
複数エージェントを管理するMulti-Agent Orchestratorの使い方からクイックスタートまで
2024/11/21、AWS Labsより新たなAIエージェントをリリースされました!
Multi-Agent Orchestratorは、複数のAIエージェントを管理し、複雑な会話を処理するための柔軟で高性能なフレームワークです。事前に構築されたエージェントと分類器を提供し、AWS Lambdaなど様々な環境への展開を可能にするなど、幅広い用途に対応できます。
- AWS LabsがリリースしたAIエージェント管理フレームワーク
- AWS Lambdaやローカル環境で動作可能
- ストリーミング応答と非ストリーミング応答をサポートし、用途に応じて最適な方法で応答処理が可能
- 複数エージェントの動的管理ができる
本記事ではPythonでMulti-Agent Orchestratorを実装していきます。ローカル環境での実装が可能なAIエージェントなので、ぜひご自身のパソコンで実装しながら読み進めていってください!
\生成AIを活用して業務プロセスを自動化/
Multi-Agent Orchestratorの概要
Multi-Agent Orchestratorは、複数のAIエージェントを管理し、複雑な会話を処理するための柔軟なフレームワークです。
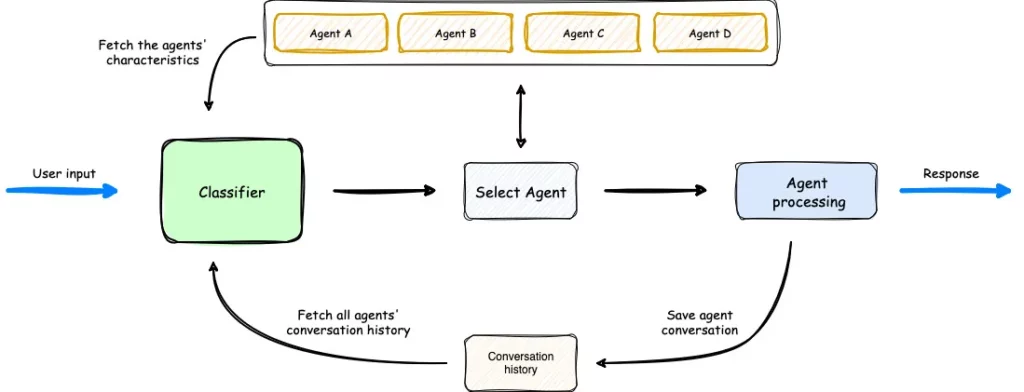
このフレームワークは、ユーザー入力に基づいて適切なエージェントにクエリを動的にルーティングするインテリジェントな意図分類を提供。 PythonとTypeScriptの両方の言語をサポートしており、さまざまなエージェントからのストリーミングおよび非ストリーミングの両方の応答に対応しています。
Multi-Agent Orchestratorの特徴
Multi-Agent Orchestratorの特徴は次の7つです。
- インテリジェントな意図分類
- デュアル言語サポート
- 柔軟なエージェント応答
- コンテキスト管理
- 拡張可能なアーキテクチャ
- ユニバーサルデプロイメント
- 事前に構築されたエージェントと分類子
一つずつ解説していきます。
インテリジェントな意図分類
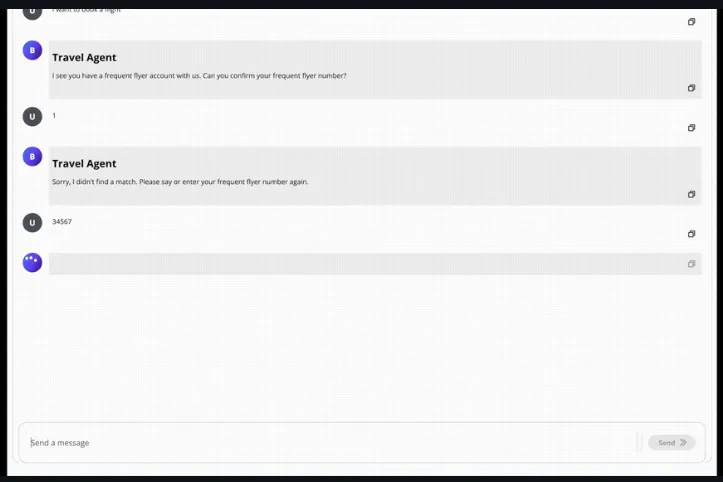
Multi-Agent Orchestratorは、ユーザー入力の内容と会話のコンテキストを分析し、最適なエージェントにクエリを動的にルーティングします。これにより、異なる分野やタスクに特化した複数のエージェントが効率的に活用され、ユーザー体験を向上させます。例えば、天気、旅行予約、健康相談など、用途に応じたエージェントが自動的に選ばれます。
デュアル言語サポート
Multi-Agent Orchestratorは、PythonとTypeScriptの両方で実装されており、開発者は自身の好みに応じてどちらの言語でも使用可能。また、PythonとTypeScriptの実装例がいくつか提供されており、初心者から経験者まで、幅広い層がすぐに開発に着手できます。
柔軟なエージェント応答
Multi-Agent Orchestratorは、エージェントからのストリーミング応答と非ストリーミング応答の両方をサポートします。この機能により、リアルタイムの対話が必要なシナリオやバッチ処理が適したケースのいずれにも対応可能です。例えば、チャットベースのインターフェースではストリーミング応答が有効で、バックエンド処理では非ストリーミング応答が利用されます。
コンテキスト管理
このフレームワークは、エージェント間で会話コンテキストを共有し、複雑なマルチターン会話を一貫性を持って処理します。過去の会話履歴やユーザーの意図を考慮して、適切な応答を生成することで、自然でスムーズなインタラクションを実現します。特に、エージェント間でのコンテキスト引き継ぎが求められるシナリオでその力を発揮します。
拡張可能なアーキテクチャ
特定のニーズに応じて、容易に新しいエージェントを統合したり、既存のエージェントをカスタマイズすることができます。この設計により、フレームワークは用途の広いソリューションとなり、簡単なチャットボットから複雑なマルチエージェントシステムまで幅広く対応可能です。
ユニバーサルデプロイメント
Multi-Agent Orchestratorは、AWS Lambdaやローカル環境、または他のクラウドプラットフォームなど、任意の環境で実行できます。この柔軟性により、開発者は選択したデプロイメント環境に応じてフレームワークを簡単に適応させることが可能です。
事前に構築されたエージェントと分類子
Multi-Agent Orchestratorには、事前に構築されたさまざまなエージェントと分類子が用意されており、すぐに使用できます。例えば、Amazon BedrockやLex Botなどのサービスと連携したエージェントが利用可能であり、これにより初期開発時間を大幅に短縮できます。また、カスタムエージェントを構築するためのガイドラインも提供されています。



マルチエージェント構成のおすすめツールを比較したい方は、以下の記事もご覧ください。

LangGraphとの違い
Multi-Agent Orchestratorは、複数のAIエージェントを動的に管理し、異なるタスクを効果的に処理することを目的としています。特に、会話型AIやマルチドメイン対応システムに重点を置き、エージェント間のコンテキスト共有とリアルタイムルーティングが強みです。
