
Gemini 3 Flashとは?高速・高知能を両立する実運用向けLLMの特徴と活用ポイントを解説

- 高速応答と高い推論性能を両立した実運用向けLLM
- 高頻度API利用やリアルタイム処理に強いコスト効率重視の設計
- 検証から本番まで同一モデルで展開しやすい導入のしやすさ
2025年12月、Googleから新たなLLMがリリースされました!
今回リリースされた「Gemini 3 Flash」は出力速度を重視しつつ、性能も維持されているモデルです。公式発表ではGemini 2.5 Proを上回る性能を発揮しつつ、3倍の速度で動作します。
本記事ではGemini 3 Flashの概要から仕組み、実際の使い方について解説をします。本記事を最後までお読みいただければ、Gemini 3 Flashの理解が深まり、ご自身で実装できるようになります。
ぜひ最後までお読みください!
\生成AIを活用して業務プロセスを自動化/
Gemini 3 Flashの概要
Gemini 3 FlashはGoogleが提供するGemini 3モデルの最新モデルで、スピードを重視しつつ高い推論能力を有しています。
従来、推論性能を上げるほどレイテンシやコストが増えやすい一方で、Flashは「速度と推論能力の両立」を狙って開発され、日常タスクから開発用途まで幅広く展開する方針が示されています。
Gemini 3 FlashはGemini 3 Pro級の推論能力を保ちつつ、Flashレベルの低レイテンシや効率、コストを組み合わせています。
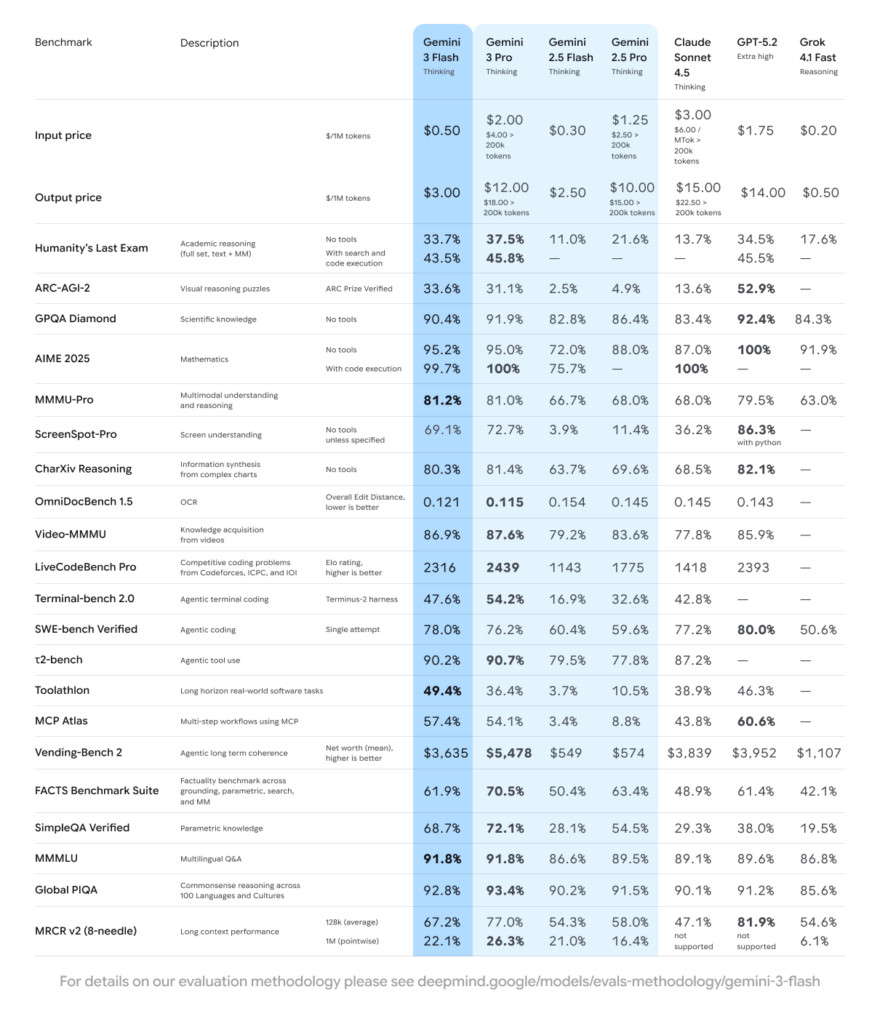
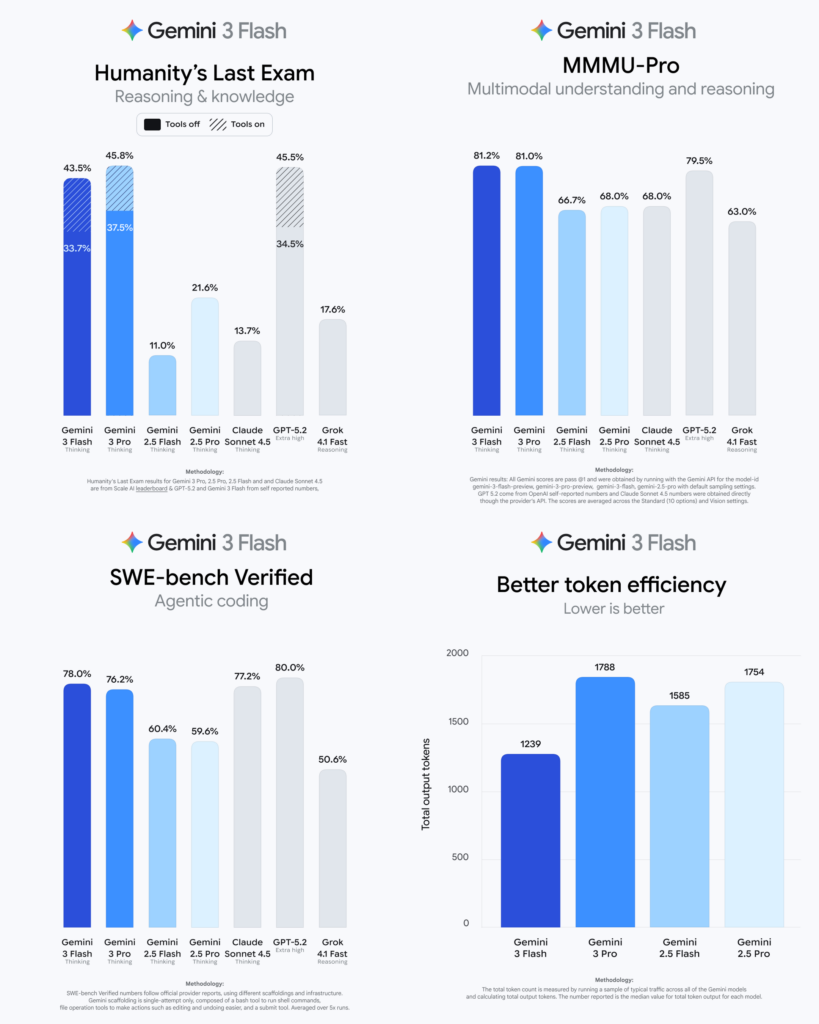
ベンチマークではGPQA Diamondが90.4%、Humanity’s Last Examがツールなしで33.7%とされ、速度重視モデルでも高いスコアを獲得。また、MMMU Proは81.2%とされ、マルチモーダル理解も重視している設計と言えるでしょう。


Gemini 3 Flashの仕組み
ここではGemini 3 Flashがどのような仕組みで速度と推論能力の両立を実現しているのかを解説します。
結論から言うと、ベースとなる推論能力はGemini 3ファミリーと共通しつつ、実行効率を最適化する設計を採用。その結果、高度なタスクにも対応しながら、レスポンスの速さを重視する用途に適したモデルとなっています。
基本的な動作原理
