
【STEP3-VL-10B】わずか10Bで100Bモデルよりも高性能!高効率マルチモーダルAIの使い方を解説

- StepFun発の10Bパラメータで100B超えモデルを超えるマルチモーダルAI
- AIME 2025で94.43%を達成し、Gemini 2.5 Proを10%ほど上回る
- Apache 2.0ライセンスで商用利用可能、Hugging Faceで無料公開
2026年1月19日、ModelScopeの公式XでSTEP3-VL-10Bが発表されました。
注目すべきは、わずか10Bパラメータでありながら、10〜20倍大きなモデルに匹敵する性能です。
GLM-4.6V(106B)やQwen3-VL(235B)といった大規模モデル、さらにはGoogleのGemini 2.5 Proまでも一部ベンチマークで上回っています。
「大規模モデルは高性能だがコストが高い」「ローカル環境で動かせるマルチモーダルAIが欲しい」という課題を抱えている方にとって、STEP3-VL-10Bは有力な選択肢となるでしょう。この記事では、STEP3-VL-10Bの仕組みから使い方まで詳しく解説します。
\生成AIを活用して業務プロセスを自動化/
STEP3-VL-10Bの概要
STEP3-VL-10BはStepFunが開発した軽量オープンソースのマルチモーダルモデルです。
「VL」はVision-Language(視覚-言語)を意味し、画像とテキストをまとめて理解して処理できます。
StepFunは中国のAIスタートアップで、大規模言語モデルやマルチモーダルAIの研究開発を行っています。STEP3-VL-10Bは2026年1月14日にarXivで技術論文が公開され、同月19日にModelScopeで正式発表されました。
STEP3-VL-10Bの仕様は以下の通りです。
| 項目 | 内容 |
|---|---|
| パラメータ数 | 10B(100億) |
| Visual Encoder | PE-lang(1.8B) |
| デコーダー | Qwen3-8B |
| 学習トークン数 | 1.2T(1兆2000億) |
| 最大コンテキスト長 | 128K(PaCoRe使用時) |
| ライセンス | Apache 2.0 |
このモデルの最大の特徴は、わずか10Bパラメータで高性能を実現している点です。これまで高性能なマルチモーダルAIを使うには、100B以上の大規模モデルが必要でした。STEP3-VL-10Bは、それらと比べてはるかに小さいサイズなのです。
なお、GoogleのマルチモーダルLLMであるT5Gemma 2も、小さなスケールで効率を最大化しています。詳しく知りたい方はこちらをご覧ください。

STEP3-VL-10Bの仕組み
