
PersonaPlex-7Bとは?フルデュプレックス音声モデルの仕組みと実装検証で分かった注意点を解説

- フルデュプレックス音声対話により割り込みや発話の重なりを自然に扱える会話体験
- テキストと音声を分離した条件付けで役割と声質を柔軟に制御可能
- 研究用途を重視した7B規模モデルでリアルタイム音声対話の検証基盤として有効
2026年1月、NVIDIAから新たな音声モデルが登場!
今回リリースされた「PersonaPlex-7B」はわずか7Bという規模でありながら、リアルタイム音声対話を行うことができます。
PersonaPlex-7Bはフルデュプレックス型の会話モデルであり、従来の音声モデルに比べてより人間同士の対話に近い会話を実現できます。しかし、新しいモデルが出てもどのように使うのかが分かりにくいことも多々あります。
そこで本記事ではPersonaPlex-7Bの概要や仕組みを解説した上で、実際にどのように使うのかを紹介していきます。本記事を最後までお読みいただければPersonaPlex-7Bの使い方がわかるようになります。
ぜひ最後までお読みください!
\生成AIを活用して業務プロセスを自動化/
PersonaPlex-7Bの概要
PersonaPlex-7Bは、リアルタイムの音声対音声で会話できるフルデュプレックス型の会話モデル。
テキストのロールプロンプトと、音声のボイスコンディショニングを組み合わせることで、会話中の「役割」と「声」を制御できます。
従来のデュプレックス音声モデルが固定の役割や固定の声だった課題に対し、構造化されたシナリオやパーソナライズ用途を狙ったアプローチと言えます。モデルは連続音声をニューラルコーデックで符号化し、テキストトークンと音声トークンを自己回帰的に予測して応答音声を生成。
ユーザー音声を逐次取り込みながら、同時にエージェント側の発話を生成するため、割り込みや発話の重なり、素早いターンテイキングを自然に扱えます。
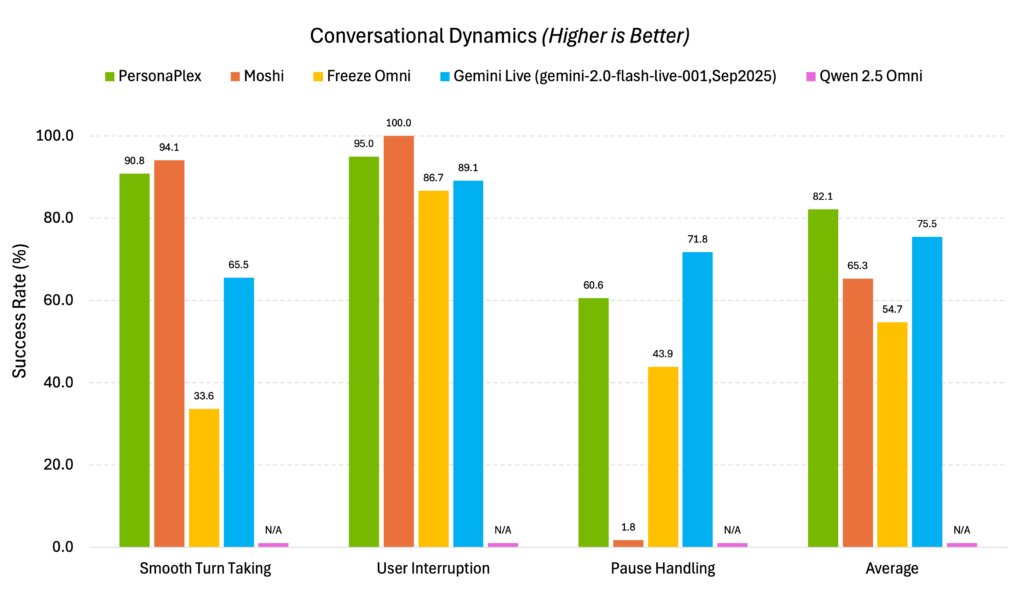
実際に上記のスコアで割り込みや話者切り替え時の遅延が少なく、人間同士の会話に近いテンポを維持していることがわかります。
PersonaPlex-7Bは会話開始前に「voice prompt」と「text prompt」の2つで条件付けを行う点がポイントです。アーキテクチャはTransformerで、Moshi系のネットワーク構成をベースにしています。
