
【PLaMo】GPT-4o超えの日本語レベルを持つ1000億パラメータLLMの性能を徹底比較

\生成AIを活用して業務プロセスを自動化/
PLaMoの概要
PLAMOは株式会社Preferred Elementsがリリースしたフルスクラッチで開発された大規模言語モデル。
PLaMoの特徴は次の3つです。
- 世界で最高レベルの日本語能力を持つ
- 純国産のフルスクラッチモデル
- APIで簡単に導入が可能
PLaMoはNEDO(国立研究開発法人新エネルギー・産業技術総合開発機構)が実施している「ポスト5G情報通信システム基盤強化研究開発事業・ポスト5G情報通信システムの開発」で、1000億パラメータのマルチモーダル基盤モデルPLaMo-100Bの開発を実施しています。
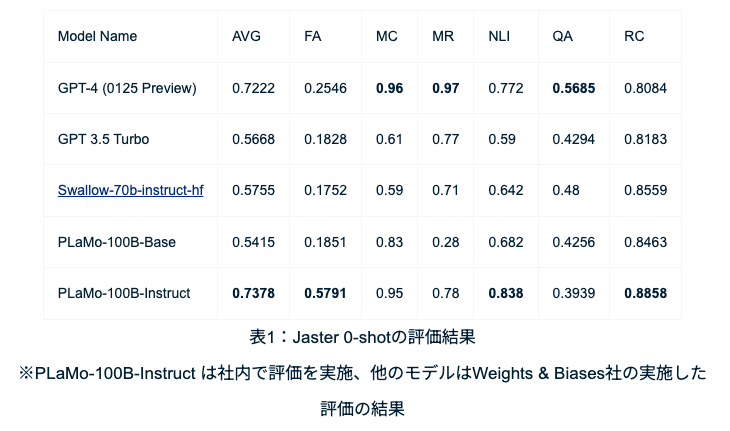
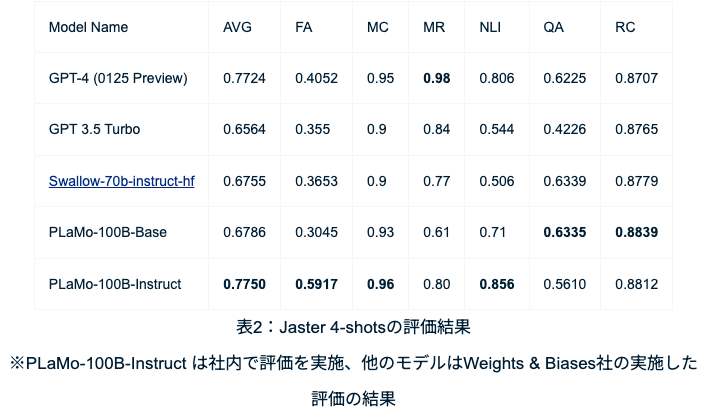
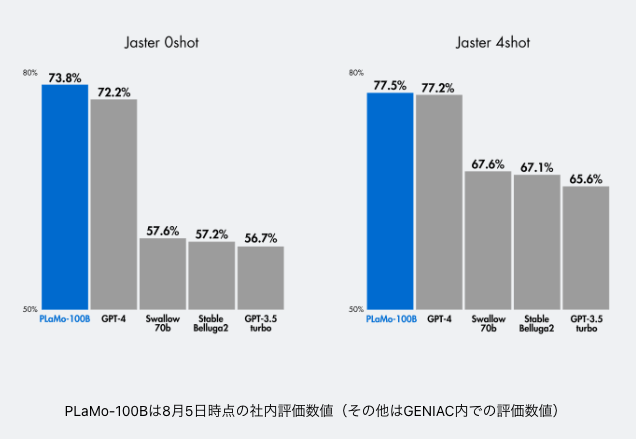
既存のAIモデルをベースにせず、事前学習では合計2兆トークンの日本語・英語のテキストデータを学習させ、フルスクラッチで開発。Jaster 0-shotおよび4-shotsにおいて、国内外の主要な大規模言語モデルを超える高い日本語性能を示しました。
世界で最高レベルの日本語能力を持つ
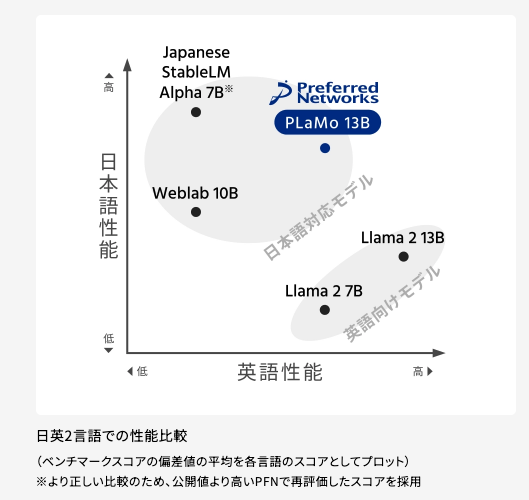
PLaMoは主要な日本語のベンチマークにおいてGPT-4を超える精度を記録。現在も日本語精度を向上させています。
また、日本語のみならず日英の翻訳性能にも優れています。
PLaMoのベンチマーク測定には、日本語LLMの性能を測るために標準的に使われるベンチマーク「Jaster」が使われており、このベンチマークには、意味的テキスト類似度、質問応答などのタスクが含まれており、日本語LLMの包括的な評価を提供することを目的としています。
純国産のフルスクラッチモデル