STEP3-VL-10BはPE-lang Visual EncoderとQwen3-8Bデコーダーを組み合わせたアーキテクチャを採用しています。コンパクトなサイズながら高い性能を実現できたのには、独自の学習戦略と推論手法があります。
アーキテクチャ構成
STEP3-VL-10Bは、画像を理解するVisual Encoder、情報を圧縮するProjector、テキストを生成するDecoderの3層構造で成り立っています。
画像は1.8BパラメータのPE-lang(Language-Optimized Perception Encoder)で処理されます。PE-langは言語モデルとの連携を前提に設計された視覚エンコーダーです。
次に、抽出された視覚特徴は、Projectorで16倍に空間ダウンサンプリングされます。この圧縮により、言語モデルが効率的に視覚情報を扱えるようになります。
最終的な応答生成は、AlibabaのQwen3-8Bが担当します。大量トークンのコンテキストに対応し、視覚情報とテキストを統合した出力を生成します。
なお、画像入力にはマルチクロップ戦略を採用しています。728×728ピクセルのグローバルビューに加え、複数の504×504ピクセルのローカルクロップを組み合わせることで、高解像度画像で認識可能です。
これらのアーキテクチャが組み合わさることで、わずか10Bでも高性能なパフォーマンスを実現しています。
学習パイプライン
高性能の秘密は、3段階に分かれた学習パイプラインにあります。
| 段階 | 手法 | 規模 |
|---|---|---|
| 事前学習 | シングルステージ・全パラメータ解凍 | 1.2Tトークン(900B + 300B) |
| SFT | 2段階(テキスト:マルチモーダル比率 9:1 → 1:1) | 約226Bトークン |
| 強化学習 | RLVR + RLHF + PaCoRe | 1,400回以上 |
事前学習では、Visual EncoderとDecoderを同時に最適化する「fully unfrozen」戦略を採用。これによって、視覚と言語の連携が確立されました。
次の工程であるSFTでは、学習データを段階的にマルチモーダル寄りにしています。前半はテキスト中心、後半は画像+テキストの割合を増やすことで、視覚と言語の結びつきを強化します。
最後の強化学習は、RLVR(検証可能な報酬)を600回、RLHF(人間フィードバック)を300回、PaCoReトレーニングを500回という構成で、計1,400回以上のイテレーションを重ねています。
PaCoRe(並列協調推論)
PaCoRe(Parallel Coordinated Reasoning)は、テスト時の計算リソースをスケールするための高度な推論手法です。
通常の推論(SeRe: Sequential Reasoning)は、Chain-of-Thoughtで順番に推論を進めますが、PaCoReは16の並列ロールアウトから証拠を集約して最終回答を合成します。