パラメータ規模は7Bとなっており、入力はテキスト(プロンプト)と音声(ユーザー発話)、出力はテキスト(エージェントテキスト)と音声(エージェント発話)です。音声のサンプルレートは入出力ともに24kHz。
学習面では、合成会話と実会話の両方を用いています。
実会話データとしてFisher English Corpusを使い、学習データは「7303 conversations(最大10分)」や「Audio Training Data Size: Less than 10,000 Hours」です。
なお、Claude 3.5 SonnetやGPT-4o超える実力のNVIDIAのLlama-3.1-Nemotron-70B-Instructについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

PersonaPlex-7Bの仕組み
ここでは、PersonaPlex-7Bがどのような技術構成で音声対音声の会話を実現しているのかを解説します。単なる音声認識や音声合成ではなく、入力から出力までを一貫して扱う点がPersonaPlex-7Bのポイントです。
まず基本的な仕組みとして、PersonaPlex-7Bはテキストと音声を同一モデル内で処理します。ユーザーの入力音声はニューラルコーデックによって離散的な音声トークンに変換。これらの音声トークンと、システム側で与えられるテキストトークンを統合的に扱います。
PersonaPlex-7Bが音声生成を行う流れは、大きく分けて3つ。
第一に会話開始時点でテキストのロールプロンプトと音声のボイスプロンプトが与えられます。次に、ユーザーの発話音声が逐次的にエンコードされ、モデル内部で自己回帰的な予測を実施。最後に、予測された音声トークンがデコードされ、エージェント側の音声として出力されます。
この段階で、入力と出力が同時進行で扱われるフルデュプレックス設計を採用。
ユーザーの発話を聞きながら、エージェントが応答を生成できるため、割り込みや発話の重なりにも対応しています。
モデル構造はTransformerアーキテクチャで、Moshi系の構成をベースとした設計で、テキストと音声の両方を時系列として扱えます。
また、PersonaPlex-7Bでは「ハイブリッドシステムプロンプト」という考え方が採用されています。これは、テキストによる役割指定と音声による話者条件付けを同時に行う仕組みです。