Gemini 3 Flashは、大規模言語モデルとしてのトランスフォーマー系アーキテクチャを基盤にしています。ただし、Flashでは計算パスや内部処理の最適化が行われ、同系統の上位モデルと比べて推論時の負荷が抑えられています。こうした設計により、モデルサイズや能力を極端に落とさずに、低レイテンシを実現。
入力から出力までの処理フロー
処理の流れは、テキストやマルチモーダル入力を受け取り、内部表現へ変換した上で推論を行い、最終的な出力を生成するという一般的なLLMの構成に沿っていますが、Flashではリアルタイム性を意識したスケジューリングや効率化が組み込まれていると発表されています。※1
そのため、チャットやAPIリクエストのように応答速度が重要な場面でも、安定した処理が可能です。
技術的な工夫と狙い
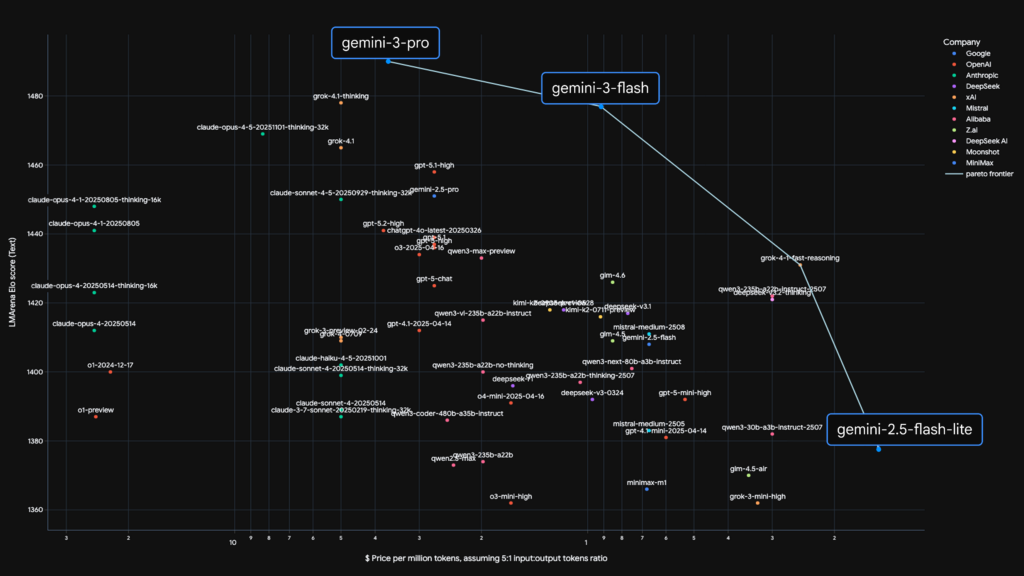
Gemini 3 Flashを、性能・コスト・スピードのバランスが取れた「Pareto frontier」上のモデルとして位置づけています。
つまり、どれか一つを犠牲にするのではなく、実運用で最も使われやすい点を狙った設計という考え方。このアプローチにより、検証用途から本番システムまで同一モデルで対応しやすくなる可能性があるでしょう。
なお、Google発のAIエージェントであるCodeMenderについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
Gemini 3 Flashの特徴
ここでは、Gemini 3 Flashが持つ主な特徴を踏まえ、どのような点が実運用でのメリットにつながるのかを解説します。全体として重視されているのは、高度な推論能力を維持しながらも、スピードとコスト効率を高い水準で両立させる点。
高い推論性能とベンチマーク結果
Gemini 3 Flashは高速モデルでありながら、複数の主要ベンチマークで高いスコアを獲得。
GPQA Diamondで90.4%、Humanity’s Last Examではツール非使用条件で33.7%とされ、知識集約型タスクへの対応力が示されています。
また、MMMU Proが81.2%とされ、マルチモーダル理解も重要。これらの数値は、単なる軽量モデルではなく、実務に耐える知能を備えていることを示す指標と言えるでしょう。
スピードとコストのバランス設計
Flashの名称が示す通り、レスポンス速度を重視した設計を採用。
Googleは本モデルを、性能・コスト・スピードの最適点、いわゆるPareto frontier上に位置づけました。そのため、より高性能なPro系モデルと比べて、日常的なリクエスト処理や大量トラフィックを前提とした運用に最適です。