PaCoReを使用することで、AIME 2025では87.66%から94.43%へとスコアが約7ポイント向上しています。複雑な画像などの視覚推論タスクにおいて効果的です。
STEP3-VL-10Bの特徴

STEP3-VL-10Bには、他のマルチモーダルAIにはない特徴があります。
10Bパラメータという制約の中で、STEM推論・視覚認識・GUI理解など幅広い能力を高水準で実現しています。特に注目すべき3つのポイントを紹介します。
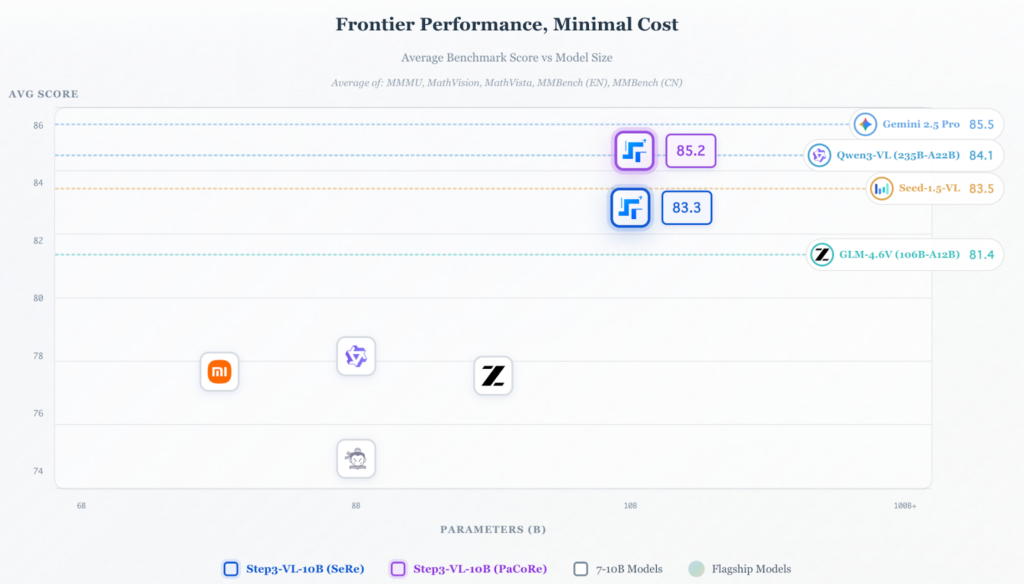
大規模モデルを凌駕する性能
最大の特徴は、10〜20倍大きなモデルと同等以上の性能を発揮する点です。
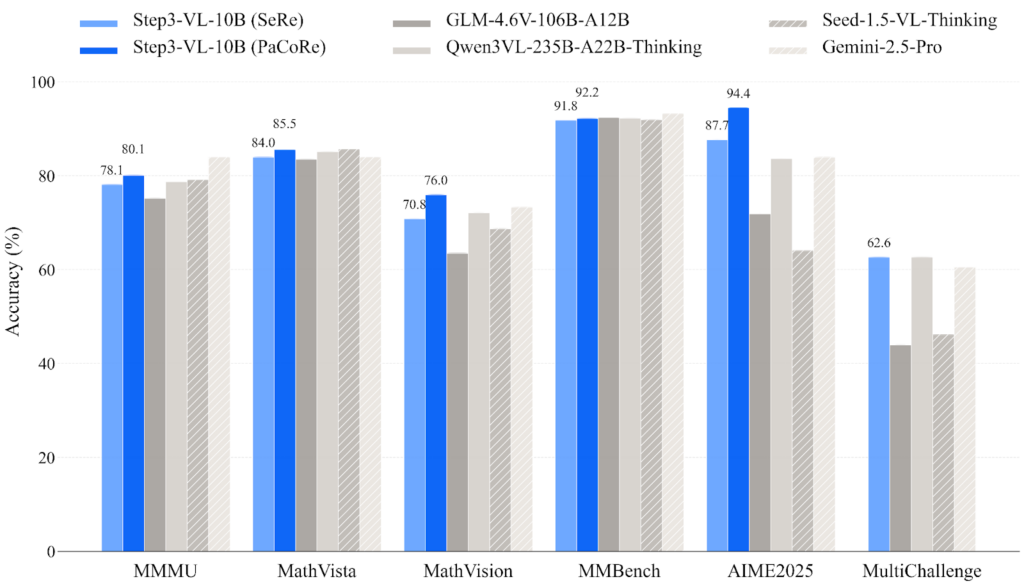
AIME 2025(数学オリンピック形式のベンチマーク)では、PaCoRe使用時に94.43%を達成しました。これはGemini 2.5 Proの83.96%を10ポイントほど上回る驚くべき結果です。
STEP3-VL-10BはMathVisionでも75.95%を記録し、GLM-4.6V(106B)の63.50%を大きく超えています。
| ベンチマーク | STEP3-VL-10B | Gemini 2.5 Pro | GLM-4.6V (106B) |
|---|---|---|---|
| AIME 2025 | 94.43% | 83.96% | 71.88% |
| MathVision | 75.95% | 73.30% | 63.50% |
| MMMU | 80.11% | 83.89% | 75.20% |
| MMBench | 92.05% | 93.19% | 92.75% |
7B〜10Bクラスで最強
同サイズ帯のオープンソースモデルと比較しても、STEP3-VL-10Bは高い性能を見せています。
MMBenchでは92.05%を記録し、Qwen3-VL-8B(91.04%)やInternVL3-8B(90.55%)を上回ります。特にHumanEval-V(コード生成ベンチマーク)では66.05%と、2位のGLM-Edge-V-5B(31.96%)の2倍以上のスコアです。
GUI理解においても優れた性能を示しています。ScreenSpot-V2で92.61%、ScreenSpot-Proで51.55%を達成しています。
これらの結果から、コード生成や画面認識・操作支援タスクに強いことがわかります。
多彩な応用領域
STEP3-VL-10Bは幅広いタスクに対応できる汎用性を備えています。
STEM推論(数学・物理)、視覚認識、OCR・ドキュメント理解、GUI操作、空間認識など、多様な領域で高いパフォーマンスを発揮します。
