
Qwen-Image-2512とは?生成画像っぽさを抑え、日本語描画も試せる最新画像生成モデルを解説

- AI画像っぽさを抑えた高品質な画像生成と文字レンダリング精度の向上を実現
- MMDiTベース20Bモデルを採用しAPI利用とローカル実行の両方に対応
- Apache 2.0ライセンスで商用利用可能だが生成物の扱いは利用者責任
2025年12月、Alibabaから新たな画像生成モデルが登場!
今回リリースされた「Qwen-Image-2512」はこれまでの画像生成モデルとは一線を画しており、いかにも生成AIっぽい画像から脱却しています。
本記事ではQwen-Image-2512の概要から仕組み、実際の使い方について解説します。本記事を最後までお読みいただければ、Qwen-Image-2512の理解が深まり、ご自分でも使うことが可能です。
ぜひ最後までお読みください。
\生成AIを活用して業務プロセスを自動化/
Qwen-Image-2512の概要
生成画像の「いかにもAIっぽい質感」や、画像内テキストの崩れに悩むケースは少なくありません。Qwen-Image-2512は、そうした課題に対して現実感の高い人物描写や複雑なテキスト描画の改善を狙った画像生成モデルです。
Qwen-Image-2512は人物の実在感を高めて「AI画像っぽさ」を減らし、風景や毛並みなど自然物のディテールを細かく描画、そしてテキストレンダリング精度の向上を図っています。
加えて、AI Arenaで10,000回以上のブラインド評価を行い、オープンソース画像モデルとして高い性能を示しています。
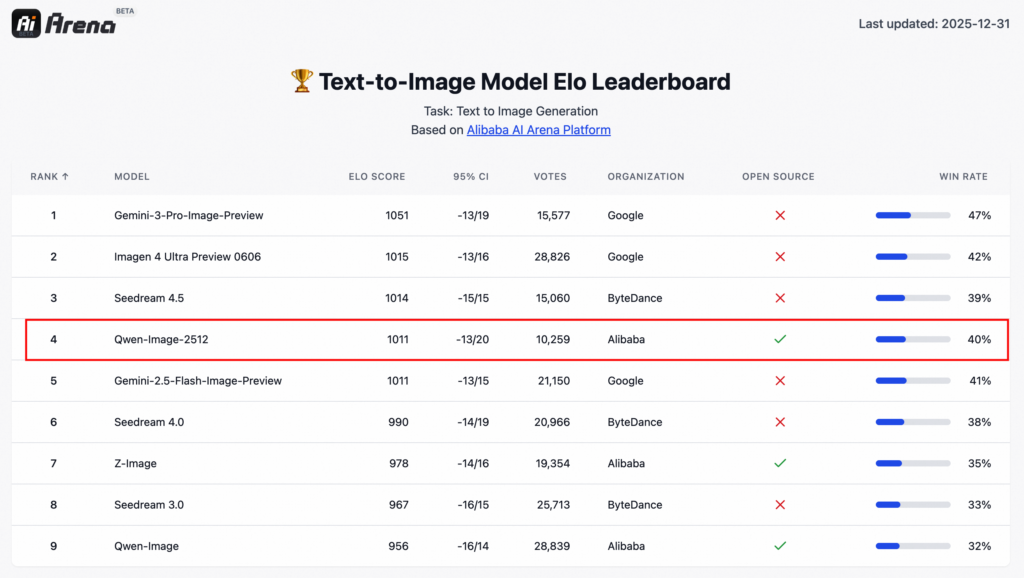
一方で、日本語プロンプトには一定程度対応するものの、日本語の文章を含む画像生成は苦手です。プロダクト用途で文字入り素材を量産したい場合、どの言語でどこまで再現できるかを事前に試す必要があるでしょう。
Qwen-Image-2512の仕組み
ここでは、Qwen-Image-2512がどのような技術構成で画像生成を行っているのかを解説します。
Qwen-Image-2512は、MMDiTと呼ばれるマルチモーダルDiffusion Transformer系の画像基盤モデルを採用。
パラメータ規模は20Bとされており、テキスト情報と視覚表現を同時に扱う設計です。この構成により、文章による指示と画像生成の対応関係を高い解像度で学習できるようになっています。
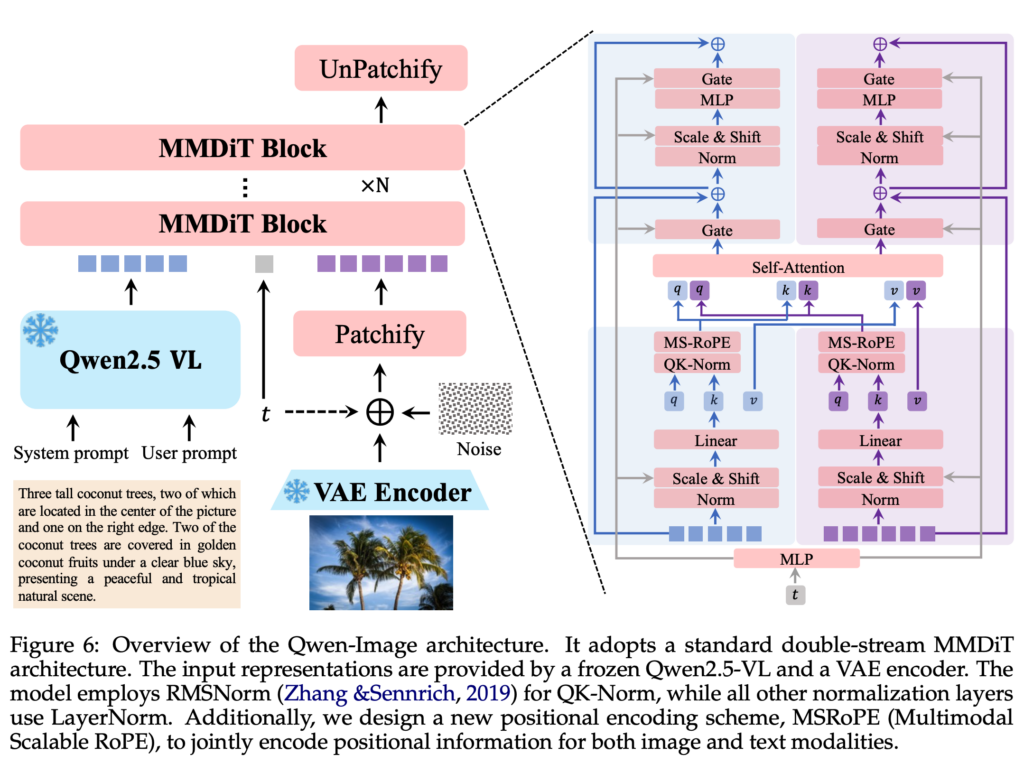
処理の流れとしては、まず入力されたテキストプロンプトを内部表現に変換し、その情報をもとに拡散モデルが段階的にノイズを除去しながら画像を生成。
一般的な拡散型画像生成と同様ですが、Qwen-Image-2512ではTransformerベースの構造を組み合わせることで、文字形状や細部の一貫性を保ちやすくなっています。
また、人物や自然物の表現力向上については、学習段階で「実在感」を重視したデータと評価手法を導入。
学習済みモデルをそのままAPI専用に閉じるのではなく、Hugging Faceで重みを公開し、diffusersやComfyUIから利用可能です。


