
AIにおけるRAG(検索拡張生成)の精度向上手法まとめ!知識や検索関連の改良手法を徹底解説

- RAG(検索拡張生成)とは何かを知りたい
- 具体的なRAGの手法を知りたい
- RAGに関する知識を得たい方
「RAG(Retrieval-Augmented Generation)」は、生成AIモデルに外部データベースからの情報検索機能を組み合わせることで、より正確で最新の情報提供を可能にする技術です。
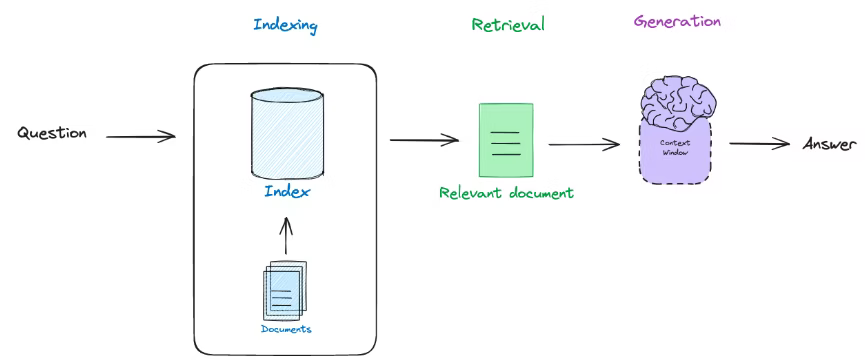
この仕組みにより、モデルはトレーニングデータに依存せず、リアルタイムで信頼性の高い回答を生成できるようになるため、生成AIの応用には欠かせません。
本記事では、そんなRAGについて、概要や精度向上のための改良手法を紹介します。
\生成AIを活用して業務プロセスを自動化/
RAGの概要
「RAG」とは、生成型AIモデルに情報検索機能を組み込む技術です。
ユーザーのクエリに対し、モデルが自身のトレーニングデータだけでなく、関連する外部ドキュメントを検索・参照し、回答を生成します。
これにより、最新の情報や専門的な知識を取り入れた応答が可能となり、企業内データへのアクセスや、信頼性の高い情報提供など、多岐にわたる応用が期待できます。


RAGの手法の大まかな分類
RAGには、大きく分けて「基本のRAG」「Advanced RAG」「Modular RAG」と3つの分類があります。それぞれ特徴をみていきましょう。
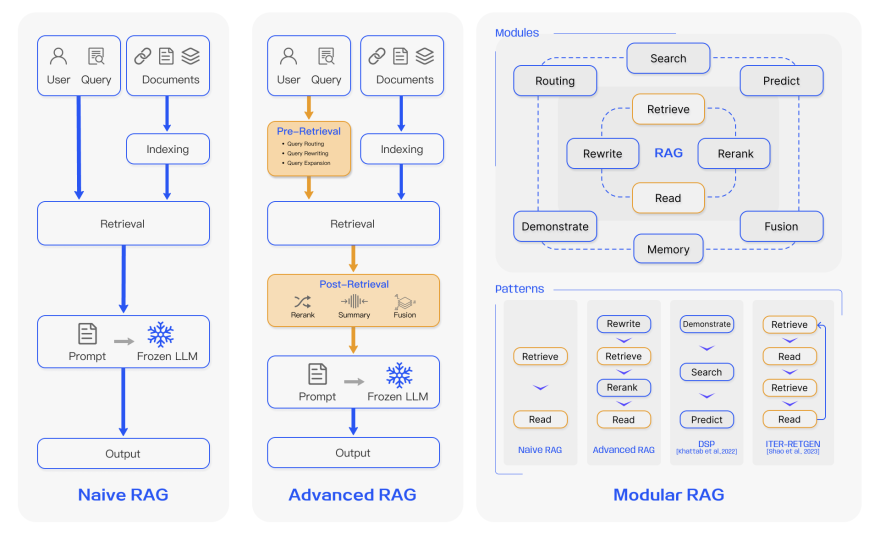
基本のRAG
Simple RAGやNaive RAG、Baseline RAGともいいますが、ユーザーのクエリに対し、関連するドキュメントを検索し、その情報をもとに応答を生成するスタンダードな手法です。
シンプルなアーキテクチャで、実装も容易ですが、複雑なクエリや大量のデータへの対応力には限界があります。
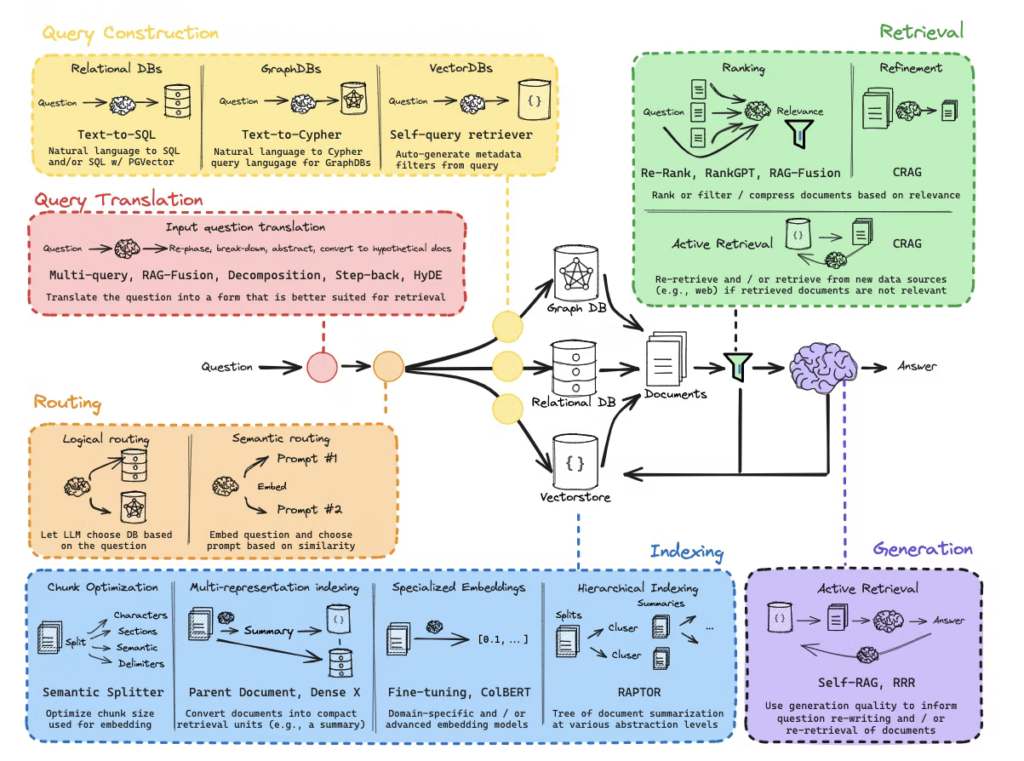
Advanced RAG
Advanced RAGは、基本のRAGに改良を加え、検索精度や応答の質を向上させた手法です。
例えば、「Late Interactions(遅延インタラクション)」を用いた精度向上や、「ハイブリッドベクトル」を活用した高速検索が含まれます。(※1)(※2)
Modular RAG
Modular RAGとは、RAGシステムを複数の独立したモジュールに分割し、各モジュールが特定の機能やタスクを担当することで、システム全体の柔軟性や拡張性を高めるアプローチです。ユーザーはデータソースやタスクの要件に応じて、異なるモジュールやオペレーターを組み合わせて最適なシステムを構築できます。
以下画像は、Modular RAGのモジュールの一覧です。
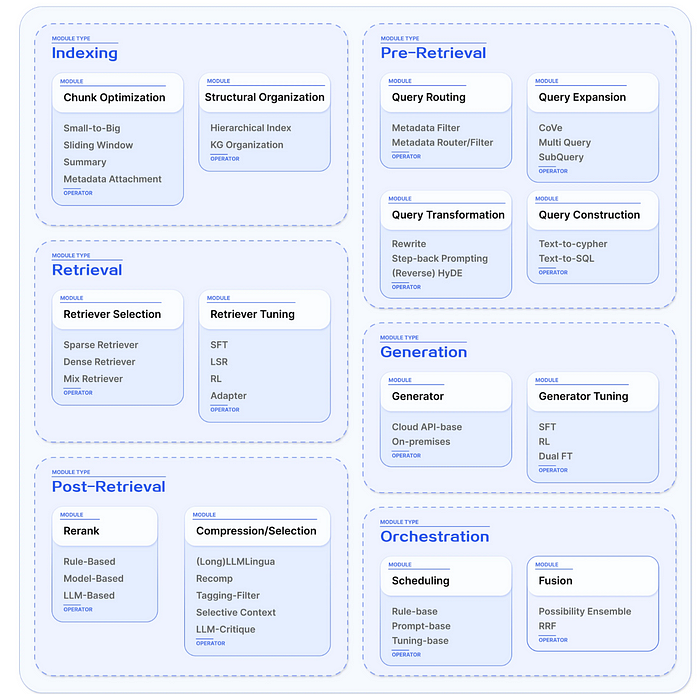
なお、RAGについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
