
NVIDIA「Nemotron 3 Nano」とは?100万トークン対応の超高速LLMを徹底解説
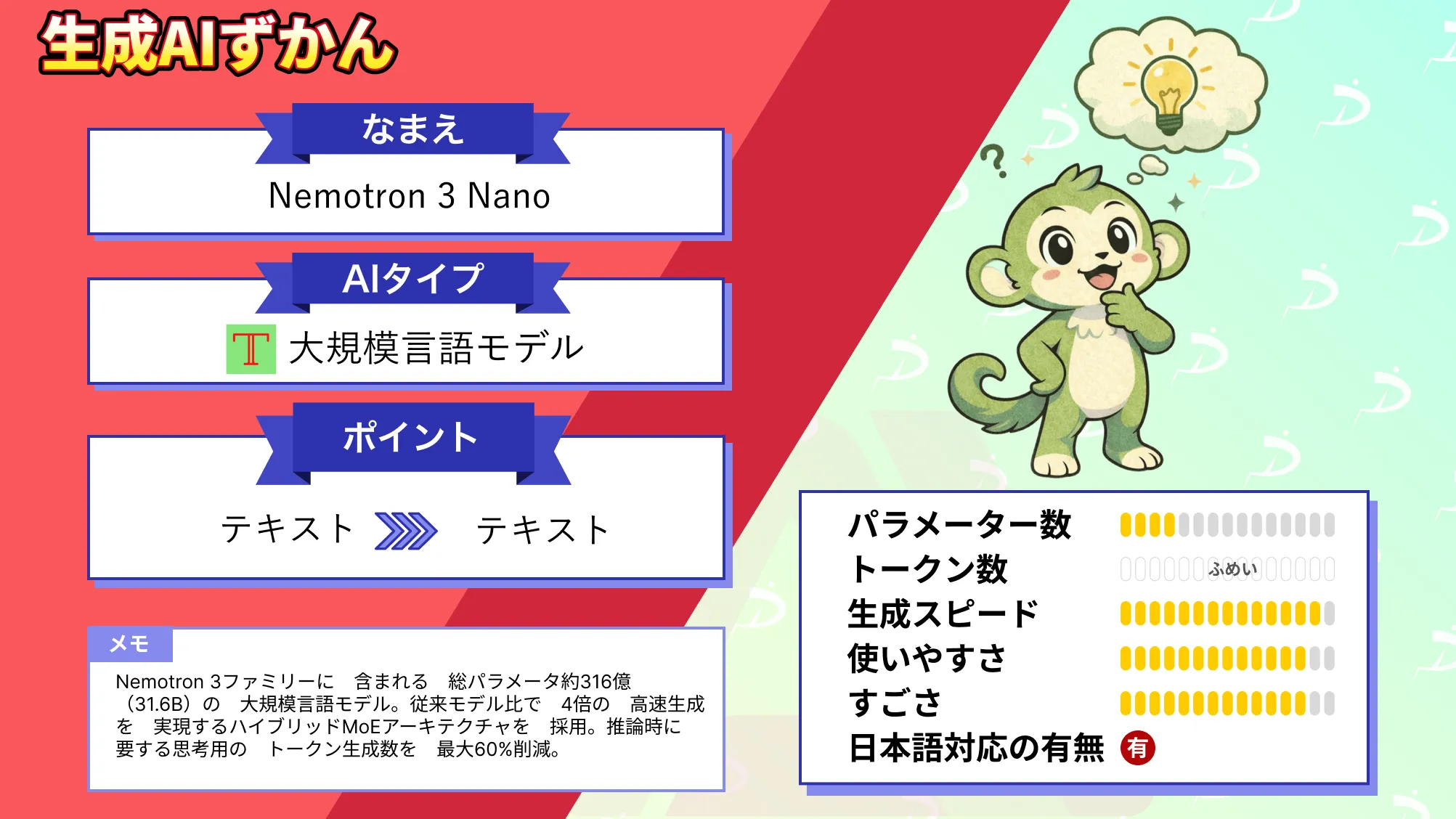
- Nemotron 3ファミリーに含まれる総パラメータ約316億(31.6B)の大規模言語モデル
- 従来モデル比で、4倍の高速生成を実現するハイブリッドMoEアーキテクチャを採用
- 推論時に要する思考用のトークン生成数を最大60%削減
2025年12月16日、NVIDIAは「Nemotron 3」ファミリーを発表しました!
