
【Qwen3-VL-Reranker】マルチモーダル検索の精度をUPする再ランキングモデルの実力と使い方を徹底解説!

- アリババ発、テキスト・画像・動画など異なる媒体間の情報検索に特化したモデル
- 検索結果の精度を飛躍的に高める再ランキングモデルとして注目される
- Embeddingモデルで検索し、その結果をRerankerで確認することで、検索の精度と再現率を大幅に向上させることができる
2026年1月8日、アリババがマルチモーダル検索の世界に大きな一歩となる新モデル「Qwen3-VL-Reranker」をオープンソースで公開しました!
このモデルは、強力なビジョン・ランゲージ基盤モデル「Qwen3-VL」を土台として構築された、テキスト・画像・動画など異なる媒体間の情報検索に特化したモデルです。
従来の検索は、キーワードの単純な一致に頼っていましたが、今回の発表で意味ベースのマッチングができる可能性を秘めています。
特にQwen3-VL-Rerankerは、検索結果の精度を飛躍的に高める再ランキングモデルとして注目されています。
そこで本記事では、このQwen3-VL-Rerankerについて、その概要や同時公開されたQwen3-VL-Embeddingとの違い、ライセンス情報や使い方について詳しく解説します。
ぜひ最後までご覧ください!
Qwen3-VL-Rerankerの概要
Qwen3-VL-Reranker(以下、Reranker)は、テキスト・画像・スクリーンショット・動画といったあらゆる組み合わせの入力を受け付け、与えられたクエリとドキュメントとの関連性スコアを出力する再ランキングモデルです。
ベースとなるQwen3-VL-Embedding(以下、Embeddingモデル)が、クエリやドキュメントを高次元ベクトルに変換し、大量データの中から大まかに関連する候補を高速に絞り込むのに対し、Rerankerは、それらの候補とクエリを対にして入力し、モデル内部で両者を突き合わせて精密に関連度を評価します。
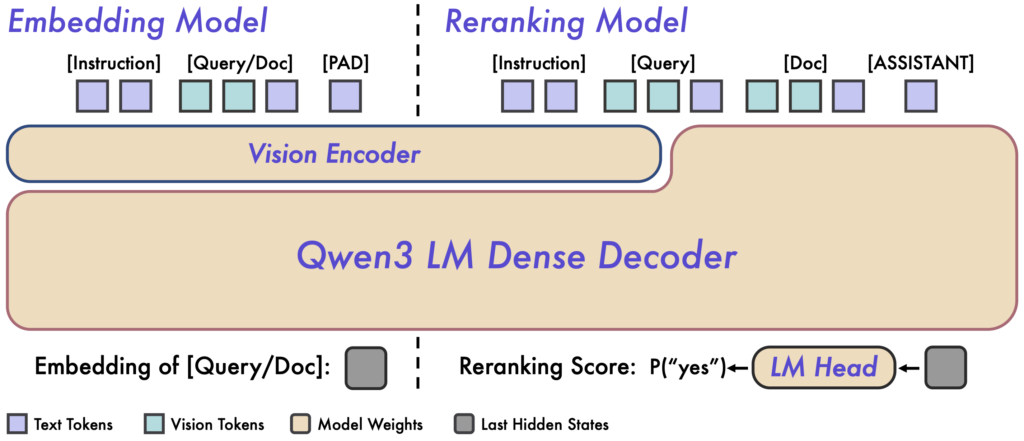
この2段階構成によって、まず、Embeddingモデルで効率良く検索し、その結果をRerankerで詳細に確認することで、検索の精度と再現率を大幅に向上させることができます。
Rerankerは、Qwen3-VLシリーズの1つとして、30以上の言語に対応した多言語能力も備えていて、テキストとビジュアル情報を統合的に理解できるのが特徴です。
「テキスト+画像やテキスト+動画」といった複合モーダル入力にも対応していて、画像と言語をまたぐ質問応答や、動画とテキストのマッチング、さらには、マルチモーダルなデータのクラスタリングなど、多彩なタスクで最先端の性能を発揮します。
また、コンテキスト長は最大32kトークンで、長文や長時間の動画シナリオにも対応可能となっています。
モデルサイズは、用途に応じて約20億パラメータ(2B)版と、80億パラメータ(8B)版が用意されており、精度と計算リソースのバランスを見て選択することができます。
なお、Qwen3-VL-Embeddingについて詳しく知りたい方は、以下の記事も参考にしてみてください。
Qwen3-VL-Rerankerの性能
Qwen3-VL-Rerankerは、マルチモーダル分野の権威ある評価セットであるMMEB-v2(画像・動画検索など複数サブタスクの集まり)やMMTEB、視覚文書検索向けのJinaVDR、ViDoRe v3といったデータセットを用いたテストで、Qwen3-VLシリーズはすばらしい成績を収めています。

