
【EMO】二次元彼女と話せる日がすぐそこに…!アリババのヤバい音声AIの仕組みを徹底解説

WEELメディア事業部LLMリサーチャーの中田です。
2024年2月27日、アリババの研究グループから「EMO」という動画生成AIモデルが公開されました!
このモデルによって、画像の中の人物に、表情豊かに歌わせたり、喋らせたりすることが可能になりました。
EMOのGitリポジトリのスター数は、すでに1,200を超えており、注目されていることが分かります。
この技術を使えば、画面の中にいる二次元彼女と話せる日もそう遠くはないでしょう!
この記事では、EMOの技術的な部分を徹底的に解説します。本記事を熟読することで、EMOの内部構造をより理解でき、一般公開が待ち遠しくなるでしょう。
ぜひ、最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
EMOの概要
アリババが公開した「EMO」は、1枚の画像と1つの音声から、ポートレートビデオを生成できるAIです。これにより、画像の中の人物を喋らせたり、歌わせたりすることが可能になります。さらに、表情や頭の動きも自然に表現されるのだとか。
イメージとしては、一時期流行ったマイアヒのような感じです。
入力するデータは、以下の2つ。
- 人物画像
- 音声(歌、話し声など)
これだけで、高精度なリップシンクを実現できるそう。
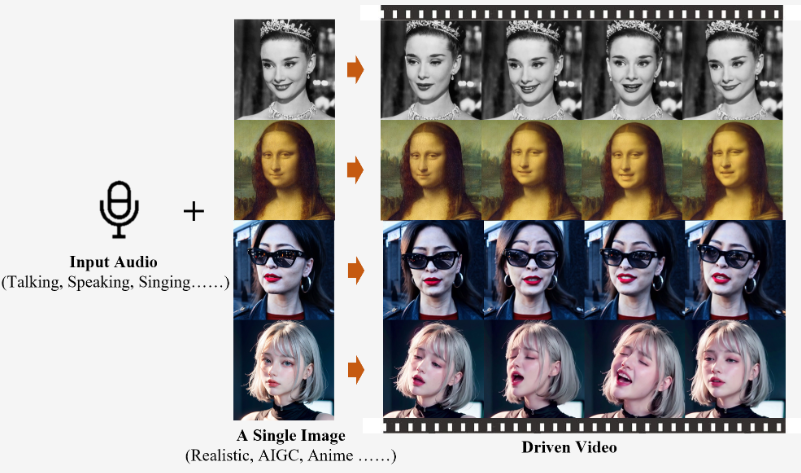
EMOを利用すれば、かなり自然なCGの生成も可能になるでしょう。EMOの成果物は、公式のプロジェクトページで確認できます。
なお、音源を分析したり、多言語に翻訳したりできるAIについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
→【Qwen-Audio】音声だけで状況認識や多言語翻訳ができるアリババ産LLMを使ってみた
EMOで用いられている技術
EMOの技術的な詳細は、EMOの論文に記載されています。
EMOの概要は、以下の通りです。
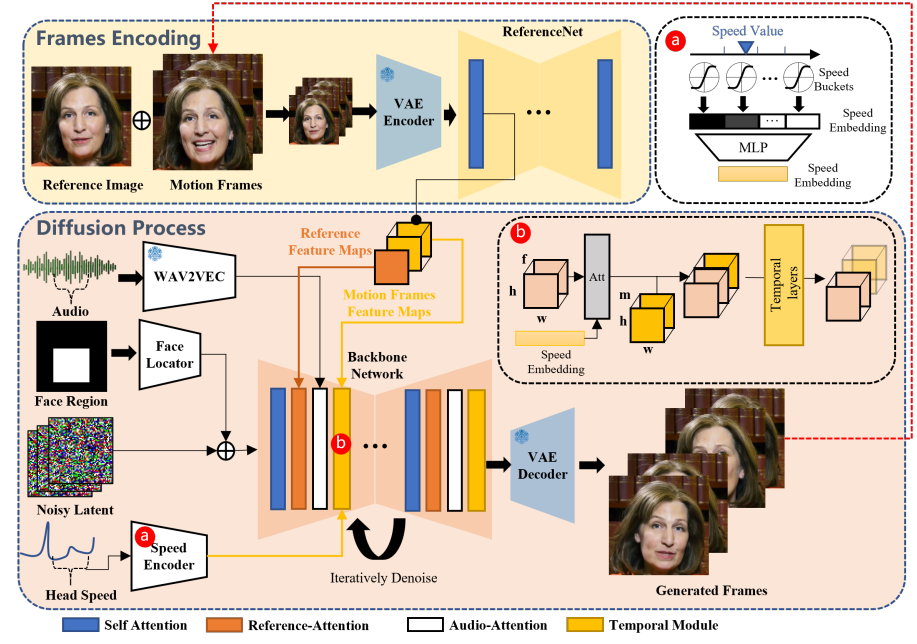
本手法のメインとなるモデルは、以下の2つ。2つとも、Stable DiffusionのU-Netと同様の構造を持っており、Stable Diffusionの重みでパラメータの初期化を行っているとのこと。
- ReferenceNet
- Backbone Network
特に、メインとなるのはBackbone Networkで、画像と音声が入力されると、上図の右下のような「Generated Frames(ビデオフレーム)」を生成します。これが、本モデルの生成物の正体です。つまり、EMOは動画生成モデルと言えるでしょう。
また、ReferenceNetでは、対象人物の画像がReferenceNetに入力されます。Backboneのノイズ除去(データ生成)の過程で、Backbone Networkに、入力画像に関する詳細な情報を送り込みます。
他にも、EMOには以下のようなモジュールがあります。
| モジュール | 役割 |
|---|---|
| Audio-Attention Layers | wav2vecを通じて抽出された音声の特徴を把握し、動画生成の際に情報を送り込む。 |
| Temporal Modules | 連続するビデオフレーム間の時間関係を理解し、動画生成の際に情報を送り込む。 |
| Face Locator | 画像中の顔の位置を検出。 |
| Speed Layers | 頭部動作の速度情報を抽出。 |
ちなみに、「○○-Attention」と名前がついている層は、プロンプトなどの「条件」を受け付ける役割を持っています。そして、そこで受け付けた条件情報を参考にして、データ生成を行います。
学習過程
EMOの学習では、以下の3つのステップで進みます。
- Backbone Network、ReferenceNet、Face Locatorを画像で学習
- Audio LayerやTemporal Layerもモデルに追加し、動画データでモデル全体を学習
- Speed Layersをモデルに追加し、Temporal ModulesとSpeed Layerを学習
また、モデルの推論中にはDDIMのサンプリングアルゴリズムを使用し、40ステップでビデオクリップを生成します。各フレーム生成には一定の速度値が割り当てられ、所要時間は約15秒/バッチ(f = 12フレーム)です。
研究結果
実験の詳細は以下の通りです。
- HDTFデータセットを用いて、10%をテストセットとして割り当て、残りの90%をトレーニングに使用。
- 既存の手法(Wav2Lip, SadTalker, DreamTalkなど)と比較。
- Diffused Headsとの定性的比較も実施。
- インターネットから約250時間のトーキングヘッドビデオを収集し、HDTFとVFHQデータセットでモデルを学習。
- 複数の量的指標((FID), SyncNetスコア、顔の類似度(F-SIM)、(FVD)、表情FID (E-FID))を用いてモデルを評価。
EMOは、定量的指標と定性的評価において優れた結果を示し、特に表情の豊かなビデオ生成において顕著な改善が見られました。
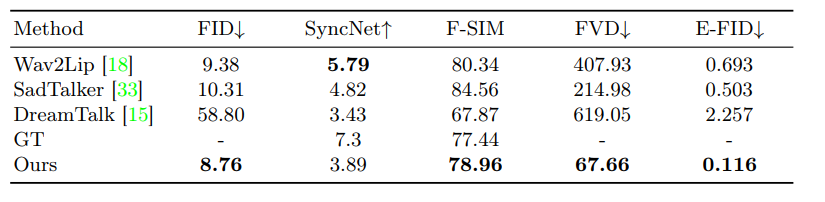

