
【Qwen3-VL-Embedding】入力情報を意味ベースのベクトルに変換する大規模モデルの概要・Rerankerとの違い・使い方を徹底解説!
- アリババ発、テキスト・画像・動画など異なる媒体間の情報検索に特化したモデル
- テキストや画像などあらゆる情報を意味ベースのベクトルに変換する大規模モデル
- Embeddingモデルで効率良く検索し、結果をRerankerで確認することで、検索の精度と再現率を大幅に向上させることができる
2026年1月8日、アリババが新たなマルチモーダル検索向けAIモデル「Qwen3-VL-Embedding」をオープンソースで公開しました!
同時に発表された関連モデル「Qwen3-VL-Reranker」と組み合わせることで、テキスト・画像・動画など異なるモダリティ間の検索精度を飛躍的に高めることができると注目を集めています。
Qwen3-VL-Embeddingは、テキストや画像などあらゆる情報を意味ベースのベクトルに変換する大規模モデルです。従来は、テキストと画像を別々に扱っていたのに対して、このモデルではそれらを共通の埋め込み空間にマッピングすることができるとのこと。
そこで本記事では、このQwen3-VL-Embeddingについて、その概要や同時公開されたQwen3-VL-Rerankerとの違い、ライセンス情報や使い方について詳しく解説します。
ぜひ最後までご覧ください!
Qwen3-VL-Embeddingの概要

Qwen3-VL-Embeddingは、アリババがオープンソース公開した最新のマルチモーダル埋め込みモデルです。
基本となる大規模言語モデル「Qwen3-VL」(視覚と言語の両方を扱える基盤モデル)をベースに設計されていて、テキスト・画像・スクリーンショット・動画といった多様な入力モダリティを1つの統一的なベクトル空間に写像します。
ベースとなるQwen3-VL-Embeddingが、クエリやドキュメントを高次元ベクトルに変換し、大量データの中から大まかに関連する候補を高速に絞り込むのに対し、同時公開されたQwen3-VL-Rerankerでは、それらの候補とクエリを対にして入力し、モデル内部で両者を突き合わせて精密に関連度を評価します。
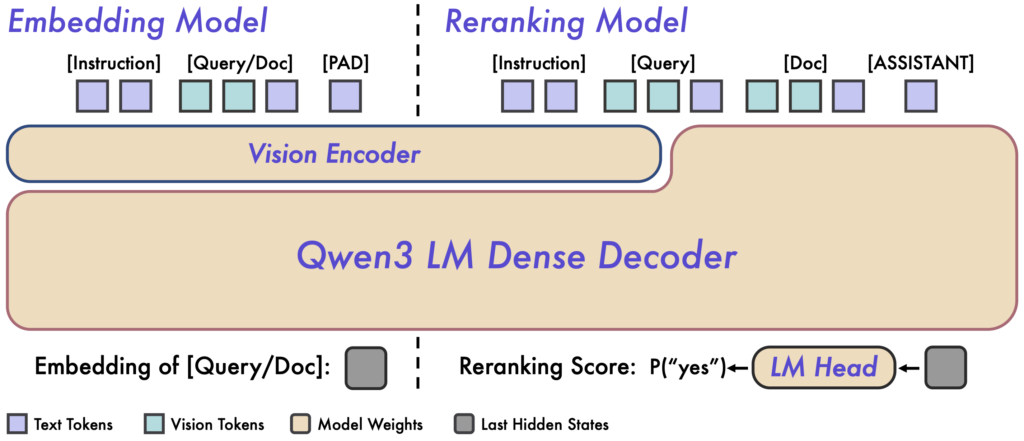
この2段階構成によって、まず、Embeddingモデルで効率良く検索し、その結果をRerankerで詳細に確認することで、検索の精度と再現率を大幅に向上させることができます。
さらに、Qwen3-VL-Embeddingシリーズでは、Matryoshka Representation Learning(MRL)という手法を導入していて、埋め込み次元を柔軟に調整可能となっています。
例えば、2Bパラメータ版では、最大2048次元のベクトルを出力できますが、必要に応じて64次元から2048次元の範囲で出力次元を選ぶことができるようです。
加えて、入力に対してタスク固有の指示文(Instruction)を与える機能も備えています。Hugging Face上の公式発表によれば、この指示対応モードを活用することで、多くの下流タスクにおいて、1~5%程度の精度向上が見られたとのことです。
なお、Qwen3-VL-Rerankerについて詳しく知りたい方は、以下の記事も参考にしてみてください。

Qwen3-VL-Embeddingの性能
Qwen3-VL-Embeddingの性能は、多様なマルチモーダル検索ベンチマークで最先端(SOTA)レベルと評価されています。
特に、画像・動画・文書など、複数モーダリティを含む総合的な評価基盤MMEB-V2での成績においてQwen3-VL-Embedding-8B(8億パラメータ版)は、総合スコア77.8を記録し、他のあらゆるモデルを押さえて第1位となりました。
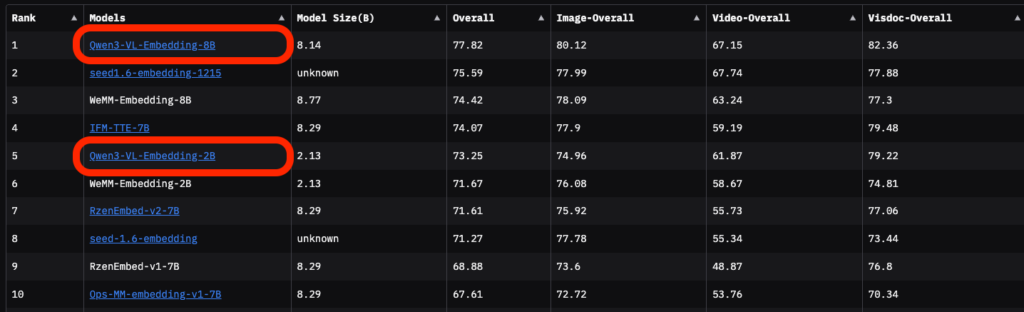
これは、従来トップだったモデル(例えばIFM-TTEやRzenEmbedなどの8Bクラス)を上回る結果で、現時点(2026年1月)で、マルチモーダル埋め込み分野の最高水準に位置することを意味します。