PLaMoは独自構築したアーキテクチャ・学習データで0からの事前学習・指示学習を通して開発された大規模言語モデル。他社モデルをベースにしていないため、社外のライセンス縛りや開発上での不明瞭な点の存在しない基盤モデルです。
多くのAIモデルはすでにある他のAIモデルをベースに、その上に新しい機能を追加したり特定の目的に合わせてカスタマイズをします。しかし他のAIモデルをベースにすると、そのAIモデルを開発した会社のルールやライセンスを遵守する必要があります。
さらに、元のAIモデルがどのように作られたかが不明瞭になりやすく、開発者はその中身がどう動いているのかを完全に理解することが難しいです。
一方で、最初から最後まで自分たちで開発したPLaMoは中身がどう動いているのか明確であり、しかもルールやライセンスにも縛られません。
APIで簡単に導入が可能
PLaMoはAPI経由でクラウドを介して提供されます。そのため、インターネットに接続されていれば、他のシステムやアプリから簡単に利用可能です。さらに簡単なコードの書き換えのみで自分たちのシステムに取り入れることができるため、導入ハードルも高くありません。
また、クローズドなオンプレミス環境でも利用できるので、外部にデータを持ち出さず、自社システム内だけで安全にAIを利用ができます。
事前学習と事後学習
大規模言語モデルの開発では、事前学習と事後学習が必要です。

事前学習は機械学習モデルを作成するための1工程であり、大規模なデータセットから大量の情報を学習してモデルのパラメーターを初期化します。これにより、モデルが言語の統計パターンや文章の文脈などの知識を得て、言語処理タスクに応用が可能です。
PLaMoの事前学習では、一般的な自然言語理解のデータセットを用いて、言語の理解力を向上させ、文脈に沿った適切な回答を生成できるようにしています。この工程があるからこそ、多様なトピックに対してもモデルが適切に対応できるようになるのです。
事前学習後のベンチマークは以下です。
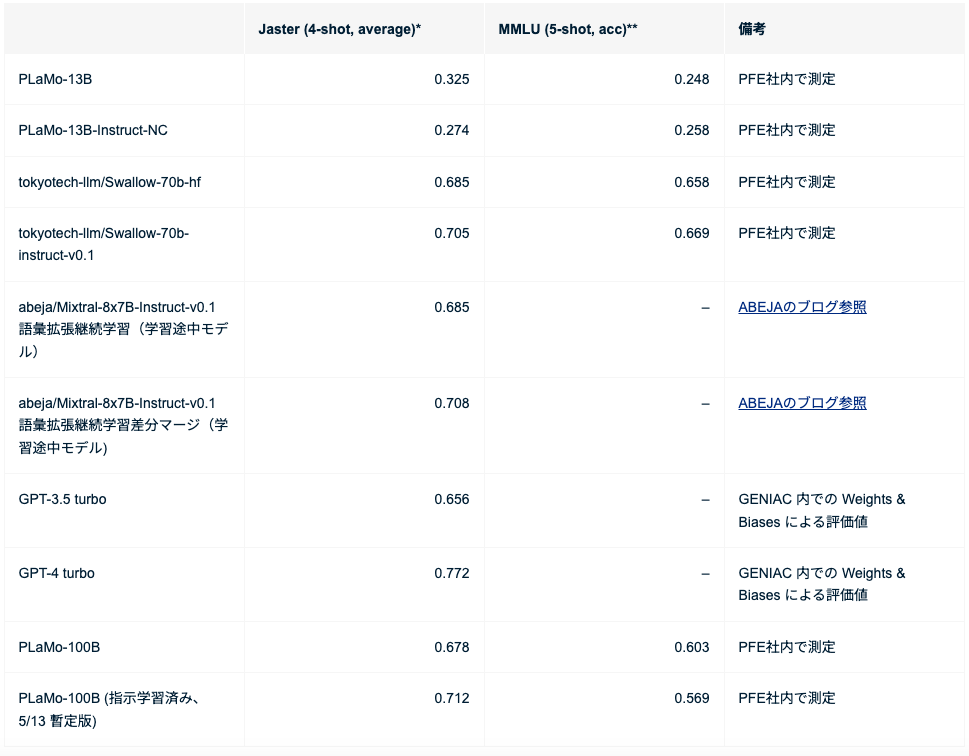
