
TranslateGemmaとは?Google発の翻訳特化Gemmaモデルの性能・使い方を徹底解説

- Google発、新たなオープンソースの機械翻訳モデルファミリー
- 最新の大規模モデルGemma 3を基盤として構築された翻訳特化モデル
- 世界中の主要言語から希少言語まで合計55言語に対応
2026年1月16日、Google DeepMindとGoogle翻訳チームは、新たなオープンソースの機械翻訳モデルファミリー「TranslateGemma」を発表しました!
これは最新の大規模モデルGemma 3を基盤として構築された翻訳特化モデルで、規模の異なる複数モデルから構成されています。
TranslateGemmaは、パラメータ数が小さいにもかかわらず、高品質な翻訳を可能にしています。
対応言語は、世界中の主要言語から希少言語まで合計55言語にも及び、場所やデバイスを問わず人々のコミュニケーションを支援することを目指しているそうです。
そこで本記事では、このTranslateGemmaの特徴や性能、ライセンスや使い方を徹底的に解説します!
ぜひ最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
TranslateGemmaの概要

TranslateGemmaは、Googleが公開した最新のオープンソース翻訳モデル群で、4B(40億)、12B(120億)、27B(270億)という3つの規模のモデルから構成されています。
各モデルは、スマートフォン等のモバイル端末からノートPC、クラウド上のGPUサーバーまで、幅広い環境での実行を想定して設計されています。
最大モデルの27Bは、クラウド上の高性能GPU(例:H100)での動作を想定したフラッグシップモデルで、12Bは一般的なコンシューマー向けGPUや高性能ラップトップで動かせるバランスモデル、4Bはスマホやエッジデバイスでも扱える軽量モデルです。
対応している言語は55言語にも及び、英語・日本語・中国語・フランス語などの主要言語から、アイスランド語やスワヒリ語といった低リソース言語まで幅広くカバーしています。
TranslateGemma最大の特長は、その効率性と高性能を両立した点にあります。
Googleの発表によると、本モデルは、従来の大規模モデルGemma 3(27Bパラメータ)の翻訳性能を、なんと約半分のサイズである12Bモデルが上回りました。
つまり、モデルサイズを小さく抑えつつも品質を犠牲にせず、むしろ既存の巨大モデル以上の精度を実現しているのです。
この効率の高さは、Geminiから知識を蒸留し、TranslateGemmaに凝縮する特殊な学習プロセスによって達成されているようです。
なお、現時点でのGeminiシリーズ最高モデル「Gemini 3 Pro」について詳しく知りたい方は、以下の記事も参考にしてみてください。

TranslateGemmaの性能
TranslateGemmaの性能は、従来モデルを圧倒する結果となっています。

Googleの技術レポートによるベンチマークテスト(WMT24++)では、翻訳エラー率を示す指標MetricXにおいて以下のようなスコアが得られています。
| モデル | スコア |
|---|---|
| Gemma 3 27B(ベースラインモデル)のMetricX | 4.04 |
| TranslateGemma 12BモデルのMetricX | 3.60 |
| TranslateGemma 27BモデルのMetricX | 3.09 |
MetricXは値が低いほど誤訳が少なく、より高性能であることを意味します。
つまり、TranslateGemmaの12Bモデル(3.60)は、倍以上のサイズを持つGemma 3の27Bモデル(4.04)よりも良いスコアを記録していて、さらに、27B版では3.09とより一層高品質であることが分かります。
TranslateGemmaのもう1つの注目すべき点は、マルチモーダル能力を維持していることです。
Gemma 3は、テキストだけでなく画像なども理解可能なVLMでしたが、通常、こうしたモデルを特定タスクに特化調整すると、画像理解など汎用能力が損なわれる懸念があります。
それにもかかわらず、TranslateGemmaでは、画像内テキスト翻訳(Vistraベンチマーク)の精度も向上したと報告されています。
これは、テキスト翻訳の性能向上が、そのまま画像内文字の翻訳能力にも波及したことを意味していて、基盤モデルGemma 3が持つ潜在的なマルチモーダル能力の高さも証明しています。
なお、Gemma 3について詳しく知りたい方は、以下の記事も参考にしてみてください。

