
Appleの次世代オンデバイスAI!FastVLM-0.5Bの概要・性能・使い方を徹底解説

- Apple発の画期的な大規模視覚言語モデル
- パラメータ数約5億と小型でありながら、高解像度画像の処理をリアルタイムで行う圧倒的な速度性能を実現
- 研究目的に限定してモデルを使用・改変・再配布可能
2025年8月30日、Appleから画期的な視覚言語AIモデル「FastVLM-0.5B」がリリースされました!
FastVLMは、画像を入力するとその内容を人間のように理解し、瞬時にテキストで説明してくれる視覚言語モデルです。
その中でも今回リリースされた「FastVLM-0.5B」は、パラメータ数約5億という小型モデルでありながら、高解像度画像の処理をほぼリアルタイムで行う圧倒的な速度性能を実現しています。
さらに、モデルサイズも従来比で3分の1以下と非常にコンパクトで、MacやiPhoneといったデバイス上で直接動作可能な点も大きな注目ポイントです。
本記事では、FastVLM-0.5Bの概要や性能、使い方まで徹底解説します。
ぜひ最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
FastVLM-0.5Bの概要
FastVLM-0.5Bは、視覚(ビジョン)とテキスト(言語)の両方を扱うことができるVision Language Model(VLM)の一種です。例えば、写真や絵を入力すると、その内容を解析して「自然な文章」で説明したり、ユーザーからの質問に答えたりすることができます。
基本的な仕組みとして、視覚情報を処理するビジョンエンコーダと、テキストを生成する大規模言語モデルを組み合わせており、画像を圧縮したトークンに変換してからテキスト生成を行います。
FastVLMが従来のVLMと決定的に異なるのは、そのビジョンエンコーダ部分の革新性です。Appleの研究チームは高解像度画像を効率よく処理するために、FastViT-HDという新方式のハイブリッドエンコーダを開発し、画像から生成されるトークン数を大幅に削減することに成功しました。
これによって、画像サイズをそのまま大きくしても処理が極端に遅くならないよう最適化されており、不要なトークンを削減するなどの工夫により、複雑な手順なしで高速かつ高精度な画像理解を実現しています。
また、ファミリーとしてはFastVLM-0.5Bの他に、より高性能な1.5B版や7B版も公開されており、用途に応じて選択することもできます。


FastVLM-0.5Bの性能
FastVLM-0.5Bの性能を詳しく見てみましょう。最大の特徴はなんといっても応答の速さです。
ユーザーが画像を見せてからAIが最初の単語を発するまでの待ち時間(TTFT:Time-to-First-Token)が飛躍的に短縮されていて、従来モデルでは数秒かかるような場面でも、FastVLM-0.5Bなら瞬時に回答を開始します。具体的には、同程度の規模の既存モデル「LLaVA-OneVision-0.5B」と比較してTTFTが最大85倍高速だと報告されています。