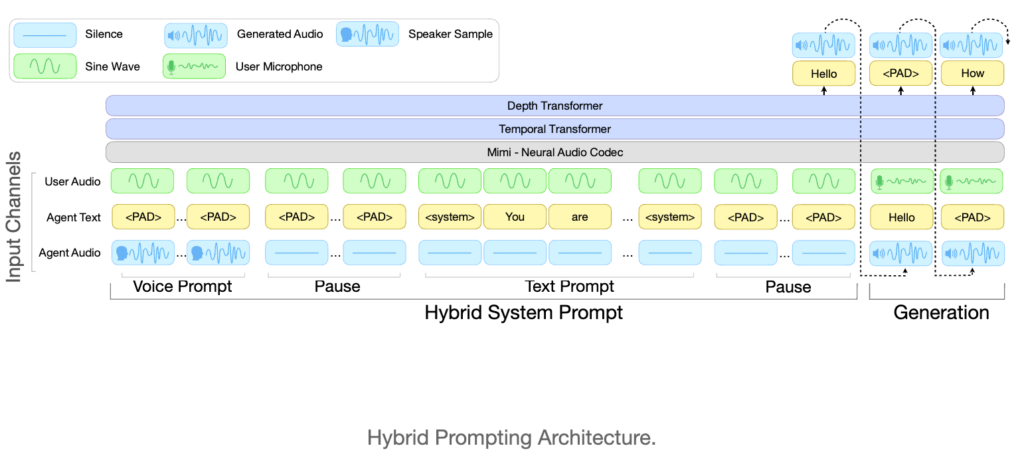
その結果、同一モデルで複数の役割や声質を切り替えられるようになっています。


PersonaPlex-7Bの特徴
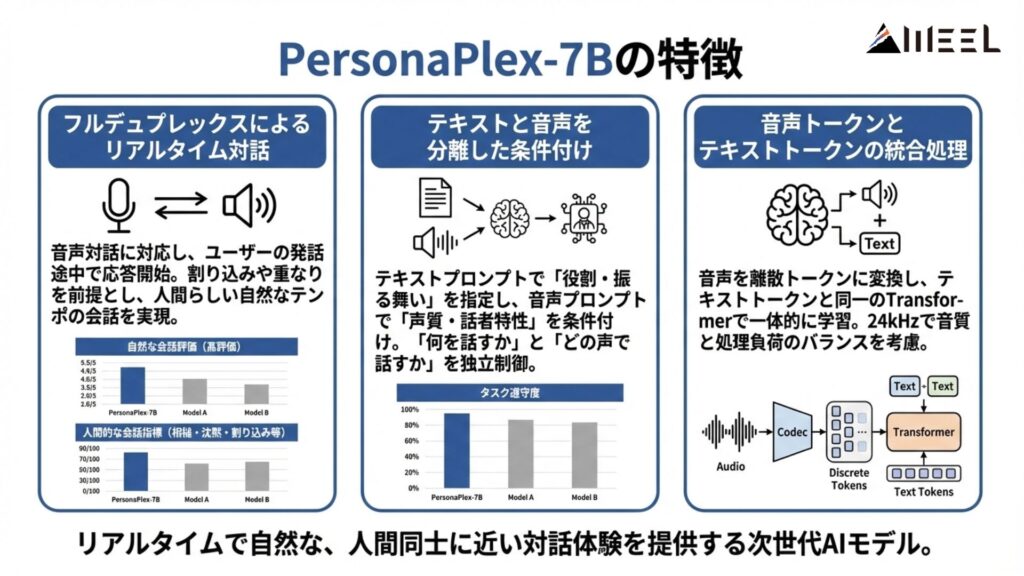
PersonaPlex-7Bには、音声対音声の対話モデルとして従来のモデルとは異なる特徴がいくつかあります。
フルデュプレックスによるリアルタイム対話
PersonaPlex-7Bの最大の特徴は、フルデュプレックスでの音声対話に対応している点。
ユーザーの発話を最後まで待たずに応答生成を開始できるため、会話のテンポが自然です。また、割り込みや発話の重なりを前提としています。
この構成により、従来の「入力→処理→出力」という直列的な対話フローから脱却。より人間同士の会話に近い話し方を再現できるようになっています。
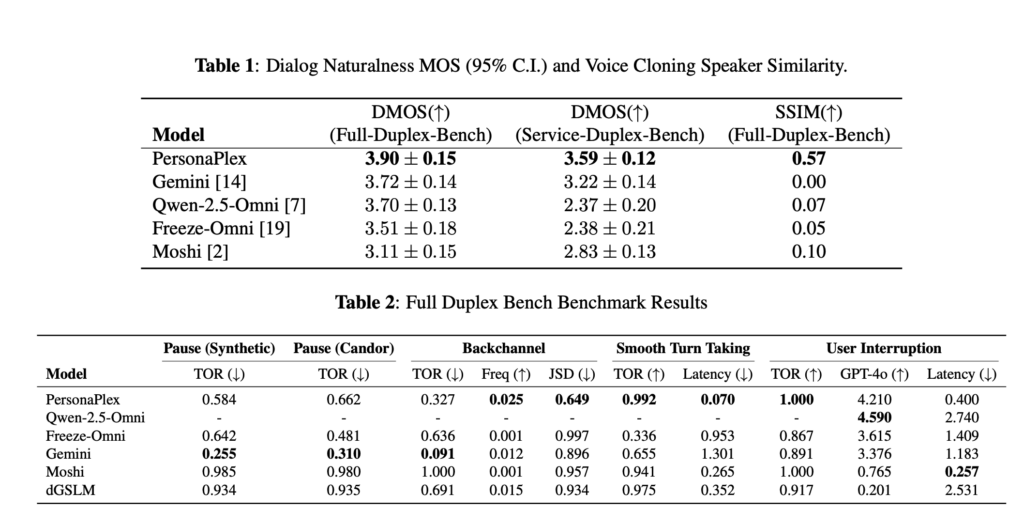
画像上段の表はより自然な会話かどうかを評価している指標になりますが、PersonaPlex-7Bは人が聞いても自然に会話していると最も感じられたモデルです。
また下段の表はより人間的な会話をできているかどうか(相槌や沈黙、会話中の割り込みなど)の指標ですが、こちらもPersonaPlex-7Bは高いスコアを算出しています。
テキストと音声を分離した条件付け
PersonaPlex-7Bでは、テキストプロンプトと音声プロンプトを明確に分離。テキスト側では役割や振る舞いを指定し、音声側では声質や話者特性を条件付けしています。
この二層構造により、「何を話すか」と「どの声で話すか」を独立して制御可能です。
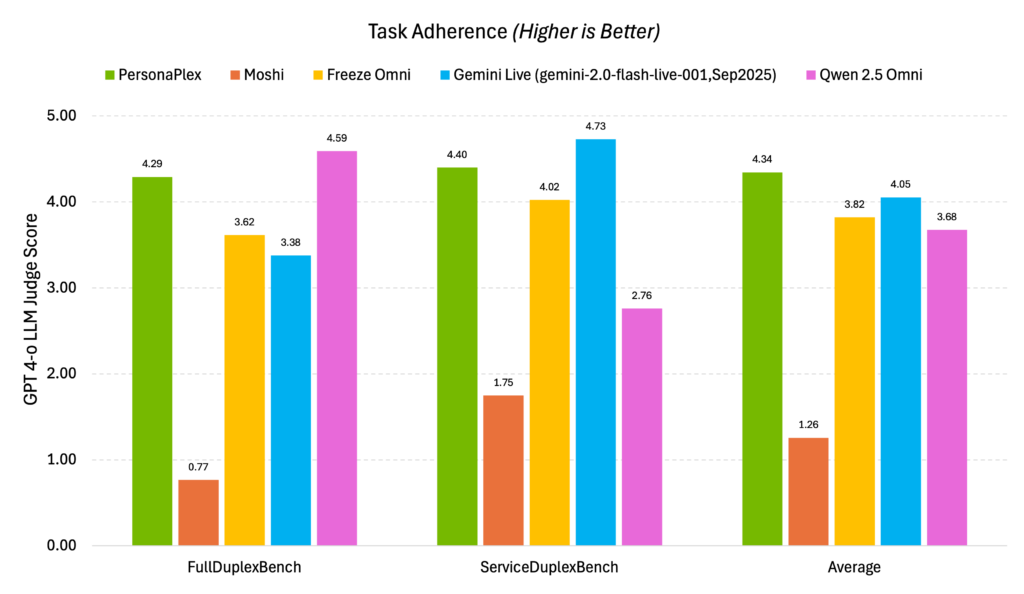
ベンチマークのタスク遵守度でも安定したスコアを算出しており、実際の会話でも役割と声を分離して制御できていることがわかります。
音声トークンとテキストトークンの統合処理
内部処理では、音声をニューラルコーデックによって離散トークンに変換し、テキストトークンと音声トークンを同一のTransformerで扱います。
これにより、音声理解と音声生成を一体化した学習が可能。
音声入出力は24kHzで統一されており、リアルタイム用途を意識した仕様であり、音質と処理負荷のバランスを取った設定と考えられます。