一方で、事後学習は特定のタスクやデータセットに対して、事前学習済みのモデルをカスタマイズする工程を指します。モデルに追加のデータや知識を学習させて、より特定のタスクに適応させることを目的とします。
PLaMoでも、事後学習は重要です。実際のアプリケーションにおいて、多様なユーザーのニーズに応えるために、その業界固有のデータセットを使ってユーザーの好みや応答スタイルの学習をさせたり、特定のタスクに特化したチューニングを行うことができます。
事後学習により、医療や法律など専門的な知識が必要な領域でも、適切な応答を生成できるようになります。
以上のように、事前学習と事後学習は、機械学習モデルの発展に重要な役割を果たしています。PLaMoもこれらの工程を経て、高い品質での言語理解や生成を可能にし、ユーザーに役立つアシスタントとしての能力を発揮します。
Supervised FinetuningとDirect Preference Optimization
Supervised Finetuningは教師ありの調整で、この学習手法では、PLaMoのモデルはまず人間のフィードバックを受けた大規模なテキストデータセットで事前学習されます。
その後、より特定のタスクやドメインに基づいて、小規模なデータセットで微調整。この際、モデルは特定の基準(通常は正解/不正解のラベル)に合わせて調整されます。
PLaMoの場合、教師あり調整はレコメンデーションシステムのようなタスクや、質問に正確な回答を生成するタスクに適用。
Direct Preference Optimizationはスタンフォード大学で発表されたモデルを直接最適化する方法です。
直接最適化は、強化学習の一種で、モデルの好みや好みに対する感度を扱うことができます。
この手法では、PLaMoのモデルは、ユーザーの好みやフィードバックを最大化することを目的とした報酬関数に従って調整されます。
モデルが様々な入力やアクションに触れることで、好みや敏感さを学習し、ユーザーの好みにより適した応答や推奨を生成できるようになります。