TranslateGemmaのライセンス
TranslateGemmaは、Google独自の「Gemma利用規約(Gemma Terms of Use)」に基づいて提供されています。
このライセンスは、従来のオープンソースライセンスとは若干異なる性質を持ちますが、基本的には商用利用やモデルの改変・再配布を許可しつつ、利用者に一定の条件遵守を求めるものです。
| 利用用途 | 可否 | 備考 |
|---|---|---|
| 商用利用 | ⭕️ | |
| 改変 | ⭕️ | |
| 配布 | ⭕️ | |
| 特許使用 | ⭕️ | 特許権に関する明示的記載なし。通常利用の範囲で許容 |
| 私的使用 | ⭕️ |


TranslateGemmaの料金
TranslateGemmaはオープンモデルとして公開されているため、モデルそのものを入手・使用すること自体に利用料は発生しません。
つまり、月額サブスクリプション費用や、API使用料といったライセンスコストは無料です。
利用時のコストは、主にモデルを動作させる環境(ハードウェアやクラウドサービス)に依存します。
TranslateGemmaの使い方
TranslateGemmaはオープンモデルなので、モデルを入手し実行環境を用意すれば使うことができます。
こちらでは、代表的な利用シナリオとして、Hugging FaceのTransformersライブラリを用いた実行方法を例に、「①テキスト翻訳」と「②画像内テキスト翻訳」の手順をそれぞれ紹介します。
なお、モデルのダウンロードには、Hugging Faceアカウントでの利用規約同意が必要ですが、それを済ませればコード数行で高度な翻訳AIを扱うことができます。
①テキスト翻訳
モデルとパイプラインの準備
まずPython環境でtransformersライブラリをインポートし、TranslateGemmaモデルを読み込みます。モデル名はHugging Face上で公開されているgoogle/translategemma-12b-it(12Bモデルの場合)などを指定します。例えば12BモデルをGPU上で使う場合、以下のように設定します(GPUがない場合はdevice="cpu"としてください)。
from transformers import pipeline
import torch
pipe = pipeline(
"image-text-to-text",
model="google/translategemma-12b-it",
device="cuda", # GPU利用(CPUなら "cpu")
dtype=torch.bfloat16 # bfloat16精度で高速化
)翻訳したいテキストの準備
次に、翻訳させたい文章を指定します。TranslateGemmaでは入力をメッセージ形式で与える必要があります。
具体的には、「ユーザー」役割のメッセージとして、翻訳元言語・翻訳先言語のコードと言語種別、それに翻訳するテキスト本体を含むJSONライクな構造を用います。例として、チェコ語⇒ドイツ語の翻訳をしてみましょう。
messages = [
{
"role": "user",
"content": [
{
"type": "text",
"source_lang_code": "cs",
"target_lang_code": "de-DE",
"text": "V nejhorším případě i k prasknutí čočky.",
}
],
}
]翻訳の実行
準備したmessagesをパイプラインに渡して推論を実行します。max_new_tokensで生成される最大トークン数を指定可能です(ここでは200に設定します)。
output = pipe(text=messages, max_new_tokens=200)
print(output[0]["generated_text"][-1]["content"])実行すると、outputにモデルの応答が返ってきます。outputはリスト形式で、要素0の中に"generated_text"(生成された対話メッセージ群)が含まれています。その最後のメッセージ([-1])の"content"が翻訳結果テキストです。
②画像内テキスト翻訳
TranslateGemmaは画像内のテキスト抽出と翻訳にも対応しています。基本的な流れはテキスト翻訳と似ていますが、"type"を"image"にし、画像のURLまたはバイナリを指定する点が異なります。
画像入力メッセージの用意
先ほどと同様にmessagesを構築しますが、コンテンツの"type"を"image"に設定します。また、画像を指定するには直接バイナリデータを与える方法もありますが、ここでは簡単に、インターネット上の画像URLを利用します。
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"source_lang_code": "cs",
"target_lang_code": "de-DE",
"url": "https://example.com/sample_sign_cs.jpg",
},
],
}
]上記ではチェコ語の看板画像を想定し、URLで画像へのリンクを指定しています。
画像翻訳の実行
テキスト翻訳時と同様にpipeを呼び出します。
output = pipe(text=messages, max_new_tokens=200)
print(output[0]["generated_text"][-1]["content"])モデルは画像内の文字列を読み取り、指定された言語へ翻訳した結果を返してくれます。
以上が基本的な使い方の手順です。
TranslateGemmaは、汎用のLLMとは異なり翻訳専用モードで動作するので、入力形式さえ整えれば、容易に高品質な翻訳結果を得ることができます。
追加のチューニングなしでも多言語・多領域に対応しますが、もし特定分野に最適化したい場合は、さらに独自データでファインチューニングすることも可能です。
TranslateGemmaを使ってみた
それでは実際に、TranslateGemma 4BモデルをGoogle Colab上で実装してみます。実行する際、Hugging Faceのご自身のアクセストークンが必要になりますので、こちらから取得しましょう。
入力プロンプトはこちら
This model can run on various devices and supports many languages.
結果はこちら

