質と指示遵守能力を大きく前進させた」との開発者のコメントからも、本モデルの完成度の高さがうかがえます。
Nano Banana(Gemini 2.5 Flash Image)のライセンス
Nano Banana(Gemini 2.5 Flash Image)は、商用利用も可能な形で提供されています。ただしモデルそのものはオープンソースではなく、あくまでGoogleのクラウドサービス経由でアクセスする形態です。そのため、利用にあたってはGoogleの利用規約やAIポリシーに従う必要があります。
2025年8月27日時点では、プレビュー提供のため、Google Cloudの「Pre-GA利用規約」に準拠した扱いとなっており、生成物を商用プロジェクトで使用したり第三者に提供したりすることも認められています。一方でモデルの重みデータそのものは公開されていないため、モデル自体を改変・再配布することは許可されていません。以下の表に主要なライセンス面のポイントをまとめます。
| 利用用途 | 可否 | 備考 |
|---|---|---|
| 商用利用 | ⭕️ | |
| 改変 | ❌️ | モデル提供元でのみ改良可能 |
| 配布 | ❌️ | モデルそのものは非公開 |
| 特許使用 | ❌️ | モデル利用に特許実施権は付随しない |
| 私的使用 | ⭕️ |
Nano Banana(Gemini 2.5 Flash Image)の商用利用について
2025年9月にNano Banana(Gemini 2.5 Flash Image)の商用利用条件について発表されました。※1
広告利用などの商用利用でNano Banana(Gemini 2.5 Flash Image)を使用する際には、Google Workspace with GeminiもしくはVertex AIを利用する必要があります。
\画像生成AIを商用利用する際はライセンスを確認しましょう/

Nano Banana(Gemini 2.5 Flash Image)の料金
Nano Banana(Gemini 2.5 Flash Image)の利用料金は、開発者向けAPI経由の従量課金とエンドユーザー向けアプリでの無料利用の2形態に大別できます。開発者や企業がGoogle CloudのGemini APIもしくはVertex AI経由で本モデルを呼び出す場合は、その出力トークン数に応じた課金が発生します。
一方、一般ユーザーがGeminiのチャットアプリやGoogle AI Studio上で試す範囲では、2025年8月27日時点では無料で利用可能となっています(※プレビュー提供期間中の措置であり、将来的に変更となる可能性もあります)。以下に料金の概要をまとめます。
| 利用方法 | 料金 |
|---|---|
| Geminiアプリ / AI Studio(一般ユーザー向け) | 無料(現在プレビュー期間につき無償提供) |
| Gemini API / Vertex AI(開発者向け) | $0.039/画像(出力1枚あたり約0.039ドル=約5.7円) |
※開発者向けのAPI利用料金は、100万トークンあたり$30に設定されています。画像1枚の出力は約1,290トークンに相当し、料金にすると約0.039ドル(6円弱)となっています。
Nano Banana(Gemini 2.5 Flash Image)はいつまで無料?
2025年9月に以下のようなポストがXにされています。
Nano Banana (Gemini 2.5 Flash Image) 自体、Google AI Studioで使う分には無料で利用可能ですが、APIを使う場合にはインプット0.3ドル、アウトプット0.039ドルがかかります。
Nano Banana(Gemini 2.5 Flash Image)の使い方
Nano Banana(Gemini 2.5 Flash Image)の利用方法は大きく分けて、プログラミング不要で試せるWebインターフェース経由と、開発者向けのAPI経由の2通りがあります。
Webインターフェース経由での使い方
まずは手軽に試せるGoogle AI StudioやGemini公式チャットアプリでの使い方です。Google AI Studioにアクセスし、自分のGoogleアカウントでログインします。
プロジェクトを作成したら、メニューから利用できるモデル一覧の中に「Gemini 2.5 Flash Image」が表示されますので選択します。
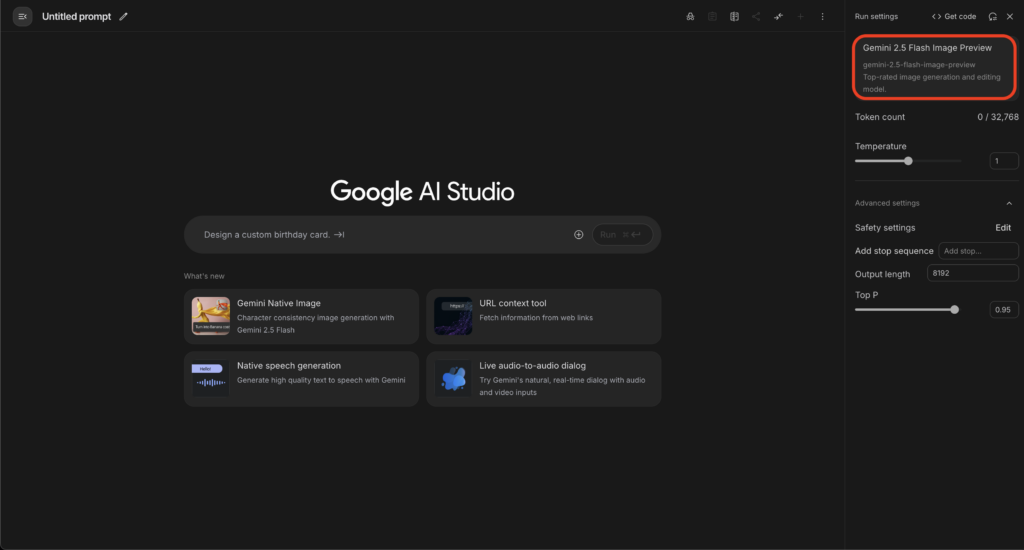
あとはテキストボックスに生成したい画像の内容や編集の指示を日本語または英語で入力するだけです。
API経由での使い方
開発者向けには、プログラムからNano Banana(Gemini 2.5 Flash Image)を呼び出す方法も整備されています。Googleが提供するGemini APIを使えば、自分のアプリケーションやサービスの中でこのモデルに画像生成させることが可能です。例えばPython用のSDK(Google GenAIライブラリ)を使う場合の手順は以下の通りです。
まず、認証用のAPIキーを取得してgenai.Client()でクライアントを初期化します。その上で、テキストのプロンプト文字列と必要なら画像バイナリを準備し、client.models.generate_content()メソッドを呼び出すとモデルからの応答が得られます。
リクエスト時にmodel="gemini-2.5-flash-image-preview"のようにモデル名を指定し、contents=[prompt, image]のようにテキストと画像をリストで渡すことで、テキストと画像の複合入力にも対応しています。
返ってきたレスポンスオブジェクトから生成画像データを取り出し、ファイルに保存すれば完了です。以下は公式ブログで紹介されているコード例です。
from google import genai
from PIL import Image
from io import BytesIO
client = genai.Client()
prompt = "Create a picture of my cat eating a nano-banana in a fancy restaurant under the gemini constellation"
image = Image.open('/path/to/image.png')
response = client.models.generate_content(
model="gemini-2.5-flash-image-preview",
contents=[prompt, image],
)
for part in response.candidates[0].content.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = Image.open(BytesIO(part.inline_data.data))
image.save("generated_image.png")Nano Banana(Gemini 2.5 Flash Image)を使ってみた
今回はGoogle AI StudioでNano Banana(Gemini 2.5 Flash Image)を試していきます。
まずはこちらのペンギンにヘルメットを被らせてもらいましょう。