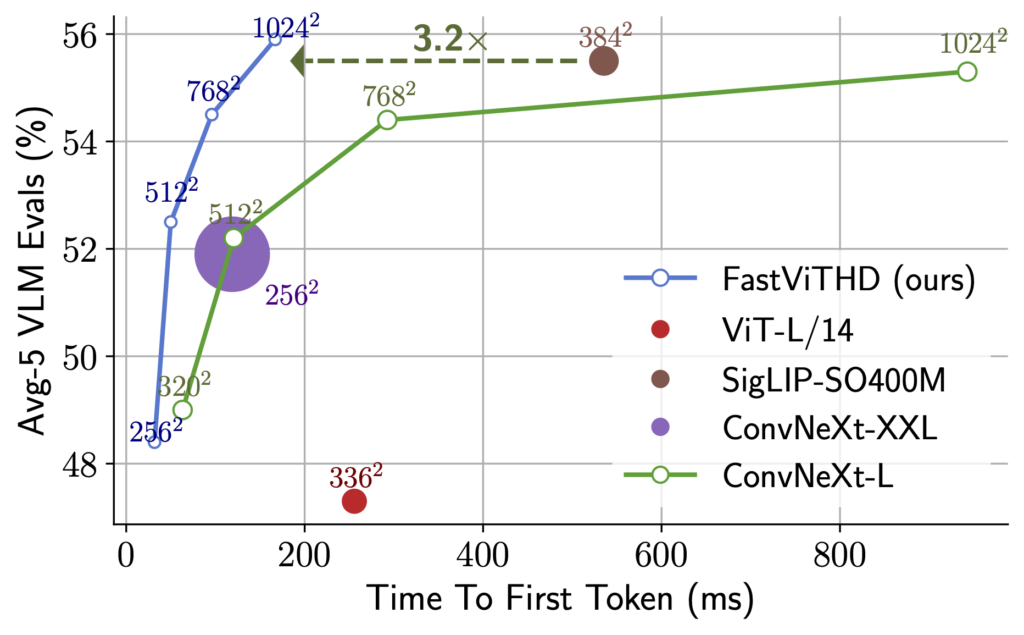
わずか5億パラメータの小型モデルでありながら、これだけ早いレスポンスが得られるのはすごいですね。
また、モデルサイズも3.4倍小型化されており、視覚エンコーダ部分が大幅に軽量であるためメモリ消費も抑えられています。この軽さと速さは、バッテリー駆動のモバイル機器でも動作させやすくする上で極めて重要です。
では精度の面ではどうでしょうか。
FastVLMは高速化を図りつつも、画像理解の精度を既存モデルと同等レベルに維持するよう設計されています。実際に公開されている評価結果によると、例えば、画像質問応答ベンチマークのVQAv2でFastVLM-0.5Bは76.3%の正解率を達成していて、大規模なモデルに迫る結果となっています。
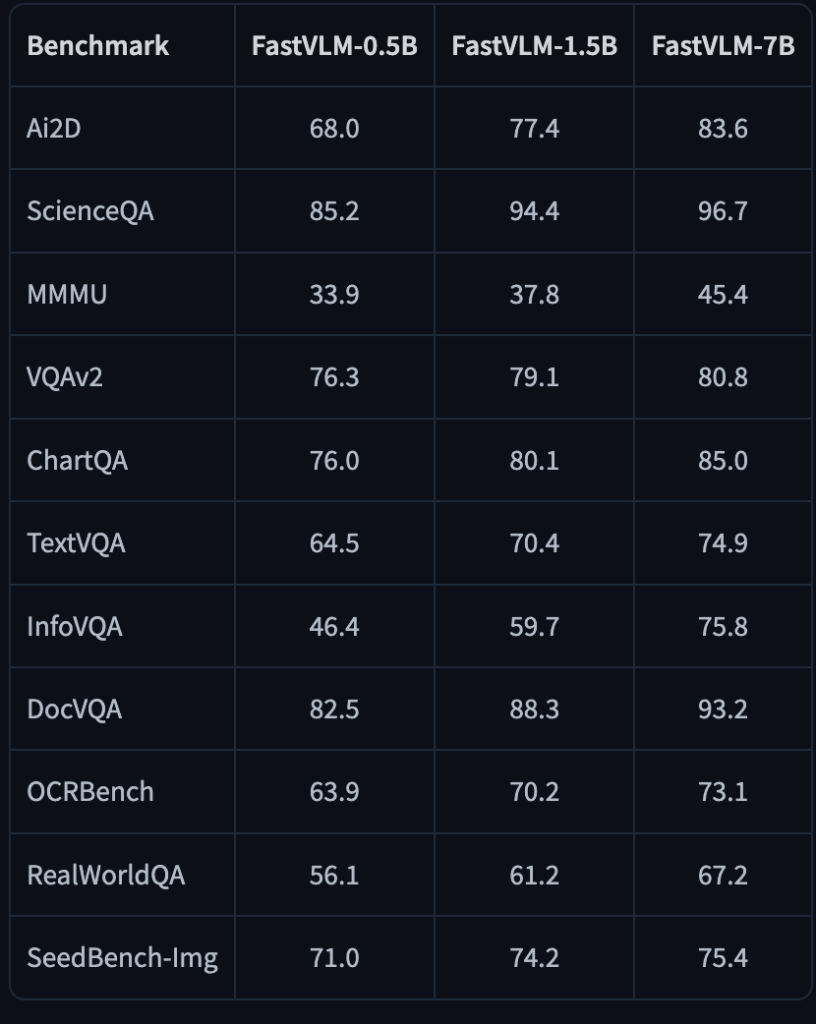
また科学問題データセットのScienceQAでは85.2%、文書中の質問応答であるDocVQAでも82.5%と、高い水準の性能を発揮しています。これは同程度の小型モデルでは難しかったレベル感で、FastVLMのアルゴリズム工夫による効果が感じられます。
FastVLM-0.5Bのライセンス
FastVLM-0.5Bのライセンスは、Apple独自の「Apple Machine Learning Research License (AMLR)」となっています。
これは、オープンソースコミュニティで一般的なMITやApacheライセンスとは異なり、研究目的に限定してモデルを使用・改変・再配布できるという条件になっています。簡単に言えば、「非商用の研究・学術目的」であれば自由に使えますが、商用利用は認められていません。以下に主な利用条件を表にまとめます。
| 利用用途 | 可否 | 備考 |
|---|---|---|
| 商用利用 | ❌️ | 営利目的での利用NG |
| 改変 | ⭕️ | 研究目的に限定 |
| 配布 | ⭕️ | 同梱のライセンス契約書とクレジット表記が必要 |
| 特許使用 | ❌️ | |
| 私的使用 | ⭕️ | 研究・学習目的の個人利用はOK |
ご覧のとおり、FastVLM-0.5Bは、研究目的であれば無料で自由に使える一方で、商用利用や製品への組み込みは明確に禁止されています。
利用する際は、公式から発表されているライセンス情報をしっかり確認するようにしましょう。
FastVLM-0.5Bの料金プラン
FastVLM-0.5Bは、モデル自体がオープン(研究目的限定で公開)であるため、使用することに料金は発生しません。クラウド経由で従量課金されるAPIサービスとは異なり、自分の手元でモデルを動かす場合は基本的に無料で利用できます。
