
最大24分の音声も一発変換!「NVIDIAのParakeet」次世代音声認識の実力とは?
- NVIDIA発の超高精度な自動音声認識
- 他の音声モデルと比べ50倍高速化
- 最大24分の音声を一回で処理可能
2025年5月1日、NVIDIAからオープンソースの自動音声認識モデルが登場!
今回リリースされたParakeet TDT 0.6B V2(Parakeet)はOpen-ASR-Leaderboardで業界最高の6.05%の単語エラー率を達成しており、非常に精度の高い高速推論を実現しています。
本記事ではParakeetの概要から使い方について解説をします。本記事を最後までお読みいただければ、Parakeetの理解が深まります。
ぜひ最後までお読みください。
\生成AIを活用して業務プロセスを自動化/
Parakeetの概要
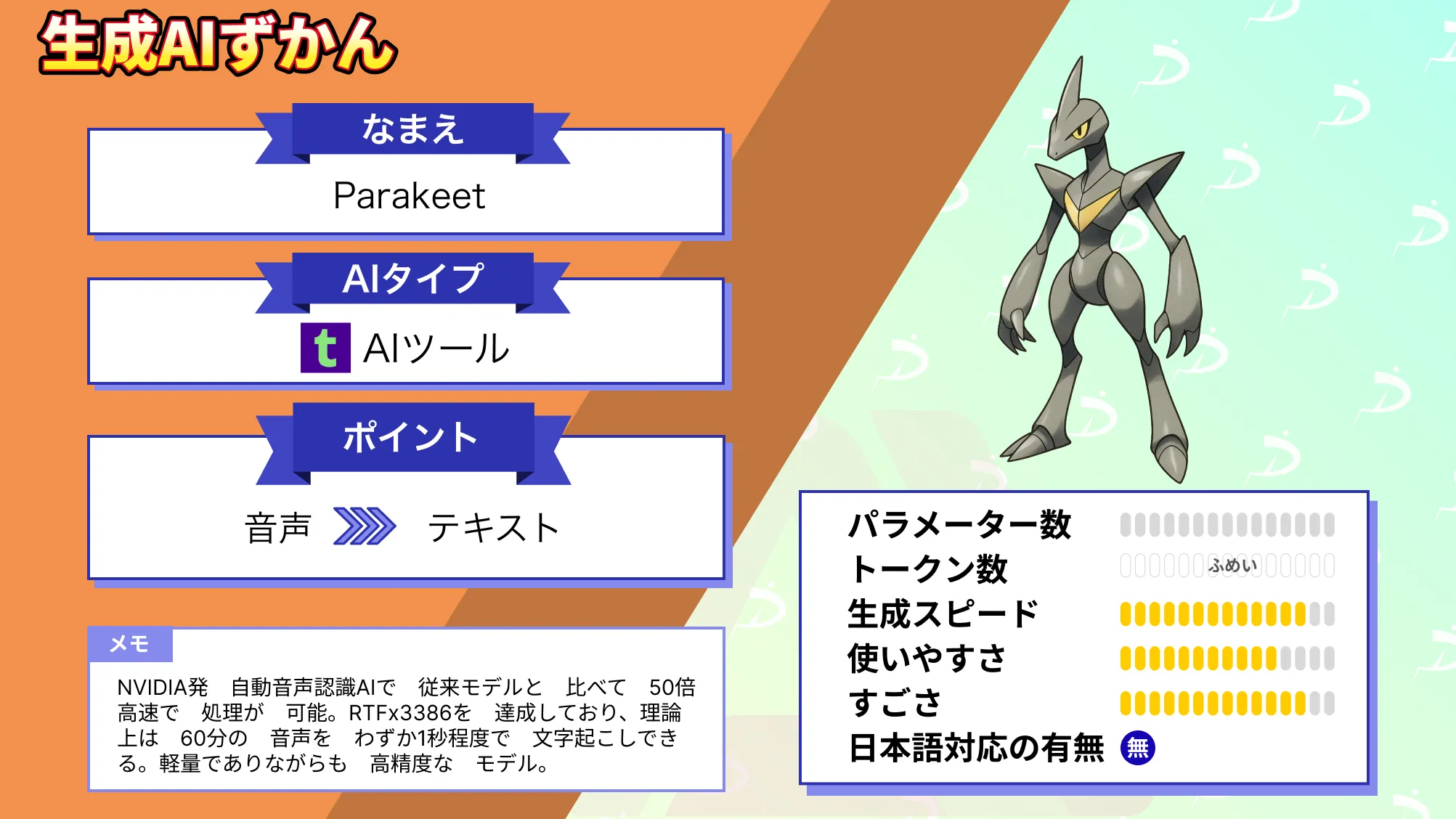
ParakeetはNVIDIAがリリースした自動音声認識モデル。6億のパラメータを持ち、英語音声の文字起こしに特化しています。
Hugging Faceの音声認識リーダーボードでは、従来のモデルに比べはるかに高い精度の平均単語エラー率6.05%を実現。
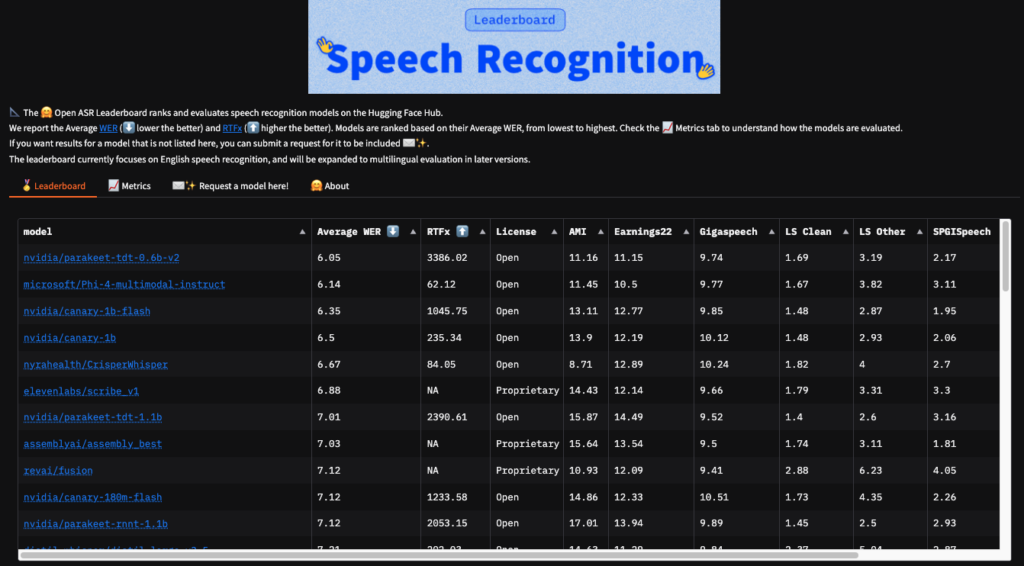
Parakeetの処理速度は、他のモデルの50倍以上の速さであり、RTFx3386を達成しています。
RTFxとは:音声認識モデルの処理速度を評価するための指標。RTF=処理にかかった時間/音声の実時間
RTF < 1.0の時、実時間処理が可能です。「x」は倍速を表しており、「RTFx = 1.0」であれば、音声1秒の処理にちょうど1秒かかる(リアルタイム)。「RTFx = 0.5」であれば音声1秒を0.5秒で処理をするため2倍速になります。
つまりParakeetは音声1秒を1/3386秒で処理することが可能。一度に処理可能な音声時間は最大24分であり、60分の音声であればわずか1秒程度で処理が可能という計算になります。
Parakeetの学習データ
Parakeetはさまざまな音声環境でも高精度な文字起こしを実現するために、約12万時間におよぶ学習データ「Granary Dataset」を使用。
Granary Datasetには1万時間の高品質な人の音声データと11万時間の擬似ラベル付き音声が含まれており、このデータセットによって音質・話者・話題・雑音など、あらゆる条件に対応することが可能になっています。
「1万時間の高品質な人の音声データ」には、書籍の朗読を中心とした音声や日常会話を中心とする多話者データ、英国アクセントを含む音声など多様な音声が含まれています。


Parakeetの性能
Parakeetの性能はベース性能/音質変化耐性/ノイズ耐性、3つの評価がされています。
まずベース性能についてです。
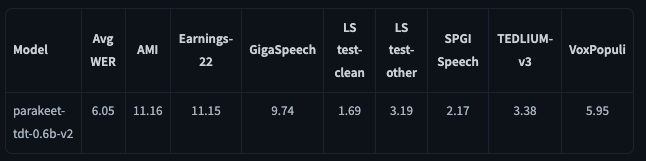
ベース性能は外部言語モデルを使わずにTransducerデコーダのGreedy Decodingで得られたWER。平均WERは6.05%であり、非常に精度が高いことがわかります。
また、会議音声や演説音声(AMIとVoxPopuli)といった特定のドメインにおいても、WERは10%〜11%程度と実用的なレベルを達成。
次に、電話音声に対する性能です。これは、標準的な16kHzサンプリングの音声を、電話品質である8kHzにダウンサンプリングした場合のWERを評価したもの。
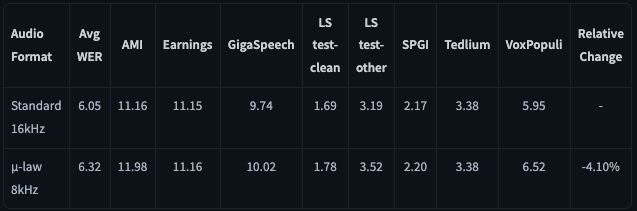
結果として、16kHzでの平均WER 6.05%に対し、8kHzでは6.32%と、電話音声特有の周波数帯域制限による性能低下はごくわずかでした。特にLibriSpeech-cleanやEarnings-22のようなデータセットでは、性能低下はほとんど見られません。