これにより、EMOは話し声や歌声に合わせた自然でリアルな「ビデオポートレート」の生成が可能であることが確認されました。

EMOを使ってできること
今回のEMOに関してもそうですが、ここ最近のアリババは、「エンタメ用途のAI」に関する研究に焦点を置いているのが見受けられます。
そして、今回のEMOに関しては、以下のようなエンタメ業界での応用が示唆されています。
- 映画やゲーム業界でキャラクターアニメーションを生成するため
- 仮想現実(VR)や拡張現実(AR)アプリケーションでリアルなユーザーインタラクションを実現するため
さらに、そのほかの業界でも、多岐にわたる応用が考えられます。
- デジタルアバターの作成
- オンライン教育での講師の表情を再現するツール
- ソーシャルメディアでのエンゲージメント向上
なお、Llama 2やGPT3.5をはるかに凌ぐアリババLLMについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
→【Qwen-72B】Llama 2、GPT3.5を大幅に上回る性能のアリババLLMを実際に使ってレビューしてみた
EMOの研究課題
本論文では、以下の2つの課題が示されています。
- 拡散モデルに依存しない方法(LLMベースなどの手法)に比べてデータ生成に時間がかかる。
- 手などの他の身体部分が不用意に生成され、映像にアーチファクトが生じる可能性がある。
この問題を解決する1つの方法は、身体の部位に関する情報抽出特化したモジュールを採用することだそう。
なお、アリババの仮想試着ツールについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
→【Outfit Anyone】「服を着る」という概念が大きく変わる!誰でも好きな服を着れる最新AIの使い方〜実践まで
今後のエンタメ業界におけるAIの動向に注目
本記事では、画像と音声から、画像と音声を用いて表情豊かなアバターや動画を生成するAIの「EMO」についてご紹介しました。
EMOの公式リポジトリには、まだソースコードは公開されていないです。そのため、EMOのモデルが一般公開されれば、そのほかの生成AIモデルとの融合により、さらなる用途の拡大が見込めるでしょう。
EMOでは画像を入力しますが、コードが改良されて、動画の入力も受け付ければ、より精度の高いアバター生成が可能になるかもしれません。
ちなみにXでは、「中国のAIの勢い」や「今後のAI×エンタメ」について言及している投稿がありました。
最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