実際、MMEB-V2の詳細を見ると、Qwen3-VL-Embedding-8Bは、画像検索系のタスクで平均80.1点、動画検索系で67.1点、視覚文書(スクリーンショットやPDFなど)でも他モデルを凌駕する高精度を達成しており、バランス良く優秀な成績を収めています。


Qwen3-VL-Rerankerとの違い
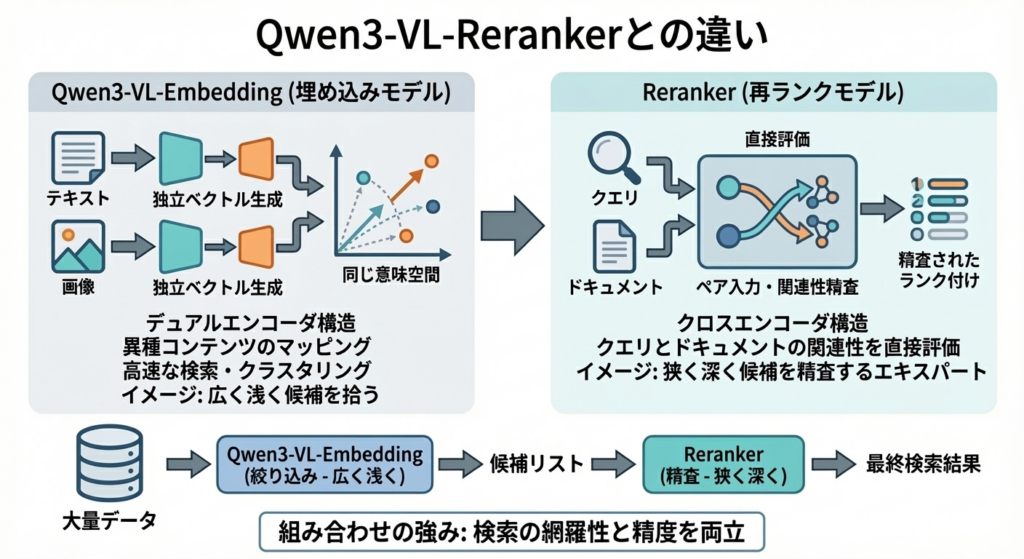
Qwen3-VL-Embedding(埋め込みモデル)と、Reranker(再ランクモデル)は、役割とアーキテクチャが明確に異なります。
Embeddingモデルは、デュアルエンコーダ構造を採用していて、テキストでも画像でも入力1件ごとに独立したベクトル表現を生成します。これによって、異種のコンテンツ同士を同じ意味空間にマッピングし、ベクトル類似度による高速な検索・クラスタリングを可能にします。
一方のRerankerは、クロスエンコーダ構造を取っていて、クエリとドキュメントをペアで入力して、両者間の関連性をモデル内部で直接評価します。
つまり、Embeddingモデルが広く浅く候補を拾い上げる役割であるのに対して、Rerankerは狭く深く候補を精査するエキスパートのようなイメージです。
そのため、Reranker単体では大量データからの検索には向きませんが、Embeddingモデルで絞り込んだ後の候補を細かくランク付けする段階で活躍してくれます。
2つを組み合わせることで、検索の網羅性と精度を両立できる点が、このシリーズの強みと言えると思います。
Qwen3-VL-Embeddingのライセンス
Qwen3-VL-Embeddingは、Apache License 2.0で公開されています。
Apache 2.0は、寛容なオープンソースライセンスとして知られていて、商用利用から改変・再配布まで幅広い用途が許可されています。
また、本ライセンスには特許権の明示的な許諾も含まれており、モデルの提供者が保有する特許についても利用者側が安心して使えるように配慮されています。
| 利用用途 | 可否 | 備考 |
|---|---|---|
| 商用利用 | ⭕️ | |
| 改変 | ⭕️ | |
| 配布 | ⭕️ | ※条件付き |
| 特許使用 | ⭕️ | |
| 私的使用 | ⭕️ |
Qwen3-VL-Embeddingの料金
Qwen3-VL-Embeddingはオープンソースで提供されているため、モデル自体の利用は無料です。
ダウンロードしてローカル環境で実行する場合、ライセンス料やサブスクリプション費用といったものは一切かかりません。
Qwen3-VL-Embeddingの使い方
Qwen3-VL-Embeddingはオープンソースモデルのため、自分でダウンロードしてローカル環境で実行することも、クラウド上で動かすこともできます。
こちらでは、代表的な利用方法を順番にご説明していきます。
1.環境の準備とモデルの入手
まずは実行環境を用意します。深層学習モデルを扱うため、Python環境と必要なライブラリをインストールしましょう。
Qwen3-VL-Embeddingを扱うには、PyTorchとHugging Face Transformers、そしてAlibaba提供のユーティリティパッケージqwen-vl-utilsが必要です。以下のコマンドでインストールできます。
pip install torch transformers qwen-vl-utils
モデルの入手方法は2通りあります。
ひとつは、Hugging Face Hubからダウンロードする方法、もうひとつはGitHubリポジトリから取得する方法です。
Hugging Faceでは「Qwen/Qwen3-VL-Embedding-2B」や「Qwen/Qwen3-VL-Embedding-8B」といったリポジトリ名でモデルが公開されており、これらを指定することで、自動的にモデルデータをダウンロード・ロードできます。
