
【Gemini 3.1 Flash TTS】世界2位のAI音声合成モデルの特徴・使い方・料金を徹底解説

- Gemini 3.1 Flash Liveは、Googleが公開したリアルタイムの音声・映像対話に特化した音声生成モデル
- Artificial Analysis TTSリーダーボードでEloスコア1,211を記録し、全モデル中第2位にランクイン
- 70以上の言語とネイティブマルチスピーカー対応で、多言語の対話コンテンツを1回のAPI呼び出しで生成可能
2026年4月16日、Googleは最新のテキスト音声変換モデル「Gemini 3.1 Flash TTS」を公開しました!
従来のTTSモデルとはひと味違って200以上のaudio tagsによる表現力の制御や、ネイティブマルチスピーカー機能の搭載が大きな注目を集めています。Artificial Analysis TTSリーダーボードでは、Eloスコア1,211を記録し、世界2位という高い評価を獲得しました。
とはいえ、「audio tagsって何?」「日本語にも使えるの?」「料金はいくらかかるの?」と疑問に思っている方も多いのではないでしょうか。
そこで本記事では、Gemini 3.1 Flash TTSの概要から技術的な仕組み、料金体系、具体的な使い方、そして実際に試してみた検証結果まで徹底的に解説します。ぜひ最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
Gemini 3.1 Flash TTSとは?

Gemini 3.1 Flash TTSは、Google DeepMindが開発したGeminiシリーズのテキスト音声変換(TTS)専用モデルです。テキストを入力するだけで、人間のような自然な音声を生成できます。
最大の特徴は、audio tagsと呼ばれる制御タグをテキスト内に埋め込むことで、音声の感情表現やペース、トーンを細かくコントロールできる点にあります。例えば、 [whispers](ささやき)や [excited](興奮)といったタグを文中に挿入するだけで、モデルがその指示に沿った表現豊かな音声を生成してくれます。
こうしたタグは200種類以上用意されており、映画の監督がキャストに演技指導をするような感覚で、音声の演出が行えるそうです。対応言語は70以上で、日本語ももちろんサポートされています。audio tagsの記述自体は英語ですが、日本語テキストと組み合わせて使うことが可能です。
さらに、ネイティブマルチスピーカー機能を搭載しており、複数の話者による対話を1回のAPI呼び出しで自然に生成できます。従来は話者ごとに個別のAPI呼び出しが必要でしたが、この機能によってポッドキャストやオーディオブックのような対話コンテンツの制作が大幅に効率化されました。
生成AIの大手「アリババ」のTTSについては以下の記事も参考にしてみてください。

Gemini 3.1 Flash TTSの仕組み
Gemini 3.1 Flash TTSの内部処理は公式に詳細が公開されているわけではありませんが、Google DeepMindのモデルカードによると、Gemini 3 Proのアーキテクチャをベースに構築されています。テキスト入力のみを受け付け、音声のみを出力するという、TTS処理に特化した設計です。
入力テキストには、単純な読み上げ原稿だけでなく、5つの要素を含む構造化プロンプトを渡すことで品質を高められます。具体的には「Audio Profile(キャラクター設定)」「Scene(場面設定)」「Director’s Notes(演出指示)」「Sample Context(文脈情報)」「Transcript(読み上げテキスト)」の5要素です。


Gemini 3.1 Flash TTSの特徴
Gemini 3.1 Flash TTSには、従来のTTSモデルにはなかった独自の強みがいくつもあります。ここからは、ベンチマーク結果や機能面から、その特徴を見ていきましょう。
Eloスコア1,211でTTSリーダーボード第2位
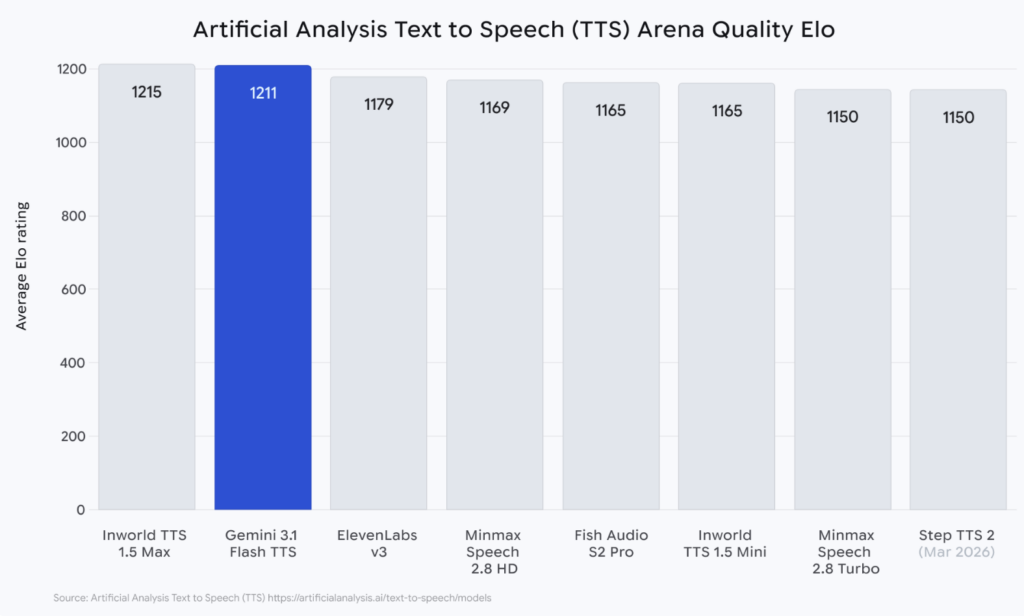
Artificial Analysisが運営するTTSリーダーボード(Speech Arena)では、数千件のブラインド比較テストに基づくEloレーティングが算出されています。Gemini 3.1 Flash TTSはEloスコア1,211を記録し、Inworld TTS 1.5 Max(Elo 1,215)に次ぐ全モデル中第2位にランクインしました。ElevenLabsのEleven v3(Elo 1,179)をも上回るスコアです。
さらに、このリーダーボードでは品質とコストのバランスを評価する象限分析も行われており、Gemini 3.1 Flash TTSは「最も魅力的な象限(most attractive quadrant)」に位置づけられています。