PersonaPlex-7Bの安全性・制約
ここでは、PersonaPlex-7Bを利用する際に把握しておきたい安全性と技術的な制約について解説します。
まず、安全性に関する明示的なポリシーやガードレールについては、公式情報では詳細に示されていません。
データの保存期間や暗号化方式、アクセス制御の仕組みなども具体的には公開されていない状況です。そのため、セキュリティ要件が厳しい用途では、事前検証や追加対策が必要になるでしょう。
技術的な制約として、対応言語や対応音声の範囲が挙げられます。
公開情報では、英語音声を中心とした学習が行われたことが読み取れます。多言語対応の可否や精度については、現時点では判断材料が不足しています。
PersonaPlex-7Bの料金
PersonaPlex-7Bは研究公開を主目的としたモデルとしてリリースされており、API利用料やサブスクリプション型の料金プランは設定されていません。
利用するにはHugging Faceなどからモデルウェイトをダウンロードしてローカルで利用することになります。


PersonaPlex-7Bのライセンス
PersonaPlex-7Bは、MITライセンスで提供されています。そのため、商用利用のみならず、ほぼすべての用途で利用可能です。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
ただし、MITライセンスでは著作権表示とライセンス文の保持が求められ、再配布時には、元の著作権表示を削除できません。
なお、100万トークン対応の超高速LLMであるNemotron 3 Nanoについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
PersonaPlex-7Bの実装方法
では実際に実装していきます。
PersonaPlex-7BはGated modelなので、Hugging Face上で利用規約に同意してから利用します。
今回はgoogle colaboratoryで実装していきますが、google colaboratoryの環境は以下です。
◆システムRAM:3.8 / 53.0 GB
◆GPU RAM:0.9 / 22.5 GB
◆ディスク:38.7 /112.6 GB
◆使用GPU:L4
◆プラン:無料
まずは必要ライブラリのインストール。
!apt-get update -y