# 依存のインストール(uvでもpipでもOKです)
pip install -U huggingface-hub
# 2Bをローカルに保存
huggingface-cli download Qwen/Qwen3-VL-Embedding-2B --local-dir ./models/Qwen3-VL-Embedding-2B
# 8Bをローカルに保存(必要に応じて)
huggingface-cli download Qwen/Qwen3-VL-Embedding-8B --local-dir ./models/Qwen3-VL-Embedding-8BGitHubの場合、QwenLM/Qwen3-VL-Embeddingリポジトリにモデルの重みやコード一式があり、そこからモデルファイルをダウンロードしてローカルパスを指定して読み込むことも可能です。
# リポジトリ取得(コード一式)
git clone https://github.com/QwenLM/Qwen3-VL-Embedding.git
cd Qwen3-VL-Embedding
# 環境セットアップ(uv + 依存インストール)
bash scripts/setup_environment.sh
source .venv/bin/activate
初めてモデルをロードする際には数GB~十数GB程度のデータをダウンロードすることになるため、ネットワーク環境とストレージ空き容量を準備しておきましょう。
2.モデルのロードと初期化
環境とモデルの準備が整ったら、実際にモデルをロードしていきます。
Hugging Face経由の場合、Transformersライブラリのインターフェースを使ってモデルを読み込めますが、Qwen3-VL-Embeddingでは独自のユーティリティクラスQwen3VLEmbedderが提供されています。このクラスを使うと、複雑な前処理などを意識せずに簡単に埋め込みベクトルを取得できます。
具体的には、Pythonコード上で以下のようにモデルをロードします。
from qwen_vl_utils import Qwen3VLEmbedder # 実際には適切なパスからインポートしましょう
model = Qwen3VLEmbedder(model_name_or_path="Qwen/Qwen3-VL-Embedding-2B")上記のようにmodel_name_or_pathにHugging Face上のモデル名を渡すと、自動的にモデルをダウンロード&ロードしてくれます。GitHubからファイルをダウンロード済みの場合は、そのパスを指定することも可能です。
ターミナル上で、直接対話実行したい場合は、以下のように実行できます。
python - << 'PY'
import os
from src.models.qwen3_vl_embedding import Qwen3VLEmbedder
path = os.path.abspath("./models/Qwen3-VL-Embedding-2B")
print("path:", path)
model = Qwen3VLEmbedder(model_name_or_path=path)
print("loaded")
PY
3.入力データの準備(テキスト・画像の形式)
モデルがロードできたら、次に検索したいデータをベクトル化してみましょう。
※なお、以降のステップ3〜5のPythonコードは、最後にPythonスクリプト(run_demo.py)にまとめて実行しますので、ステップ3〜5については、やることの概要を掴んでいただければと思います。
Qwen3-VL-Embeddingでは、テキストや画像、動画といった入力をPythonのディクショナリ形式で指定します。単一の入力を表す辞書には、以下のようなキーを含めることができます。
| キー | 詳細 |
|---|---|
| “text” | テキスト文字列(例:”夕日のビーチで犬と遊ぶ女性”) |