この中で最小構成の「Nemotron 3 Nano」は、約316億パラメータ(31.6Bパラメータ)を持つモデルで、1トークンあたり約32億パラメータ(3.2B)が活性化される高効率な設計となっています。
NVIDIAは、このNemotron 3 Nanoを「エージェントAI向けの効率的な推論モデル」と位置づけており、従来モデル比で、4倍の高速生成を実現するハイブリッドMoEアーキテクチャを採用しています。
そこで本記事では、Nemotron 3 Nanoの概要や性能、使い方を徹底的に解説します。
ぜひ最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
Nemotron 3 Nanoの概要

Nemotron 3 Nanoは、総パラメータ約316億(31.6B)の大規模言語モデルです。
そのうち、トークンあたり約32億(3.2B)のパラメータのみが活性化され、余分な計算を抑えつつ高性能を発揮します。
アーキテクチャは、「Mamba-2」という状態空間モデル層と、Transformer層を組み合わせたハイブリッド型のMixture-of-Experts(MoE)構造になっています。
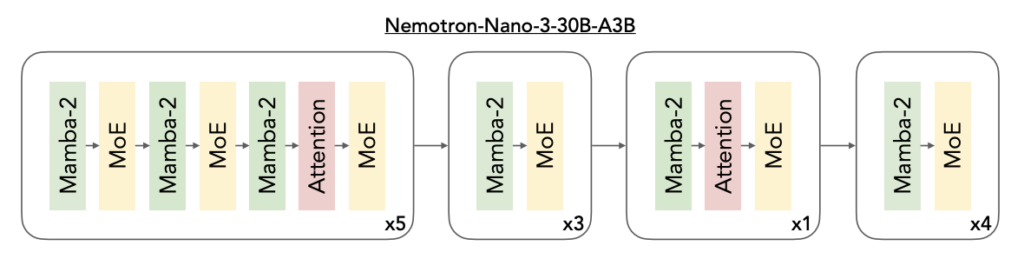
これによって、文脈長に対し、線形近くスケールするMamba層で長大シーケンスを効率的に処理し、Transformer層で精緻な推論を行います。
NVIDIAによると、Nemotron 3 Nanoは前世代のNemotron 2 Nanoより4倍速いトークン生成を実現し、推論時に要する思考用のトークン生成数を最大60%削減しているとのことです。
コンテキストウィンドウは、最大100万トークンに対応し、長文処理やマルチターン対話に適しています。
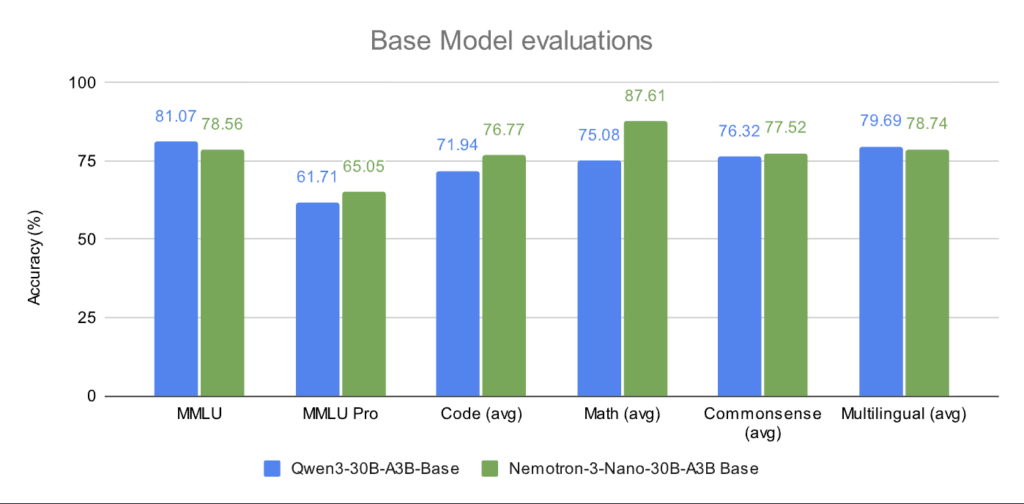
また、訓練データには、合計約10.6兆トークンが使用され(うち約3.5兆は合成データ)、数学的思考やコード生成、多言語対応を重視して強化されています。
言語対応としては、英語、日本語を含む20言語がサポートされています。
なお、NVIDIAのLllama-3.1-Nemotron-70B-Instructについて、詳しく知りたい方は、以下の記事も参考にしてみてください。

Nemotron 3 Nanoの性能
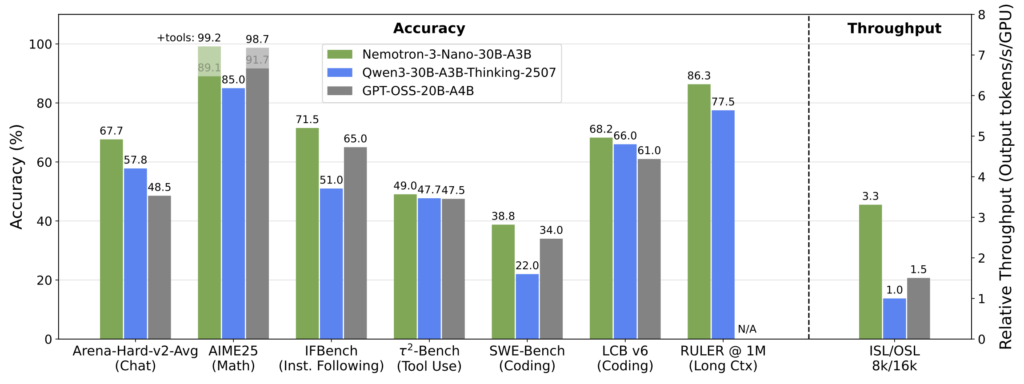
Nemotron 3 Nanoは、効率性と精度の両面で高い性能を誇っています。
先述のとおり、Nemotron 2 Nano比でトークン生成速度が4倍に向上し、ベンチマークでも、同クラスのオープンモデルを大きく上回るスループットを記録しました。
独立系ベンチマーカーによる検証では、約377トークン/秒という非常に高速な出力速度を達成し、MetaやMistralなど他社モデルを上回っているそうです。(※1)
精度面では、数学やコーディングなどの難問で優れた結果を出しています。
例えば、数学ベンチマーク「MATH」では、82.88%というスコアを記録し、類似モデル(Qwen3 30B-A3B)の61.14%を大きく上回りました。
コード生成タスク(HumanEval)でも78.05%を達成し、Qwen3の70.73%を上回っています。


Nemotron 3 Nanoのライセンス
Nemotron 3 Nanoは、NVIDIAのOpen Model License(OML)の下で公開されています。
| 利用用途 | 可否 | 備考 |
|---|---|---|
| 商用利用 | ⭕️ | |
| 改変 | ⭕️ | |
| 配布 | ⭕️ | |
| 特許使用 | ⭕️ | ただし、NVIDIAへの特許訴訟を提起するとライセンス失効 |
| 私的使用 | ⭕️ |
Nemotron 3 Nanoの料金
Nemotron 3 Nanoモデル自体のダウンロードは、オープンソースモデルとして無償で提供されています。
ただ、推論環境の選択によってコスト構造が異なってきます。
大規模運用では自己ホスティングが長期的には費用対効果が高い一方、手軽さを優先するならクラウドAPI(例: Baseten、DeepInfra、Amazon Bedrockなど)の利用が便利な可能性もあります。


Nemotron 3 Nanoの使い方
Nemotron 3 Nanoの代表的な利用方法には、①デモサイトでの利用、②Hugging Faceからダウンロード、の2種類があります。
①デモサイト
NVIDIAのデモページを開きます。右上にログインボタンが表示されますが、NVIDIAアカウントを持っていなくても、こちらのデモサイトは使うことができます。
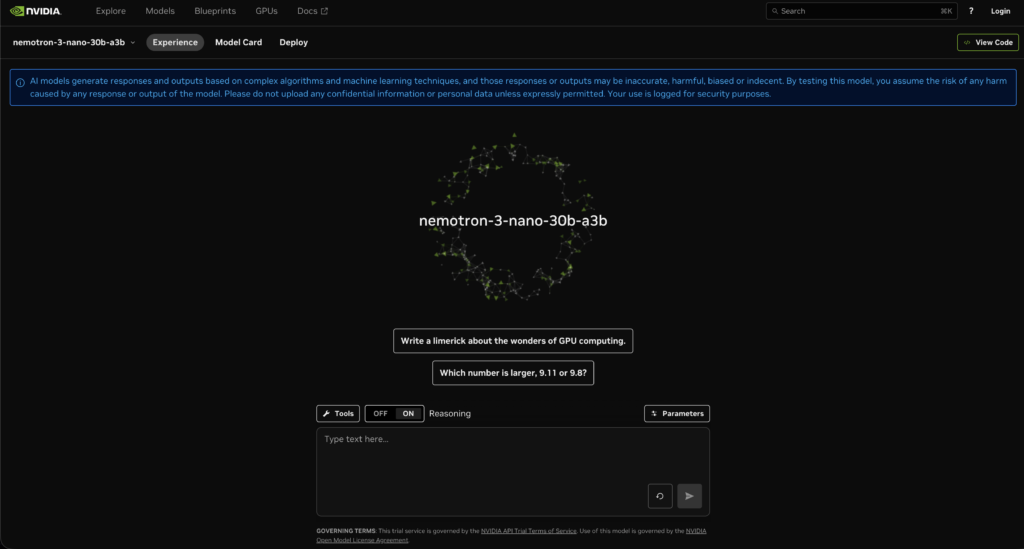
あとはテキスト入力欄で、プロンプトを書いて実行するだけです。
このページには、Reasoning(OFF/ON)のトグルがあり、ONにすると、推論過程を含む回答、OFFにすると最終回答のみ寄りの出力になります。
②Hugging Faceからダウンロード