大規模運用を前提としたスケーラビリティ
Gemini 3 Flashは、API経由で1日あたり1Tトークン以上を処理している実績が言及されました。※2
この数値は、研究用途にとどまらず、本番環境での大規模利用を想定していることを示しています。小規模なPoCから大規模サービスまで同一モデルで対応できる点は、システム設計を簡素化する要因となり得るでしょう。
Gemini 3 Flashの安全性・制約
ここでは、Gemini 3 Flashを利用する際の安全性の考え方と、事前に把握しておきたい制約を解説します。
セーフティ設計とガードレール
Gemini 3 Flashは、GoogleのAI全体に共通するセーフティポリシーに基づいて設計されています。
具体的には、有害コンテンツの生成抑制や不適切な利用を防ぐためのガードレールが組み込まれています。これにより、一般的な業務利用やプロダクト組み込み時にも、一定の安全性が担保される構成となっています。
利用上の制約と注意点
Gemini 3 Flashは高速性を重視したモデルであるため、最先端の長時間推論や極端に複雑な推論タスクでは、Pro系モデルの方が適する場合があります。
また、出力の正確性や完全性が常に保証されるわけではなく、重要な意思決定では人による確認が前提となります。こうした制約を理解した上で、用途に応じてモデルを使い分けることが求められるのではないでしょうか。
Gemini 3 Flashの料金
Gemini 3 FlashはGoogle AI Studioで無料で利用可能。
APIを利用する場合には「gemini-3-flash-preview」を選択する必要があり、入力が$0.5/1Mトークン、出力が$3/1Mトークンです。音声入力の場合には$1/1Mトークンとなります。
Gemini 3 Proとの比較が下記です。
| モデル | インプット | アウトプット |
|---|---|---|
| Gemini 3 Flash | $0.50(テキスト / 画像 / 動画) $1.00(音声) | $3.00 |
| Gemini 3 Pro | $2.00、プロンプト <= 200, 000トークン $4.00、プロンプト > 200, 000トークン | $12.00、プロンプト <= 200, 000 トークン $18.00、プロンプト > 200, 000 |
Gemini 3 Flashのライセンス