| “image” | 画像データ(ローカル画像ファイルのパス、画像URL、またはPIL.Imageオブジェクト) |
| “video” | 動画データ(ローカル動画ファイルのパス、動画URL、またはフレームのリスト) |
この他、必要に応じて"instruction"キーで埋め込み生成時の指示文を与えることもできます。指示文は「ユーザの入力内容をどう表現するか」をモデルに伝える短いテキストで、デフォルトでは "Represent the user's input."(ユーザ入力を表現せよ)という汎用的なものが使われます。
例えば「画像検索用のベクトルを作れ」というニュアンスを出したければ"instruction": "Retrieve images or text relevant to the user's query."のように書くとよいかと思います。
では実際に入力データを準備してみましょう。コード上では、以下のようなイメージになります。
queries = [
{"text": "夕日のビーチで犬と遊ぶ女性の写真"} # ユーザが探しているもの(日本語クエリ)
]
documents = [
{"text": "A woman shares a joyful moment with her golden retriever on a sun-drenched beach at sunset, as the dog offers its paw in a heartwarming display of companionship and trust."},
{"image": "/path/to/beach_dog_photo.jpg"}, # ローカルにある画像ファイルへのパスやURL
{"text": "A woman shares a joyful moment ... (略)", "image": "/path/to/beach_dog_photo.jpg"}
]上記ではクエリは日本語テキスト、ドキュメント候補には英語テキスト説明や画像を入れています。実際には、さらに複数のクエリや多数の候補をまとめて処理できますが、まずはシンプルに考えておきましょう。
4.埋め込みベクトルの取得
準備した入力データ(クエリリスト+ドキュメントリスト)をモデルに与えてベクトル変換します。
Qwen3VLEmbedderにはmodel.process()というメソッドが用意されていて、これに入力リストを渡すだけで対応するベクトルが返ってきます。今回の例ではqueries + documentsを一つのリストに結合し、それをprocess()に渡すと計4件分のベクトルが得られるイメージです。
実行コード例は以下の通りです。
# モデルにクエリとドキュメントをまとめて投入
inputs = queries + documents
embeddings = model.process(inputs)embeddingsには、各入力に対応する埋め込みベクトル(PyTorchのテンソル)が格納されています。
ベクトルの次元はモデルや設定によりますが、デフォルトでは、2Bモデルなら2048次元、8Bモデルなら4096次元です。先述したMRL機能を活用すれば、この次元数を変更することも可能ですが、特に理由がなければデフォルトの高次元のままで問題ないと思います。
5.類似度計算と検索結果の確認
ベクトルが取得できたら、最後にクエリと各ドキュメントの類似度を計算します。
類似度計算には、コサイン類似度や内積などの指標が使われますが、Qwen3-VL-Embeddingの場合、ベクトルがL2正規化されている(ベクトルの長さが1に規格化されている)ので、内積を取ることでコサイン類似度と同等の値を得られます。
embeddings行列からクエリ部分とドキュメント部分を取り出して行列乗算することで、一度にスコアを計算できます。
import numpy as np
# embeddings[:len(queries)] がクエリ側ベクトル集合、embeddings[len(queries):] がドキュメント側
query_emb = embeddings[:len(queries)]
