
【LongWriter】たった2分で2万文字のブログ記事を生成できるAI!長文出力でGPT-4oを超える?

\生成AIを活用して業務プロセスを自動化/
LongWriterの概要
これまでの大規模言語モデルは、長文テキスト生成が苦手でした。しかしLongWriterは従来の大規模言語モデルが生成できなかった長文テキストを生成可能なモデルです。
最大10,000ワードのテキストを生成することができ、従来の大規模言語モデルに比べて、非常に高品質なテキストを生成できます。
LongWiterが登場したことにより、高校や大学のレポート課題というものがなくなりそうです。生成速度もかなり速く、3.6万字程度の内容は1-2分で生成。
LongWiter開発の背景
これまで、大規模言語モデルでは、最大10万トークンの入力を処理できるにも関わらず、2,000語を超える出力を生成することが困難でした。これは、既存の大規模言語モデルの出力長が、教師あり微調整中に学習したサンプルの長さによって制限されるためです。
そのため、既存の教師あり微調整データセットには、長い出力の例が不足していたので大規模言語モデルは長い出力を生成するように効果的に学習ができません。
しかし、ChatCPTとGPT-4ユーザーとの会話ログ分析によると、ユーザーの1%以上が明示的に2,000語を超える出力を要求しており、この制限を克服することが課題でした。
これらの問題に対処するために、LongWiterは既存モデルの出力長に関する制限を克服し、より長く、より充実した出力を生成できるように開発されました。
教師あり微調整とは、規模言語モデルの能力を特定のタスクに特化させるために、ラベル付きデータセットを用いて追加学習を行うプロセス。
従来の大規模言語モデルの限界
Figure1は、縦軸が「出力長(Output Length)」、横軸は「要求された長さ(Required Length)」を表しており、グラフ内の各線は異なるモデルを表しています。グラフが表しているように、全てのモデルが約2000単語の出力長で限界に達していることがわかります。このことは、ほとんどのモデルが2000単語程度の長さまでしか生成できないことを示しています。
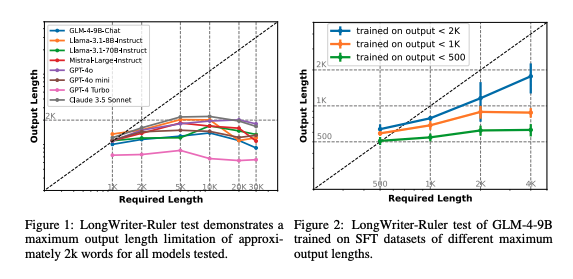
Figure2は、特定のモデル(GLM-4-9B)が異なる最大出力長のデータセットで訓練された場合のパフォーマンスを示しています。縦軸と横軸は同じく「出力長」と「要求された長さ」を表しており、線の色が異なる訓練データセット(出力長が500単語未満、1000単語未満、2000単語未満)を表しています。
グラフの結果から、訓練データセットの出力長の限界が大きいほど、より長い出力が可能になることがわかります。
AgentWriteの使用
AgentWriteは、既存の大規模言語モデルを使用して、より長く、より首尾一貫した文章を自動的に生成できるよう設計されたエージェントベースのパイプライン。AgentWriteは、人間が長い文章を書く際に、最初に構造を概説し、各セクションの内容と長さを計画することから着想を得ています。
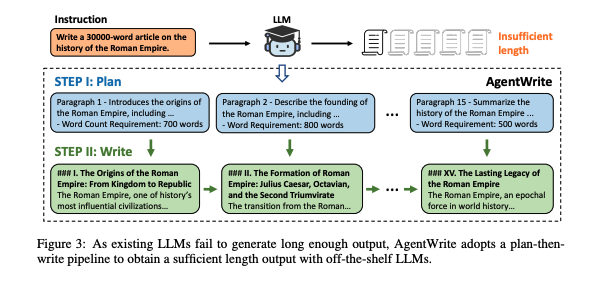
AgentWriteのステップとしては2段階です。
最初のステップは計画段階で、大規模言語モデルの計画能力を利用して、ユーザーの指示に基づいて詳細な執筆プランを作成します。
このプランには、各段落の主要な内容と単語数の要件が含まれており、例えば「ローマ帝国の歴史について30,000語の記事を書く」という指示が与えられた場合、AgentWriteは、各段落の主要なポイントと単語数の要件を概説した執筆プランを作成。
次に執筆ステップです。ステップ1で執筆プランを取得した後、AgentWriteは大規模言語モデルを順番に呼び出して各サブタスクを実行し、セクションごとに文章コンテンツを生成します。
出力の整合性を確保するため、n番目のセクションの生成をモデルに要求する場合、AgentWriteは、以前に生成されたn-1個のセクションも入力として提供。
これにより、モデルは既存の文章履歴に基づいて次のセクションを書き続けることができます。
この逐次的なアプローチは、複数のサブタスクを同時に完了するためにモデルを並列に呼びだすことを妨げますが、全体的な一貫性と品質は、並列に生成された出力よりもはるかに優れていることがわかっています。
Direct Preference Optimizationの使用
DPO(Direct Preference Optimization)は、LongWriter-9Bモデルに対して、出力の品質と指示内の長さ制限への追従能力をさらに向上させるために適用。
具体的には、教師ありファインチューニングを行ったLongWriter-9Bモデルに対して、DPOを実施しています。
このDPOデータは、GLM-4のチャットDPOデータ(約50,000件のエントリ)と、長い文章作成の指示に特化した4,000件のデータペアで構成されています。
長い文章作成の指示に特化したデータペアは、各文章作成の指示に対してLongWriter-9Bから4つの出力をサンプリングし、Hou et al.(2024)の方法に従ってスコアリングすることで構築されました。
このスコアには、式1で計算された長さ追従スコアも組み込まれています。