PLaMoの場合、直接最適化は、ユーザーの好みに合わせて言語出力をカスタマイズし、より魅力的で親しみやすい会話体験を生み出す目的で使用。
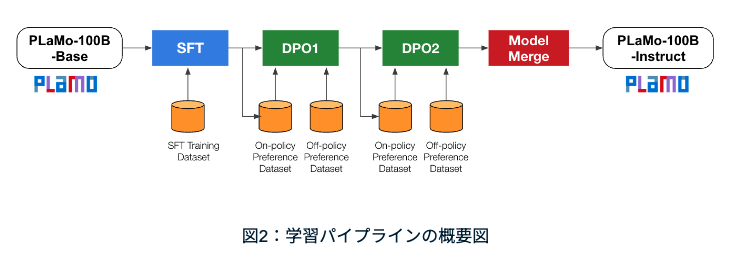
PLaMoの学習手法であるSupervised FinetuningとDirect Preference Optimizationは、特定の用途やユーザーの好みに合わせてモデルのパフォーマンスを向上させるために用いられます。
これらの手法によって、PLaMoは、ユーザーの好みを把握し、より適切で魅力的な応答を生成する能力を身につけることができます。
PLaMoのライセンス
ライセンスに関する細かい内容は発表されていませんが、トライアルAPIは商用利用が可能です。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | 不明 |
| 配布 | 不明 |
| 特許使用 | 不明 |
| 私的使用 | 不明 |
なお、日本語に強いSwallow on mistralについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

PLaMoの使い方
PLaMoを使うにはPLaMoβ版トライアルに申し込む必要があります。
トライアルはこちらから申し込み可能です。
トライアル申し込み後に1-2日くらいでメールが送られてくるので、送られてきたメールのURLにアクセスしてログインすればPLaMoを使うことができます。

PLaMoのTry Demo
Try Demoを使えばAPIキーを使用せずともPLaMoを体験することができます。
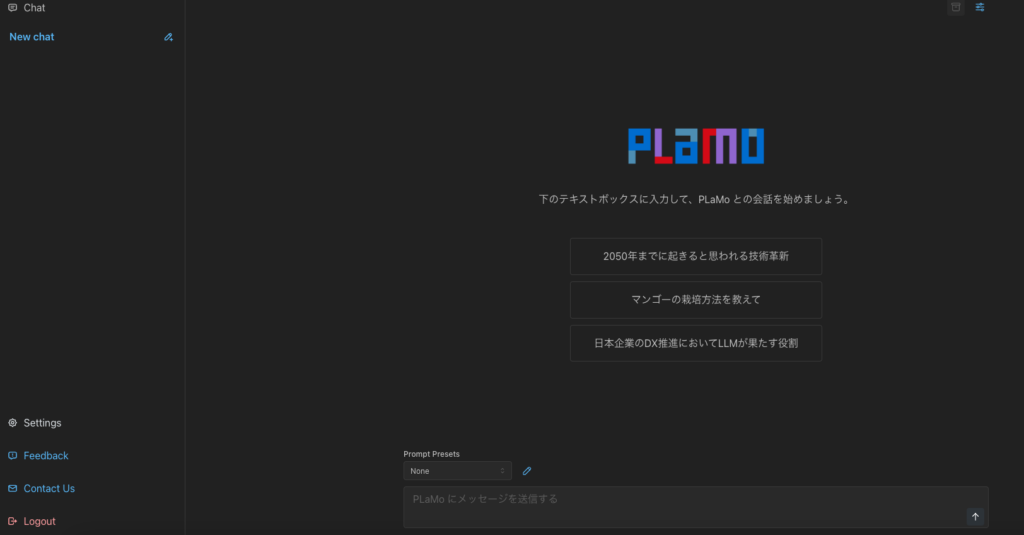
インターフェースはChat GPTに似ていますね。
チャットボックスにテキストを入力して送信すれば、それに対応した返事がきます。
PLaMoについて質問をしたら喜んで教えてくれました。

しかも、公式サイトには書かれていませんでしたが、PLaMoは感情知能と感情認識機能を持っているとのこと!