Qwen-Image-2512の特徴
ここでは、Qwen-Image-2512が他の画像生成モデルと比べてどのような特徴があるのかを解説します。
Qwen-Image-2512には、主に3つの大きな特徴があります。いずれも「生成品質を実用水準まで引き上げる」という観点で設計されています。
人物表現における実在感の向上
Qwen-Image-2512は、人物画像の生成で「AIらしさ」を抑える点を重視。
肌の質感や表情、文字などが不自然になりにくく、実写に近い印象を狙った出力が可能になりました。特にポートレート用途では、この差が品質に直結するでしょう。
複雑なテキストレンダリングへの対応
画像内に文字を正しく描画できるかどうかは、画像生成モデルの実用性を左右する重要な要素。
Qwen-Image-2512では、複雑なテキストや長めの文章を含む指示でも、文字の崩れを抑えた生成結果が示されています。従来モデルで課題になりがちだった部分への明確な改善点と言えるでしょう。

なお、49種類のボイスと10言語対応の最新音声合成モデルであるQwen3-TTSについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

自然物や背景表現のディテール強化
人物だけでなく、風景や動物の毛並み、背景要素の描写精度が高い点も特徴として挙げられます。
細部の情報量が増えることで、全体としてのリアリティが向上している印象です。広告用ビジュアルやコンセプトアート用途では、修正工数の削減につながる可能性があります。
こうしたディテール表現は、MMDiTベースの拡散モデル構成と、大規模パラメータによる表現力の組み合わせが効いていると考えられます。