200以上のaudio tagsで表現力を演出
audio tagsは、テキスト内に [ ](角括弧)で囲んだ自然言語の指示を埋め込むことで、音声の感情やトーンを制御する仕組みです。
[whispers](ささやき)、[shouting](叫び)、[laughs](笑い)、[sighs](ため息)、[excited](興奮)、[sarcastic](皮肉)など、200種類以上のタグが利用できます。文の途中に挿入すればその位置から表現が切り替わるため、一文の中でも感情の変化をつけられるのが特徴です。
30種類のビルトイン音声
あらかじめ用意された30種類の音声プリセットから、用途に合った声質を選べます。Kore、Puck、Zephyr、Charon、Fenrir、Leda、Aoede、Enceladusなど、ギリシャ神話や天体に由来する個性的な名前がつけられています。
ネイティブマルチスピーカー対応
従来のTTSでは、複数の話者が登場する対話コンテンツを作るには話者ごとにAPIを呼び出し、生成した音声を後から結合する必要がありました。
Gemini 3.1 Flash TTSでは、1回のAPI呼び出し内で複数話者の対話を一括生成できます。話者ごとに異なる音声プリセットを割り当てることも可能で、自然な掛け合いのテンポが保たれるのが大きなメリットになりそうです。
Gemini 3.1 Flash TTSの安全性・制約
AI生成音声の悪用リスクへの対策として、Gemini 3.1 Flash TTSが生成する全ての音声には、SynthIDによるウォーターマークが埋め込まれます。SynthIDは、人間の耳には聞こえない形で音声データに直接織り込まれる電子透かし技術で、AI生成コンテンツであることを後から検出できる仕組みです。ディープフェイクや偽情報の拡散防止に一役買っています。
また、Google DeepMindのモデルカードによると、リリース前にはGoogleのAI原則に基づく自動評価・人間による評価・レッドチーミング(攻撃的テスト)・倫理および安全性レビューが実施されています。ヘイトスピーチや危険な指示、ハラスメント、医療に関する誤情報などの生成は禁止コンテンツとして制限されています。
Gemini 3.1 Flash TTSの料金
Gemini 3.1 Flash TTSの料金体系は、入力(テキスト)と出力(オーディオ)のトークン数に応じた従量課金制です。音声出力は1秒あたり25トークンとして換算されるため、1分間の音声生成には約1,500トークンが消費されます。なお、無料枠(Free tier)も用意されており、レート制限はあるものの入出力ともに無料で試すことが可能です。
| プラン | 入力(テキスト) | 出力(オーディオ) | 1分あたりの目安コスト |
|---|---|---|---|
| 無料枠(Free tier) | 無料 | 無料 | $0(レート制限あり) |
| Standard(従量課金) | $1.00 / 100万トークン | $20.00 / 100万トークン | 約$0.03(約4.5円) |
| Batch(バッチ処理) | $0.50 / 100万トークン | $10.00 / 100万トークン | 約$0.015(約2.3円) |
例えば、Standardプランで1時間分の音声を生成した場合のコストは約$1.80(約270円)、Batchプランならその半額の約$0.90(約135円)です。
Gemini 3.1 Flash TTSのライセンス
Gemini 3.1 Flash TTSはオープンソースモデルではなく、Gemini APIを通じて利用するクラウドサービスとして提供されています。そのため、モデルの重みをダウンロードして自社サーバーで動かすといった使い方はできません。
利用にあたっては、Gemini API利用規約(Gemini API Additional Terms of Service)とGoogleの生成AI禁止使用ポリシーが適用されます。
| 項目 | 可否 | 備考 |
|---|---|---|
| 商用利用 | ⭕️ | |
| 生成音声の改変 | ⭕️ | |
| 生成音声の再配布 | ⭕️ | |
| モデル自体の改変・再配布 | ❌️ | APIサービスとして提供されるため、モデルのダウンロード・リバースエンジニアリング・競合モデルの開発目的での利用は禁止 |
| 私的利用 | ⭕️ |
重要なポイントとして、有料プラン(Paid Services)ではGoogleがユーザーの入出力データをモデル改善に使用しないことが規約で明示されています。
Gemini 3.1 Flash TTSの使い方