知識周りのRAG改良手法8選
RAGには、ナレッジ関連の改良手法が複数あります。以下、1つ1つ詳細をみていきましょう。
Chunk Optimization
Chunk Optimizationはドキュメントを適切な長さのチャンクに分割し、検索精度と効率を高める手法です。
チャンクサイズが大きすぎると関連情報の抽出が困難になり、逆に小さすぎると文脈が失われる可能性があるため、適切なチャンクサイズの設定が重要です。
Proposition Chunking
Proposition Chunkingは文章を命題単位に分割し、より精緻な情報検索を可能にする手法です。クエリとの関連性が高まり、精度の高い検索結果が得られます。
Hypothetical Questions(HyDE Approach)
Hypothetical Questions(HyDE Approach)は、ユーザーの質問から仮の回答を生成し、それに似たドキュメントを検索する手法です。質問と関連する情報とのマッチングが向上し、より適切な回答を提供できます。
Contextual Chunk Headers
Contextual Chunk Headersは、各チャンクにコンテキストを示すヘッダーを付与し、検索時の関連性を高める手法です。チャンク間の関係性や文脈を保持しつつ、精度の高い検索が可能となります。
Relevant Segment Extraction
Relevant Segment Extractionとは、ドキュメントからクエリに関連するセグメントを抽出し、効率的な検索と応答生成を行う手法です。不要な情報を排除し、必要な情報に焦点を当てることができます。
Context Enrichment Techniques
外部データや知識ベースを活用して、チャンクのコンテキストを豊かにし、検索と生成の質を向上させる手法がContext Enrichment Techniquesです。モデルの理解力と応答の信頼性が向上します。
Semantic Chunking
Semantic Chunkingは、意味的な単位でドキュメントを分割し、検索の精度と効率を高める手法です。クエリとの関連性が高い情報を効果的に抽出できます。
Contextual Compression
Contextual Compressionとは、重要な情報を保持しつつ、チャンクのサイズを圧縮する手法のこと。メモリ使用量を削減し、検索と生成の速度を向上させます。
なお、RAGのデータの前処理について詳しく知りたい方は、下記の記事を合わせてご確認ください。

検索周りのRAG改良手法11選
検索周りについても改良手法が複数あります。1つ1つ、特徴をみていきましょう。
Query Transformations
Query Transformationsは、ユーザーのクエリを再構成または拡張し、検索精度を向上させる手法です。
具体的には、クエリの書き換えやサブクエリへの分解などが含まれます。検索エンジンがユーザーの意図をより正確に理解し、関連性の高い情報を取得できます。
Fusion Retrieval