Qwen-Image-2512の安全性・制約
ここでは、Qwen-Image-2512を利用する際に把握しておきたい安全性の考え方と、現時点で確認できる制約について解説します。
まず安全性として、Qwen-Imageは学習データ段階でリスク低減を強く意識した設計が取られています。
学習用データには多段階のフィルタリングパイプラインが導入されており、破損ファイルや低解像度画像、重複データの除外に加え、NSFWコンテンツを排除する工程が明示されています。暴力的、性的、攻撃的と判断される素材は学習対象から除外される仕組みです。
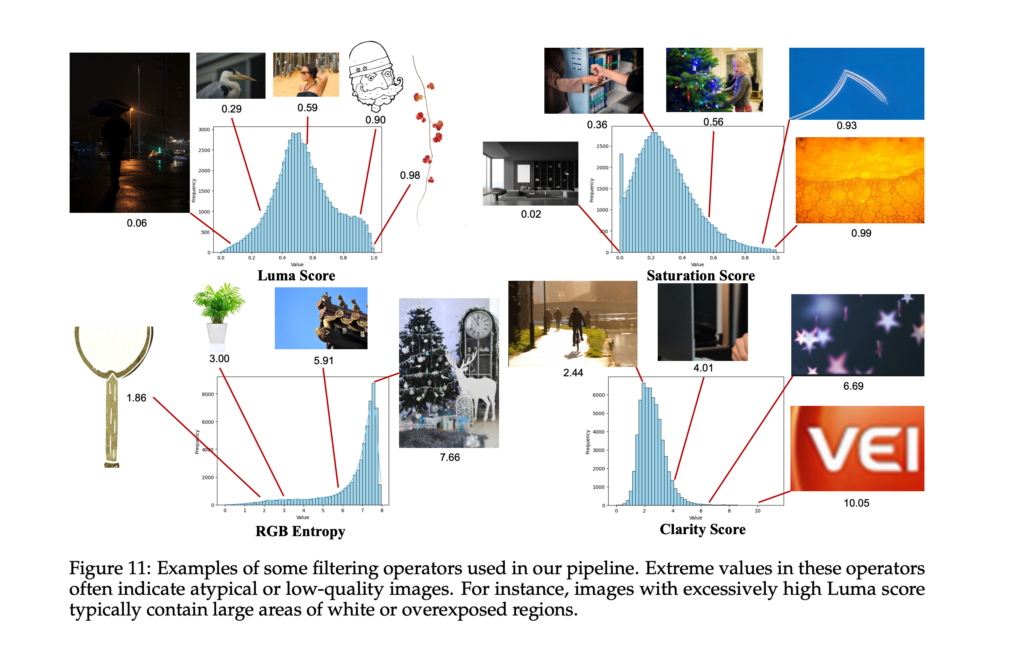
また、人物画像を多く含むPeopleカテゴリについては、プライバシーへの配慮が明確に言及されています。※1
一方で、生成物そのものに対する利用制限やコンテンツポリシーが詳細に定義されているわけではありません。
モデル内部にどのような出力制御やリアルタイムフィルタが組み込まれているかについては、公式情報では明らかにされていない状況です。そのため、不適切な指示を与えた場合の挙動や、生成結果の責任範囲は利用者側の運用に委ねられる部分が大きいでしょう。
制約面で注目すべきなのは、文字生成やレイアウト表現の「得意領域」と「限界」が明確に分かれる点です。
Qwen-Imageは英語や中国語を中心としたテキストレンダリングで高い性能を示していますが、全ての言語やフォント、極端に密度の高い文字配置が常に正確に出力されるわけではありません。
Qwen-Image-2512の料金
Qwen-Image-2512にはAPIが用意されており、APIの料金は画像一枚あたり$0.075です。また、デモサイトも用意されているので、デモサイトは無料で利用可能、Qwen Chatでも画像生成が可能です。
またHugging Faceにモデルもあるので、モデルをダウンロードしてローカル環境で実行すれば無料で使えます。
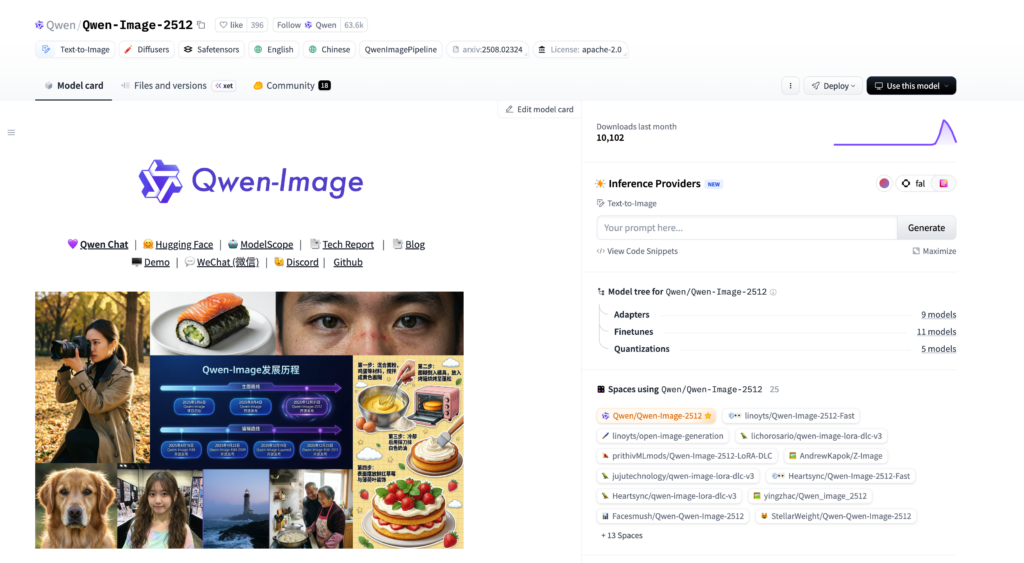