doc_emb = embeddings[len(queries):]
# 内積(cos類似度)を計算
scores = (query_emb @ doc_emb.T)
print(scores.tolist())このscores行列にはクエリと各ドキュメントとの類似度が数値で入っています。今回クエリは1件だけなので、scoresは1行3列の行列(実質リスト)になるはずです。
では、ここまでの内容をrun_demo.pyスクリプトに保存して実行しましょう。
入力画像は、ChatGPT Imagesで生成したこちらの画像とします。

import os
import numpy as np
from src.models.qwen3_vl_embedding import Qwen3VLEmbedder
# 1) Embeddingモデルをロード
emb_path = os.path.abspath("./models/Qwen3-VL-Embedding-2B")
model = Qwen3VLEmbedder(model_name_or_path=emb_path)
# 3) 入力データの準備(画像パスは実在するものに変更してください)
img_path = os.path.abspath("./assets/beach_dog_photo.jpg") # ←ここだけご自身の画像に合わせてください
queries = [{"text": "夕日のビーチで犬と遊ぶ女性の写真"}]
documents = [
{"text": "A woman shares a joyful moment with her golden retriever on a sun-drenched beach at sunset, as the dog offers its paw in a heartwarming display of companionship and trust."},
{"image": img_path},
{"text": "A woman shares a joyful moment ...", "image": img_path},
]
# 4) 埋め込みベクトルの取得
inputs = queries + documents
embeddings = model.process(inputs)
# 5) 類似度計算(内積=cos類似度相当)
query_emb = embeddings[:len(queries)]
doc_emb = embeddings[len(queries):]
scores = (query_emb @ doc_emb.T)
print("Embedding scores:", scores.tolist())
私の環境での実行結果は以下の通りでした。
| キー | 類似度 |
|---|---|
| 候補1(英語テキスト説明) | 0.7071 |
| 候補2(画像) | 0.5360 |
| 候補3(テキスト+画像) | 0.6023 |

この数値を見ると、クエリに対して、候補1のテキスト説明が最も高いスコアを持っていることが分かります。
次いで、その画像(候補2,3)がやや劣ったスコアで並んでいます。
一方、例えばまったく無関係なクエリ(今回用意していませんが、「夜の都市の景色」など)であれば、これら候補とのスコアは0.1や0.0台といった低い値になるかと思います。
つまり、関連性が高い組み合わせほどスコアが高く、低い組み合わせはスコアも低いという形で、モデルがしっかり意味的なマッチングを行っていることが確認できます。
このようにして得られたスコアに基づいて、最も高いものをユーザへの検索結果として返す、というのが基本的な使い方です。
今回はシンプルな例で紹介しましたが、実際には、クエリに対して大量のデータベースからトップN件を高速に探すにはベクトルデータベース(FaissやMilvusなど)の導入が有効になるかもしれません。