例えば、8B版のEmbeddingモデルは、MMEB-v2の平均スコアで73.4を記録し、既存のオープンソースモデルおよび主要なクローズドソースの商用サービスのスコアを上回るトップ性能を出しています。
そこに、Rerankerモデルを組み合わせることで精度が一段と向上し、8B版のRerankerは平均79.2とEmbeddingモデルを大きく上回るスコアを達成しています。
特に、RerankerはJinaVDRやViDoRe v3といった視覚文書検索タスクで一貫して最高性能を叩き出しており、細分類目の多くで1位を獲得しています。
一方、2B版の軽量モデルについても、Reranker 2BはEmbedding 2Bを上回る精度を発揮しており、小規模モデルでも再ランキングによる強みが確認できます。


Qwen3-VL-Embeddingとの違い
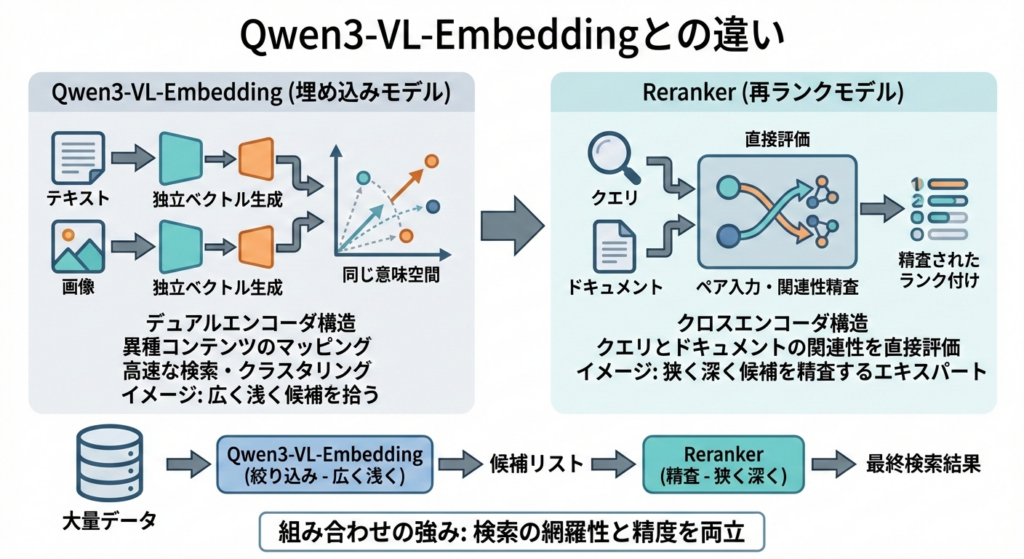
Qwen3-VL-Embedding(埋め込みモデル)と、Reranker(再ランクモデル)は、役割とアーキテクチャが明確に異なります。
Embeddingモデルは、デュアルエンコーダ構造を採用していて、テキストでも画像でも入力1件ごとに独立したベクトル表現を生成します。これによって、異種のコンテンツ同士を同じ意味空間にマッピングし、ベクトル類似度による高速な検索・クラスタリングを可能にします。
一方のRerankerは、クロスエンコーダ構造を取っていて、クエリとドキュメントをペアで入力して、両者間の関連性をモデル内部で直接評価します。
つまり、Embeddingモデルが広く浅く候補を拾い上げる役割であるのに対して、Rerankerは狭く深く候補を精査するエキスパートのようなイメージです。
そのため、Reranker単体では大量データからの検索には向きませんが、Embeddingモデルで絞り込んだ後の候補を細かくランク付けする段階で活躍してくれます。
2つを組み合わせることで、検索の網羅性と精度を両立できる点が、このシリーズの強みと言えると思います。
Qwen3-VL-Rerankerのライセンス
Qwen3-VL-Rerankerは、Apache License 2.0で公開されています。
Apache 2.0は、寛容なオープンソースライセンスとして知られていて、商用利用から改変・再配布まで幅広い用途が許可されています。
また、本ライセンスには特許権の明示的な許諾も含まれており、モデルの提供者が保有する特許についても利用者側が安心して使えるように配慮されています。
| 利用用途 | 可否 | 備考 |
|---|---|---|
| 商用利用 | ⭕️ | |
| 改変 | ⭕️ | |
| 配布 | ⭕️ | ※条件付き |
| 特許使用 | ⭕️ | |
| 私的使用 | ⭕️ |
Qwen3-VL-Rerankerの料金
Qwen3-VL-Rerankerはオープンソースで提供されているため、モデル自体の利用は無料です。
ダウンロードしてローカル環境で実行する場合、ライセンス料やサブスクリプション費用といったものは一切かかりません。
Qwen3-VL-Rerankerの使い方
Qwen3-VL-Rerankerはオープンソースで公開されていますので、ローカル環境にダウンロードし、誰でもモデルを動かして試すことができます。
Qwen3-VL-RerankerはPythonベースで提供されていて、GPU上での実行が推奨されています。
Rerankerだけでも動作はしますが、同時リリースされたEmbeddingと組み合わせることで本領発揮してくれますので、Embedding記事を参照して、先にEmbeddingの準備を整えていただいてから、この先を進めていただくとよいと思います。