BLINKベンチマーク(空間理解)では66.79%、All-Angles-Benchでは57.21%を記録しており、AIによるロボット制御などの応用にも期待できます。
STEP3-VL-10Bの安全性・制約
STEP3-VL-10Bを利用する際は、いくつかの制約事項を把握しておく必要があります。公式ドキュメントには、モデルの限界や注意点が明記されています。実際の導入前に確認しておきましょう。
生成精度の限界
公式のHugging Faceページには、以下の制限事項が記載されています。
- 事実情報の提供は想定されていない
- テキストレンダリングは不正確になる場合がある
- 学習データのバイアスを反映する可能性がある
- プロンプトに一致しない出力が発生する場合がある
動作環境の要件
STEP3-VL-10Bを実行するには、BF16推論に対応したGPUが必要です。
2026年1月20日時点では、BF16推論のみがサポートされています。推論には約20GB以上のVRAMが目安となるため、NVIDIA RTX 3090/4090クラス以上のGPUを推奨します。
なお、オープンソースAIは様々な種類があり、文章の要約や動画の抽出といったタスクを簡単に実行できるfabricもおすすめです。詳しく知りたい方は、下記の記事を合わせてご確認ください。

STEP3-VL-10Bの料金
STEP3-VL-10Bはオープンソースで公開されており、ダウンロード・利用ともに無料です。
クラウドAPI経由ではなく、自前の環境で実行する形式のため、モデル自体への課金は発生しません。
| 項目 | 料金 |
|---|---|
| モデルダウンロード | 無料 |
| ローカル推論 | 無料(自己ホスティング) |
| 商用利用 | 無料 |
| APIサービス | 公式提供なし(2026年1月20日時点) |
2026年1月20日時点では、公式のAPIサービスは提供されていません。Hugging Face Inference Providersでの提供も待機状態となっています。
STEP3-VL-10Bのライセンス
STEP3-VL-10BはApache 2.0ライセンスで公開されています。
これは非常に寛容なオープンソースライセンスで、商用利用を含む幅広い用途に対応しています。
| 項目 | 可否 |
|---|---|
| 商用利用 | ◯ |
| 改変・カスタマイズ | ◯ |
| 再配布 | ◯ |
| プロダクトへの組み込み | ◯ |
| SaaS/APIサービスとしての提供 | ◯ |
Apache 2.0ライセンスの主な条件は、著作権表示とライセンス文の保持と変更箇所の明示です。商標の使用は許可されていないため、StepFunの商標を使ったサービス名などは避ける必要があります。
STEP3-VL-10Bの実装方法
STEP3-VL-10Bは、Hugging Face TransformersやvLLM、SGLangなど複数の方法で実行できます。