Fusion Retrievalとは、ベクトルベースの類似性検索とキーワードベースの検索を組み合わせる手法のこと。
これにより、両方の方法の強みを活かし、より包括的で関連性の高いドキュメントの取得が可能となります。
なお、RAG Fusionについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Intelligent Reranking
Intelligent Rerankingは、初期の検索結果を再評価し、最も関連性の高い情報を優先的に表示する手法。ユーザーにとって有益な情報を上位に配置し、検索結果の品質を向上させることができます。
Multi-faceted Filtering
Multi-faceted Filteringとは、複数のフィルタリング技術を適用し、検索結果の品質を向上させる手法です。
これには、メタデータや類似性の閾値を利用した「フィルタリング」が含まれ、最も関連性が高く正確な情報を取得できます。
Hierarchical Indices
Hierarchical Indicesは、ドキュメントの階層的なインデックスを作成し、まず関連するセクションを特定。その後、詳細な情報を取得する手法です。これにより、精度の高い検索が可能となります。
Ensemble Retrieval
Ensemble Retrievalは、複数の検索モデルを組み合わせて、総合的な検索結果を生成する手法のこと。各モデルの強みを活かし、検索精度と網羅性を向上させます。
Dartboard Retrieval
Dartboard Retrievalとは、検索空間を複数のセグメントに分割し、それぞれを個別に検索する手法。広範な情報源から効率的に関連情報を取得できます。
Multi-modal Retrieval
Multi-modal Retrievalとは、テキスト、画像、音声など、複数のデータ形式を同時に検索し、包括的な情報取得を可能にする手法です。ユーザーの多様なニーズに対応した検索結果を提供できます。
なお、マルチモーダルRAGについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Retrieval with Feedback Loops
Retrieval with Feedback Loopsは、ユーザーのフィードバックを活用し、検索結果を逐次改善する手法です。検索エンジンがユーザーの好みやニーズに適応し、より精度の高い情報を提供できます。
Adaptive Retrieval
Adaptive Retrievalとは、ユーザーの行動やコンテキストに基づいて、検索戦略を動的に調整する手法。個々のユーザーに最適化された検索結果を提供できます。
Iterative Retrieval
Iterative Retrievalは、検索プロセスを複数の段階に分け、各段階で得られた情報を基に次の検索を行う手法です。
これにより、複雑なクエリや多段階の情報ニーズに対応できます。
その他のRAG改良手法4選
