
【imp-v1-3b】軽量MLLMがCAPTCHA認証に挑戦!果たして突破できるのか?

- 小型ながら高性能なマルチモーダルモデル「imp-v1-3b」が登場
- Phi-2とSigLIPを基盤に、最適化・LoRA学習・多様なデータ拡張で高精度を実現
- Apache-2.0ライセンスで商用利用可、GPT-4Vに迫る画像理解力を持つ
画像とテキストを入力するだけで簡単に、AIに画像認識をさせることができるマルチモーダルモデル「imp-v1-3b」が公開されました。
このマルチモーダルモデルAIは小規模でありながら、高性能なんです、、、!
この記事ではimp-v1-3bの使い方や、有効性の検証まで行います。本記事を熟読することで、imp-v1-3bの凄さを実感し、GPT-4Vよりもimp-v1-3bを使いたくなるかもしれません。
ぜひ、最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
imp-v1-3bの概要
imp-v1-3bは、テキストと画像の情報を一緒に扱える、小型のマルチモーダルモデルです。
このモデルを用いることで、以下のように、「入力画像に対してチャット形式での質問」ができるのです。

また、imp-v1-3bの主な特徴として、「わずか3Bのパラメータでありながら、強力な性能を持つ」という点。
小型でありながら強力なSLM Phi-2(2.7B)と、強力な画像エンコーダSigLIP(0.4B)をベースに構築され、LLaVA-v1.5学習セットで学習されています。
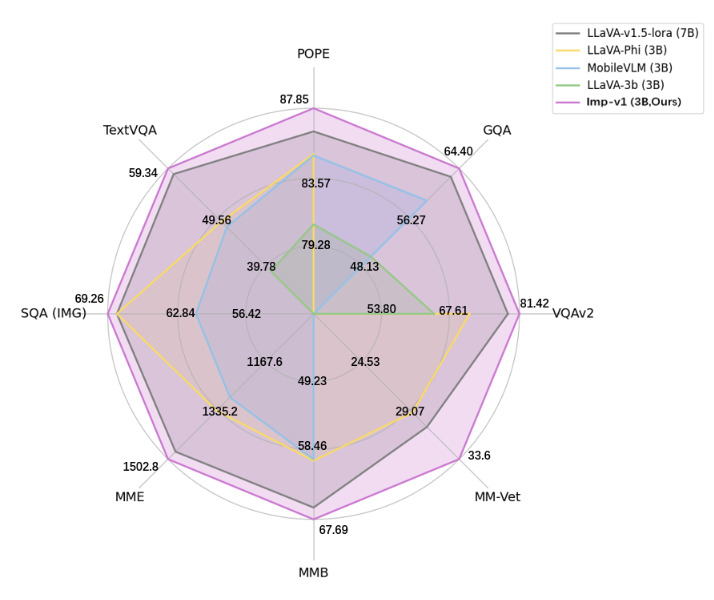
下表に示すように、imp-v1-3bは性能面で、「類似のモデルサイズを持つ同等モデル」を大幅に上回っています。
なお、Microsoftの最強小型テキスト生成モデルについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

imp-v1-3bの技術
imp-v1-3bが「小さなサイズで大きな性能」を実現できた背景には、いくつかの技術的工夫があります。
単にモデルを縮小しただけでは性能は維持できず、アーキテクチャ設計・学習戦略・データ拡張の3つを徹底的に検証・最適化する必要がありました。
ここでは、それぞれの技術について詳しく見ていきます。
アーキテクチャの最適化
imp-v1-3bは、ベースとなるLLMと視覚エンコーダの選択に重点が置かれています。
ベースにはMicrosoftが公開したPhi-2 (2.7B)を採用しており、Phi-2は規模こそ小さいものの、学習データが精緻に整理されており、同規模のMobileLLaMAと比較しても安定した高精度を発揮。
これにより、モデル全体のサイズを抑えつつも、言語処理能力を維持することが可能です。
視覚エンコーダには、従来広く用いられてきたCLIPに代わり、SigLIP-SO400M/14@384を導入。SigLIPは大規模な画像テキスト対照学習により訓練されており、より微細な画像特徴の抽出を得意としています。
その結果、imp-v1-3bは画像理解の精度が一段と向上し、3B規模でありながら7B規模のモデルを超える性能を達成しています。
学習の工夫
モデルの性能を引き出す上で重要なのが学習です。imp-v1-3bでは、効率性と精度を両立するためにLoRAファインチューニングを採用。
LoRAはモデル全体のパラメータを更新するのではなく、特定部分に低ランク行列を挿入して学習を行う方式であり、GPUメモリ消費を抑えつつ精度を確保できます。
実験の結果、Rank=256が最適値であることが示され、無駄な計算リソースを割かずに安定した学習が可能となっています。
さらに、学習エポック数の最適化も実施。LLaVA-1.5では1エポック学習が一般的でしたが、Impの検証では1エポックでは学習不足、3エポックでは逆に精度低下が発生。最終的に2エポックが最適であると結論づけられています。
データ拡張
最後に、モデル性能を大きく左右するのが学習データの質と多様性です。
従来のLLaVAでは約665Kの指導データが使われていましたが、imp-v1-3bではこれを大幅に拡張。
まず、OCRやチャートに特化したデータセット(DVQA, ChartQA, DocVQA, AI2D, InfographicVQA)を32K件追加し、図表やテキスト入り画像の理解を強化しています。
さらに注目すべきは、GPT-4Vを用いた自動アノテーションデータの活用です。
これにより、画像キャプションやマルチモーダル会話データを約33万件生成し、最終的に100万件規模の指導データセットを構築しました。
この結果、特にTextVQAやScienceQAのように文字認識や推論を要するタスクで大幅な性能向上が確認されています。
imp-v1-3bのライセンス
imp-v1-3bのライセンスは、Apache-2.0 licenseです。そのため、商用利用のみならず、ほぼすべての用途で利用可能です。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |


imp-v1-3bのアップデート
Githubを確認すると、いくつかアップデートがされています。

アップデートをみると、現状はImp-v1.5-2B/3B/4Bが最新のようです。後述の検証部分で実際にImp-v1.5-2B/3B/4Bを使ってみたいと思います。
imp-v1-3bの使い方
今回は、公式のHuggingFaceのモデルカードにあるコードを実行していきます。
まずは、以下のコードを実行して、ライブラリをインストールしましょう。
!pip install -U transformers
!pip install -q pillow accelerate einops次に、モデルやトークナイザーのロード。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from PIL import Image
torch.set_default_device("cuda")
# モデルとトークナイザー
model = AutoModelForCausalLM.from_pretrained(
"MILVLG/imp-v1-3b",
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained(
"MILVLG/imp-v1-3b",
trust_remote_code=True
)次に、カレントディレクトリに、入力したい画像を置いてください。
そして、以下のコードを実行して、プロンプトと入力画像の準備をしましょう。
# プロンプトと画像
text = "A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: <image>\nDescribe the person in the image. ASSISTANT:"
image = Image.open("image.jpg")そして、以下のコードを実行して、推論を実行。
# 推論
input_ids = tokenizer(text, return_tensors="pt").input_ids
image_tensor = model.image_preprocess(image)
output_ids = model.generate(
input_ids,
max_new_tokens=100,
images=image_tensor,
use_cache=True)[0]
print(tokenizer.decode(output_ids[input_ids.shape[1]:], skip_special_tokens=True).strip())これで、チャットの返信がimp-v1-3bから返ってくるはずです。
ちなみに、「Imp Chat」という公式のデモページでは、ブラウザ上で簡単にimp-v1-3bとのチャットが可能です。
imp-v1-3bを動かすのに必要なPCのスペック
■Pythonのバージョン
Python 3.8以上
■必要な容量
公式のドキュメントには、必要なメモリ容量等に関する情報は、記載されていませんでした。ただ、少なくとも10GBのストレージを、確保しておけば十分でしょう。また、最低でも10GBのVRAM、16GB以上のRAMを持つGPUも必要だと思われます。
なお、GPT-4Vに匹敵する性能を持つマルチモーダルモデルについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

imp-v1-3bを実際に使ってみた
先ほどの例の場合、
「A chat between a curious user and an artificial intelligence assistant.
The assistant gives helpful, detailed, and polite answers to the user's questions.
USER: \nDescribe the person in the image. ASSISTANT:」
(好奇心旺盛なユーザーと人工知能アシスタントとのチャット。アシスタントはユーザーの質問に親切、詳しく、丁寧に答えてくれる。
ユーザー:「画像に写っている人物を教えてください。」アシスタント:)というテキストプロンプトと、image.jpgファイルを入力しました。
この時、image.jpgを以下の画像にした場合の、imp-v1-3bのふるまいを見ていきましょう。