Nemotron 3 NanoはHugging Face上で公開されているため、モデルID(例:nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-BF16)を指定して取得します。ローカルにダウンロードする場合、Hugging FaceのCLIを使うのが簡単です。
実行する際、Hugging Faceアクセストークンが必要なので、こちらから取得しておきましょう。
また、こちらのBF16モデルはモデルサイズが大きいので、ダウンロード前にストレージ等を確認するようにしましょう。
pip install -U "huggingface_hub[cli]"
huggingface-cli login
huggingface-cli download nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-BF16 \
--local-dir ./nemotron3nano-bf16 \
--local-dir-use-symlinks False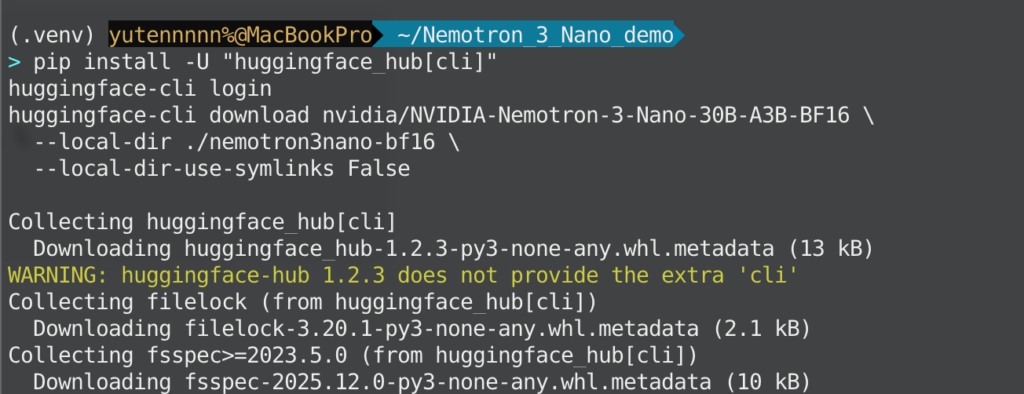
Hugging Faceアクセストークンは以下の部分で必要となります。

また、もしTransformersでそのままダウンロードするなら、公式の例と同じく AutoTokenizer / AutoModelForCausalLM でモデルIDを指定します。
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-BF16")
model = AutoModelForCausalLM.from_pretrained(
"nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-BF16",
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)Nemotron 3 Nanoを使ってみた
それでは、NVIDIAデモサイトでNemotron 3 Nanoを使ってみます。
日本語の長文要約タスク
プロンプトはこちら
あなたは日本語の編集者です。以下の長文を、事実を捏造せずに読み解き、読み手が「結局なにが重要か」を一発で掴める要約にしてください。
【出力ルール】
- 日本語のみ
- 出力は次の3部構成(見出しも含めてそのまま出す)
1) 要約(450〜650文字)
2) 重要ポイント(本文の事実だけで、3つ。各120〜180文字)
3) 論点と打ち手(論点2つ+打ち手2つ。各80〜140文字)
- 本文にない数字・固有名詞・因果は書かない
- 断定が難しい箇所は「〜と述べています」の形で書く
- 表現は自然で読みやすいですます調
【長文(この下をまるごと要約してください)】
――――――――――
【サンプル長文】
本レポートは、社内の問い合わせ対応(メール・チャット・電話)の負荷増大に対して、生成AIを用いた一次対応の自動化を検討した結果をまとめたものです。対象期間は2025年4月から10月で、部門はカスタマーサポート、物流、経理の3部門です。現状の課題として、問い合わせ件数の増加だけでなく、内容が複雑化している点が挙げられます。具体的には、配送遅延に起因する個別対応、請求書の再発行、返品ルールの例外処理などが重なり、担当者が同時に複数のタスクを処理しなければならない状態が継続しています。
期間中の総問い合わせ件数は約12万件で、月平均は約2万件でした。チャネル別ではチャットが約55%、メールが約35%、電話が約10%です。電話比率は低いものの、1件あたりの平均処理時間が最も長く、対応品質のブレも大きいという指摘があります。一次回答のテンプレートは存在しますが、更新が追いついておらず、最新のキャンペーン条件や例外規定が反映されていないケースが散見されました。その結果、担当者が個別に判断し、二次確認のやり取りが増えるという悪循環が起きています。
本検討では、一次対応を「受付」「状況確認」「FAQ回答」「必要情報の収集」「担当者への引き継ぎ」に分解し、それぞれに生成AIを適用できるかを評価しました。結論として、FAQ回答と必要情報の収集は自動化の効果が大きい一方で、返金の可否判断や例外処理の最終決定は人が担うべきだとしています。特に、規約の例外を認める判断には、顧客の利用履歴や過去のトラブル、キャンペーン適用条件など複数の情報を踏まえる必要があるため、誤判定のコストが高いという理由です。
プロトタイプは、ナレッジベース(社内規程・FAQ・手順書)を参照して回答を生成する方式を採用しました。回答の根拠となる文書の参照箇所を提示することで、担当者が確認しやすい形にしています。評価は、過去ログから抽出した1,000件の問い合わせで行い、正答率(想定する正しい回答に一致する割合)と、必要情報の回収率(引き継ぎに必要な項目が揃う割合)を測定しました。その結果、FAQ回答の正答率は83%で、必要情報の回収率は91%でした。一方で、返品・返金の境界にある問い合わせでは正答率が68%まで落ち、言い回しが強い顧客に対して過剰に譲歩する回答を出すケースが確認されました。