Qwen-Image-2512のライセンス
Qwen-Image-2512はApache 2.0ライセンスで公開されていて、商用利用・改変・再配布・特許利用・私的利用のすべてが許可されています。Apache 2.0ライセンスはオープンな条件で利用を認められているライセンスです
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
\画像生成AIを利用する際はライセンスを確認しましょう/

Qwen-Image-2512はApache 2.0ライセンスのもと、商用利用を含めて幅広い用途で利用できますが、生成物の内容や利用方法については利用者側が責任を負う点に注意が必要です。
まず、違法・有害なコンテンツの生成や法令に反する利用は認められていません。また、既存IPや実在人物を用いた生成物を商用利用する場合は、権利者のガイドラインや肖像権・プライバシーへの配慮が不可欠です。
なお、Alibaba発キャラクター動画生成AIであるWan2.2-Animateについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
Qwen-Image-2512の実装方法
では実際にQwen-Image-2512を使っていきます。まずはデモサイトを使って画像を生成してみます。
生成した結果がこちら。

数分で生成できました。実際に生成している様子が下記です。
API経由でQwen-Image-2512を使う
続いてはAPI経由でQwen-Image-2512を使っていきます。google colaboratoryで実装をします。
まずは必要ライブラリのインストール。
!pip -q install dashscopeサンプルコードはこちら
import dashscope
from dashscope import MultiModalConversation
from IPython.display import Image, display
import requests
dashscope.base_http_api_url = "https://dashscope-intl.aliyuncs.com/api/v1"
api_key = "sk-xxxxxxxxxxxxxxxx"
messages = [{
"role": "user",
"content": [{
"text": "An elegant and solemn couplet hangs in a hall with classic Chinese decor."
}]
}]
res = MultiModalConversation.call(
api_key=api_key,
model="qwen-image-max",
messages=messages,
size="1328*1328",
)
# 画像URLを取り出して表示
img_url = res.output["choices"][0]["message"]["content"][0]["image"]
display(Image(url=img_url))
# 保存したい場合
open("result.png", "wb").write(requests.get(img_url).content)生成された画像がこちらです。

