
【Qwen3-Coder-Next】コーディング特化型LLMの性能・ライセンス・使い方を徹底解説

- Alibaba Qwenチーム発、プログラミング特化型大規模言語モデル
- 独自の工夫でアクティブパラメータ数を抑え、リーズナブルなリソースで動作するよう設計されている
- SWE-Bench Verified(ソフトウェアエンジニアリング分野の総合的な課題集)で70%超のスコアを記録
2026年2月4日、中国のAlibaba Qwenチームがプログラミング特化型大規模言語モデル「Qwen3-Coder-Next」を公開しました!
Qwen3-Coder-Nextは、ソースコードの生成やデバッグはもちろん、エージェントとして対話しながらタスクを遂行できる点が特徴です。
大規模モデルというと高い計算コストや商用利用の制約が気になると思いますが、Qwen3-Coder-Nextは独自の工夫でモデルのアクティブパラメータ数を抑え、リーズナブルなリソースで動作するよう設計されています。
今回はこのQwen3-Coder-Nextについて、概要から性能、ライセンス、具体的な使い方まで詳しく解説します。
ぜひ最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
Qwen3-Coder-Nextの概要

Qwen3-Coder-Nextは、AlibabaのAI研究チームが開発したコード特化型の大規模言語モデルです。
Alibabaの第3世代LLMシリーズ「Qwen3」をベースに、コード処理能力が強化されたモデルで、ローカル環境での開発やコーディングエージェント用途に特に最適化されています。
アーキテクチャが特徴的で、全体で約800億(80B)パラメータを持ちながら、一度の推論で活性化されるのは約30億(3B)のパラメータのみというMixture-of-Experts(MoE)技術を導入しています。