感情知能と感情認知機能があるということは、ユーザーの感情を汲み取り、その文脈を読み取ることができるということです。

生成速度はChat GPT-4oと同じくらいでClaude 3.5 sonnetに比べるとやや遅めです。
PLaMoとGPT-4oとの日本語性能を比較してみた
現状性能が高いと言われているGPT-4oとPLaMoの日本語性能を比較してみます。
使用するプロンプトはこちらです。
| タスク | プロンプト内容 |
|---|---|
| 日本語のビジネスメールの返信文章 | あなたは、優秀なビジネスマンです。以下の内容をもとに、メールの返信内容を出力してください。 #受信したメール内容 ○○様 お世話になっております。 お忙しいところ失礼いたします。 現在進行中の施策について情報共有したいことがあり、ミーティングをお願いできればと思っております。 ご都合の良い日時をお知らせいただけますと幸いです。 以下の時間帯で、ご都合が合う時間がございましたらご教示ください。 8/6(火): 10:00~18:00 8/7(水): 10:00~18:00 お忙しいところ恐縮ですが、何卒よろしくお願いいたします 合わせて、ミーティングの際に使用させていただく資料も共有させていただきます。 お手すきの際にご確認いただけると幸いです。 #返信に含める内容 – 8月7日(水)17:00~18:00の日程が参加可能 – 資料がまとまっていてキレイであることを褒める #条件 – 敬語を正確に使う – 文章最後に電子署名を入れる #出力 本文: |
| 長文の英語文章を一言一句日本語にする | あなたは優秀な翻訳家です。 以下の英語文章を、一語一句日本語に翻訳してください。 翻訳を省略したり要約した場合、ペナルティを課します。 [英語文章] In August 2024, Japan is experiencing frequent earthquakes and there is concern about the risk of a Nankai Trough earthquake. Opinions are divided among experts and there is still no unanimous view on whether a Nankai Trough earthquake will occur in the future. Therefore, it is necessary for each household to take its own disaster-prevention measures. |