!apt-get install -y libopus-dev
!git clone https://github.com/NVIDIA/personaplex.git
%cd personaplex
!pip -q install moshi/.続いてHugging Faceのトークンを登録します。
import os, getpass
os.environ["HF_TOKEN"] = getpass.getpass("HF_TOKENを入力: ")以上で準備が完了しました。公式READMEに記載されているコマンドを実行します。
サンプルコードはこちら
!HF_TOKEN=$HF_TOKEN python -m moshi.offline \
--voice-prompt "NATF2.pt" \
--input-wav "assets/test/input_assistant.wav" \
--seed 42424242 \
--output-wav "output.wav" \
--output-text "output.json"結果はこちら
[Info] retrieving voice prompts
voices.tgz: 100% 6.10M/6.10M [00:00<00:00, 13.0MB/s]
[Info] extracting /root/.cache/huggingface/hub/models--nvidia--personaplex-7b-v1/snapshots/f69e74f60b25bded21b08fd932c334e47e28f184/voices.tgz to /root/.cache/huggingface/hub/models--nvidia--personaplex-7b-v1/snapshots/f69e74f60b25bded21b08fd932c334e47e28f184/voices
/usr/local/lib/python3.12/dist-packages/moshi/offline.py:145: DeprecationWarning: Python 3.14 will, by default, filter extracted tar archives and reject files or modify their metadata. Use the filter argument to control this behavior.