結果は以下の通りです。
The person in the image is a young man, possibly a boy, who is standing in front of a door.
He is holding a brown box in his hands, and he appears to be bending over to get into the room.
日本語訳:
画像の人物は若い男性(おそらく少年)で、ドアの前に立っている。手には茶色の箱を持っており、部屋の中に入ろうと腰をかがめているように見える。出力された文章を見ると、「若い男性」という人物の特徴や、その男性の行動を細かくとらえられていると思います。ただ、「部屋の中に入ろうと腰をかがめているように見える」という記述に関しては、少しズレている気がします。というのも、この男性の行動を正しく認識するなら「足でドアを開けている」というような記述が適切かもしれません。
ちなみに、「この男は何をしていますか?」と日本語で質問したところ、「この男は何を財いません。ねらについてです。」という誤った出力が返ってきました。。どうやら、日本語には対応していないようです。
アップデートされたImp-v1.5-2B/3B/4Bを試してみる
Hugging Faceに新たなモデルがアップされているので、それを参考にgoogle colaboratoryで動かしてみます。
今回はMILVLG/Imp-v1.5-3B-Phi2を使います。
まずは必要ライブラリをインストール。
!pip install transformers
!pip install -q pillow accelerate einopsサンプルコードを実行します。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from PIL import Image
torch.set_default_device("cuda")
#Create model
model = AutoModelForCausalLM.from_pretrained(
"MILVLG/Imp-v1.5-3B-Phi2/",
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained("MILVLG/Imp-v1.5-3B-Phi2", trust_remote_code=True)
#Set inputs
text = "A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: <image>\nWhat are the colors of the bus in the image? ASSISTANT:"
image = Image.open("images/bus.jpg")
input_ids = tokenizer(text, return_tensors='pt').input_ids
image_tensor = model.image_preprocess(image)
#Generate the answer
output_ids = model.generate(
input_ids,
max_new_tokens=100,
images=image_tensor,
use_cache=True)[0]
print(tokenizer.decode(output_ids[input_ids.shape[1]:], skip_special_tokens=True).strip())そうすると下記のような結果になります。
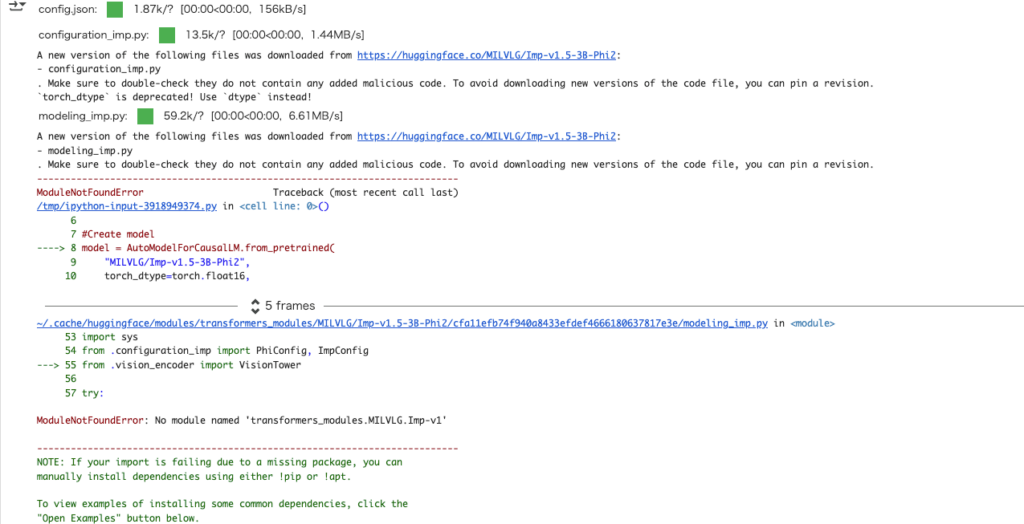
GitHubのIssueをみてみると、エラーについて記載がありましたが、解決はしていなさそうです。2024年から更新されていないので、もしかしたら2025年9月時点では動かせないのかもしれませんね。
imp-v1-3bの推しポイントである小規模ながら高性能なMLLMというのは本当なのか?
imp-v1-3bの画像処理能力を検証してみたいと思います。CAPTCHAの画像を用意して、テキストを読み取ってもらいます。

まずは必要ライブラリをインストールします。
!pip install transformers==4.37.2 accelerate torch torchvision pillow einops timm続いてコードを実行。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from PIL import Image
torch.set_default_device("cuda")
model = AutoModelForCausalLM.from_pretrained(
"MILVLG/imp-v1-3b",
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained("MILVLG/imp-v1-3b", trust_remote_code=True)
text = "A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: <image>\nWhat text can you see in this image? Please tell me what is written. ASSISTANT:"
image = Image.open("/content/sample.png")
input_ids = tokenizer(text, return_tensors='pt').input_ids
image_tensor = model.image_preprocess(image)
output_ids = model.generate(
input_ids,
max_new_tokens=100,
images=image_tensor,
use_cache=True)[0]
print(tokenizer.decode(output_ids[input_ids.shape[1]:], skip_special_tokens=True).strip())結果はこちら。
The text in the image reads "The picture contains 8 characters."うーん、確かに画像に何が書いてあるかを質問はしたのですが、CAPTCHA画像のテキストではなく、その下のテキストを正確に読み取ってくれました。
画像処理の性能としては高いですが、CAPTCHA画像のテキストを読み取ることはまだ難しいのかもしれません。もしくはCAPTCHA画像の種類によっては読み取ってくれるかもしれません。
なお、画像認識能力がとても高いGPT-4Vの画像認識能力を、さらに高める方法について詳しく知りたい方は、下記の記事を合わせてご確認ください。
まとめ
imp-v1-3bは、テキストと画像に関する小型マルチモーダルモデルです。Microsoftが開発したPhi-2に基づいて構築されており、学習データセットはLLaVA-v1.5のものが使われています。
Xでは、CAPTCHAを破ることはないだろうとの意見がありました。実際にやってみないとわからないですが、今のところはimp-v1-3bを悪用したボットなどは、生まれないのかもしれません。

最後に
いかがだったでしょうか?
自社プロダクトに画像認識AIやマルチモーダル技術を組み込みたい企業必見。軽量で高性能なモデルを活用し、開発コストを抑えながら生成AI導入を加速させる方法を具体的に紹介します。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