Gemini 3.1 Flash TTSを試す方法は、大きく分けて「Google AI Studioでブラウザから試す」「PythonでGemini APIを使う」「マルチスピーカー音声を生成する」の3パターンがあります。ここからは、それぞれの方法をステップ・バイ・ステップでご紹介します。
Google AI Studioからブラウザで試す
1番お手軽にGemini 3.1 Flash TTSを体験できる方法です。プログラミングの知識がなくても、ブラウザだけで音声生成を試すことができます。
画面右上のモデル選択から「Gemini 3.1 Flash TTS Preview」を選択します。
テキスト入力欄に読み上げたい文章を入力します。audio tagsを使いたい場合は、[excited] や [whispers] などのタグを文中に挿入してください。音声プリセット(Kore、Puckなど)を選択したら、生成ボタンを押すだけで音声が出力されます。
生成された音声はブラウザ上で再生でき、WAVファイルとしてダウンロードすることも可能です。
Python(Gemini API)で音声を生成する
APIを使ったプログラムからの音声生成は、アプリケーションに組み込む際に必要になる方法です。Python SDKを使った基本的な手順を紹介します。
ターミナルで以下のコマンドを実行して、Python用のGoogle AI SDKをインストールします。
pip install google-genaiGoogle AI Studioにアクセスし、「Get API key」からAPIキーを発行します。環境変数に設定しておくと便利です。
export GEMINI_API_KEY="あなたのAPIキー"以下のPythonコードで、テキストから音声ファイルを生成できます。
from google import genai
from google.genai import types
import wave
import os
# クライアントの初期化(環境変数からAPIキーを取得)
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
# 音声生成リクエスト
response = client.models.generate_content(
model="gemini-3.1-flash-tts-preview",
contents="[warm] こんにちは、今日はGemini 3.1 Flash TTSの使い方をご紹介します。",
config=types.GenerateContentConfig(
response_modalities=["AUDIO"],
speech_config=types.SpeechConfig(
voice_config=types.VoiceConfig(
prebuilt_voice_config=types.PrebuiltVoiceConfig(
voice_name='Kore' # 30種類から選択可能
)
)
)
)
)
# レスポンスからPCMデータを取得してWAVファイルに保存
data = response.candidates[0].content.parts[0].inline_data.data
with wave.open("output.wav", "wb") as wf:
wf.setnchannels(1) # モノラル
wf.setsampwidth(2) # 16ビット
wf.setframerate(24000) # 24kHz
wf.writeframes(data)
print("音声ファイルを output.wav に保存しました")実行すると、カレントディレクトリに output.wav が生成されます。再生して音声品質を確認してみてください。
マルチスピーカー音声を生成する
複数の話者が登場する対話形式の音声を生成する方法です。ポッドキャストや会話形式のコンテンツ制作に最適な機能となっています。
MultiSpeakerVoiceConfig を使って、各話者に音声プリセットを割り当てます。
from google import genai
from google.genai import types
import wave
import os
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
# マルチスピーカー設定
response = client.models.generate_content(
model="gemini-3.1-flash-tts-preview",
contents="""Say the following as a conversation between friends.