tar.extractall(path=voices_tgz.parent)
[Info] voice_prompt_dir = /root/.cache/huggingface/hub/models--nvidia--personaplex-7b-v1/snapshots/f69e74f60b25bded21b08fd932c334e47e28f184/voices
config.json: 100% 56.0/56.0 [00:00<00:00, 388kB/s]
[Info] loading mimi
(…)nizer-e351c8d8-checkpoint125.safetensors: 100% 385M/385M [00:16<00:00, 23.7MB/s]
[Info] mimi loaded
tokenizer_spm_32k_3.model: 100% 553k/553k [00:00<00:00, 849kB/s]
[Info] loading moshi
model.safetensors: 100% 16.7G/16.7G [03:02<00:00, 91.9MB/s]
Traceback (most recent call last):
File "<frozen runpy>", line 198, in _run_module_as_main
File "<frozen runpy>", line 88, in _run_code
File "/usr/local/lib/python3.12/dist-packages/moshi/offline.py", line 431, in <module>
main()
File "/usr/local/lib/python3.12/dist-packages/moshi/offline.py", line 408, in main
run_inference(
File "/usr/local/lib/python3.12/dist-packages/moshi/offline.py", line 206, in run_inference
lm = loaders.get_moshi_lm(moshi_weight, device=device, cpu_offload=cpu_offload)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/moshi/models/loaders.py", line 196, in get_moshi_lm
model = LMModel(device=device, dtype=dtype, **lm_kwargs).to(device=device, dtype=dtype)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/moshi/models/lm.py", line 340, in __init__
self.depformer = StreamingTransformer(
^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/moshi/modules/transformer.py", line 681, in __init__
layer_class(
File "/usr/local/lib/python3.12/dist-packages/moshi/modules/transformer.py", line 506, in __init__
self.self_attn: StreamingMultiheadAttention = StreamingMultiheadAttention(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/moshi/modules/transformer.py", line 362, in __init__
in_proj = nn.Linear(embed_dim, mult * out_dim, bias=False, **factory_kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/torch/nn/modules/linear.py", line 99, in __init__
self.weight = Parameter(torch.empty((out_features, in_features), **factory_kwargs))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
torch.OutOfMemoryError: CUDA out of memory. Tried to allocate 96.00 MiB. GPU 0 has a total capacity of 14.74 GiB of which 94.12 MiB is free. Process 23966 has 14.65 GiB memory in use. Of the allocated memory 14.36 GiB is allocated by PyTorch, and 176.71 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)モデルのダウンロードまではできましたが、メモリ不足で落ちてしまいました。なので、CPUオフロードを使って実行をします。
サンプルコードはこちら
!HF_TOKEN=$HF_TOKEN python -m moshi.offline \
--voice-prompt "NATF2.pt" \
--input-wav "assets/test/input_assistant.wav" \
--seed 42424242 \
--output-wav "output.wav" \
--output-text "output.json" \
--cpu-offload結果はこちら
[Info] retrieving voice prompts
[Info] voice_prompt_dir = /root/.cache/huggingface/hub/models--nvidia--personaplex-7b-v1/snapshots/f69e74f60b25bded21b08fd932c334e47e28f184/voices
[Info] loading mimi
[Info] mimi loaded
[Info] loading moshi
^CCPUオフロードを使ってもメモリ不足になり、強制的に終了されてしまいました。
google colaboratoryでは実装が難しそうなので、ローカル環境で実行してみます。
ローカル環境について
◆M4 Pro
◆メモリ64GB
◆Python 3.10
まずは下記を一つずつ実行していきます。
サンプルコードはこちら
conda create -n personaplex python=3.10 -y
conda activate personaplex
brew install opus
pip install --upgrade pip setuptools wheel
pip install torch torchvision torchaudio
git clone https://github.com/NVIDIA/personaplex.git
cd personaplex
pip install moshi/.moshiのインストールまでエラーなく進めばOKです。次にHugging Faceのトークン設定です。
export HF_TOKEN=あなたのトークントークンの設定ができたら下記を実行して出力されればOK。
python -m moshi.offline --help最後にvoice promptを一部修正します。
修正コードはこちら
python - << 'EOF'
import torch
from pathlib import Path
#パスは自身の環境に合わせてください
src = Path(
"/.cache/huggingface/hub/"
"models--nvidia--personaplex-7b-v1/snapshots"
)
# voicesディレクトリを探す
voices_dir = next(src.glob("*/voices"))
for pt in voices_dir.glob("*.pt"):
print(f"Converting {pt.name}")
state = torch.load(pt, map_location="cpu")
torch.save(state, pt)
print("Done.")