プロンプト:
Let this penguin wear a yellow helmet.
(このペンギンに黄色いヘルメットを被らせて)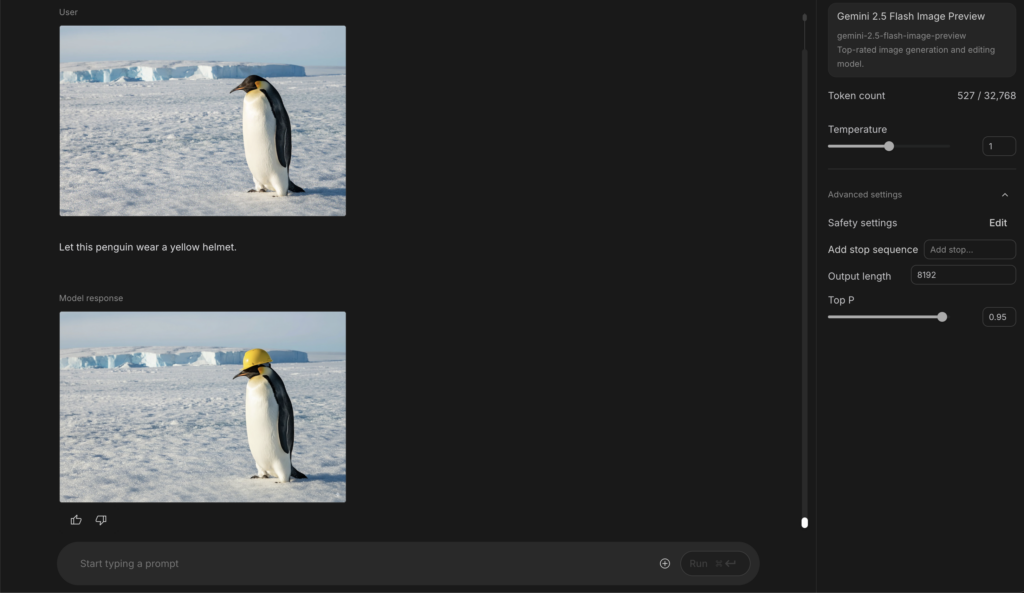

