
【VibeVoice-ASR】1時間の音声を一括文字起こしできるMicrosoftの次世代ASRを徹底解説
- Microsoft発、従来ASRモデルの課題を解決する画期的なオープンソース音声認識モデル
- 最大60分もの音声を一度に処理し、誰が・いつ・何を話したかという情報まで含めた構造化された文字起こしを出力可能
- アーキテクチャとして、AlibabaのLLM「Qwen 2.5」が組み込まれている
長時間にわたる会議やインタビューなどの音声を文字起こしする際、従来の音声認識(ASR)モデルでは、課題が多く存在します。
多くのモデルは、音声を数十秒程度の短い断片に区切って処理し、それらを繋ぎ合わせる手法を取ります。しかし、この方法では話者の混同や文脈の切断が発生しがちで、発言者が入れ替わって認識されたり、長い会話の流れが失われたりする問題がありました。
こうした課題を解決するため、2026年1月にMicrosoftから画期的なオープンソース音声認識モデル「VibeVoice-ASR」が公開されました!
VibeVoice-ASRは、最大60分もの音声を一度に処理し、誰が・いつ・何を話したかという情報まで含めた構造化された文字起こしを出力できる音声認識モデルです。本記事では、このVibeVoice-ASRの概要や性能、ライセンス情報や使い方まで詳しく解説します。
ぜひ最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
VibeVoice-ASRの概要

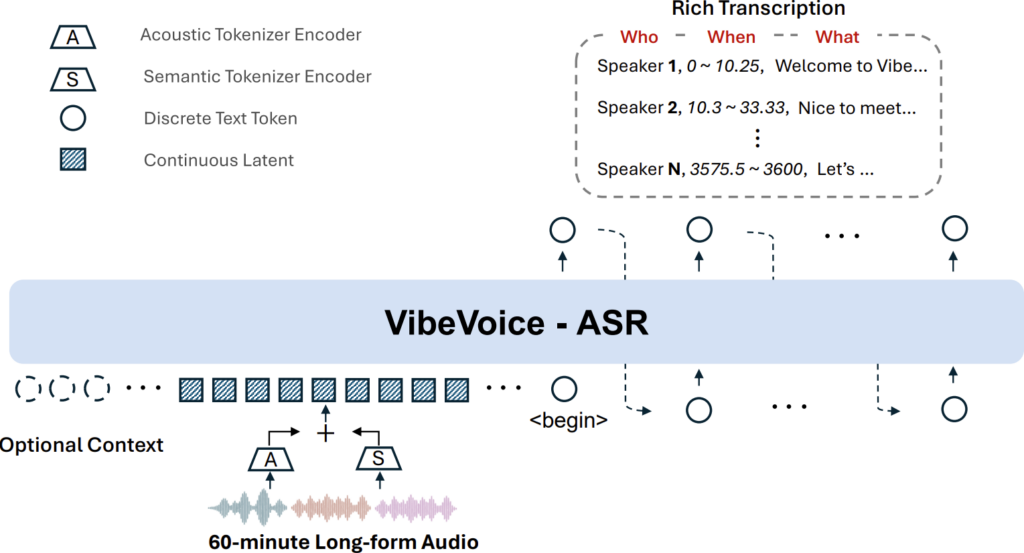
VibeVoice-ASRは、Microsoft Researchが開発した音声認識モデルで、話者分離(ダイアリゼーション)とタイムスタンプ付与を音声認識と統合した「統合型ASRモデル」です。
一般的なASRモデルとは異なり、VibeVoice-ASRは、長時間の音声も音声全体を一度で処理できるのが特徴です。具体的には、最長60分の連続音声を切り分けずに入力し、出力として「誰(話者)」「いつ(発話時間)」「何を(発言内容)」の情報を含んだリッチな文字起こし結果を返してくれます。
VibeVoice-ASRの主な特徴は以下の通りです。
長時間音声の一括処理
60分までの音声を切り分けずに一度で処理できます。従来のように、短い断片ごとに認識して結果をつなぎ合わせる必要がなく、話者IDのリセットや文脈の途切れが起きません。
64,000トークンという非常に長いコンテキストウィンドウを持ち、長時間録音全体の文脈を保持したまま認識を行います。
話者の自動識別(ダイアリゼーション)
音声中の発話者をモデルが自動で識別し、発言ごとに「スピーカー1」「スピーカー2」など話者ラベルを割り当てます。これによって、誰が話したかが明確に記録された文字起こし結果を得ることができます。
複数話者の会議や対談でも、話者ごとの発言内容を後からかんたんに追跡することもできます。
タイムスタンプ付きの出力