Gemini 3 Flashのライセンスについて、明示されている文章を見つけることはできませんでしたが、プライバシーポリシーと利用規約から以下のように考えられます。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ❌ |
| 配布 | ❌ |
| 特許使用 | 明示的には記載なし |
| 私的使用 | ⭕️ |
なお、Gemini 3.0 Proをベースとした画像生成AIであるNano Banana Proについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Gemini 3 Flashの実装方法
Gemini 3 FlashはGoogle AI Studioでモデルを選択すれば使用可能です。
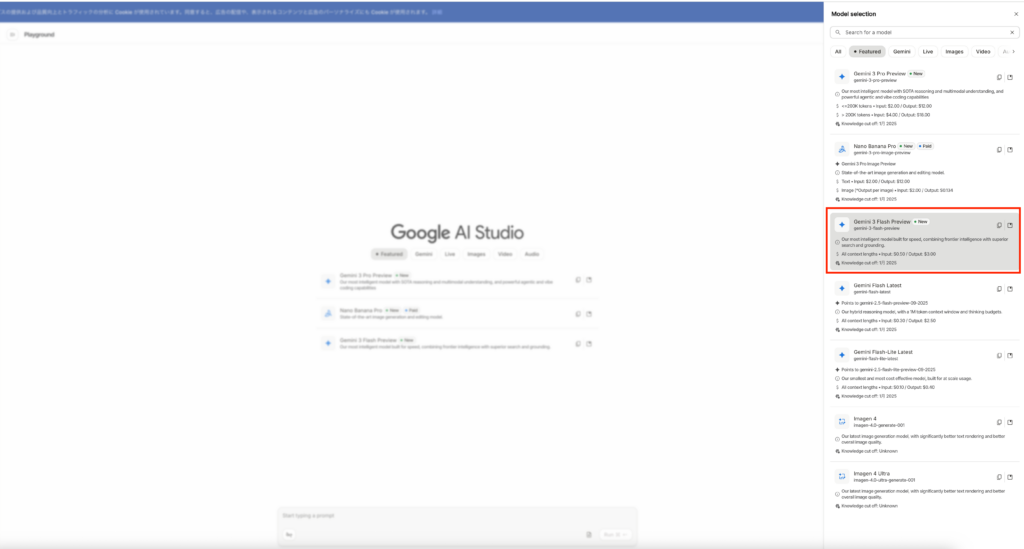
確かに出力速度は速い気がしますね。Proでも同じことを聞いてみます。
出力結果自体は大きく変わりませんが、速度はやはりGemini 3 Flashが速いですね。よほど複雑なタスクじゃない限りはGemini 3 Flashで良いかもしれません。
API経由でGemini 3 Flashを使う
次はAPI経由でGemini 3 Flashを使ってみます。
Google AI Studioの右上に「get code」と書かれている部分があります。
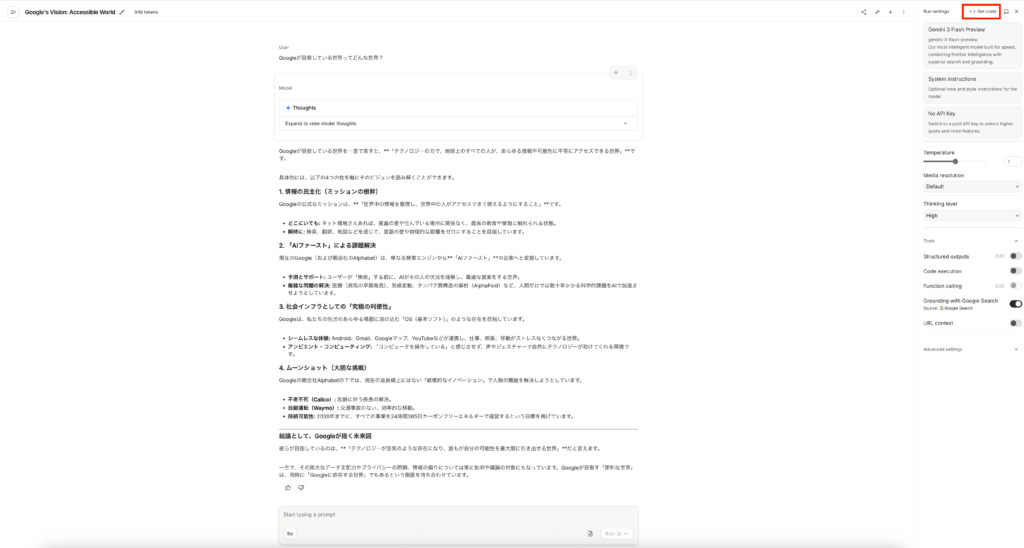
ここからコードを出力して、google colaboratoryに貼り付けます。もしくは「co」と書かれているボタンがあるので、そちらをクリックするとgoogle colaboratoryが起動します。
実際に起動している様子がこちら。
Google AI Studio経由だと非常に簡単に実装ができますね。
Gemini 3 Flashの活用事例
Gemini 3 Flashがどのような場面で活用できるのかを解説します。
リアルタイム性が求められる対話型アプリケーション
Gemini 3 Flashは低レイテンシを重視した設計であるため、チャットボットや対話型UIとの相性が良いモデルです。問い合わせ対応や社内QAのように、即時応答が求められる場面では、体感速度の向上がユーザー満足度に直結します。速度と一定以上の推論精度を両立した点が、この用途での強みと言えるでしょう。
高頻度API呼び出しを伴う業務自動化
1日あたり1Tトークン以上を処理しているという言及から、大量リクエストを前提とした利用が想定されます。