問題なく翻訳してくれました。
続いて、画像内テキスト翻訳も試してみましょう。入力画像は、ChatGPT Imagesで生成したこちらの画像とします。
結果はこちら
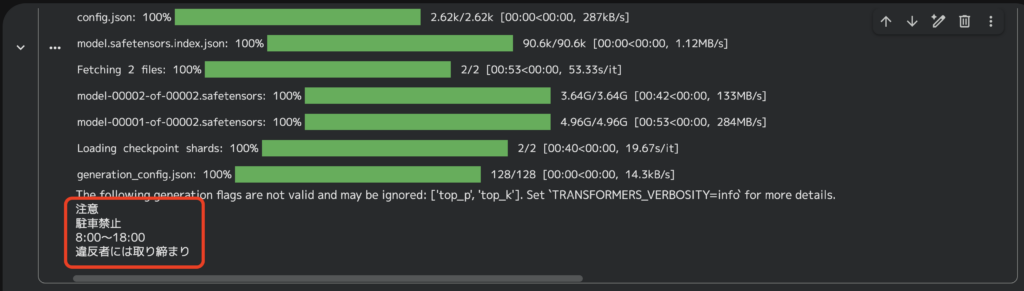
画像内テキスト翻訳も問題なさそうですね。「PM 6:00」の意味を理解して「18:00」としているのも評価できるポイントだと思います。
TranslateGemmaの活用可能性
最後にTranslateGemmaの活用イメージをご紹介します。
社内ドキュメント翻訳の内製化と情報漏えいリスクの低減
TranslateGemmaは自前の環境で動かすことができるので、機密情報を外部APIに送らずに翻訳フローを組むことができます。
設計書や議事録、契約書の下訳を社内で完結でき、監査対応などもしやすくなるかと思います。さらに、用語集や文体ルールを足して微調整することで、部署ごとの訳語ブレみたいな点も抑えることができます。
プロダクト組み込みによる多言語UXの高速改善
アプリやSaaSのUI文言、ヘルプ、通知文などをTranslateGemmaで一括で翻訳すれば、ローカライズの初速が上がるかと思います。
12Bモデルであれば、性能と運用コストのバランスが取りやすいと思いますので、ABテストで文面を改善しながら多言語展開を回すことができます。低リソース言語にも対応できる点もメリットになります。
画像内テキスト翻訳を活かした現場支援
TranslateGemmaは画像内テキスト翻訳に対応しているので、看板や資料写真、手書きメモなどを撮ってすぐに翻訳するフローを組むこともできると思います。
工場や建設、観光などの現場で、読めない状況を減らして、確認の手戻りを抑えることができます。
多言語対応の動画文字起こしや字幕生成に興味がある方は、以下の記事もご覧ください。
まとめ
TranslateGemmaは、小さくても強力な翻訳AIモデルファミリーとしてAI業界に新風を吹き込んでいます。
Gemma 3をベースに、高度にチューニングされたこのモデルは、55言語対応というカバー範囲の広さと、12Bモデルでも27Bモデルを上回るという効率性の高さで注目を集めています。
気になった方は、ぜひ一度試してみてください!

最後に
いかがだったでしょうか?
弊社では、AI導入を検討中の企業向けに、業務効率化や新しい価値創出を支援する情報提供・導入支援を行っています。最新のAIを活用し、効率的な業務改善や高度な分析が可能です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