各発言には、開始〜終了時刻のタイムスタンプが付与されます。これによって、いつ話されたかが明示的になり、後から音声を再生するときの目安にしたり、映像と同期させたりといった利活用が可能になります。
カスタムホットワード
ユーザーが事前に、特定の用語や名前をホットワード(重要語彙)としてモデルに与えることで、その言葉を正確に聞き取るよう認識精度を向上させることができます。
例えば、専門用語や人名、プロジェクト名などをホットワードとして指定すれば、それらが音声中に出てきた際の認識ミスを大幅に減らすことができます。
従来のWhisperやGoogleの音声APIではこのような特定語彙の指定ができないため、VibeVoice-ASRの大きな強みと言えそうです。
50言語以上の多言語対応
英語や日本語はもちろん、中国語を含む50以上の言語に対応しており、言語を明示的に指定しなくても自動で認識してくれます。
1つの音声中で複数言語が混在するコードスイッチングにも対応しているため、国際会議やバイリンガルの会話でも一貫して文字起こしが可能になっています。
また、内部のモデル構造としては、Alibabaが公開したLLMであるQwen(2.5世代・15億パラメータ)がベースとして組み込まれていて、音声から抽出した連続トークン列をこのLLMが言語的文脈を考慮してテキストに変換します。
モデル全体の規模は、約90億パラメータに及び、オープンソースのASRモデルとしては非常に大規模です。
なお、Qwen2.5について詳しく知りたい方は、以下の記事も参考にしてみてください。
VibeVoice-ASRの性能
Microsoftの技術レポートによると、VibeVoice-ASRは、話者混在の長時間音声において従来の最先端モデルを上回る精度を誇っています。
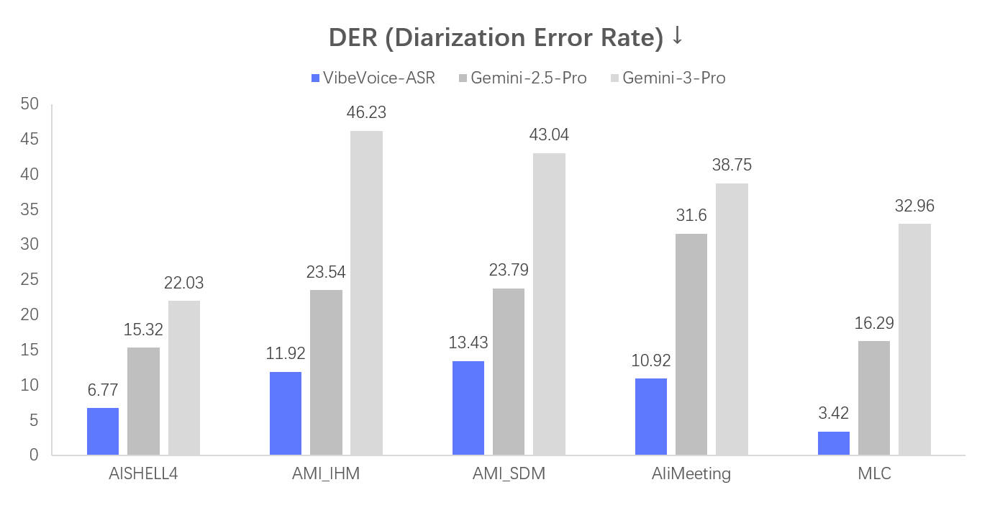
特に、話者ダイアリゼーション性能(誰が話したかを正しく分離できているかの指標)であるDER(Diarization Error Rate)が大幅に改善されています。
以下の図は、公開された複数ベンチマークでのDER比較結果ですが、低いほど良いこの指標で、青色のVibeVoice-ASRが他の既存モデル(Gemini-2.5-ProやGemini-3-Pro)よりも一貫して低い誤り率を残しているのがわかります。
また、音声認識の語錯誤率(WER)についても、話者混在下での評価指標であるcpWER(話者順序の入れ替えを許容した連結WER)やtcpWER(時間整合性も考慮したWER)で高い性能を残しています。
VibeVoice-ASRは、公開ベンチマークの全データセットで、DERとtcpWERにおいて既存モデルを上回る結果を達成し、cpWERでも16項目中11項目で最新のベストスコアを更新しました。
通常のWER自体も16項目中8項目で最良となっていて、他の項目でもごくわずかな差に留まっています。
これらの結果から、VibeVoice-ASRが、文字起こしの正確さと話者区別を伴う転写の2点で、非常に優れたバランスを達成していることがわかりますね。