これによって、巨大モデルの性能を維持しつつ、計算コストを大幅に削減することに成功しています。
また、対応できるプログラミング言語の種類も非常に豊富です。
Qwen3-Coder-Nextは、実に358種類もの言語(マークアップやシェルスクリプト等も含む)をサポートしていて、幅広い技術スタックのコードを理解・生成することができます。
なお、Qwen3について詳しく知りたい方は、以下の記事も参考にしてみてください。

Qwen3-Coder-Nextの性能
Qwen3-Coder-Nextの性能は、オープンソースのコード特化モデルとして、2026年2月時点で最高クラスです。
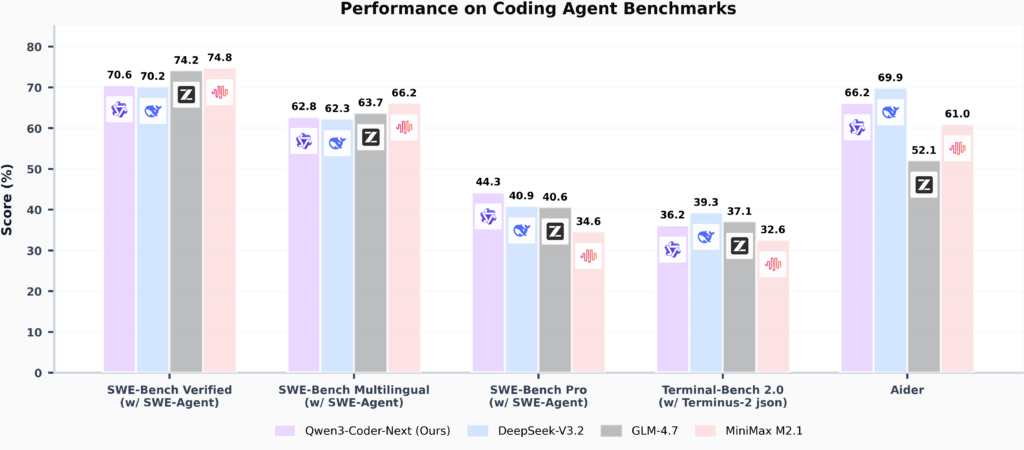
たとえば、SWE-Bench Verified(ソフトウェアエンジニアリング分野の総合的な課題集)では70%超のスコアを記録し、これは従来のオープンモデルを大きく上回る最高記録となりました。
さらに、多言語設定の難易度が高い課題や、より複雑なSWE-Bench Proにおいてもハイスコアを残しています。
特に注目すべきなのは、これらの成果をたった3Bのアクティブパラメータで達成している点です。
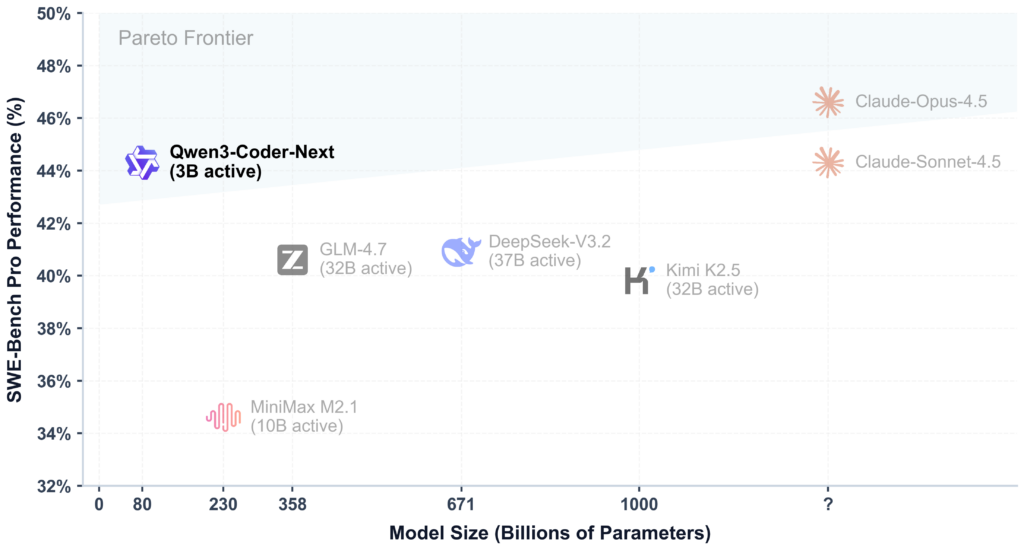
従来であれば、数十億~数百億パラメータ規模のモデルが必要だったエージェント性能を、Qwen3-Coder-Nextは効率的な構造で実現しており、同等かそれ以上の結果を残していると考えられます。
なお、Qwen3-Coderについて詳しく知りたい方は、以下の記事も参考にしてみてください。
Qwen3-Coder-Nextのライセンス
Qwen3-Coder-NextはオープンソースのApache License 2.0で公開されています。
このライセンスは、非常に寛容なもので、商用・非商用を問わず利用可能となっています。