まず動作確認したい場合はTransformersで試し、本格的なデプロイにはvLLMやSGLangを使うのがおすすめです。ここでは、最も基本的なTransformersでの実行方法を紹介します。
動作環境
| 項目 | 推奨 |
|---|---|
| Python | 3.10 |
| PyTorch | 2.1.0以上 |
| Transformers | 4.57.0 |
| VRAM | 約20GB以上 |
`transformers < 4.51.0`を使用すると`KeyError: ‘qwen3’`エラーが発生するため、必ず4.57.0以上にアップグレードしてください。
デプロイ方法
本格的なAPIサービスとしてデプロイする場合は、vLLMまたはSGLangを使用します。
bash
# SGLangでのデプロイ
python -m sglang.launch_server --model-path stepfun-ai/Step3-VL-10B --reasoning-parser qwen3
# vLLMでのデプロイ
vllm serve --model stepfun-ai/Step3-VL-10B -tp 1 --reasoning-parser deepseek_r1 --enable-auto-tool-choice --tool-call-parser hermes --trust-remote-codeSTEP3-VL-10Bの活用シーン
STEP3-VL-10Bの高い推論能力と視覚理解力は、さまざまなシーンで活用できます。
STEM推論やGUI操作、ドキュメント処理に強みを持つため、これらが活かせる環境での導入がおすすめです。ここでは、3つの活用シーンを紹介します。
教育・学習支援
AIME 2025で94.43%を達成した高いSTEM推論能力は、教育分野での活用に最適です。
数学や物理の問題解説、図解が必要な説明文、段階的な解法の提示など、生徒の理解を助けるコンテンツ生成に活用できます。
PaCoReを使えば、複雑な問題でも複数の視点から検討した上で最適な解答を導き出せます。
GUIオートメーション
ScreenSpot-V2で92.61%、ScreenSpot-Proで51.55%というGUI理解性能は、RPAやテスト自動化に役立ちます。
画面のスクリーンショットを入力して「このボタンをクリックしてください」といった指示を理解させたり、画面上の要素を認識してレポートを生成したりする業務に向いています。
今までのルールベースRPAでは対応が難しかった、動的なUIの認識も可能です。
ドキュメント処理
OCRBenchで86.75%という文字認識精度は、ドキュメント処理の自動化に有効です。