運用面では、回答のトーンと免責の書き方が重要だとしています。たとえば「返金します」と断定するのではなく、「状況を確認し、条件に合致する場合に返金の手続きをご案内します」といった表現に統一する必要があります。また、個人情報(住所・電話番号・注文番号)の取り扱いがチャネルによって異なるため、入力フォームの設計で漏えいリスクを下げることも必要です。加えて、ナレッジの更新フローを整備しないと、モデルの出力が古い規程に引っ張られるという懸念も述べています。
コスト試算では、一次対応の30%を自動化できれば、月あたりの削減工数は約1,200時間と見積もっています。これは、平均処理時間6分の問い合わせが月2万件あり、そのうち30%が一次対応で完結する前提です。一方、品質担保のためのレビュー工数として、初期は自動回答の10%をサンプリングし、人がチェックする体制を想定しています。これにより、導入初期の工数削減効果は目減りするものの、学習とナレッジ整備が進めば監査率を下げられるとしています。
リスクとしては、誤回答による炎上、規約違反の案内、差別的な表現、そして不適切な個人情報の取り扱いが挙げられています。対策として、出力のガードレール(禁止表現、断定禁止、根拠提示の必須化)に加え、センシティブなカテゴリは必ず人にエスカレーションするルールを設ける方針です。最後に、本レポートは「生成AIを入れれば終わり」ではなく、「運用設計とナレッジ更新が成果を左右する」と結論づけています。
――――――――――Nemotron 3 Nanoの出力結果はこちら
要約
本レポートは、2025年4月から10月までの期間にカスタマーサポート、物流、経理の3部門で発生した問い合わせ対応業務について、生成AIを用いた一次対応自動化の検討結果をまとめたものです。総問い合わせ件数は約12万件で、月平均は約2万件でした。チャネルはチャット約55%、メール約35%、電話約10%と分布しており、電話は処理時間が最も長く品質ブレが顕著です。また、チャネルごとの処理時間の違いが顕在化しており、チャットは短時間で済むケースが多いのに対し、電話は詳細な説明が必要となり、担当者の負担が増大しています。課題は件数だけでなく、配送遅延に起因する個別対応や請求書の再発行、返品ルールの例外処理などで内容が複雑化し、担当者が同時に複数のタスクを処理する状態が続いています。一次回答テンプレートはありますが、最新情報が反映されず担当者が個別に判断するため、二次確認が増加し、悪循環が生じています。評価ではFAQ回答と必要情報の収集を自動化し、過去ログ約1,000件の検証で正答率83%、必要情報回収率91%を記録し、返品・返金の境界問い合わせでは正答率が68%まで低下し、過剰譲歩が出るケースがありました。運用上は回答トーンの統一、免責表現の統一、個人情報の取り扱いリスク低減、ナレッジ更新フローの整備が重要とされ、一次対応の30%自動化で月約1,200時間の削減が見込まれますが、レビュー工数や誤回答・規約違反といったリスクも指摘されています。最終的に、単なるAI導入ではなく運用設計とナレッジ更新が成果を左右すると結論付けています。
重要ポイント 期間中の総問い合わせ件数は約12万件で、月平均は約2万件でした。チャネル別ではチャットが約55%、メールが約35%、電話が約10%と分布しており、電話は処理時間が最も長く品質ブレが顕著です。また、チャネルごとの処理時間の違いが顕在化しており、チャットは短時間で済むケースが多いのに対し、電話は詳細な説明が必要となり、担当者の負担が増大しています。課題は件数だけでなく、配送遅延に起因する個別対応や請求書の再発行、返品ルールの例外処理などで内容が複雑化し、担当者が同時に複数のタスクを処理する状態が続いています。一次回答テンプレートはありますが、最新のキャンペーン条件や例外規定が反映されておらず、担当者が個別に判断することで二次確認が増加し、悪循環が生じています。検証では、FAQ回答と必要情報の収集を自動化し、過去ログ約1,000件の評価で正答率83%、必要情報回収率91%を達成しましたが、返品・返金の境界にある問い合わせでは正答率が68%まで低下し、言い回しが強い顧客に対して過剰に譲歩する回答が出るケースが確認されました。運用上は回答トーンの統一、免責表現の統一、個人情報の取り扱いリスク低減、ナレッジ更新フローの整備が重要とされ、一次対応の30%自動化で月約1,200時間の削減が見込まれますが、レビュー工数や誤回答・規約違反といったリスクも指摘されています。
論点と打ち手 生成AIでの一次対応自動化は、FAQ回答や必要情報収集は有効と判明しているが、返金可否や例外処理の最終決定は誤判定リスクが高いため、人の関与が不可欠であることが課題です。ナレッジベースの更新が遅れると、AIが古い規程に基づいて回答し、誤った情報提供のリスクが生じるため、情報の常時更新体制が成果の可否を左右すことが課題です。出力のガードレールを強化し、禁止表現や断定表現を排除するとともに、センシティブなカテゴリは必ず有人にエスカレーションするフローを設けることで、誤回答や個人情報漏洩のリスクを低減できる。運用設計に加えて、ナレッジの定期的な見直しと更新プロセスを確立し、レビュー工数を段階的に縮小できる仕組みを構築すれば、長期的に自動化の効果を持続できる。(比較対象)Gemini 3 Proの出力結果はこちら