必要なライブラリとしては、Hugging FaceのTransformers(バージョン4.57.0以上)、qwen-vl-utils(0.0.14以上)、そしてPyTorch 2.8.0などが挙げられています。これらはpipでインストール可能です。
pip install transformers==4.57.0 qwen-vl-utils==0.0.14 torch==2.8.0モデルは、Hugging Face Hubからダウンロードする方法、もうひとつはModelScopeから取得する方法がありますが、Hugging Face Hubからダウンロードする方法をご紹介します。
Hugging Faceでは「Qwen/Qwen3-VL-Reranker-2B」や「Qwen/Qwen3-VL-Reranker-8B」といったリポジトリ名でモデルが公開されており、これらを指定することで、自動的にモデルデータをダウンロード・ロードできます。
# 依存のインストール(uvでもpipでもOKです)
pip install -U huggingface-hub
# 2Bをローカルに保存
huggingface-cli download Qwen/Qwen3-VL-Reranker-2B --local-dir ./models/Qwen3-VL-Reranker-2B
# Embeddingをダウンロードしていない方はこちらも
huggingface-cli download Qwen/Qwen3-VL-Embedding-2B --local-dir ./models/Qwen3-VL-Embedding-2B基本的な検索システムでは、Embeddingモデルで上位候補を絞り込んだ後、その候補群をRerankerモデルに入力して精密な関連度評価を行います。
Qwen3-VL-RerankerもEmbeddingモデルと同様の手順でQwen3VLRerankerクラスからロードできます。
Rerankerへの入力はEmbeddingと少し形式が異なり、"query"キーと複数の"documents"キーを持つディクショナリで指定します。以下のようなイメージです。
from qwen_vl_utils import Qwen3VLReranker
reranker = Qwen3VLReranker(model_name_or_path="Qwen/Qwen3-VL-Reranker-2B")
inputs = {
"instruction": "Retrieve images or text relevant to the user's query.",
"query": {"text": "夕日のビーチで犬と遊ぶ女性の写真"},
"documents": [
{"text": "A woman shares a joyful moment with her golden retriever on ..."},
{"image": "/path/to/beach_dog_photo.jpg"},
{"text": "...", "image": "/path/to/beach_dog_photo.jpg"}
]
}
scores = reranker.process(inputs)
print(scores)reranker.process()は各ドキュメントに対する関連度スコア(通常は[0,1]範囲の値)を返します。
このようにRerankerを使うとEmbeddingモデルのスコアをさらに微調整でき、最終的な順位付け精度が高まります。