| 利用方法 | 料金 |
|---|---|
| HuggingFaceデモの利用 | 無料 |
| ローカル環境での実行 | 無料 |
| クラウドAPIサービス | なし |


FastVLM-0.5Bの使い方
FastVLM-0.5Bを実際に利用する方法として、大きく分けて「①ブラウザ上のデモを使う方法」と、「②ローカル環境でモデルを動かす方法」の2つがあります。それぞれ順を追って説明します。
①ブラウザ上のデモを使う方法
一番手軽なのは、Hugging Faceサイト上に公開されているFastVLMのWebデモを利用する方法です。特別なインストール作業は不要で、対応ブラウザさえあればすぐに試せます。以下の手順で進めてみましょう。
まず、Appleシリコン搭載MacなどのWebGPUが使える環境で、最新のブラウザを開きます。次にHugging Face上のFastVLM-0.5Bデモページにアクセスしてください。
ページを開くとカメラへのアクセス許可を求められるので、自分のカメラ映像をモデルに読み込ませる場合は許可します。するとブラウザ内でモデルの読み込みが始まります。モデルデータは数百MB規模であるため、環境によっては読み込みに数分ほど時間がかかることもあります。
ロード完了後、すぐにWebカメラの映像に対する説明文の生成が始まります。画面上には説明文がリアルタイムに表示され、自分や周囲の状況をモデルが文章で描写してくれます。
②ローカル環境でモデルを動かす方法
開発者向けの使い方として、FastVLM-0.5Bのモデルをローカル環境で実行する方法もあります。
公式のGitHubリポジトリ(apple/ml-fastvlm)にコード一式が公開されており、自分のPC上で推論を行ったりファインチューニングを試すことが可能です。簡単に手順を解説します。
まずPython(推奨はPython 3.10)環境を用意し、GitHubからリポジトリをクローンします。その中でpip install -e .コマンドを実行すると必要な依存ライブラリを含めパッケージがインストールされます。
次にモデルの学習済みチェックポイント(重み)をダウンロードします。GitHubのget_models.shスクリプトを実行すると0.5Bから7Bまで全チェックポイントを一括取得できますが、0.5Bモデルのみ試す場合はHugging Faceのモデルページからhuggingface-cliコマンドで必要なファイルだけダウンロードすることも可能です。
huggingface-cli download apple/FastVLM-0.5B以下のようなダウンロードコンプリートログが出ればOKです。

あとは予測スクリプトを動かすだけです。公式リポジトリにはpredict.pyというサンプル推論スクリプトが含まれており、ターミナルから以下のように実行します。