太郎: [excited] おい、Geminiの新しいTTSモデル使ってみた?すごいぞ!
花子: [curious] えっ、何それ?どんなことができるの?
太郎: [enthusiastic] audio tagsっていうのを使うと、ささやき声とか叫び声とか、感情を自由に操れるんだ。
花子: [amazed] それはすごい!日本語でも使えるの?
太郎: [confident] もちろん。70言語以上に対応してるよ。""",
config=types.GenerateContentConfig(
response_modalities=["AUDIO"],
speech_config=types.SpeechConfig(
multi_speaker_voice_config=types.MultiSpeakerVoiceConfig(
speaker_voice_configs=[
types.SpeakerVoiceConfig(
speaker='太郎',
voice_config=types.VoiceConfig(
prebuilt_voice_config=types.PrebuiltVoiceConfig(
voice_name='Kore'
)
)
),
types.SpeakerVoiceConfig(
speaker='花子',
voice_config=types.VoiceConfig(
prebuilt_voice_config=types.PrebuiltVoiceConfig(
voice_name='Leda'
)
)
)
]
)
)
)
)
# WAVファイルとして保存
data = response.candidates[0].content.parts[0].inline_data.data
with wave.open("dialogue.wav", "wb") as wf:
wf.setnchannels(1)
wf.setsampwidth(2)
wf.setframerate(24000)
wf.writeframes(data)
print("対話音声を dialogue.wav に保存しました")上記コードを実行すると、太郎と花子が異なる声で会話する音声ファイルが1つ生成されます。話者ごとにAPIを呼び分ける必要がなく、会話の自然なテンポが維持されるのがポイントです。
【業界別】Gemini 3.1 Flash TTSの活用シーン
Gemini 3.1 Flash TTSは音声コンテンツが求められる幅広い業界で活用できる可能性があります。ここからは、特に相性のよい業界別のユースケースを見ていきましょう。
教育・eラーニング
eラーニング教材のナレーション制作は、プロのナレーターに依頼すると時間もコストもかかります。
Gemini 3.1 Flash TTSを使えば、教材のテキスト原稿をそのまま音声化でき、しかもaudio tagsで重要なポイントを強調口調にするといった教育的な工夫も可能です。70以上の言語に対応しているため、多言語対応の教材制作にも即座に活用できるでしょう。
教育業界における生成AI活用について、詳しく知りたい方は以下の記事も参考にしてみてください。

メディア・コンテンツ制作
ポッドキャスト番組や動画ナレーションの制作現場では、マルチスピーカー機能が活躍してくれます。
2人のホストが掛け合うポッドキャスト形式のコンテンツを、台本テキストを渡すだけで一括生成できるのは大きな時短になるはずです。ニュースメディアでは、記事のオーディオ版を自動生成して配信するワークフローにも組み込めます。
カスタマーサポート・コールセンター
IVR(自動音声応答)やチャットボットの音声インターフェースに組み込むことで、機械的でない、自然なトーンの応対を実現できます。
お客様への案内音声に [warm] や [empathetic] などのタグを適用すれば、冷たい印象を与えがちなAI音声の課題を軽減できるでしょう。
コールセンターにおける生成AI活用について、詳しく知りたい方は以下の記事も参考にしてみてください。

【課題別】Gemini 3.1 Flash TTSが解決できること
多くの組織が抱える音声コンテンツ制作の課題に対して、Gemini 3.1 Flash TTSはどのような解決策を提供できるのでしょうか。具体的な課題ごとに確認していきましょう。
多言語音声コンテンツを低コストで一括生成できる
グローバル展開する企業にとって、製品説明やサポートガイドの多言語音声化は大きなコスト要因です。
Gemini 3.1 Flash TTSは70以上の言語に対応しており、同じAPIで言語を切り替えるだけで多言語の音声を生成できます。ナレーターの手配や録音スタジオの確保が不要になるため、制作コストとリードタイムを大幅に圧縮できるでしょう。
感情表現のある自然なAIナレーションを実現できる
従来のTTSモデルでは、音声が平坦でいかにもAIな印象が強かったと思います。
そこで、200以上のaudio tagsを活用すれば、喜怒哀楽のある自然なナレーションを実現でき、リスナーの没入感を高められます。物語の朗読や広告ナレーションなど、感情表現が重要なコンテンツで特に有用だと思います。
対話コンテンツの制作工数を大幅に削減できる
マルチスピーカー機能によって、複数話者の対話を1回のAPI呼び出しで生成できるようになります。
従来のように話者ごとに音声を生成して後からタイミングを合わせて結合する手間がなくなり、ポッドキャストやインタビュー形式のコンテンツの制作工数が大幅に減ります。台本を書けばすぐに音声化できるため、コンテンツの試作や検証のスピードも上がるでしょう。
Gemini 3.1 Flash TTSを使ってみた
それでは実際に、Google AI Studio上でGemini 3.1 Flash TTSの検証をしていきましょう。
今回は、Gemini 3.1 Flash TTS最大の目玉機能であるaudio tagsの表現力を検証しましょう。1つのナレーション原稿の中で感情が切り替わるよう、複数のタグを埋め込んでみます。
音声プリセットは好みのものを選んでください。今回は「Aoede」を選択しました。
テキスト入力欄に、以下のようなプロンプトを貼り付けます。
プロンプトはこちら
Audio profile: A professional Japanese narrator for a tech review show.