| 利用用途 | 可否 | 備考 |
|---|---|---|
| 商用利用 | ⭕️ | |
| 改変 | ⭕️ | |
| 配布 | ⭕️ | |
| 特許使用 | ⭕️ | |
| 私的使用 | ⭕️ |


Qwen3-Coder-Nextの料金
Qwen3-Coder-Nextそのものはオープンソースモデルですので、モデルのダウンロードや利用に利用料金はかかりません。
とはいえ、80Bという大規模モデルを扱うには相応のハードウェアが必要であり、現実的には高性能GPU(例えばA100やH100クラス)やそれ相応のクラウド計算インスタンスを用意する必要があります。
計算資源をお持ちでない場合でも、Alibaba Cloudが提供するモデル推論APIサービスを利用することで、インフラ構築なしにQwen3-Coder-Nextを使うことが可能ですが、その場合はAPI利用料が発生します。
| コンテキスト長 | 入力料金(100万トークン) | 出力料金(100万トークン) |
|---|---|---|
| 0~32Kトークン以内 | $1.0 | $5.00 |
| 32K超~128Kトークン以内 | $1.80 | $9.00 |
| 128K超~256Kトークン以内 | $3.00 | $15.00 |
| 256K超~最大1Mトークン以内 | $6.00 | $60.00 |
Qwen3-Coder-Nextの使い方
Qwen3-Coder-Nextはオープンで提供されているので、いくつかの方法で利用できます。今回は代表的な利用方法を2通り紹介します。
ローカル環境での利用(Transformersライブラリ)
1番スタンダードなのは、Hugging FaceのTransformersライブラリを使って、モデルとトークナイザを読み込み、ローカルマシン上で実行する方法です。