その一方で、LangGraphは、LLMを使用したタスクのワークフローをグラフとして構築・管理するためのフレームワークでもあり、主にNLPタスクの状態遷移や条件付き分岐など、プロセスの可視化やデバッグに優れています。
つまり、Multi-Agent Orchestratorは複数エージェントの統合と応答の最適化が必要な場面で有用で、LangGraphは複雑な状態管理やカスタムワークフローの構築を視覚的かつ効率的に行う場合に適しています。
Multi-Agent Orchestratorのライセンス
Multi-Agent OrchestratorのライセンスはApacheライセンス2.0です。
Apache 2.0ライセンスは特許ライセンスを含んでいるため、商用利用を含む幅広い使用が可能。再配布や改変時に、元のライセンス条項と表示が求められます。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
なお、Microsoftの新しいPythonライブラリであるTinyTroupeについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Multi-Agent Orchestratorの使い方
Multi-Agent OrchestratorのGitHubを確認すると、PythonとTypeScriptで使用することができます。デモも用意されていますが、その多くはTypeScriptで提供されており、Pythonで提供されているデモは一つだけでした。
本記事では、Pythonでの実装方法についてお伝えをしていきます。
Multi-Agent OrchestratorはLLMモデルをダウンロードする必要がないため、自身のパソコンにPythonを実行できる環境があれば実装が可能です。また、AWSを使うため、AWSのアクセスキーとシークレットキー、リージョン情報を取得しておきます。
まずは必要になるライブラリをインストールします。
pip install multi-agent-orchestratorその後、エージェントの設定です。Multi-Agent Orchestratorの使用では、最初にエージェントを設定します。例えば、Bedrock LLM AgentやAmazon Lex Bot Agentなどです。
# エージェントの設定
tech_agent = BedrockLLMAgent(BedrockLLMAgentOptions(
name="Tech Agent",
streaming=True,
description="Specializes in technology areas including software development, hardware, AI, \
cybersecurity, blockchain, cloud computing, emerging tech innovations.",
model_id="anthropic.claude-3-sonnet-20240229-v1:0",
callbacks=BedrockLLMAgentCallbacks()
))
orchestrator.add_agent(tech_agent)ここで自分の好きなエージェントを作ることができます。
上記はテック技術者にしていますが、データアナリストのような役割をしてほしいときは、以下のように設定します。
data_analysis_agent = BedrockLLMAgent(BedrockLLMAgentOptions(
name="Data Analyst",
streaming=True,
description="Expert in data analysis, statistics, and visualization. Can help with interpreting data, \
creating visualizations, and providing analytical insights.",
model_id="anthropic.claude-3-sonnet-20240229-v1:0",
callbacks=BedrockLLMAgentCallbacks(),
temperature=0.3
))続いて、オーケストレーターの設定も行います。
オーケストレーターは、複数のAIエージェントを管理・制御するための中心となるコンポーネント。オーケストレーターを適切に設定することで、会話において適切なエージェントが選択され、応答の質向上やシステム動作の透明性確保、メモリ使用量の最適化などを行うことができます。
# オーケストレーターの設定
orchestrator = MultiAgentOrchestrator(options=OrchestratorConfig(
LOG_AGENT_CHAT=True,
LOG_CLASSIFIER_CHAT=True,
LOG_CLASSIFIER_RAW_OUTPUT=True,
LOG_CLASSIFIER_OUTPUT=True,
LOG_EXECUTION_TIMES=True,
MAX_RETRIES=3,
USE_DEFAULT_AGENT_IF_NONE_IDENTIFIED=True,