ご依頼の要約を作成しました。事実に基づき、編集者の視点で重要箇所を整理しています。
要約 本レポートは、2025年4月から10月にかけてカスタマーサポート、物流、経理の3部門で実施された、生成AIによる問い合わせ一次対応自動化の検討結果を報告するものです。月平均約2万件に上る問い合わせは内容が複雑化しており、既存テンプレートの更新遅れが担当者の負荷を高める悪循環を生んでいます。これに対し、ナレッジベースを参照する生成AIプロトタイプを検証した結果、FAQ回答の正答率は83%、必要情報の回収率は91%と高い効果が確認されました。
一方で、返品や返金の判断が難しいケースでは正答率が68%まで低下し、言い回しの強い顧客に対して過剰に譲歩する傾向が見られるなど、課題も明らかになっています。そのため、定型的なFAQ対応や情報収集は自動化しつつ、例外処理や最終判断は人が担うべきだとしています。コスト試算では、一次対応の30%を自動化することで月間約1,200時間の工数削減を見込んでいますが、導入初期には品質担保のための人的監査が必要であり、即座に全工数が削減されるわけではありません。
結論として、誤回答や炎上リスクを防ぐためのガードレール設定やエスカレーションルールの策定が不可欠です。生成AIの導入だけで課題が解決するのではなく、適切な運用設計とナレッジの継続的な更新こそが成果を左右すると述べています。
重要ポイント ● 問い合わせの現状とAIの適用範囲 期間中の問い合わせは月平均約2万件で、チャットとメールが約9割を占めますが、内容の複雑化とテンプレートの陳腐化が課題です。検証の結果、FAQ回答や情報収集にはAIが有効である一方、例外規定の適用や返金判断などの最終決定は誤判定のコストが高いため、人が行うべきだという役割分担が示されています。
● プロトタイプ検証で見えた精度と課題 過去ログを用いた検証では、FAQ回答で83%、情報回収で91%の精度を達成しました。しかし、返品・返金の境界事例では正答率が68%に留まり、AIが顧客に過剰譲歩するリスクが確認されています。また、回答には根拠となる文書の参照箇所を提示させることで、担当者の確認を容易にする工夫が有効であると述べています。
● コスト削減効果と運用の現実解 一次対応の30%が自動化されれば、月あたり約1,200時間の工数削減が可能と試算されています。ただし、導入初期は自動回答の10%を人がチェックする体制が必要なため、初期効果は限定的です。また、ナレッジの更新フローを整備しないとAIが古い情報に基づいて回答してしまうため、運用体制の構築が必須とされています。
論点と打ち手 ● 論点:誤回答リスクと回答品質の制御 返品・返金の判断が難しいケースや、強い口調の顧客に対して、AIが不適切な譲歩や誤った案内をするリスクがあります。また、断定的な表現によるトラブルや、個人情報の取り扱いにおける漏えいリスクも懸念されており、品質のブレをどう防ぐかが論点です。
● 打ち手:ガードレールの実装とエスカレーション 出力に対して「断定禁止」「根拠提示の必須化」などのガードレールを設けます。さらに、センシティブなカテゴリや判断に迷う案件は必ず人へエスカレーションするルールを徹底し、フォーム設計での個人情報保護対策も併せて行う必要があるとしています。
● 論点:ナレッジの鮮度維持とモデルの陳腐化 回答の根拠となる社内規定や手順書が更新されていない場合、AIが高い精度で「古い誤った回答」をしてしまう恐れがあります。現状でもテンプレート更新が追いついていない中、AI導入後にいかに最新情報を反映させ続けるかが重要な論点です。
● 打ち手:更新フローの整備と初期監査の実施 ナレッジ更新の業務フローを確立し、モデルが常に最新の規定を参照できる環境を整えます。また、導入初期は自動回答のサンプリングチェックを行うことで、誤回答を早期に発見・修正し、学習とナレッジ整備を進めながら徐々に監査率を下げていく方針です。どちらも概ね問題なく要約できているかと思います。
また、生成スピードはNemotoron 3 Nanoが約32秒、Gemini 3 Proが約29秒で、生成速度にほとんど差はないという結果でした。
Pythonコーディングタスク
プロンプトはこちら
あなたはPythonエンジニアです。以下の仕様を満たす「集計スクリプト」を作ってください。
私はコピペで動かして検証したいので、コードは1ファイル(Python)にまとめてください。
【目的】
注文データ(JSON文字列)を受け取り、日別売上と商品別売上ランキングを集計します。
【入力】
- 変数 `ORDERS_JSON` に、注文データのJSON文字列が入っているとします(下にサンプルあり)
- 各注文は以下のキーを持ちます:
- order_id: str
- ordered_at: str(ISO 8601、例 "2025-12-16T18:40:12")
- item: str
- unit_price: int(円)
- quantity: int
- status: str("paid" / "canceled" / "refunded")
- refunded_quantity: int(statusが"refunded"のときのみ有効。返金された数量)