公式のモデルカードでも推奨されている方法で、Pythonコード数行でセットアップできます。あらかじめPyTorchとTransformersをインストールしておきましょう。(GPU環境推奨)
まず、Pythonスクリプト上でモデルとトークナイザをロードします。モデル名は "Qwen/Qwen3-Coder-Next" となっています。
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-Coder-Next"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto" # 利用可能なGPUに自動割当て
)こちらのコードを実行すると、初回はインターネット経由でモデルの重みとトークナイザのデータがダウンロードされます。完了後、モデルがメモリ上にロードされます。
続いて、プロンプトを準備します。Qwen3-Coder-Nextはチャット形式(ユーザー発言とシステム応答の履歴)を想定した設計のため、transformersのChatAPI形式に合わせてメッセージリストを構築します。
prompt = "Pythonでクイックソートのアルゴリズムを書いてください。"
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)最後に、用意した入力をモデルに渡し、回答を生成させます。以下のコードで推論を行い、モデルからの応答テキストを取得することができます。
generated_ids = model.generate(**model_inputs, max_new_tokens=1024)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):]
answer = tokenizer.decode(output_ids, skip_special_tokens=True)
print(answer)max_new_tokensは生成するトークン数の上限ですので、必要に応じて調整するようにしましょう。
クラウドAPI・ツール経由での利用(Qwen Code / Claude Code)
自前でモデルをホストするのはハードルが高い…という場合でも、クラウド経由でQwen3-Coder-Nextの実力を試す方法があります。
Alibaba CloudのAPIを直接使うこともできますが、ここではもう少しお手軽な方法として、Qwen3-Coderシリーズ専用に用意されたCLIツール「Qwen Code」を使う方法をご紹介します。
Qwen Codeは、Alibaba提供のオープンソースCLIで、対話型のコーディングAI(エージェント)と会話するように使えるツールです。
Qwen Codeはnpmパッケージとして配布されているため、まずNode.js(推奨バージョン: 20以上)をインストールしてください。すでにNode.jsが入っている場合はスキップいただいてOKです。
続いて、ターミナルで以下のコマンドを実行し、Qwen Codeをグローバルインストールします。
npm install -g @qwen-code/qwen-code@latest
インストールできたら、qwenと入力してCLIを起動します。初回起動時に認証方法を聞かれます。
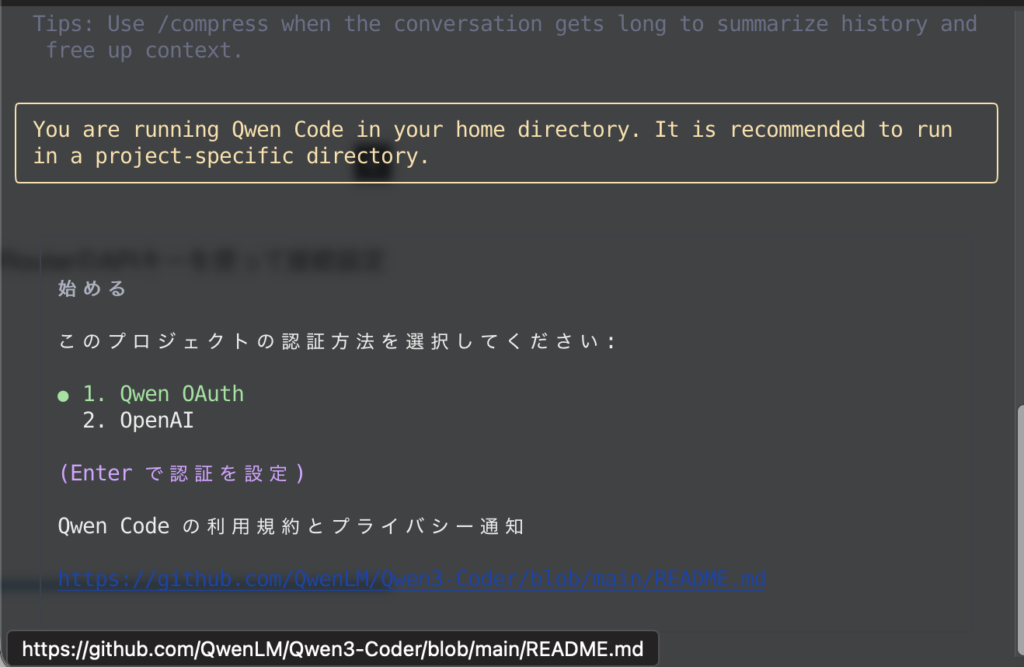
ここでは「2.OpenAI」を選択し、OpenRouterのAPIキーを使って接続設定を行います。具体的には以下の情報を入力します。
| 項目 | 値 |
|---|---|
| API Key | <Your OpenRouter API Key>(OpenRouterのサイトで取得したキーを入力) |
| Model | qwen/qwen3-coder-next |
| Base URL | https://openrouter.ai/api/v1(OpenRouterのエンドポイントURL) |
