
【LFM2.5-1.2B-Thinking】Liquid AIが発表した1GB未満で動作可能な推論モデルを徹底解説!

- Liquid AI発、LFM2.5ファミリーに属する1.2Bパラメータの新型モデル
- 完全にオンデバイスで推論できるよう設計され、スマートフォン1台分(約900MB)のメモリ上で動作
- 同規模モデルとしては世界最速の推論速度と、サイズを超えた高品質な出力が特徴
2026年1月21日に、Liquid AIが1.2Bパラメータの新型モデル「LFM2.5-1.2B-Thinking」を公開しました!
このモデルは、完全にオンデバイスで推論できるよう設計されていて、スマートフォン1台分(約900MB)のメモリ上で動作します。
従来データセンターが必要だった高度な推論タスクが、今ではオフライン環境でも実行可能となり、同規模モデルとしては世界最速の推論速度と、サイズを超えた高品質な出力が特徴です。
そこで本記事では、LFM2.5-1.2B-Thinkingの概要や性能、使い方を徹底的に解説します。
ぜひ最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
LFM2.5-1.2B-Thinkingの概要

LFM2.5-1.2B-Thinkingは「LFM2.5」ファミリーの最新モデルで、特に、推論過程での思考トレース生成を重視して開発されています。
1.2Bパラメータの軽量モデルながら、強化学習による大規模な後訓練(28Tトークン以上)を経ていて、数学やツール操作などの複雑な問題解決に優れた性能を発揮します。
また、32Kトークンに達する長文コンテキストや、日本語を含む複数言語に対応しており、エッジデバイスでの実用的な運用が可能です。
他のLFM2.5モデルと同様にハイブリッドアーキテクチャを採用しており、推論時には、ロジック処理を明確にしながら高品質な回答を生成する設計になっています。
モデルカードや公式ブログでは、具体的なアーキテクチャやトレーニング手法について詳しく説明されているので、われわれ開発者は高度なファインチューニングや連想学習をかんたんに利用することができます。
なお、LFM2.5について詳しく知りたい方は、以下の記事も参考にしてみてください。

LFM2.5-1.2B-Thinkingの性能
公式ベンチマークによると、LFM2.5-1.2B-Thinkingは、サブ2Bパラメータのモデルの中でも最先端の推論性能を誇っています。
特に、同じLiquidAIの従来モデルや他社製の大型モデルと比較して、多くの推論タスクで上回っています。
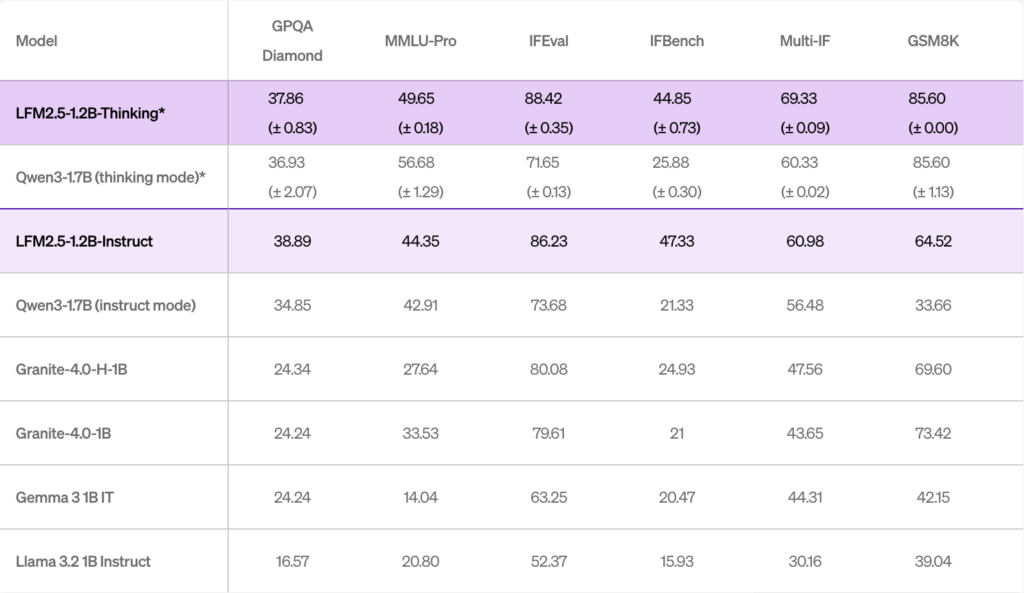
例えば、Qwen3-1.7B(同じく思考モード)の比較では、ほとんどのベンチマークでLFM2.5-1.2B-Thinkingが同等かそれ以上のスコアを記録しています。
パラメータ数は、Qwen3-1.7Bの40%少ない1.2Bであるにも関わらず、全体的な性能で優れ、出力トークン数も少なくて済むため計算効率が高いという特徴があります。
また、推論速度においても大きな優位があり、同規模モデルやハイブリッドアーキテクチャを圧倒する速度とメモリ効率を実現しています。
特に、ツール使用や数値計算など、エージェンティックなタスクで強みを発揮し、複数の推論フレームワークやNPUで最適化が進められている点も注目に値しますね。
公開資料では、既存モデルを上回る速度で長文(32Kトークン)の処理が可能であることも報告されており、エッジデバイスでの実用性が裏付けられています。