画質はいいですが、ちょっと生成画像っぽいですね。本記事後半で生成画像っぽくならないプロンプトを試してみたいと思います。
Qwen-Image-2512の活用シーン
ここでは、Qwen-Image-2512の特性を踏まえた活用シーンを考えていきます。Qwen-Image-2512は「実写に近い人物表現」「文字を含む画像生成」「高精細な背景描写」を強みとするモデルです。この特徴を踏まえて考えてみます。
マーケティング・広告用ビジュアル制作
人物や背景の実在感が高いことから、広告やマーケティング素材の試作に活用しやすいモデルといえます。
例えば、Web広告やSNS投稿用の人物カット、イメージビジュアルを短時間で複数パターン生成できます。撮影前のイメージ検討やA/Bテスト用素材として使うことで、制作工程の初期コストを抑えられる可能性があります。
また、文字入りのビジュアル生成にも一定の改善が見られるため、簡単なキャッチコピーを含む画像のラフ作成にも向いているでしょう。
UIデザイン・プロダクトモック作成
Qwen-Image-2512は、背景や小物、質感表現の精度が高い点も特徴です。
このため、アプリやWebサービスのUIデザイン検討用に、画面イメージや世界観を表すビジュアルを生成する用途が考えられます。デザイナーがゼロから描き起こす前に、視覚的な方向性を共有する素材として使えるでしょう。
とくに初期のプロトタイピング段階では、「完成度よりもスピード」が重視されます。短時間で多数の案を出せる点は、開発チーム内の合意形成を助ける要素になるのではないでしょうか。
コンセプトアート・世界観設計
風景や自然物のディテール表現が強化されているため、ゲームや映像制作のコンセプトアート用途も想定されます。
舞台となる街並みや自然環境、キャラクターの雰囲気を視覚化する作業を効率化できるでしょう。完全な最終成果物ではなく、アイデアを膨らませるための素材としての位置付けです。
このような用途では、ローカル環境でモデルを動かせる点も評価ポイントになります。外部にデータを出さずに検証できるため、未公開企画を扱う場合でも使いやすい構成です。
Qwen-Image-2512を実際に使ってみた
ここからは生成画像っぽくならないプロンプトを試してみるのと、日本語描画がどこまでできるのかを試してみます。
まずは生成画像っぽさをなくすプロンプトから。
サンプルコードはこちら
import json
import base64
import requests
from IPython.display import Image, display
import dashscope
from dashscope import MultiModalConversation
dashscope.base_http_api_url = "https://dashscope-intl.aliyuncs.com/api/v1"
api_key = ""
model_name = "qwen-image-max"
image_size = "1328*1328"
prompt = """
A realistic photograph taken with a full-frame DSLR camera.
Natural lighting, slight imperfections.
Real-world textures and subtle noise.
A real interior space, candid and unposed.
No CGI, no illustration, no stylized look.
"""
messages = [{
"role": "user",
"content": [{"text": prompt}]
}]
res = MultiModalConversation.call(
api_key=api_key,
model="qwen-image-max",
messages=messages,
size="1328*1328",
)
img_url = res.output["choices"][0]["message"]["content"][0]["image"]
display(Image(url=img_url))
open("photoreal.png", "wb").write(requests.get(img_url).content)
まだ生成画像っぽさはある気がします。上記のプロンプトに「No overly perfect lighting or textures.」を追加した画像が下記です。

少し生成画像っぽさは減りましたかね。最後に「Eye-level viewpoint.Centered composition.」を追加したのがこちら。

自分自身が画像生成モデルで生成していると知っているので、どうしても生成画像っぽく見えてしまいますが、だいぶ現実味のある画像になったのではないでしょうか。
続いて日本語の描画です。
サンプルコードはこちら
import json
import base64
import requests
from IPython.display import Image, display
import dashscope
from dashscope import MultiModalConversation
dashscope.base_http_api_url = "https://dashscope-intl.aliyuncs.com/api/v1"
api_key = ""
model_name = "qwen-image-max"
image_size = "1328*1328"
prompt = """
A vertical hanging scroll (kakemono) on a plain background.
The scroll contains ONLY the following Japanese text, written exactly as-is:
「智を磨き、道を拓く」
Clear, legible Japanese calligraphy.
Black ink, simple brush strokes.
No additional text.
"""
messages = [{
"role": "user",
"content": [{"text": prompt}]
}]
res = MultiModalConversation.call(
api_key=api_key,
model="qwen-image-max",
messages=messages,
size="1328*1328",
)
img_url = res.output["choices"][0]["message"]["content"][0]["image"]
display(Image(url=img_url))
open("photoreal.png", "wb").write(requests.get(img_url).content)生成された画像がこちら。

しっかりと日本語が描画できていますね。もう少し長めの日本語にしてみます。

少し長くしても適切に描画されていますね。テクニカルレポートには「complex text rendering paragraph-level text
Chinese text rendering is particularly strong」と書かれていましたが、日本語も出力できそうです。
日本語訳
複雑なテキストのレンダリング(段落単位のテキスト)
中国語テキストのレンダリングは特に優れている
なお、画像編集タスクで最新鋭の性能(SOTA)を達成したオープンソースモデルであるQwen-Image-Edit-2511について詳しく知りたい方は、下記の記事を合わせてご確認ください。

まとめ
本記事ではQwen-Image-2512の概要から仕組み、実際の使い方について解説をしました。プロンプトを工夫すれば生成画像っぽくはならず、日本語も適切に描画できることがわかりました。
多くの生成画像モデルは日本語描画が課題になりがちですが、Qwen-Image-2512であれば日本語を含む画像を手軽に作れそうです。ぜひ皆さんも本記事を参考に画像を生成してみてください!

最後に
いかがだったでしょうか?
Qwen-Image-2512のような生成AIを「試す」から「使える」に変えたい場合は、業務特化で設計できるWEELがサポートします。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、弊社紹介資料もご用意しておりますので、併せてご確認ください。