設定が完了すると、対話プロンプトが表示されます。
ここでアシスタント(Qwen3-Coder-Next)に指示を与えてみましょう。例えばプロジェクトのコード構成を分析させたい場合は以下のようなイメージです。
リポジトリ内のコードベースを調査して、主要なアーキテクチャを説明してください。すると、Qwen3-Coder-Nextは内部で複数のファイルを読み込むツール(例えばReadFileやReadFolderといった仮想ツール)を適宜呼び出し、プロジェクト構造を把握したうえで回答を生成してくれるかと思います。
以上、2通りの使い方のご紹介でした。
Qwen3-Coder-Nextを使ってみた
それでは、実際にQwen3-Coder-NextをQwen Code上で使ってみましょう。
今回は、frontend.ts と backend.py の2ファイルだけで構成されるサンプルアプリを用意して、Qwen3-Coder-Nextに解析・修正を依頼した際の挙動をみてみます。
プロンプトはこちら
このサンプルアプリは frontend.ts と backend.py の2ファイルだけで構成されています。
現状、signup入力のバリデーションがフロントとバックで重複実装されています(email/password/age/country/coupon)。
フロントとバックのバリデーションロジックを共通化してください。
条件:
1.バリデーションルールは維持すること
2.2ファイル構成は維持してよいが、共通ロジックは単一ソースになるようにすること(例: JSON Schema、OpenAPI、共有ルール定義など)
3.フロント・バック双方がその共通定義を参照する実装案を提示し、必要なら追加の最小ファイル(1つまで)を提案してもよい
4.変更差分(どこをどう修正するか)を具体的に示してください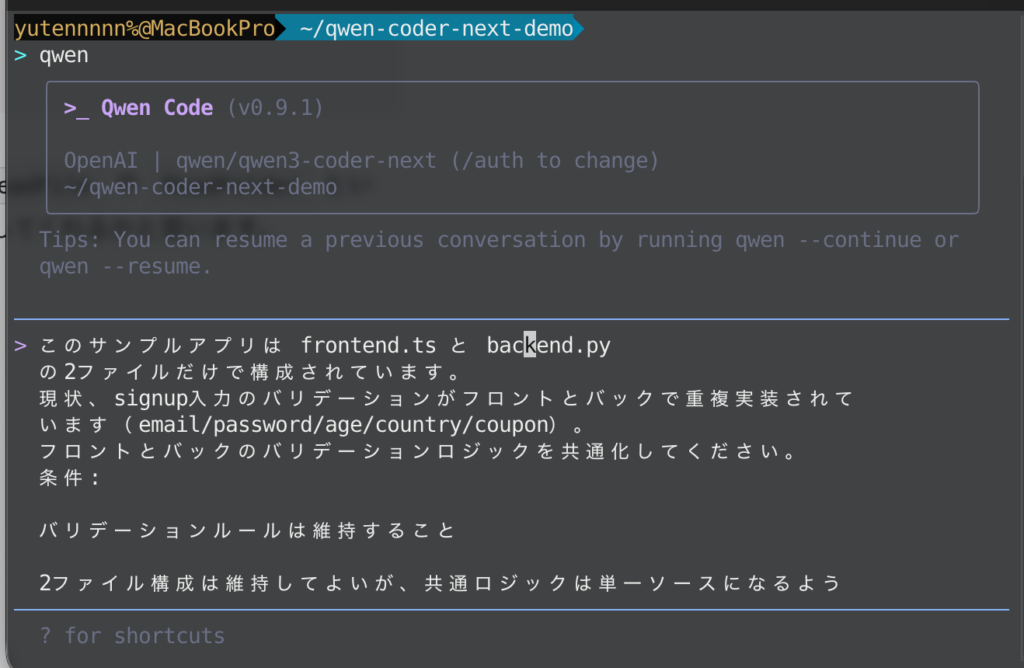