LFM2.5-1.2B-Thinkingのライセンス
LFM2.5-1.2B-Thinkingは、Liquid AIの独自「LFM Open License v1.0」で提供されています。
このライセンスはApache 2.0をベースとしており、一般的な利用や改変、再配布が許可されています。企業年商が1000万米ドル未満であれば、商用利用も無料で認められており、非営利研究用途においては制限なく利用できます。
| 利用用途 | 可否 | 備考 |
|---|---|---|
| 商用利用 | ⭕️ | 年商1,000万ドル未満まで無料 |
| 改変 | ⭕️ | |
| 配布 | ⭕️ | |
| 特許使用 | ⭕️ | |
| 私的使用 | ⭕️ |
LFM2.5-1.2B-Thinkingの料金
Liquid AIのモデルは基本的にオープンソースで無償提供されており、LFM2.5-1.2B-Thinkingも無料です。
誰でもセルフホストで自由にダウンロード・利用でき、スタートアップや個人利用で料金は発生しません。ただし企業向けには条件があり、年商1,000万ドル以上の企業は商用ライセンスが必要です。
LFM2.5-1.2B-Thinkingの使い方
LFM2.5の主な使い方としては、①スマートフォンでの利用、②PCでの利用、の2通りがあります。
①スマートフォンでの利用
1番かんたんなのは、Liquid AI公式のモバイルアプリ「Apollo」を使う方法です。
ApolloはiPhoneやアンドロイド端末で、LFMs(Liquid Foundation Models)を直接実行できる軽量アプリで、公式サイトの「Download Apolio」から無料でダウンロードできます。
インストールしたらアプリを起動し、使用するモデルとして最新のLFM2.5を選択します。
ここでLFM2.5-1.2B-Thinkingを選ぶことで、モデルを利用することができます。
使い方はシンプルで、チャットアプリのようにテキストを送信するだけです。インターネットに接続しなくても、端末内で完結してAIが応答してくれます。
なお、Apollo上では音声入力や音声読み上げにも対応しており、マイクアイコンをタップして話しかければ音声認識で質問ができて、モデルによる回答は、テキスト表示だけでなく音声でも返ってきます(端末のスピーカーから回答を読み上げてくれます)
②PCでの利用
Hugging FaceのモデルページからLFM2.5-1.2B-Thinkingの重みデータを取得し、自分の環境で実行することもできます。
Python環境で必要なライブラリをインストールします。
pip install torch transformers sentencepieceモデルとトークナイザーを読み込みます。
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "LiquidAI/LFM2.5-1.2B-Thinking"
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_id)チャット形式のプロンプトを作成し、生成を実行します。
prompt = "日本の首都はどこですか?"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=50, do_sample=False)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))全体のコードをまとめると以下のような形になります。
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
model_id = "LiquidAI/LFM2.5-1.2B-Thinking"
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
dtype="bfloat16",
# attn_implementation="flash_attention_2" <- uncomment on compatible GPU
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
prompt = "日本の首都はどこですか?"
input_ids = tokenizer.apply_chat_template(
[{"role": "user", "content": prompt}],
add_generation_prompt=True,
return_tensors="pt",
tokenize=True,
).to(model.device)
output = model.generate(
input_ids,
do_sample=True,
temperature=0.1,
top_k=50,
top_p=0.1,
repetition_penalty=1.05,
max_new_tokens=512,
streamer=streamer,
)これらの他にも、Liquid AIの提供するPlaygroundやLEAPプラットフォームを利用して、ブラウザ上でインタラクティブに試すこともできます。
LFM2.5-1.2B-Thinkingを使ってみた
それでは実際に、スマートフォンでダウンロードしたApolioアプリ上で、LFM2.5-1.2B-Thinkingを試してみます。
iOS端末、オフライン環境(機内モード、Wi-Fi接続なし)でモデルを実行していきます。
37×29+7は?多少思考開始までに時間はかかりましたが、15秒ほどで思考がスタートし、正確な答えを導き出してくれました。
続いてはごちゃごちゃな文章からの情報抽出と要件整理をしてもらいましょう。
次の文章は、議事メモがぐちゃぐちゃに貼られたものです。情報を整理し、抜けや矛盾があれば指摘してください。
【文章】
来週のMTGは火曜か水曜。火曜は午後ならOK。水曜は午前だけ…たぶん。
資料はA案ベースで作る。B案も念のため。担当は田中さん?いや鈴木さんかも。確認必要。
締切は1/28夜。できれば1/27中に初稿。
論点は「コスト」「スケジュール」「リスク」。ただリスクは今回触れない可能性あり。
参加者:私、田中、鈴木、あと佐藤さん(未確定)。
【やってほしいこと(重要)】
・「確定事項」「未確定事項」「要確認タスク」に分けて、自然な日本語の文章でまとめてください
・日付や曜日の矛盾があれば、どこが不明確かを具体的に指摘してください
・最後に、確認すべき質問文を4つだけ作ってください(相手にそのまま送れる文面)今回はすぐに思考開始してくれました。初回遅かったのは、モデルのロード直後だった影響もあるかもしれません。
内容としても、指示通りに要件ごとに情報を整理し、矛盾点の指摘、そして質問文の提案まで完璧にこなしてくれました。これを完全オフライン環境でこなしてくれるのは、非常にすばらしいですね。


まとめ
LFM2.5-1.2B-Thinkingは、Liquid AIの1.2Bパラメータ級の新型推論モデルで、900MBメモリのエッジデバイスでも動作する高効率設計が特徴です。
大型モデルに匹敵する思考性能と、高速な推論能力を兼ね備えており、多様なベンチマークで優れた結果を残しています。
気になる方は、ぜひ一度試してみてください!

最後に
いかがだったでしょうか?
弊社では、AI導入を検討中の企業向けに、業務効率化や新しい価値創出を支援する情報提供・導入支援を行っています。最新のAIを活用し、効率的な業務改善や高度な分析が可能です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。