VibeVoice-ASRのライセンス
VibeVoice-ASRは、オープンソースのMITライセンスで公開されています。MITライセンスは非常に寛容なオープンライセンスで、商用利用や改変・再配布などを自由に行うことができます。
| 利用用途 | 可否 | 備考 |
|---|---|---|
| 商用利用 | ⭕️ | |
| 改変 | ⭕️ | |
| 配布 | ⭕️ | |
| 特許使用 | 不明 | |
| 私的使用 | ⭕️ |
VibeVoice-ASRの料金
VibeVoice-ASR自体の利用は無料です。
前述の通り、MITライセンスで公開されているので、モデルのダウンロードや使用にライセンス料は一切かかりません。
ただし、実際に運用する際には計算資源(GPUサーバー等)のコストは発生するので注意しましょう。
VibeVoice-ASRの使い方
VibeVoice-ASRはオープンソースモデルのため、ウェブ上のデモからプログラムでの呼び出しまで様々な使い方が可能です。今回は、代表的な利用方法を2つご紹介します。
オンラインデモを利用する
技術的なセットアップ無しで試したい場合は、Microsoftの公式オンラインデモ(Playground))を利用する方法があります。
VibeVoice-ASR Playgroundにアクセスすると、音声ファイルをアップロードできるUIが読み込まれます。
表示されたら、文字起こししたい音声のファイル(例:会議録音のMP3など)を選択してアップロードします。デモではサンプル音声が用意されているので、最初はそちらで試すことも可能です。
必要に応じて、専門用語や人名など、事前に認識精度を上げたい単語があればテキスト入力欄にホットワードとして登録します。例えば「Azure」「プロジェクトX」「山田太郎」などと入力しておくと、その語が音声中に出現した際にモデルが聞き逃しにくくなります。
設定が完了したら、「Transcribe」ボタンを押すとモデルが音声の解析を開始してくれます。
長時間動画を一括で文字起こしするツールを探している方は、以下の記事もご覧ください。
PythonでTransformersパイプラインを利用する
ご自身の環境でコードから直接VibeVoice-ASRを使いたい場合は、Hugging FaceのTransformersライブラリ経由でモデルをロードする方法があります。2026年2月3日時点のTransformersではVibeVoice-ASRに対応しているため、以下のように数行のコードで音声認識を実行可能です。
pip install -U transformers torchaudioTransformersのpipeline機能を使ってモデルをロードします。モデル名としてHugging Face上のリポジトリIDである"microsoft/VibeVoice-ASR"を指定します。
from transformers import pipeline