【集計ルール】
1) 日別売上(YYYY-MM-DDごと)
- status="paid": unit_price * quantity を売上に加算
- status="canceled": 売上0(加算しない)
- status="refunded": unit_price * (quantity - refunded_quantity) を売上に加算(差額分だけ売上として残る)
2) 商品別売上(全期間合計)
- 上のルールと同じ計算で商品ごとに合計
- 売上が高い順に上位3つを出す(同点はitem名の辞書順)
【出力】
- 標準出力に、次の形式でprintしてください(JSONで)
{
"daily_revenue": {"2025-12-16": 12345, ...},
"top_items": [
{"item": "xxx", "revenue": 9999},
{"item": "yyy", "revenue": 8888},
{"item": "zzz", "revenue": 7777}
]
}
- daily_revenue の日付キーは昇順に並ぶようにしてください
- 外部ライブラリ禁止(標準ライブラリのみ)
- 型ヒントとdocstringを必ず付ける
- 例外処理:JSONが壊れている/キーが欠けている場合は、理由が分かるエラーメッセージを出して終了
【サンプル】
ORDERS_JSON = r'''
[
{"order_id":"A001","ordered_at":"2025-12-16T09:10:00","item":"camera","unit_price":50000,"quantity":1,"status":"paid"},
{"order_id":"A002","ordered_at":"2025-12-16T10:20:00","item":"lens","unit_price":30000,"quantity":2,"status":"paid"},
{"order_id":"A003","ordered_at":"2025-12-16T11:30:00","item":"camera","unit_price":50000,"quantity":1,"status":"canceled"},
{"order_id":"A004","ordered_at":"2025-12-17T08:05:00","item":"bag","unit_price":8000,"quantity":3,"status":"paid"},
{"order_id":"A005","ordered_at":"2025-12-17T12:45:00","item":"lens","unit_price":30000,"quantity":2,"status":"refunded","refunded_quantity":1},
{"order_id":"A006","ordered_at":"2025-12-17T15:00:00","item":"strap","unit_price":1500,"quantity":5,"status":"paid"}
]
'''
【期待する出力イメージ(数値はこのサンプルに基づく)】
daily_revenueは
- 2025-12-16: 50000 + 30000*2 = 110000
- 2025-12-17: 8000*3 + 30000*(2-1) + 1500*5 = 24000 + 30000 + 7500 = 61500
top_itemsは売上上位3つ(camera, lens, bag など)になります。
では、完成したPythonコードを提示してください。Nemotron 3 Nanoの出力結果はこちら(コード部分のみ抜粋)
import json
import sys
from datetime import datetime
from typing import Dict, List, Any
# ----------------------------------------------------------------------
# 型エイリアス(可読性向上のため)
# ----------------------------------------------------------------------
Order = Dict[str, Any]
Result = Dict[str, Any]
def _parse_order(order: Order) -> tuple[str, int]:
"""
1 件の注文辞書を検証・正規化し、売上算出に必要な情報を返す。
Returns
-------
(date_str, revenue) : Tuple[str, int]
* date_str : ordered_at の日付部分 (YYYY-MM-DD)
* revenue : その注文が売上に寄与する金額(int)
Raises
------
KeyError : 必須キーが不足している場合
ValueError : 日付形式が ISO 8601 でない、status が不正、数値が整数でない etc.