ナレッジ、検索以外にもRAGの改良手法がありますので、紹介します。
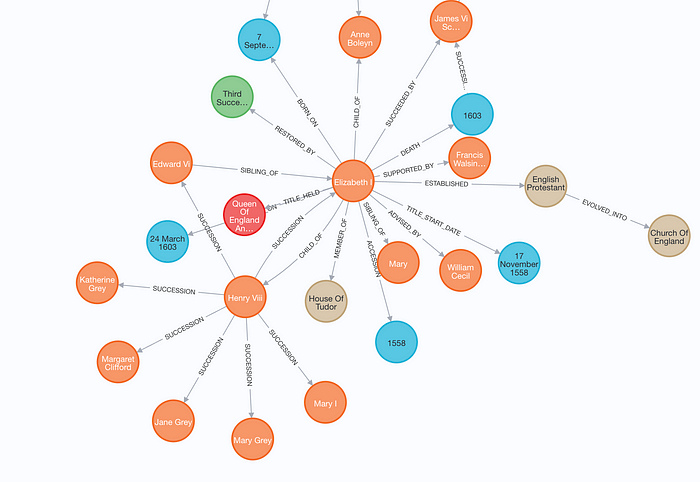
Knowledge Graph Integration(Graph RAG)
Knowledge Graph Integration(Graph RAG)とは、ナレッジグラフをRAGシステムに統合することで、情報の関連性と精度を向上させる手法です。
ナレッジグラフは、エンティティ間の関係性を視覚化し、複雑な情報の構造を明確にします。これにより、RAGシステムはユーザーのクエリに対して、より精緻でコンテキストに適した応答を生成できます。
以下の画像は、LangChainのLLMGraphTransformerで構築したナレッジグラフをNeo4で表示した例です。
Self RAG
Self-RAGは、LLMが自己反省を通じて、検索の必要性や取得したドキュメントの質を評価し、応答の正確性と信頼性を向上させる手法です。
具体的には、LLMがクエリに対して検索が必要かを判断し、取得したドキュメントごとに個別の応答を生成、その質を評価して最適な応答を選択します。
このプロセスにより、不要な検索を避け、ハルシネーションを減少させることが可能となります。
Corrective RAG(CRAG)
CRAGは、初期の応答に対して追加の検索と修正を行うことで、応答の正確性を高める手法です。
具体的には、初期の生成結果を評価し、不足している情報や誤りを検出した場合に、追加の検索を実行して情報を補完し、修正された応答を提供します。
これにより、ユーザーに対してより信頼性の高い情報を提供することが可能となります。
ファインチューニングとの併用
RAGシステムにおいて、LLMを特定のドメインやタスクに合わせてファインチューニングすることで、応答の精度と関連性を向上させる手法です。
ファインチューニングにより、モデルは特定のコンテキストや専門知識を学習し、ユーザーのクエリに対してより適切な応答を生成できます。
なお、RAGとファインチューニングの違いについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

まとめ
最後に改めて、RAGの改良で実現可能なことをまとめます。
【RAGの改良でできること】
- 最新情報の取得
- 外部データソースを活用し、常に最新の情報を取得
- 詳細かつ正確な回答生成
- 関連する情報を検索し、より具体的で正確な回答を生成
- 文脈に沿った回答生成
- ユーザーの意図や背景にあわせた応答が可能
- 社内文書やナレッジの活用
- 内部データを効果的に利用し、業務効率化に貢献
生成AIの性能向上と応用に欠かせない存在ですね!

最後に
いかがだったでしょうか?
RAGの活用により、生成AIはより正確で最新の情報を提供できるようになります。貴社の業務に最適なRAGの導入方法を検討し、AI活用の精度をさらに高めてみませんか?
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