しかし、原理的な部分はここで紹介したとおり「テキストや画像をembed→類似度計算」という流れになります。
Qwen3-VL-Embeddingを使ってみた
それでは、先ほどのrun_demo.pyの内容をベースに、クエリやテキストを変更すると類似度がどう変化するか確認してみましょう。
検証①:日本語クエリ→英語テキスト/画像
クエリとテキスト部分を以下の通り候補を4つに変更して、実行します。
queries = [
{"text": "夕日の海辺で、女性がゴールデンレトリバーと握手している写真"}
]
documents = [
{"text": "A woman in a white sundress gives a high-five to her golden retriever on a beach at sunset."},
{"image": img_path},
# 似ているけど違う候補(あえてズラすとスコア差が出るかも)
{"text": "A dog running on a beach at sunset (no people)."},
{"text": "A woman and her dog at the beach in daytime (not sunset)."},
]結果はこちら

| キー | 類似度 | 所感 |
|---|---|---|
| 候補1(夕日、海辺、女性、犬、ハイタッチ) | 0.7499 | 1番近くて妥当な結果 |
| 候補2(元の画像) | 0.5633 | テキストほどではないが、中くらい |
| 候補3(犬だけの夕日ビーチ) | 0.5438 | 人がいない分、下がるのは妥当 |
| 候補4(女性と犬だが、夕日でなく昼間) | 0.6864 | もう少し低い類似度を期待したが、意外と高い |
検証②:全く無関係のtextを1つ追加してみる
検証①の内容に、候補5として、以下のtextを追加した場合、どういった類似度が出るか見てみます。
{"text": "A detailed recipe for making ramen noodles at home."}
結果はこちら

| キー | 類似度 | 所感 |
|---|---|---|
| 候補1(夕日、海辺、女性、犬、ハイタッチ) | 0.7499 | 1番近くて妥当な結果 |
| 候補2(元の画像) | 0.5633 | テキストほどではないが、中くらい |
| 候補3(犬だけの夕日ビーチ) | 0.5438 | 人がいない分、下がるのは妥当 |
| 候補4(女性と犬だが、夕日でなく昼間) | 0.6864 | もう少し低い類似度を期待したが、意外と高い |
| 候補5(まったく無関係のテキスト) | 0.2478 | 想定通り低スコア |
こちらの結果から、Embedding段階でも、ざっくり関連・非関連のフィルタが効果的に作用していることが分かりました。
上位数件をRerankerモデルに渡すと、さらに精度や説明性が上がる可能性があるので、気になる方はぜひ一度試してみてください!
まとめ
Qwen3-VL-Embeddingは、テキスト・画像・動画といった様々なデータを同じベクトル空間で表現し、高速に類似検索できる画期的なマルチモーダル埋め込みモデルです。
Qwen3-VL-Rerankerとのコンビネーションによって、テキスト・画像・動画・UI画面など多様な情報源を横断して検索し、しかもその結果を高精度に並び替えるという、これまでにない高度な検索エージェントを構築できます。
今後のアップデートやコミュニティからの派生プロジェクトにも注目しつつ、Qwen3-VL-Embeddingを活用していきたいですね。

最後に
いかがだったでしょうか?
弊社では、AI導入を検討中の企業向けに、業務効率化や新しい価値創出を支援する情報提供・導入支援を行っています。最新のAIを活用し、効率的な業務改善や高度な分析が可能です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。