例えば、ログ要約や簡易レポート生成、定型文の生成といった業務では、コストと処理速度のバランスが重要です。こうした用途では、上位モデルではなくFlashを選択することで、全体最適につながる可能性があります。
マルチモーダル理解を活かした補助タスク
MMMU Proで81.2%というスコアが示す通り、Gemini 3 Flashはマルチモーダル理解も性能が高いです。そのため、画像とテキストを組み合わせた入力を前提とするサポート機能や分析補助的な役割での活用が考えられます。
実際にマルチモーダル理解を活用した例が公式サイトに掲載されていました。
Gemini 3 Flashを実際に使ってみた
Gemini 3 Flashが低レイテンシで即応答できる・処理が速いので特徴を踏まえてサンプルコードを動かしてみたいと思います。
サンプルコードはこちら
# pip install google-genai
from google import genai
from google.genai import types
client = genai.Client(
api_key="YOUR_GEMINI_API_KEY"
)
MODEL = "gemini-3-flash-preview"
def smart_response(user_input: str):
prompt = f"""
以下の入力に対して、次の3点を日本語で出力してください。
1. 内容を一文で要約
2. 要点を3つ箇条書き
3. ユーザーが次に聞きそうな質問を2つ
入力:
{user_input}
"""
contents = [
types.Content(
role="user",
parts=[types.Part.from_text(prompt)],
)
]
config = types.GenerateContentConfig(
thinking_config=types.ThinkingConfig(
thinking_level="HIGH",
),
)
response = client.models.generate_content(
model=MODEL,
contents=contents,
config=config,
)
return response.text
if __name__ == "__main__":
text = "Gemini 3 Flashはどんな用途に向いているモデルなの?"
print(smart_response(text))結果はこちら