EOF上記を実行したら最後に下記を実行すれば音声が生成されます。
サンプルコードはこちら
HF_TOKEN=$HF_TOKEN \
python -m moshi.offline \
--device cpu \
--voice-prompt "NATF2.pt" \
--input-wav "assets/test/input_assistant.wav" \
--output-wav "output.wav" \
--output-text "output.json"最後に下記が出力されれば成功です。
[Info] Wrote output audio to output.wav
[Info] Wrote output text to output.json上記のサンプルコードはサンプルとして保存されている音声に対して回答をモデル内部で生成、それを音声として出力するといった内容です。出力された音声はこちらです。
PersonaPlex-7Bの活用シーン
PersonaPlex-7Bはリアルタイム性と役割制御を重視した音声モデルです。その特性を活かして活用できそうな内容を考えてみました。
リアルタイム音声エージェントの研究開発
PersonaPlex-7Bは、フルデュプレックス会話を前提とした設計。そのため、音声エージェントの対話品質を評価する研究用途に向いていると考えられます。
例えば、応答タイミングがユーザー体験に与える影響を分析できます。従来モデルでは難しかった自然なターンテイキングの評価が可能でしょう。
対話AI研究のベンチマーク用途としての活用ができるのではないでしょうか。。
役割切り替え型の対話システム検証
テキストプロンプトと音声プロンプトを分離できる設計も特徴です。この仕組みにより、同一モデルで複数の役割を切り替える実験、例えばオペレーター役、案内役、教育役といった使い分けが可能。
業務シナリオを想定した対話フロー検証にも適しています。会話内容と声質を独立して制御できる点は、従来モデルとの差別化ポイントです。
マルチロール対話エージェントの研究に向いた構成と言えます。
音声対話UIのプロトタイプ開発
PersonaPlex-7Bは、テキスト生成と音声生成を一体で扱います。そのため、音声UI全体のプロトタイプを短期間で構築できます。
個別にASRやTTSを組み合わせる必要がありません。リアルタイム性が求められるUI設計の検証にも向いています。
例えば、対話テンポや応答遅延がUXに与える影響を評価できます。音声中心のインターフェース設計における実験基盤として活用可能でしょう。