asr = pipeline("automatic-speech-recognition",
model="microsoft/VibeVoice-ASR")読み込んだasrパイプラインに音声ファイルパスを渡すだけで文字起こしを実行することができます。さらにhotwords引数でリストを渡せばホットワードも指定できます。
result = asr("meeting.mp3",
hotwords=["Azure", "プロジェクトX", "山田太郎"])こちらののコードではmeeting.mp3という音声ファイルを認識し、結果をresultに格納させています。処理時間は音声長に依存すると思います。
resultオブジェクトには認識結果が格納されています。VibeVoice-ASRの場合、出力は各発話ごとに話者・時間・内容を含むリスト形式の辞書となっています。
以上、代表的な使い方を2つご紹介しました。
会議の文字起こし・議事録作成を自動化したい方は、以下の記事もご覧ください。

VibeVoice-ASRを使ってみた
それでは実際に、ViveVoice-ASRを使ってみましょう。今回は公式オンラインデモ(Playground))上で試していきます。
まずはサンプルの音声(動画)を使ってみます。左下が1分ほどの音声付き動画になっています。
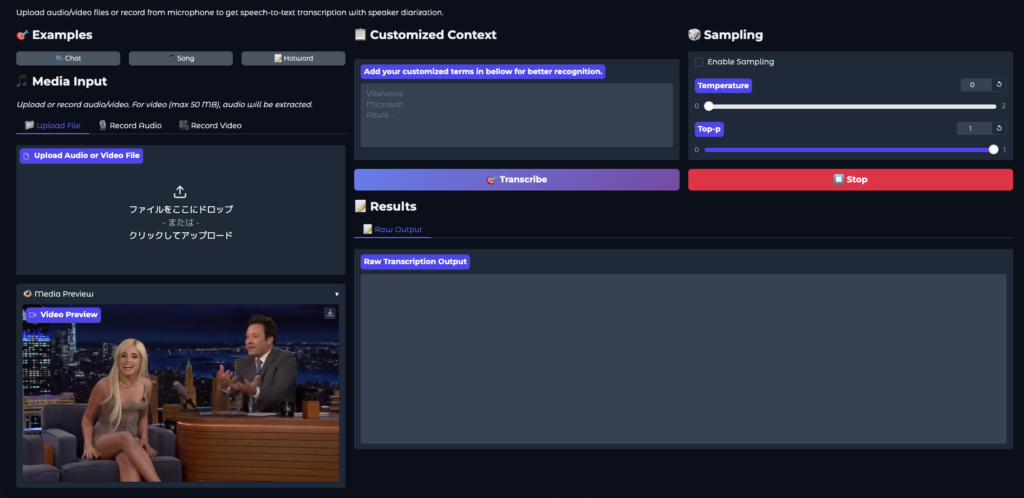
音声解析を実行すると、数秒で解析が完了しました。想像以上の速さです。
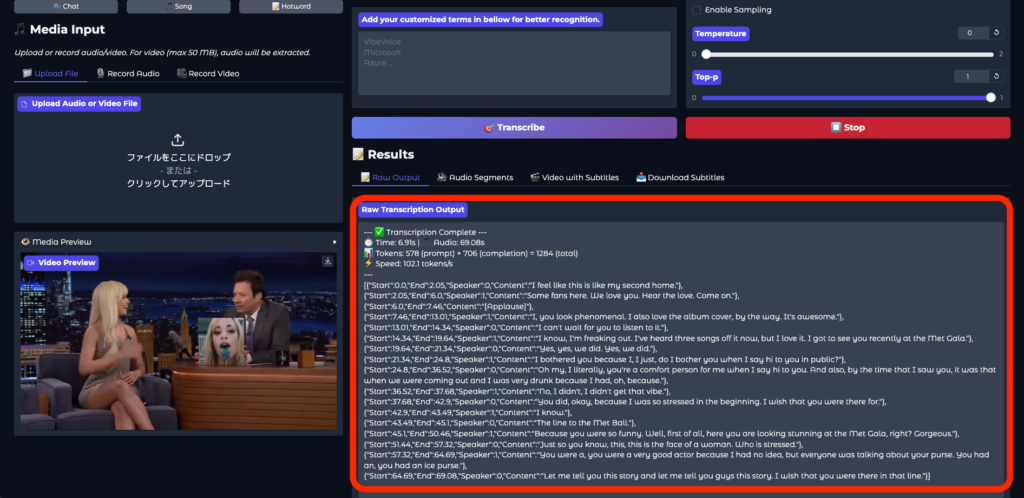
スピーカーの発した言葉はもちろん、観客の歓声(「Applause」と解析されている部分)も正確に反映されています。
続いては実際に録音した音声を解析させてみます。日本語で話したり、拍手などの音も入れてみた音声の解析結果はこちら。
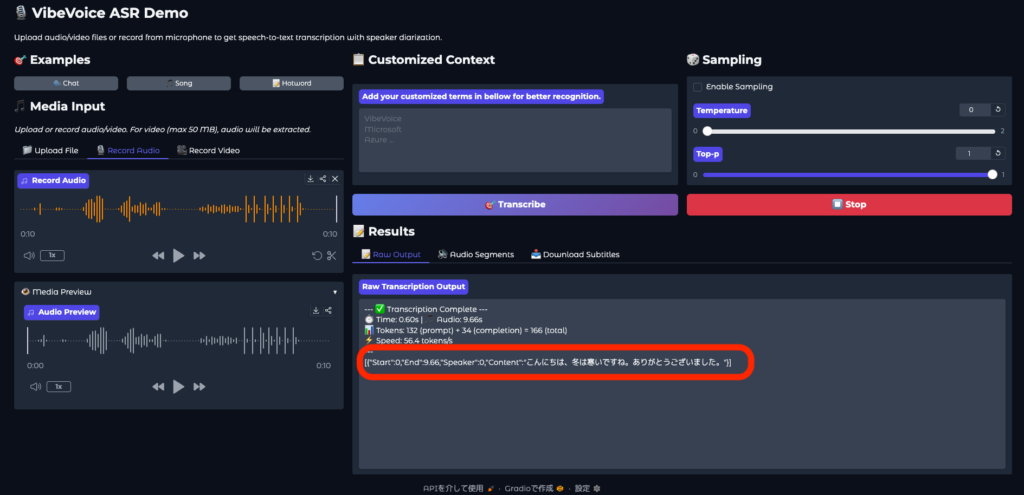
日本語も問題なく正確に音声を抽出してくれました。ただ、最後に7回拍手した部分はスルーされてしまいましたね。
お手元の動画・音声ファイルをアップロードして解析させることもできるので、ぜひ試してみてください。


まとめ
Microsoftが公開したVibeVoice-ASRは、長時間・多話者の音声認識という課題を解決してくれる画期的なオープンソースASRモデルです。
今後、競合他社やコミュニティからも同様の長時間対応モデルが次々と生まれてくると想像できますが、VibeVoice-ASRはその中でもキーモデルとして、多くのプロダクトや研究で活用されていくと思います。
気になった方は、ぜひ一度試してみてください!

最後に
いかがだったでしょうか?
弊社では、AI導入を検討中の企業向けに、業務効率化や新しい価値創出を支援する情報提供・導入支援を行っています。最新のAIを活用し、効率的な業務改善や高度な分析が可能です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