ご質問ありがとうございます。現時点でGoogleから発表されている最新の軽量モデルは「Gemini 1.5 Flash」ですので、その特徴に基づき回答いたします。
### 1. 内容を一文で要約
Gemini 1.5 Flashは、高速なレスポンスと高いコスト効率を維持しながら、長大なデータを一度に処理できる、スピードと実用性を重視したモデルです。
### 2. 要点を3つ箇条書き
* **高速・軽量なリアルタイム処理:** レイテンシ(応答速度)が非常に短いため、チャットボットの即答性や、スピードが求められるアプリケーションの開発に適しています。
* **100万トークンの広大なコンテキスト:** 軽量モデルでありながら、大量の文書、長い動画、数万行のコードなどを一度に読み込んで解析することが可能です。
* **優れたコストパフォーマンス:** 上位モデル(Pro)に比べて安価に利用できるため、要約、データ抽出、タグ付けなどの定型的な大量タスクに向いています。
### 3. ユーザーが次に聞きそうな質問を2つ
* 上位モデルである「Gemini 1.5 Pro」とは、具体的にどのような性能差や使い分けがありますか?
* Gemini 1.5 Flashを使って、具体的にどのような動画解析やデータ抽出ができますか?実際の処理速度については動画を見ていただくとわかりますが、結構速いと思います。一方で学習している時期が結構古いということもわかりました。
Gemini 3 Flashについてはリリース直後なので回答されないとしてもGemini 2.5 flashあたりなら回答されると思いましたが、期待した回答は得られませんでした。
なお、並列探索で調査精度を高めるGoogleのリサーチ特化AIであるGemini Deep Research agentについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

まとめ
本記事ではGemini 3 Flashの概要から仕組み、実際の使い方について解説をしました。
Gemini 2.5 Proを上回る性能を持ちつつ、高速・低コスト化されているので、非常に使い勝手の良いモデルだと思います。ぜひ皆さんも本記事を参考にGemini 3 Flashを使ってみてください!

最後に
いかがだったでしょうか?
Gemini 3 Flashが自社プロダクトに適しているか、まずは小さな検証から試してみてはいかがでしょうか。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。