PersonaPlex-7Bを実際に使ってみた
ではリアルタイム処理を行なってみたいと思います。CPU前提での実装になるのでなかなか厳しいかもしれませんが、Mac環境で雰囲気を試せればなと思います。
まずは下記を実行します。
export HF_TOKEN=あなたのトークン
SSL_DIR=$(mktemp -d)
python -m moshi.server --ssl "$SSL_DIR" --device cpuもし「UnicodeEncodeError: ‘latin-1’ codec can’t encode characters」というエラーが出た場合にはHugging Faceのトークンを再設定します。
unset HF_TOKEN
export HF_TOKEN="hf_xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"再設定が終わったらWeb UIを起動するためのコマンドを入力。
SSL_DIR=$(mktemp -d)
python -m moshi.server --ssl "$SSL_DIR" --device cpuそうすると「https://localhost:8998」が表示されるのでアクセスすればOKです。
実際の様子がこちら。
なかなか厳しく、こちらからの音声入力には反応してもらえませんでした。ただ、GPU環境の方はかなりスムーズに喋れるのではないかなと思います。
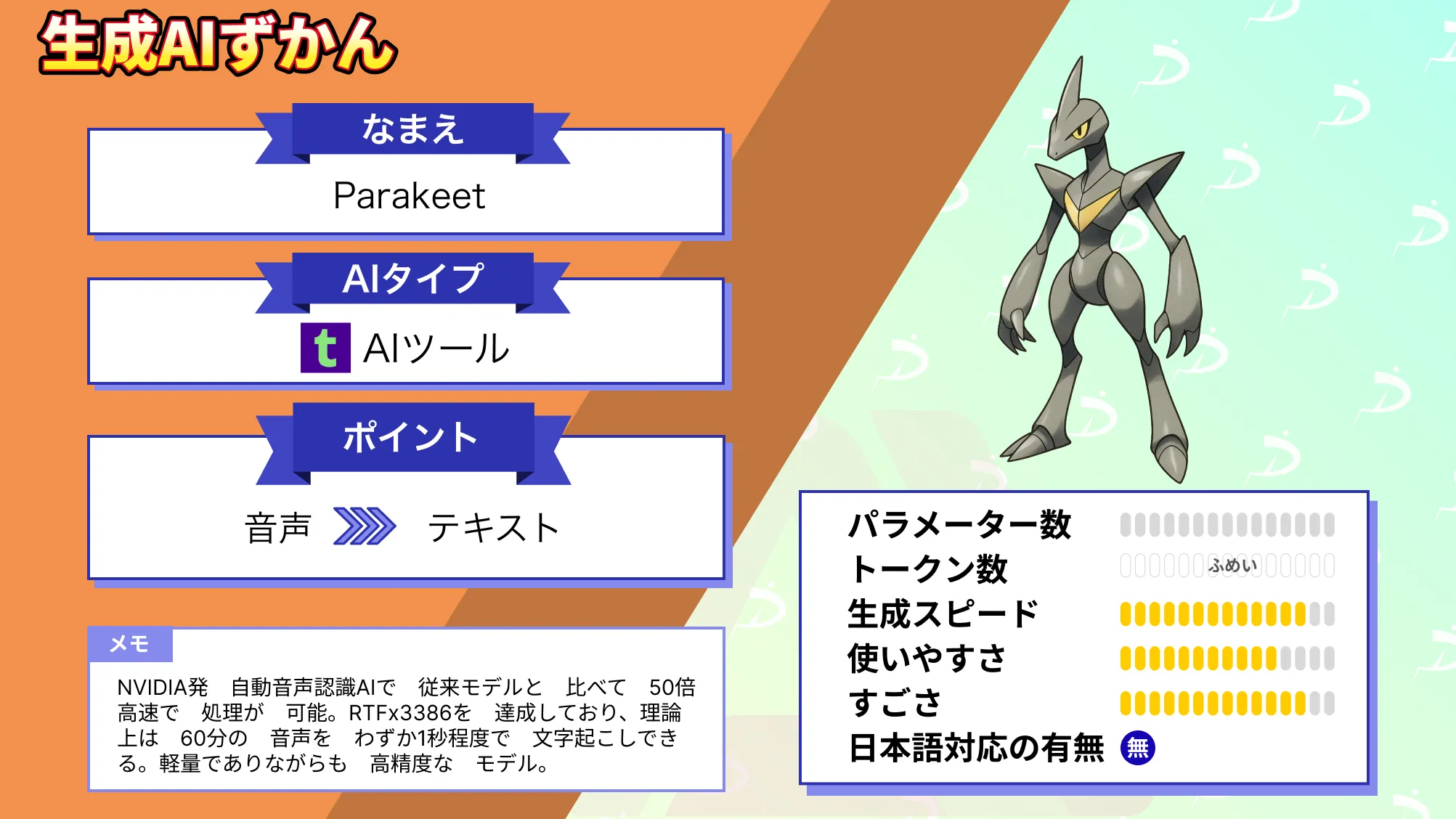
なお、最大24分の音声も一発変換できるNVIDIAのParakeetについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
まとめ
本記事ではPersonaPlex-7Bの概要から仕組み、実際にMac上で動かす方法について解説をしました。Mac環境でも動かすことはできましたが、PersonaPlex-7Bの強みであるリアルタイム処理は厳しい結果となりました。
ぜひ皆さんも本記事を参考にPersonaPlex-7Bを使ってみてください!

最後に
いかがだったでしょうか?
音声対話AIは、PoCで動かすだけでなく、業務にどう組み込み、どこまで自動化するかが成果を左右します。PersonaPlex-7Bの特性を踏まえ、実運用を見据えた設計を検討したい企業向けの内容です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。