"""
# ---- 必須キーの存在確認 ----
required_keys = {"order_id", "ordered_at", "item", "unit_price",
"quantity", "status"}
missing = required_keys - order.keys()
if missing:
raise KeyError(f"missing required key(s): {', '.join(sorted(missing))}")
# ---- 型・値の基本チェック ----
try:
ordered_at: str = order["ordered_at"]
item: str = order["item"]
unit_price: int = int(order["unit_price"])
quantity: int = int(order["quantity"])
status: str = order["status"]
except (ValueError, TypeError) as exc:
raise ValueError(f"type conversion error in order: {exc}") from exc
# ---- status 別の売り上げ計算ロジック ----
if status == "paid":
revenue = unit_price * quantity
elif status == "canceled":
revenue = 0
elif status == "refunded":
# refunded_quantity は必須ではないが、status が refunded なら存在すべき
refunded_quantity = int(order.get("refunded_quantity", 0))
if refunded_quantity < 0:
raise ValueError("refunded_quantity must be non‑negative")
revenue = unit_price * (quantity - refunded_quantity)
else:
raise ValueError(f"unknown status: {status!r}")
# ---- 日付の正規化 (YYYY-MM-DD) ----
try:
date_obj = datetime.fromisoformat(ordered_at)
except ValueError as exc:
raise ValueError(f"ordered_at is not ISO 8601: {ordered_at}") from exc
date_str = date_obj.strftime("%Y-%m-%d")
return date_str, revenue
def aggregate(orders_json: str) -> Result:
"""
JSON 文字列を解析し、日別売上辞書と商品別上位ランキングを集計して返す。
Parameters
----------
orders_json : str
注文データの JSON 文字列(配列形式)
Returns
-------
Result
{
"daily_revenue": dict[date_str] -> int,
"top_items" : list[{"item": str, "revenue": int}, ...]
}
Raises
------
json.JSONDecodeError : 文字列が有効な JSON でない場合
KeyError / ValueError : データの構造・形式が期待と異なる場合
"""
try:
orders: List[Order] = json.loads(orders_json)
except json.JSONDecodeError as exc:
raise json.JSONDecodeError(f"invalid JSON: {exc.msg}", exc.doc, exc.pos) from exc
if not isinstance(orders, list):
raise ValueError("root JSON must be an array of order objects")
daily_rev: Dict[str, int] = {}
item_rev: Dict[str, int] = {}
for idx, order in enumerate(orders):
try:
date_str, revenue = _parse_order(order)
except (KeyError, ValueError) as exc:
raise ValueError(f"error in order #{idx}: {exc}") from exc
# 日別売上集計
daily_rev[date_str] = daily_rev.get(date_str, 0) + revenue
# 商品別売上集計
item_rev[item] = item_rev.get(item, 0) + revenue
# 上位 3 商品を作成(売上降順、同点はアイテム名昇順)
sorted_items = sorted(
item_rev.items(),
key=lambda kv: (-kv[1], kv[0]) # revenue descending, item ascending
)
top_items = [
{"item": item, "revenue": rev}
for item, rev in sorted_items[:3]
]
# daily_revenue のキーを昇順に並べ替えて dict に格納(順序保持)
sorted_daily = dict(sorted(daily_rev.items()))
return {"daily_revenue": sorted_daily, "top_items": top_items}
def _main() -> None:
"""
スクリプト実行エントリーポイント。
ORDERS_JSON 変数に格納されたサンプルデータを使用し、集計結果を stdout に出力する。
エラーが発生した場合は stderr にエラーメッセージを書き出して sys.exit(1) で終了。
"""
# --------------------------------------------------------------
# 1. 入力データ(サンプル) -------------------------------------------------
# --------------------------------------------------------------
ORDERS_JSON = r'''
[
{"order_id":"A001","ordered_at":"2025-12-16T09:10:00","item":"camera","unit_price":50000,"quantity":1,"status":"paid"},
{"order_id":"A002","ordered_at":"2025-12-16T10:20:00","item":"lens","unit_price":30000,"quantity":2,"status":"paid"},
{"order_id":"A003","ordered_at":"2025-12-16T11:30:00","item":"camera","unit_price":50000,"quantity":1,"status":"canceled"},
{"order_id":"A004","ordered_at":"2025-12-17T08:05:00","item":"bag","unit_price":8000,"quantity":3,"status":"paid"},
{"order_id":"A005","ordered_at":"2025-12-17T12:45:00","item":"lens","unit_price":30000,"quantity":2,"status":"refunded","refunded_quantity":1},
{"order_id":"A006","ordered_at":"2025-12-17T15:00:00","item":"strap","unit_price":1500,"quantity":5,"status":"paid"}
]
'''
# --------------------------------------------------------------
# 2. 集計実行 & 結果出力 ---------------------------------------------
# --------------------------------------------------------------
try:
result = aggregate(ORDERS_JSON)
except (json.JSONDecodeError, KeyError, ValueError) as exc:
# エラー理由を標準エラー出力に出して終了
print(f"Error: {exc}", file=sys.stderr)
sys.exit(1)
# JSON 出力(ensure_ascii=False で日本語等文字化け防止、indent=2 で見やすく)
print(json.dumps(result, ensure_ascii=False, indent=2))
if __name__ == "__main__":
_main()(比較対象)Gemini 3 Proの出力結果はこちら(コード部分のみ抜粋)
import json
import sys
from collections import defaultdict
from typing import List, Dict, Any, Union