請求書や契約書のスキャン画像から情報を抽出したり、手書きメモをデジタル化したり、今まで人間が苦労していた作業を効率化できます。図表を含む技術文書の理解にも対応しています。
なお、オープンソースのローコード自動化ツールのn8nは、誰でも簡単にワークフローを作れて業務を効率化することができます。AI活用をした業務効率化について詳しく知りたい方は、下記の記事を合わせてご確認ください。
STEP3-VL-10Bを実際に使ってみた
Hugging Face Spacesを使って、STEP3-VL-10Bを実際に動かしてみました。Hugging Face Spacesは、AIモデルをブラウザ上で手軽に試せるデモサービスです。STEP3-VL-10Bのデモページはこちら。
画像理解テスト
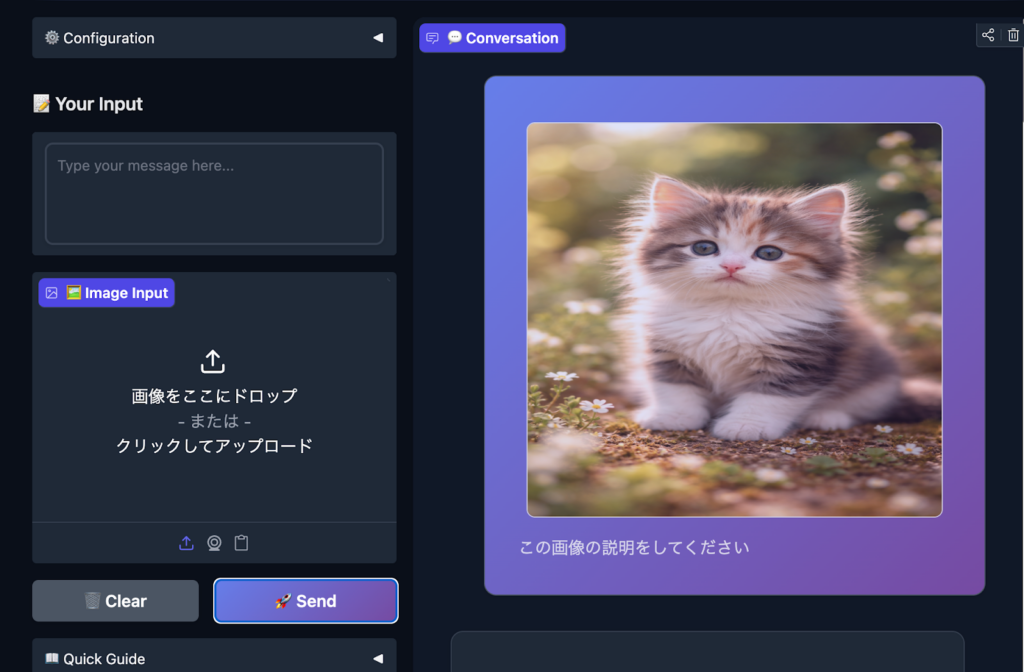
猫の画像をアップロードして、「この画像について説明してください」と指示したところ、以下のような内容が表示されました。
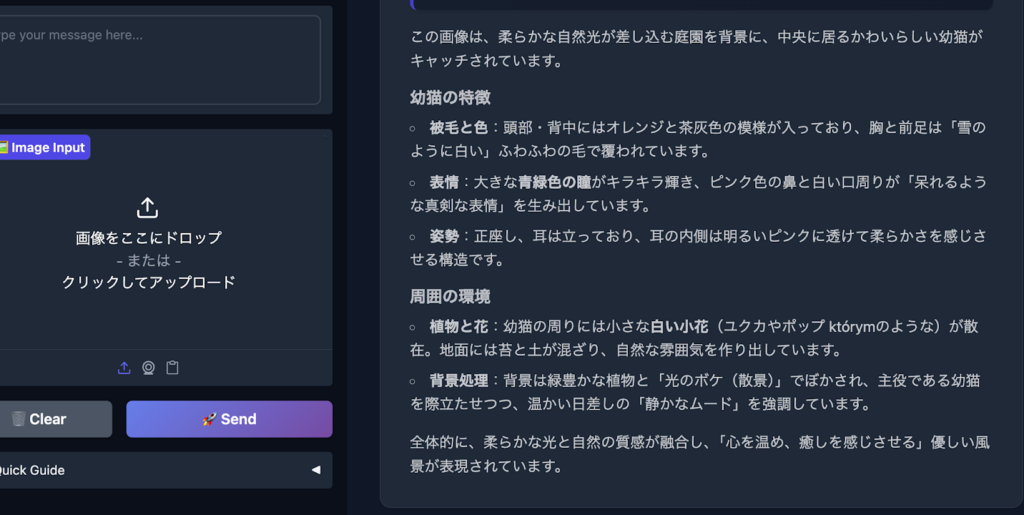
画像の内容を認識して、説明を返していることがわかるかと思います。
Qwen3-8Bをデコーダーに採用しているため、日本語も自然です。画像内の細部への言及も的確でした。
推論能力テスト
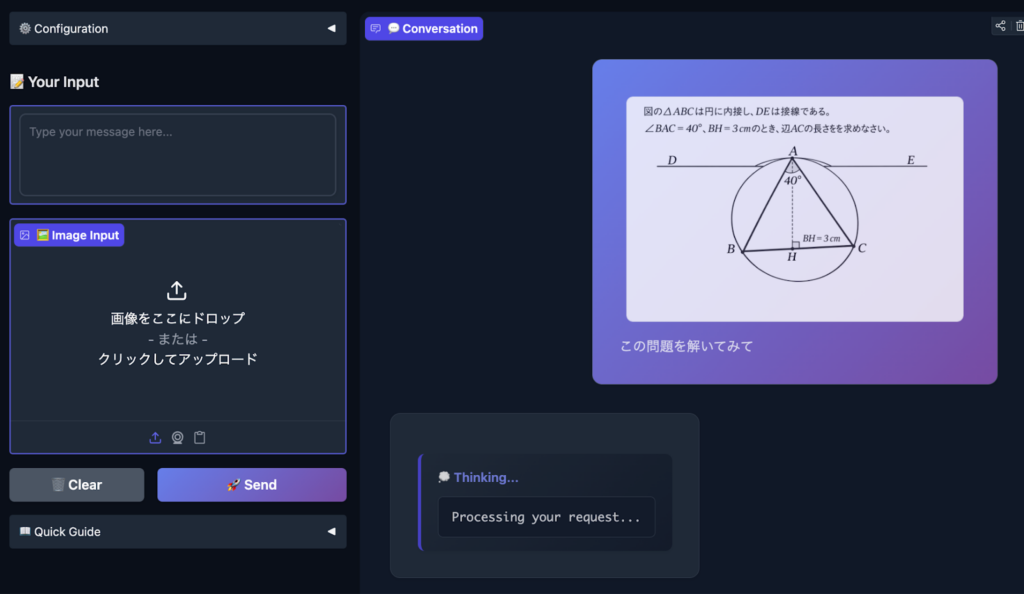
数学の図形問題を画像で入力し、解法を求めたところ、段階的な思考過程を見せながら正解にたどり着きました。複数のアプローチを検討した上で、解法を選択しているようでした。
こういった推論や計算は、他モデルでも可能ですが、わずか10Bで画像解析までできることが驚きです。
まとめ
STEP3-VL-10Bは、10Bパラメータでありながら100B超えモデルを凌駕する画期的なマルチモーダルAIです。
AIME 2025で94.43%、MMBenchで92.05%という高いベンチマークスコアを達成し、Apache 2.0ライセンスで商用利用も可能です。
PE-lang Visual EncoderとQwen3-8Bデコーダーの組み合わせ、1.2Tトークンの学習、PaCoReによる推論スケーリングなど、効率と性能を両立できることが特徴です。
教育支援やGUIオートメーション、ドキュメント処理など、幅広い用途に活用できます。まずはHugging Faceからダウンロードして、ローカル環境で試してみてください。

最後に
いかがだったでしょうか?
高性能モデルをどう業務に組み込み、コストや運用リスクを抑えながら活かすかは設計次第。STEP3-VL-10Bを含むマルチモーダルAIの選定から、ローカル運用・商用利用を見据えた活用方針まで整理したい方に弊社の紹介をさせていただきます。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