詳細な指示はせずとも、意図した画像を生成してくれました。ヘルメットのサイズ感や被らせ方、背景が一切崩れていない点など、ポイント高いです。
では、続いてこのペンギンをロサンゼルスの街中に召喚させてみます。
プロンプト:
Move the first penguin to the second city.
(1枚目のペンギンを2枚目の街に移動させて)
oh, なかなかいいですね。もう少し街に馴染ませてあげましょう。
プロンプト:
Make penguins more familiar with the city. They seem to enjoy walking around.
(ペンギンをもっと街に馴染ませて。散歩しながら楽しんでいる様子で。)
めちゃくちゃ良い感じです。増殖してくれたのはもちろん、リサイズされていたり、各ペンギンの影まで再現されていて高品質な画像を生成してくれました。
画像の合成や細部の編集、キャラクター(今回はペンギン)の一貫性維持をちゃんとしてくれることが確認できました。人間の発想力次第で、実用可能性は無限大な感じがしますね。
Nano Banana(Gemini 2.5 Flash Image)の活用事例
ここからはNano Banana(Gemini 2.5 Flash Image)の活用事例をいくつか紹介したいと思います。
画像内の一部を変更
まずは画像内の一部を変更する活用です。例えば、先ほどの桜並木を歩く高校生を入学式の会場に移してみます。
プロンプトとしては「場所を桜並木から入学式の会場に変更して」と入力しただけで、以下の画像が生成されました。

特に何も指示は与えていませんが、2人以外の高校生も描画してくれており、ユーザーの入力した文脈を理解して画像を生成してくれています。
このようにNano Banana(Gemini 2.5 Flash Image)では画像の一部を変更して画像を生成してもらうことが可能です。
また、以下のポストでは証明写真を生成するという活用をしていました。
複数画像を合成する
また、複数の画像を1枚にして画像を生成することも可能。
以下のポストでは人物と商品の2枚の画像を1枚に再生成しています。
こういった使い方ができると素材さえあればいくらでもポスターやSNS用の画像、広告用の画像など何枚でも作成することができますね。
フィギュア画像の作成
Nano Banana(Gemini 2.5 Flash Image)では画像からフィギュア画像の作成も可能です。
現在はフィギュア画像に留まっていますが、もしかしたら3Dデータとして出力が可能になれば、そのまま3Dプリンターでフィギュアを作れるかもしれません。
プロンプト例
最後にNano Banana(Gemini 2.5 Flash Image)を使う上でのプロンプト例をいくつかご紹介します。
GitHubにもまとめられていますので、より詳しく知りたい方はGitHubページもご覧ください。
プロンプト例として、先ほどの高校生の画像でいくつか試してみます。
まずはクロスビュー画像の生成です。先ほどの高校生の画像は後ろからの画像でしたが、上から撮影した画像を生成してもらいましょう。
「真上から空撮した画像に変えて」とのみプロンプトを与えた結果がこちらの画像です。

次は年代を変えてみます。プロンプトとしては「1980年代の画像に変えて」と指示を与えます。

セピアな感じにはなっていますが、これが1980年代の画像かと言われると、ちょっと違う気がしますね。
最後に画像に透かしを入れてもらいましょう。「この画像にWEELという透かしを入れてください」と指示を与えます。
ちゃんと透かしを入れてくれましたが、雑に指示を与えたからか、めちゃくちゃでかい透かしになってしまいました。
プロンプトを入れる際には、具体的に入力した方がこちらの意図している画像を生成してくれそうです。
まとめ
Nano Banana(Gemini 2.5 Flash Image)は、テキストによる直感的な操作で高度な画像生成・編集を可能にした画期的なモデルです。
ユーザー側は専門知識がなくても「何を作りたいか」さえ明確に伝えればよく、あとの難しい処理はモデルがすべて引き受けてくれます。これは、裏で動くAIがテキストと画像の両方を理解し、論理的な推論を行った上でビジュアルを構築できるからこそ実現した体験です。
Googleが培ってきた大規模言語モデルGeminiの知性と、画像生成分野の最先端技術とが融合したことで、誰もがクリエイターになれる時代が一歩近づいたと言えますね。
気になる方は、ぜひ一度試してみてください!

最後に
いかがだったでしょうか?
AI導入を検討中の企業向けに、業務効率化や新しい価値創出を支援できる情報を提供します。最新のNano Banana(Gemini 2.5 Flash Image)を活用し、効率的な業務改善や高度な分析が可能です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、弊社紹介資料もご用意しておりますので、併せてご確認ください。