| SNSの投稿文章(X) | # 指示内容 ## Prerequisites **タイトル** 共感を呼ぶツイートで新たなフォロワーを獲得するためのAIプロンプト **依頼者条件** SNSで共感を呼ぶ魅力的なコンテンツを発信したい個人や企業。心に響くメッセージや情報を提供し、フォロワーとのつながりを深める意欲があること。 **制作者条件** 感情に訴える表現力に秀でた制作者。洗練された文章を作成する能力を持ち、ターゲットオーディエンスの共感を引き出すクリエイティブなプロンプトを作成することができること。 **目的と目標** 共感を呼ぶツイートを通じて、読者の心に響くメッセージを伝えるプロンプトを生成すること。感動や共感を引き起こし、新たなフォロワーを獲得することを目指す。 ## End Prerequisites @投稿者:” 生成AIエンジニア “ @ターゲット:” 生成AIをビジネスに活かしたいと考えているビジネスマン “ @文体や語調:” ですます “ step1: ${投稿者}が${ターゲット}にクリエイティブな情報や提案を提供するためにテーマを5個出してください。 step2: step1で出したテーマにそれぞれ100点満点で点数をつけてください。 step3: setp2で一番点数の高かったテーマを選んでください。 step4: setp3で一番点数の高かったテーマから${ターゲット}にとって魅力的なトピックを5個出してください。 step5: step4で出したトピックにそれぞれ100点満点で点数をつけてください。 step6: setp5で一番点数の高かったトピックを選んでください。 ## 出力行動 setp6で選定したトッピクで、${ターゲット}向けに、${文体や語調}の文章で140文字で作成してください。 ### 禁則文字 – 絵文字 – 特殊文字 ### 注意事項 – 指示のみ従って文章を作成してください。 – 余計な説明や注意喚起は不要です。 |
それでは実際に検証していきたいと思います。
ちなみに翻訳してもらう英語はもともと以下の文章でした。
「2024年8月、日本では地震が頻発しており南海トラフ地震の危険性が心配されている。専門家の中でも意見は分かれており、今後南海トラフ地震が発生するかどうかについては、一致した見解はまだない。そのため、各家庭で各々ができる防災対応を講じる必要があると言えるだろう」
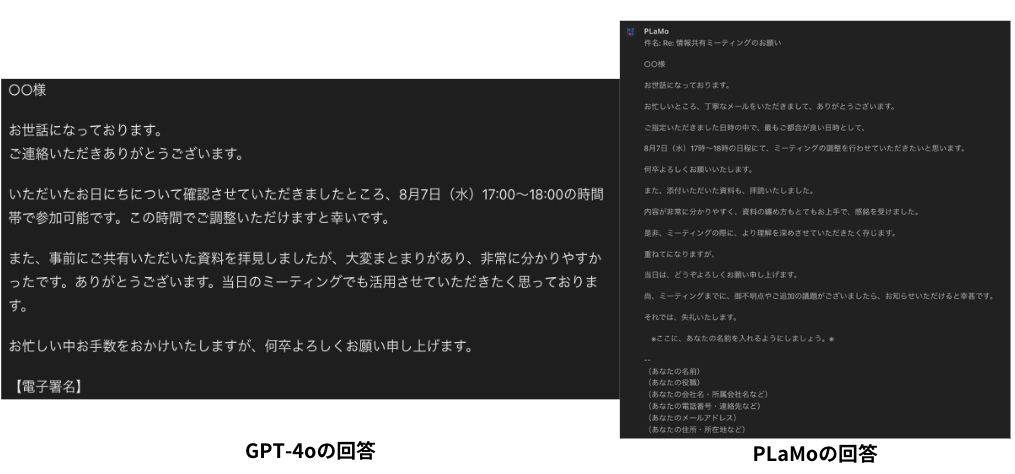

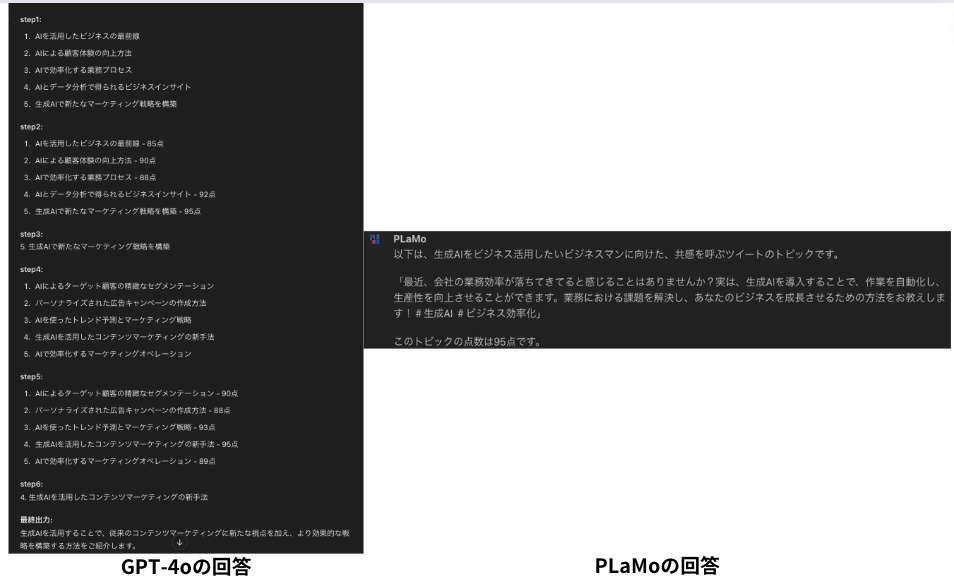
ビジネスメールの返信や英語から日本語の翻訳精度は高そうですが、SNSの投稿内容に関しては、プロンプトを忠実に守れていないですね。
パラメータをいじると結構変わるみたいなので、PLaMoのDemoを使える場合には、色々いじってみてください。
なお、安くて速い最新GPT-4o miniについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