最もスコアの高い出力を正のサンプルとして選択し、残りの3つの出力からランダムに1つを選択して負のサンプルとします。最終的に得られたモデルであるLongWriter-9B-DPOは、上記のデータミックスを用いて250ステップ学習されました。
DPOの結果、出力の長さに関するスコア (Sl) と出力の品質に関するスコア (Sq) の両方が大幅に向上しました。この改善は、すべての出力長の範囲で一貫して見られました。
このことから、長い文章生成のシナリオにおいても、DPOはモデルの出力品質を向上させ、要求された長さにモデルの出力をより良く合わせることができると示唆されます。
LongBench-Write
LongBench-Writeは、モデルの長い文章生成能力を評価するために開発された包括的なベンチマークです。

このベンチマークには、出力長の指定が0~500語、500~2,000語、2,000~4,000語、4,000語以上の、多様なユーザーの指示が含まれています。
LongBench-Writeには、中国語と英語でそれぞれ60個ずつ、合計120個のユーザーの指示が含まれています。
これらの指示は、出力の長さと質の両方の観点から、モデルの出力内容がユーザーの指示とどの程度一致しているかを評価するために、明示的な単語数の要件を含むように設計されています。
LongBench-Writeに含まれる指示は、以下の7つのタイプに分類されています。
- 文学と創作
- 学術論文とモノグラフ
- 科学解説
- 実用文
- ニュース報道
- コミュニティフォーラム
- 教育と訓練
LongWriterのライセンス
LongWriterのライセンスはApache license2.0です。
オープンソースソフトウェアの利用を許可するライセンスで、自由に使用、改変、配布が可能です。商用利用も許されており、ソフトウェアを使用する際には特定の条件を満たす必要があります。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
なお、テキスト、画像、ビデオ、音声、全部対応できるLLMについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

LongWriterの使い方
実際にLongWiterをgoogle colaboratoryで実装していきましょう。
google colaboratoryを使う場合には、有料課金して、GPUをA100もしくはL4にして使う必要があります。そうしなければ、実行している間にGPUメモリが上限をオーバーします。
LongWriterを動かすのに必要な動作環境
LongWriterを実行した時の環境は以下です。
■Pythonのバージョン
Python 3.8以上
■使用ディスク量
53.3GB
■システムRAMの使用量
7.2GB
■GPU RAMの使用量
18.7GB
LongWriterの実装
まずは必要なパッケージをインストールします。次にモデルとトークナイザーの準備、推論の実行という流れです。今回はGPUメモリ節約のためにLongWriter-llama3.1-8bを使用します。モデルを「THUDM/LongWriter-glm4-9b」に変更すれば、GLM4-9Bベースで使用可能です。
パッケージのインストールはこちら
!pip install transformers
!pip install vllmモデルとトークナイザーの準備はこちら
from vllm import LLM
# モデルとトークナイザーの準備
model = LLM(
model= "THUDM/LongWriter-llama3.1-8b",
dtype="auto",
trust_remote_code=True,
tensor_parallel_size=1,
max_model_len=20000,
gpu_memory_utilization=0.9,
)
tokenizer = model.get_tokenizer()推論の実行はこちら
from vllm import SamplingParams
# パラメータの準備
generation_params = SamplingParams(
temperature=0.5,
top_p=0.8,
top_k=50,
max_tokens=10000,
repetition_penalty=1,
)
# プロンプトの準備
query = "Tell me about LLM. Answer in 5,000 words."
prompt = f"[INST]{query}[/INST]"
# 推論の実行
input_ids = tokenizer(prompt, truncation=False, return_tensors="pt").input_ids[0].tolist()
outputs = model.generate(
sampling_params=generation_params,
prompt_token_ids=[input_ids],
)
output = outputs[0]
print(output.outputs[0].text)LongWriterの凄さを検証
LongWriterの強みはなんといっても2万語生成できる点です。これは従来の大規模言語モデルではできません。
そこで、本記事での検証はLongWriterに2万語のテキストを出力させる、また生成AIとは?というテーマで初心者向けのブログ記事内容を書いてもらっていきます。
また、同じ内容をChatGPT-4oでも実行してみます。
プロンプト以外のコードはデモを実行した時と変わりません。「query」の部分にそれぞれ以下のプロンプトを入力して実行しています。
プロンプトはこちら
LLMとは?について20,000字でレポートを書いてください
What is LLM? Please write a 20,000 character report on
生成AIとは?というテーマで初心者向けのブログ記事内容を20,000字で書いてください。
What is Generative AI? Please write a 20,000 character blog post for beginners on the subject of実際にLongWriterで長文テキストを生成してみた所感としては、文字数については指定した方が長文生成してくれる可能性が高いこと、日本語でのプロンプト入力であれば日本語で生成してくれるが、生成時間は英語の方が短いっていう感じでした。
また、Chat-GPTもLongWriterもですが、日本語での生成は若干弱い感じがします。ハルシネーションが生じているというわけではなさそうですが、日本語だとエラーが出現していますね。
あとは生成速度。ChatGPT-4oでもLongWriterでも日本語に比べると圧倒的に英語での生成が速いです。これに関しては、そもそもの学習内容が英語だからということも影響していそうです。
しかし、これだけの文字数および内容について5分もかからずに生成できてしまうので、やはりこれからはレポート課題などについては、再考していく必要があるかもしれませんね。
なお、GPT-4o超えの日本語レベルを持つ1000億パラメータLLMについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。