python predict.py --model-path /path/to/チェックポイント格納ディレクトリ \
--image-file /path/to/入力画像.png \
--prompt "Describe the image."上記のようにオプションでモデルパス、画像ファイル、プロンプト文字列を指定して実行すると、与えた画像についての説明文を出力してくれます。
以上が基本的な使い方の流れです。
FastVLM-0.5Bの活用事例
最後にFastVLM-0.5Bの活用事例を紹介します。
公式サイトデモ
公式GitHubリポジトリでは、iOS端末上でのモデルパフォーマンス評価デモが公開されています。
左から指の本数、手書き文字、絵文字の特徴把握タスクが紹介されています。
被写体の把握とキャプション生成にリアルタイム性があって良いですね。手書き文字や、印刷文字の読み取りも滑らかです。
被写体把握(スマホ)
以下のポストでは、様々な被写体把握タスクでFastVLM-0.5Bのデモの様子が紹介されています。
洋服にプリントされたロゴ、スニーカーに印字されたロゴ、また一見分かりづらそうな物体検知もある程度できていることが分かりますね。投稿主も「驚くほど認識率が高い」と評価しています。
被写体把握②
以下のポストでは、ルービックキューブとGame Boy Colorを対象とした物体検知テストの様子が紹介されています。
ルービックキューブの面を変えることですぐにキャプションが修正されたり、ゲームボーイカラーの把握まで正確にできている様子です。一方で、ゲームタイトル(ポケモン金)は、実際に画面でタイトルテキストが表示されるまで理解していない様子でした。
レスポンスの速さ、物体検知能力の高さ、テキスト把握能力の高さはかなり評価できそうですね。
まとめ
FastVLM-0.5Bは、Appleが新たにリリースした次世代の大規模視覚言語モデルとして、非常にインパクトのあるものです。高解像度の画像を扱ってもレスポンスが速く、しかもモデルサイズが小さいため手元のデバイスで動かせるという、すばらしい設計になっています。
従来であれば、高性能な画像解析AIはクラウド上の巨大サーバで動かすしかありませんでしたが、FastVLM-0.5Bの登場で、自分のPCやスマホが自らカメラ映像を理解し説明するという世界が現実のものとなりつつあります。プライバシー保護や遅延の解消といったメリットも大きく、今後、アクセシビリティ支援やウェアラブルデバイスでの応用など多彩な分野で活躍が期待されます。
気になる方はぜひ一度試してみてください。

最後に
いかがだったでしょうか?
AI導入を検討中の企業向けに、業務効率化や新しい価値創出を支援できる情報を提供します。最新のFastVLM-0.5Bを活用し、効率的な業務改善や高度な分析が可能です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