# サンプルデータ
ORDERS_JSON = r'''
[
{"order_id":"A001","ordered_at":"2025-12-16T09:10:00","item":"camera","unit_price":50000,"quantity":1,"status":"paid"},
{"order_id":"A002","ordered_at":"2025-12-16T10:20:00","item":"lens","unit_price":30000,"quantity":2,"status":"paid"},
{"order_id":"A003","ordered_at":"2025-12-16T11:30:00","item":"camera","unit_price":50000,"quantity":1,"status":"canceled"},
{"order_id":"A004","ordered_at":"2025-12-17T08:05:00","item":"bag","unit_price":8000,"quantity":3,"status":"paid"},
{"order_id":"A005","ordered_at":"2025-12-17T12:45:00","item":"lens","unit_price":30000,"quantity":2,"status":"refunded","refunded_quantity":1},
{"order_id":"A006","ordered_at":"2025-12-17T15:00:00","item":"strap","unit_price":1500,"quantity":5,"status":"paid"}
]
'''
def calculate_single_order_revenue(order: Dict[str, Any]) -> int:
"""
1注文あたりの売上をステータスに応じて計算する。
Args:
order (Dict[str, Any]): 注文情報の辞書
Returns:
int: 計算された売上金額
Raises:
KeyError: 必要なキーが存在しない場合
"""
status = order.get("status")
unit_price = order.get("unit_price")
quantity = order.get("quantity")
# 必須キーの簡易チェック (Noneチェック)
if unit_price is None or quantity is None or status is None:
missing = [k for k in ["unit_price", "quantity", "status"] if order.get(k) is None]
raise KeyError(f"Missing required fields: {missing} in order {order.get('order_id', 'Unknown')}")
if status == "paid":
return unit_price * quantity
elif status == "canceled":
return 0
elif status == "refunded":
refunded_qty = order.get("refunded_quantity")
if refunded_qty is None:
raise KeyError(f"Missing 'refunded_quantity' for refunded order: {order.get('order_id')}")
# 部分返金を考慮した売上計算
return unit_price * (quantity - refunded_qty)
else:
# 未知のステータスは一旦0とするか、要件によってはエラーにする
# ここでは計算対象外として0を返す
return 0
def process_orders(json_str: str) -> None:
"""
JSON文字列を受け取り、日別売上と商品別ランキングを集計して標準出力する。
Args:
json_str (str): 注文データを含むJSON文字列
"""
try:
orders: List[Dict[str, Any]] = json.loads(json_str)
except json.JSONDecodeError as e:
print(f"Error: Invalid JSON format. Reason: {e}", file=sys.stderr)
sys.exit(1)
daily_revenue: Dict[str, int] = defaultdict(int)
item_revenue: Dict[str, int] = defaultdict(int)
# 必須キーの存在確認用セット
required_keys = {"order_id", "ordered_at", "item", "unit_price", "quantity", "status"}
for i, order in enumerate(orders):
# 1. キーのバリデーション
if not required_keys.issubset(order.keys()):
missing = required_keys - order.keys()
print(f"Error: Missing keys {missing} in record index {i}", file=sys.stderr)
sys.exit(1)
try:
# 2. 売上計算
revenue = calculate_single_order_revenue(order)
# 3. 日別集計 (YYYY-MM-DD)
# ISO 8601形式 "YYYY-MM-DDTHH:MM:SS" の先頭10文字を取得
ordered_at = order["ordered_at"]
if not isinstance(ordered_at, str) or len(ordered_at) < 10:
raise ValueError(f"Invalid date format: {ordered_at}")
date_key = ordered_at[:10]
daily_revenue[date_key] += revenue
# 4. 商品別集計
item_name = order["item"]
item_revenue[item_name] += revenue
except (KeyError, ValueError, TypeError) as e:
print(f"Error processing order {order.get('order_id', 'Unknown')}: {e}", file=sys.stderr)
sys.exit(1)
# --- 結果の整形 ---
# 日別売上: 日付昇順
sorted_daily = dict(sorted(daily_revenue.items()))
# 商品別ランキング: 売上降順、同点なら商品名辞書順(昇順)
# item_revenue.items() -> [('camera', 50000), ...]
sorted_items_list = sorted(
item_revenue.items(),
key=lambda x: (-x[1], x[0])
)
# 上位3件を抽出し、指定の辞書形式に変換
top_3_items = [
{"item": name, "revenue": rev}
for name, rev in sorted_items_list[:3]
]
# 出力データの構築
output_data = {
"daily_revenue": sorted_daily,
"top_items": top_3_items
}
# JSONとして標準出力
print(json.dumps(output_data, indent=2, ensure_ascii=False))
if __name__ == "__main__":
process_orders(ORDERS_JSON)どちらもコード設計は良い感じですが、Nemotron 3 Nano側は、aggregate()内でitem_rev[item]を更新しているのに 、itemがそのスコープで定義されておらずNameErrorが発生するかと思います。
堅牢性の観点では、Nemotron 3 Nanoのほうがパッと見よさそうなので、このitemバグを修正すれば、Gemini 3 Proとも対等に戦えるレベルだと感じました。
また、生成スピードでは、Nemotron 3 Nanoが約7秒、Gemini 3 Proが約38秒で、Nemotron 3 Nanoの圧勝でした。
以上、2つのタスクで検証してみました。
みなさんもぜひ、ご自身のタスクで試してみてください。
まとめ
NVIDIA Nemotron 3 Nanoは、エージェントAIや長文処理向けに最適化された高効率オープンモデルです。
ハイブリッドMoEアーキテクチャの採用で4倍速の推論を可能にし、1,000,000トークンという巨大コンテキストを扱うことができます。
今後、Nemotron 3 Super/Ultra(約100B/500Bパラメータ)が2026年上半期に予定されていて、さらなる大規模モデルと組み合わせたエージェントAIシステム構築も視野に入ってきそうです。(※2)
長文理解や複数エージェント連携など、開発者にとって、Nemotron 3 Nanoは試す価値のある革新的なモデルだと思いますので、気になる方は試してみてください!

最後に
いかがだったでしょうか?
弊社では、AI導入を検討中の企業向けに、業務効率化や新しい価値創出を支援する情報提供・導入支援を行っています。最新のAIを活用し、効率的な業務改善や高度な分析が可能です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。