平均するとWERの相対的な悪化は+4.1%に留まっており、このことからParakeetが電話音声にも十分対応可能な認識精度を持つことがわかります。
最後にノイズ環境での性能です。
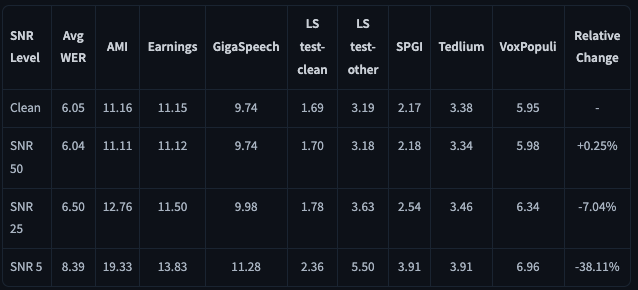
ノイズ環境での性能はMUSANの音声とノイズを使用して異なるSignal-to-Noise Ratio条件でWERを評価。
50dBの環境では平均WERは6.04、25dBの平均WERは6.50、5dBの環境では8.39となっています。25dB~5dBの強いノイズ下でも実用レベルを維持しており、Parakeetはノイズ環境にも強いことがわかります。
また、Parakeetは文字起こしだけではなく、句読点や大文字、正確なタイムスタンプ予測、歌詞の文字起こし、数字フォーマットなどの機能もあり、多種多様なアプリに組み込むことが可能です。
Parakeetのライセンス
Parakeetのライセンスは「CC-BY-4.0 ライセンス」のもと、特許使用以外の用途、つまり商用利用や改変が許可されています。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ❌(別途申請が必要) |
| 私的使用 | ⭕️ |
なお、OpenAIの音声合成モデルGPT-4o Mini TTSについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
Parakeetの使い方
ParakeetはHugging Faceにデモが用意されているので、そちらから使うことができます。
またHugging Faceではtransformersでは使えず、nemo_toolkitを使用する必要があります。
まずはHugging Faceのデモを使ってみます。リアルタイム処理なので、ファイルのアップロードはありません。なのでリアルタイムでスティーブ・ジョブズのスピーチをマイクに向かって流して、処理してもらいます。
結果はこちら
I'm honored to be with you today for your commencement from one of the finest universities in the world. Truth be told, I never graduated from college, and this is the closest I've ever gotten to a college graduation.文字起こしされたものを見てみると適切に文字起こしされている気がします。
テキストにまとめてくれているものがあるので、そちらと見比べてみると、適切に文字起こしできていることもわかります。

google colaboratoryを使って文字起こしができるか検証
ではgoogle colaboratoryでParakeetを使ってみます。
まずはライブラリのインストール。
!pip install --upgrade pip
!pip install torch torchaudio --index-url https://download.pytorch.org/whl/cu118
!pip install nemo_toolkit[asr] --quiet次にモデルのロードです。
import nemo.collections.asr as nemo_asr
asr_model = nemo_asr.models.ASRModel.from_pretrained(model_name="nvidia/parakeet-tdt-0.6b-v2")モデルのロードをすると下記のエラーが出ます。