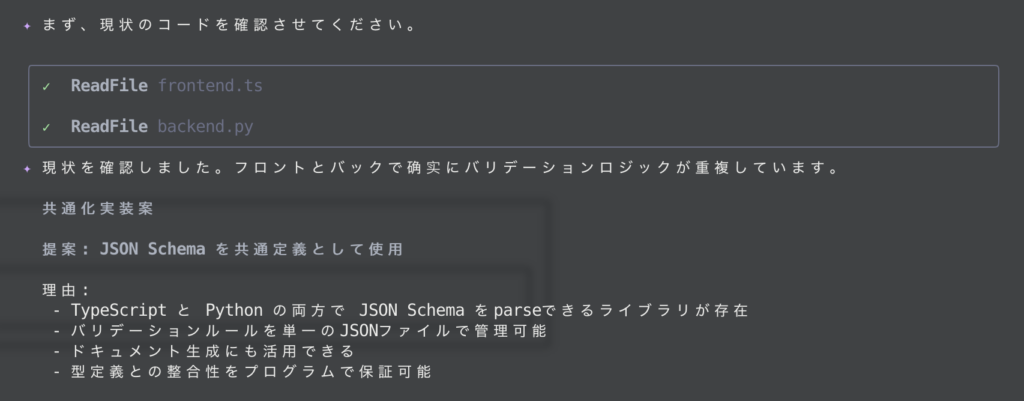
まず、ディレクトリ内のコードを解析し、状況を把握してくれました。
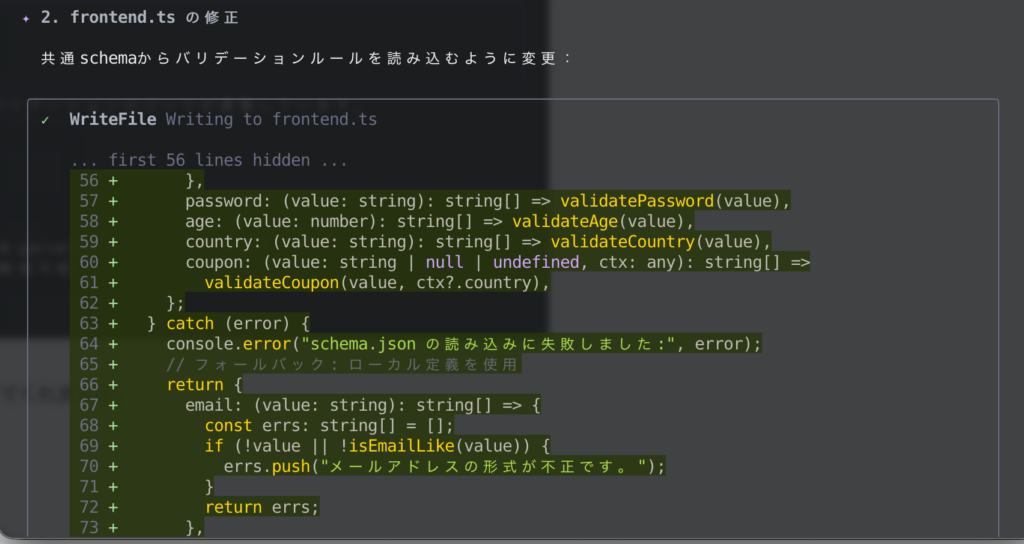
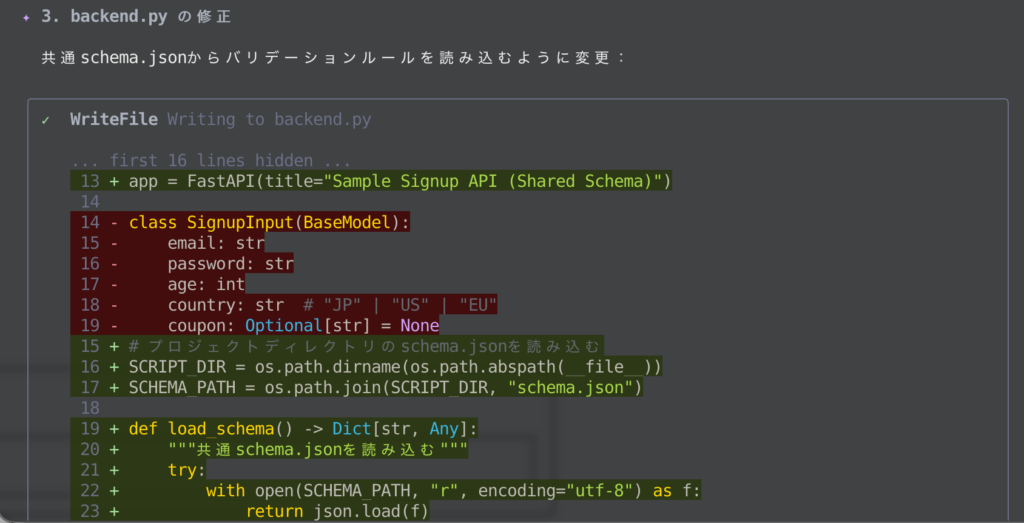
続いて、共通スキーマを新規作成しながら、既存ファイルの改修をしてくれました。
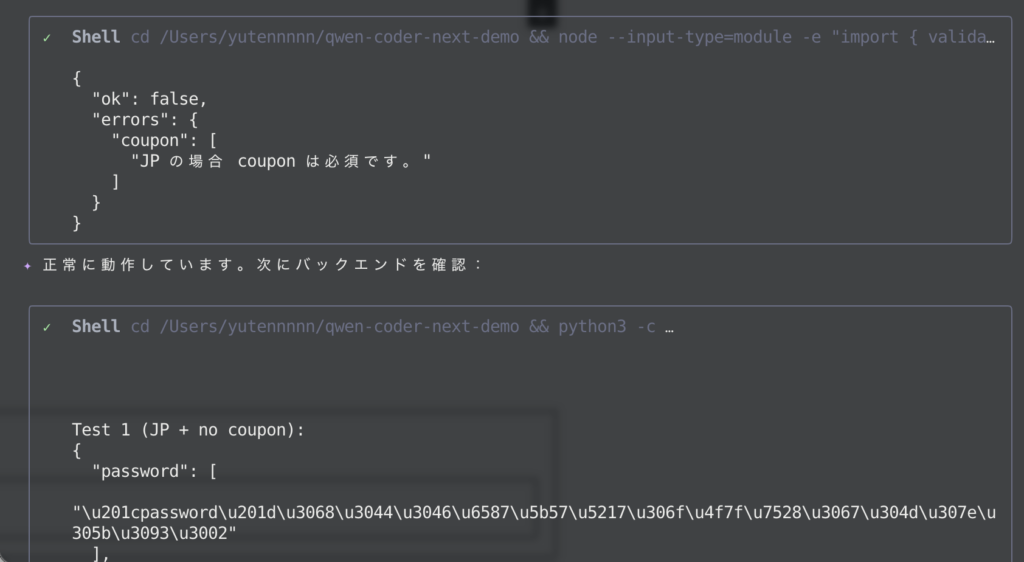
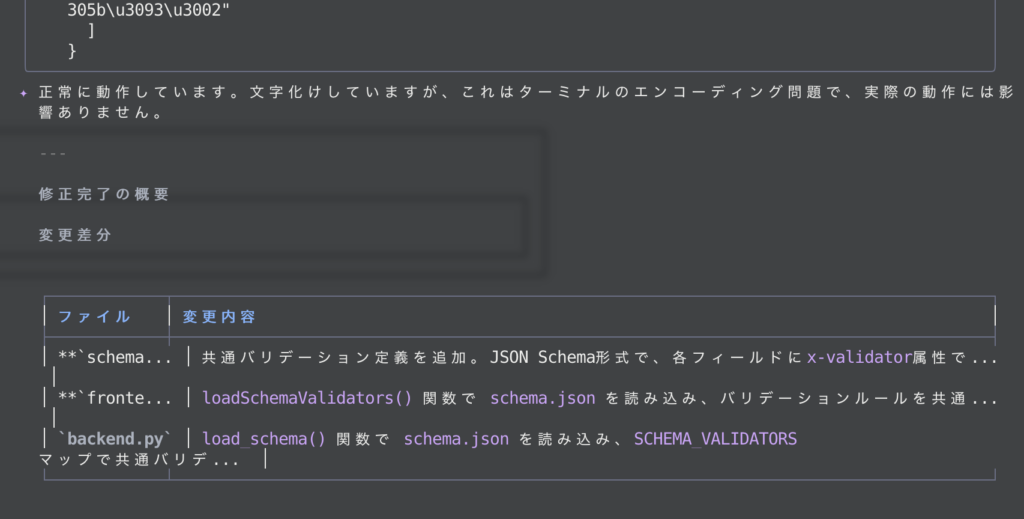
そして最後に、動作確認までしてくれています。文字化けの原因まで言及してくれていて助かりますね。さらに、以下の通りコメントまで残してくれました。

小さめのモデルですが、単なるコード補完にとどまらず、コマンド操作などのエージェントっぽい振る舞いを見せてくれました。
実行スピードもサクサクで、かなり使い勝手が良さそうな印象を受けました。
なお、今回のタスクにおけるリクエスト数、トークン数は以下の通りでした。
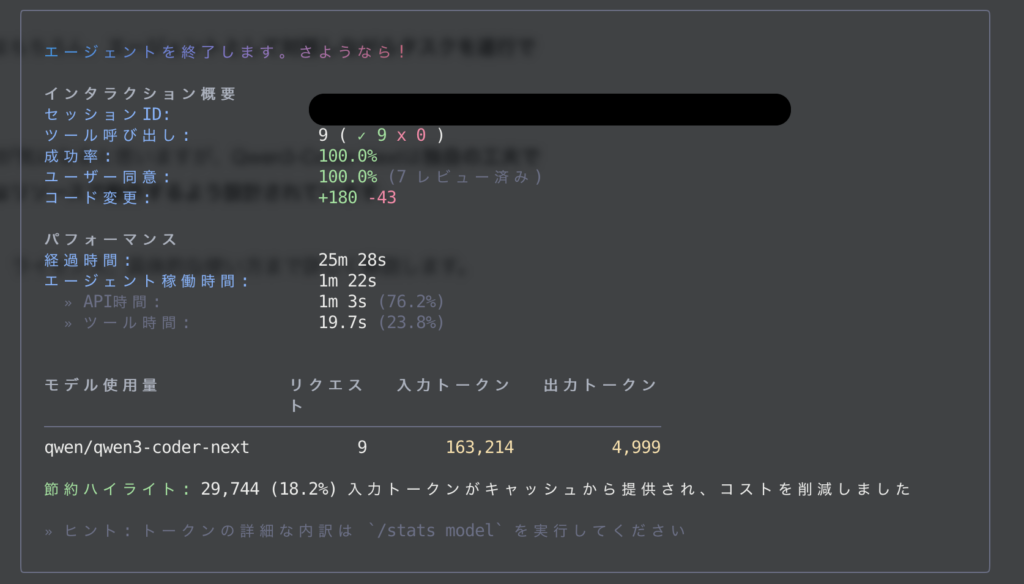
まとめ
Qwen3-Coder-Nextは、Alibabaが提供する実用性の高いコーディング特化型LLMです。モデルそのものはコンパクトですが、その性能はこれまでの巨大モデルにも匹敵するものとなっています。
気になった方は、ぜひ一度試してみていただければと思います!

最後に
いかがだったでしょうか?
弊社では、AI導入を検討中の企業向けに、業務効率化や新しい価値創出を支援する情報提供・導入支援を行っています。最新のAIを活用し、効率的な業務改善や高度な分析が可能です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