MAX_MESSAGE_PAIRS_PER_AGENT=10
))残りはAWSの認証等を行います。これまでのコードと残りのコードを統合したものが以下です。
import uuid
import asyncio
import os
from typing import Optional, List, Dict, Any
import json
import sys
from multi_agent_orchestrator.orchestrator import MultiAgentOrchestrator, OrchestratorConfig
from multi_agent_orchestrator.agents import (BedrockLLMAgent,
BedrockLLMAgentOptions,
AgentResponse,
AgentCallbacks)
from multi_agent_orchestrator.types import ConversationMessage, ParticipantRole
import time
# AWS認証情報の直接設定(ここに自分の認証情報を入力)
os.environ['AWS_ACCESS_KEY_ID'] = '' # ここにアクセスキーを入力
os.environ['AWS_SECRET_ACCESS_KEY'] = '' # ここにシークレットキーを入力
os.environ['AWS_DEFAULT_REGION'] = 'us-east-1' # 使用するリージョン
# レート制限用の変数
RETRY_DELAYS = [1, 2, 4, 8] # 指数バックオフの待機時間(秒)
last_request_time = 0
MIN_REQUEST_INTERVAL = 1.0 # 最小リクエスト間隔(秒)
class BedrockLLMAgentCallbacks(AgentCallbacks):
def on_llm_new_token(self, token: str) -> None:
print(token, end='', flush=True)
# オーケストレーターの設定
orchestrator = MultiAgentOrchestrator(options=OrchestratorConfig(
LOG_AGENT_CHAT=True,
LOG_CLASSIFIER_CHAT=True,
LOG_CLASSIFIER_RAW_OUTPUT=True,
LOG_CLASSIFIER_OUTPUT=True,
LOG_EXECUTION_TIMES=True,
MAX_RETRIES=3,
USE_DEFAULT_AGENT_IF_NONE_IDENTIFIED=True,
MAX_MESSAGE_PAIRS_PER_AGENT=10
))
# エージェントの設定
tech_agent = BedrockLLMAgent(BedrockLLMAgentOptions(
name="Tech Agent",
streaming=True,
description="Specializes in technology areas including software development, hardware, AI, \
cybersecurity, blockchain, cloud computing, emerging tech innovations.",
model_id="anthropic.claude-3-sonnet-20240229-v1:0",
callbacks=BedrockLLMAgentCallbacks()
))
orchestrator.add_agent(tech_agent)
async def handle_request(_orchestrator: MultiAgentOrchestrator, _user_input: str, _user_id: str, _session_id: str):
global last_request_time
# リクエスト間隔の制御
current_time = time.time()
time_since_last_request = current_time - last_request_time
if time_since_last_request < MIN_REQUEST_INTERVAL:
await asyncio.sleep(MIN_REQUEST_INTERVAL - time_since_last_request)
for retry_count, delay in enumerate(RETRY_DELAYS):
try:
response: AgentResponse = await _orchestrator.route_request(_user_input, _user_id, _session_id)
print("\n選択されたエージェント:", response.metadata.agent_name)
if response.streaming:
pass # ストリーミング応答はコールバックで処理済み
else:
print("応答:", response.output)
last_request_time = time.time()
break
except Exception as e:
if "ThrottlingException" in str(e):
if retry_count < len(RETRY_DELAYS) - 1:
print(f"\nレート制限に達しました。{delay}秒待機します... (リトライ {retry_count + 1}/{len(RETRY_DELAYS)})")
await asyncio.sleep(delay)
continue
else:
print("\nリトライ回数の上限に達しました。しばらく時間をおいて再度お試しください。")
else:
print(f"\nエラーが発生しました: {str(e)}")
print("エラーの詳細:", type(e).__name__)
break
async def main():
USER_ID = str(uuid.uuid4()) # ユニークなユーザーID
SESSION_ID = str(uuid.uuid4()) # ユニークなセッションID
print("\nMulti-Agentシステムへようこそ。'quit'と入力すると終了します。")
print("エージェントの準備が完了しました。質問を入力してください。")
while True:
try:
user_input = input("\nあなた: ").strip()
if user_input.lower() == 'quit':
print("プログラムを終了します。さようなら!")
break
await handle_request(orchestrator, user_input, USER_ID, SESSION_ID)
except KeyboardInterrupt:
print("\nプログラムを終了します。")
break
except Exception as e:
print(f"エラーが発生しました: {str(e)}")
if __name__ == "__main__":
asyncio.run(main())AWSの制限に応じて適切に設定を行い、エラーが発生する場合は再試行の間隔を調整してください。
私が実装した時には、「An error occurred (ThrottlingException) when calling the Converse operation (reached max retries: 4): Too many requests, please wait before trying again.」というエラーが出てしまい、レート・リクエスト間隔の調整を行わないと実行不可でした。
ストリーミング応答と非ストリーミング応答の処理
Multi-Agent Orchestratorはストリーミングと非ストリーミング応答をサポート。
ストリーミング応答の場合はデータを逐次受信し、非ストリーミング応答の場合はすべての結果が一度に返されます。適切な処理方法を選ぶことで、ユーザーエクスペリエンスを最適化できます。
複数エージェントを組み合わせたシステムを開発したい方は、以下の記事もご覧ください。

Multi-Agent OrchestratorのExamples & Quick Startを実行してみた
GitHubのexamplesの中の多くはTypeScriptのコードになっており、Pythonのデモは少ないです。
python-demoの中にはmain.pyとtoolsの中にweather_tool.pyが入っていて、こちらを使うことでmain.pyで天気予報を聞くことができます。
まずはローカル環境でリポジトリをクローンします。
git clone https://github.com/awslabs/multi-agent-orchestrator.git
cd multi-agent-orchestratorpip install -r requirements.txtひとまずこれでデモのフォルダが用意できました。python-demoがあるディレクトリに移動して、main.pyを実行します。
Metadata:
Selected Agent: Weather Agent
東京の現在の天気は晴れで、気温は8.4°C、風速は5.0km/hです。晴れ渡った空が広がっています。 🌞東京の天気を返してくれました。ちゃんと本記事執筆中の気温だったので驚きました。
なお、Gemini×Google検索で最新情報にアクセス可能なAPIについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

まとめ
本記事では、Multi-Agent Orchestratorについて解説し、ローカル環境での使い方について紹介しました。
これまで、複数のエージェントを使うとなった場合、LangGraphが主流の選択肢となっていましたが、Multi-Agent Orchestratorの登場でLangGraphと選べるようになりました。
自分の実現したいことに応じて使い分けるのがいいですね。ぜひ本記事を参考にMulti-Agent Orchestratorを活用してみてください!
最後に
いかがだったでしょうか?
AIエージェントを活用し、貴社の業務効率化や顧客体験向上をAIで実現する具体的なアプローチをご提案します。導入事例やカスタム開発の可能性をぜひご確認ください。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