RuntimeError: Detected that PyTorch and torchvision were compiled with different CUDA major versions. PyTorch has CUDA Version=11.8 and torchvision has CUDA Version=12.4. Please reinstall the torchvision that matches your PyTorch install.なのでバージョンを指定して、もう一度ライブラリをインストールします。
!pip install torch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 --index-url https://download.pytorch.org/whl/cu118もう一度モデルのロードをしますが、別のエラーが出ます。
ModuleNotFoundError: No module named 'torch.nn.attention'ライブラリのバージョンを色々変更して、試してみましたがgoogle colaboratoryでの実装はなかなか難しいため、Vast.aiでGPUを借りて実装してみます。
今回は1x H100 SXMをレンタルします。
そうしたらNotebookを使えるので、Notebookでコーディングしていきます。また、デフォルトのPytorchのバージョンが低いので、アップデートする必要があります。
!pip install --upgrade torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118ライブラリのインストールが終わったら、nemoを入れます。
!pip install nemo_toolkit[asr] --use-pep517Hugging Faceでは「–use-pep517」の記載がありませんでしたが、–use-pep517無しで実行したらエラーになったので、つけます。
ようやくモデルのダウンロードです。
import nemo.collections.asr as nemo_asr
asr_model = nemo_asr.models.ASRModel.from_pretrained(model_name="nvidia/parakeet-tdt-0.6b-v2")モデルのダウンロードが終わったら、NotebookのHomeに戻って、音声をアップロードします。アップロードしたパスをコピーして下記に貼り付けます。
コードはこちら
import os
from IPython.display import display
from IPython.display import Audio as IPAudio
from pydub import AudioSegment
AUDIO_PATH = "ここにコピーしたパスを入力"
assert os.path.isfile(AUDIO_PATH), f"ファイルが見つかりません: {AUDIO_PATH}"
display(IPAudio(AUDIO_PATH))
# ステレオ → モノラル変換
stereo_audio = AudioSegment.from_wav(AUDIO_PATH)
mono_audio = stereo_audio.set_channels(1)
MONO_AUDIO_PATH = "新しい名前をつける"
mono_audio.export(MONO_AUDIO_PATH, format="wav")
# 音声認識
result = asr_model.transcribe([MONO_AUDIO_PATH])
print("認識結果:", result[0].text)アップロードした音声をそのまま使ったら、ステレオ音声は使えないのでモノラルにしろ、とエラーが出てしまったので上記のコードではステレオ→モノラル変換を入れています。「新しい名前をつける」と書いている部分にモノラルに変更した際のファイル名をつけてください。
これでようやく音声認識がされます。
結果はこちら