もっとも、RerankerはEmbeddingに比べて計算コストが高く、全候補に対して逐一適用するのは非現実的です。そのため「Embeddingで100件に絞り→Rerankerで最終10件に厳選」といった使い分けが推奨されています。
Qwen3-VL-Rerankerを使ってみた
それでは、Qwen3-VL-RerankerをEmbeddingモデルと併用してみましょう。Embedding記事で紹介しているタスクの続きという形で検証していきます。
Embeddingモデルのみの実行結果は以下の通りでした。
| キー | 類似度 | 所感 |
|---|---|---|
| 候補1(夕日、海辺、女性、犬、ハイタッチ) | 0.7499 | 1番近くて妥当な結果 |
| 候補2(元の画像) | 0.5633 | テキストほどではないが、中くらい |
| 候補3(犬だけの夕日ビーチ) | 0.5438 | 人がいない分、下がるのは妥当 |
| 候補4(女性と犬だが、夕日でなく昼間) | 0.6864 | もう少し低い類似度を期待したが、意外と高い |
| 候補5(まったく無関係のテキスト) | 0.2478 | 想定通り低スコア |
Rerankerを併用した場合の結果は以下の通りです。
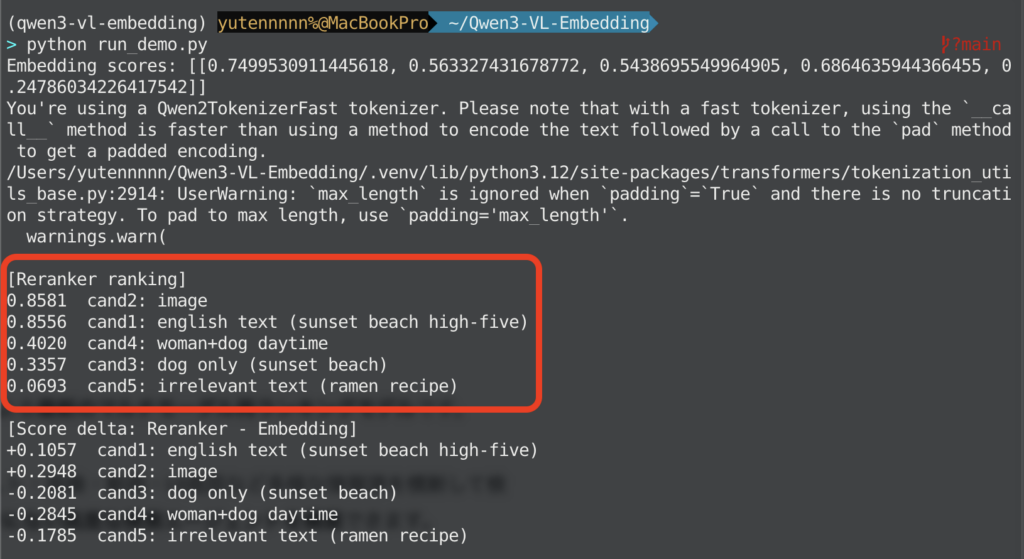
| キー | 類似度 (Embedding) | 類似度 (Embedding+Reranker) |
|---|---|---|
| 候補1(夕日、海辺、女性、犬、ハイタッチ) | 0.7499 | 0.8581 |
| 候補2(元の画像) | 0.5633 | 0.8556 |
| 候補3(犬だけの夕日ビーチ) | 0.5438 | 0.4020 |
| 候補4(女性と犬だが、夕日でなく昼間) | 0.6864 | 0.3357 |
| 候補5(まったく無関係のテキスト) | 0.2478 | 0.0693 |
Embedding段階では、候補1(英語テキスト説明)が最上位で、候補2(画像)は2番手でしたが、Rerankerを併用すると順位が入れ替わり、候補2(画像)が1位、僅差で候補1が2位となりました。
Embeddingでは、だいたい近いものを拾う(昼間の女性+犬もそこそこ高く見えてしまう)傾向があったのが、Rerankerで、クエリの条件(夕日・海辺・女性・ゴールデン・握手/ハイタッチ)に合うものを強く再評価してくれていることが分かりますね。
逆に、まったく無関係なテキストについては、ほとんど0に近い数値で評価してくれていて、Rerankerの精度の高さを確認することができました。
気になった方は、ぜひ一度試してみてください。
まとめ
Qwen3-VL-Rerankerは、大規模言語モデルQwenファミリーによる最新のマルチモーダル再ランキングモデルです。
Qwen3-VL-Embeddingとのコンビネーションによって、テキスト・画像・動画・UI画面など多様な情報源を横断して検索し、しかもその結果を高精度に並び替えるという、これまでにない高度な検索エージェントを構築できます。
マルチモーダルAIの進化を牽引していくのか非常に楽しみですね。今のうちにぜひ触ってみて、その可能性を感じてみてください!

最後に
いかがだったでしょうか?
弊社では、AI導入を検討中の企業向けに、業務効率化や新しい価値創出を支援する情報提供・導入支援を行っています。最新のAIを活用し、効率的な業務改善や高度な分析が可能です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。