Scene: Recording studio, energetic tech review atmosphere.
Director's notes: Vary the pacing. Start measured, build excitement,
end with a warm invitation.
Transcript:
[calm] 本日ご紹介するのは、Googleが開発した最新の音声合成モデルです。
[building excitement] このモデルの何がすごいかというと、200以上のタグで声の表情を自在に操れること。
[excited] なんと、ささやき声から叫び声まで、まるで本物の声優のような演技ができてしまうのです。
[warm] 気になった方は、ぜひ一度試してみてくださいね。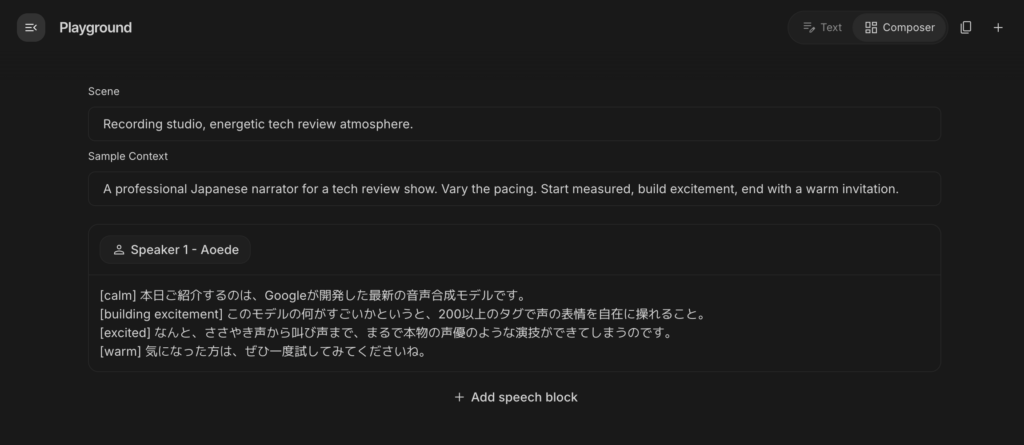
ポイントは、シーンディレクション(Audio Profile・Scene・Director’s Notes)で全体の雰囲気を設定した上で、Transcript内の各文頭に [calm]→[building excitement]→[excited]→[warm] とタグを配置している点です。こうすることで、冒頭の落ち着いたトーンから徐々にテンションが上がり、最後は温かい語りかけで締まるナレーションになると思います。
出力結果はこちら
よくある質問
最後に、Gemini 3.1 Flash TTSについて、多くの方が気になるであろう質問とその回答をご紹介します。
Gemini 3.1 Flash TTSで音声生成が新時代へ!
Gemini 3.1 Flash TTSは、200以上のaudio tagsによる感情表現の制御、ネイティブマルチスピーカー対応、70以上の言語サポートを備えた、Googleの最新テキスト音声変換モデルです。
Artificial Analysis TTSリーダーボードで世界2位のEloスコアを記録しながら、1分あたり約$0.03という低コストで利用できる点は、商用TTSサービスとしてのバランスの高さを感じますね。
Google AI Studioの無料枠を使えばコード不要で手軽に試せるため、まずは実際に音声を生成して品質を体感してみてください。音声コンテンツの制作効率化や多言語対応にお悩みの方にとって、きっと力になってくれると思います。

最後に
いかがだったでしょうか?
弊社では、AI導入を検討中の企業向けに、業務効率化や新しい価値創出を支援する情報提供・導入支援を行っています。最新のAIを活用し、効率的な業務改善や高度な分析が可能です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