認識結果: This program is brought to you by Stanford University. Please visit us at stanford.edu. Thank you. I'm honored to be with you today for your commencement from one of the finest universities in the world. Truth be told, I never graduated from college, and this is the closest I've ever gotten to a college graduation. Today, I want to tell you three stories from my life. That's it. No big deal. Just three stories. The first story is about connecting the dots. I dropped out of Reed College after the first six months, but then stayed around as a drop-in for another 18 months or so before I really quit. So why did I drop out? It started before I was born. My biological mother was a young, unwed graduate student, and she decided to put me up for adoption. She felt very strongly that I should be adopted by college graduates, so everything was all set for me to be adopted at birth by a lawyer and his wife. Except that when I popped out, they decided at the last minute that they really wanted a girl. So my parents, who were on a waiting list, got a call in the middle of the night asking, we've got an unexpected baby boy. Do you want him? They said, of course.今回もスティーブ・ジョブズの音声を文字起こししてます。先程のテキストと見比べると、適切に出力されているのがわかりますね。
google colaboratoryで実行できなかったのは「torch 2.7.0+cu118」が求められているのに、google colaboratoryでは「torch 2.6.0+cu124」がインストールされてしまい、実行できなかったと考えられます。
なお、文脈を理解する次世代音声生成AI「CSM-1B」について詳しく知りたい方は、下記の記事を合わせてご確認ください。

まとめ
本記事はNVIDIA発の音声認識モデル「Parakeet」を使ってみました。google colaboratoryでは実装に手間取ってしまいそうだったので、Vast.aiを使っています。パラメータ数が少なく軽量かつ高精度なので、今後日本語に対応するのが楽しみです。
ぜひ本記事を参考にParakeet使ってみてください!
最後に
いかがだったでしょうか?
議事録の作成に時間がかかっていませんか?Parakeetなどの生成AIを活用すれば、わずか数秒で文字起こしが可能で、面倒な作業に追われることがなくなります。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。


