
GraphRAGを実際に動かしてみた!仕組みやメリットとデメリット、RAGとの違いを徹底解説

- グラフ構造で複雑な文脈や関係性を可視化・活用
- 必要に応じてベクトル検索や全文検索ともハイブリッド対応
- ノード間の関係を活かし、一貫性・網羅性の高い回答を生成
AIモデルは学習データに含まれない知識については正確に回答できず、企業内の機密情報や最新の話題に対する回答には限界がありましたが、RAG(Retrieval-Augmented Generation)という手法の登場により、大規模言語モデル(LLM)に外部データ検索を組み合わせ、未学習の情報も参照しながら回答を生成できるようになりました。
しかし、従来型のRAG(ベクトル検索による手法)には課題も指摘されています。単純なベクトル類似検索では質問に必要な情報をうまく見つけられない場合があり、複数の文書にまたがる「点と点をつなぐ推論」や、データセット全体のテーマを問う全体要約的な質問に弱いことが分かっています。
こうした課題を解決する新しいアプローチとして、マイクロソフトリサーチが提案したのが「GraphRAG」です。
本記事では、GraphRAGについて、概要や仕組み、使い方についてご紹介します。
ぜひ、最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
GraphRAGの概要
「GraphRAG(Graph Retrieval-Augmented Generation)」は、情報検索とテキスト生成を統合した高度な手法であり、特にグラフ構造を活用して情報同士の関連性を強化する点が特徴です。
従来のRAGでは、ユーザーの質問に対して関連する文書を検索し、その内容を元にLLMが回答を生成します。
一方、「GraphRAG」では、ここにナレッジグラフ(知識グラフ)の情報を組み合わせます。
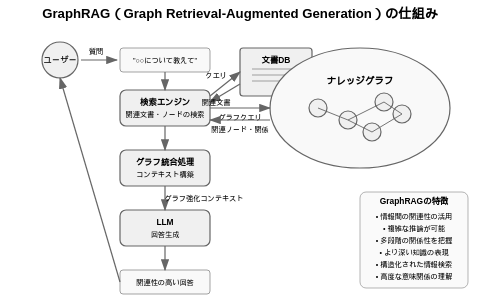
ナレッジグラフとは、データ間の関係性をノード(対象)とエッジ(関係)で表現した構造化データのことです。
「GraphRAG」はこのグラフから得られる関係情報を活用し、より高度な情報処理と精度の高い回答生成を目指すものとなっています。
そもそもRAGとは何か?
RAG(Retrieval-Augmented Generation)とは、生成AIモデルに検索機能を組み合わせた技術です。
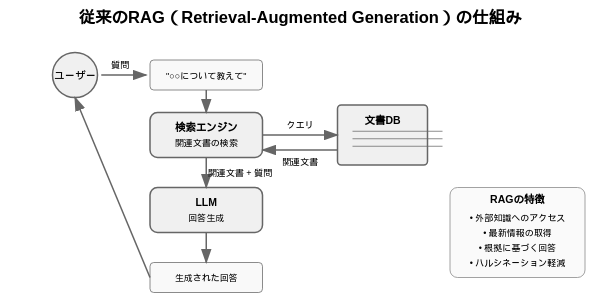
通常のLLMは訓練データ内の情報しか知らないため、新しい情報や特定ドメインの知識には答えられませんが、RAGではまずユーザーの質問に対して検索コンポーネントが動作し、事前に用意された大規模データベースやドキュメント集から関連情報を探し出します。
このデータベースには、Wikipedia記事や社内資料、論文データなど、回答に使えそうなテキストがインデックス化(ベクトル化など)されています。
詳しく知りたい方は以下の記事も参考にしてみてください。
GraphRAGとRAGの違い
GraphRAGと従来のRAGでは何が異なるのでしょうか?その大きな違いはデータ構造と検索アプローチにあります。
データ構造の違い
従来のRAGはテキストの集合(ドキュメント群)をそのまま保持し、ベクトルデータベースなどに登録して扱います。一方、GraphRAGでは文書から抽出したエンティティ(事物)同士の関係をグラフデータベースに格納します。
ノードとエッジで構成される知識グラフとしてデータを保持する点が大きな特徴です。
情報検索の違い
RAGでは、主にベクトル類似度に基づいて関連文書を検索しますが、GraphRAGではグラフクエリを用いてノード間のパスを辿るような検索が可能です。
つまり、単純な単語の類似だけでなく「Aという人物が所属する組織B」といった関係性に沿った情報探索ができます。これにより、従来見つけにくかった間接的な繋がりも検索で捉えられるようになります。
回答生成精度の違い
RAGの回答精度は、検索で拾われたテキストの質に大きく依存します。一方、GraphRAGではノード間のリンク構造やコミュニティ(後述)を考慮したうえでコンテキストを選択できるため、より網羅的で一貫性のある回答が期待できます。
特に、複数文書にまたがる質問や原因・結果の追跡など、関係性を辿る必要がある問いに対して強みを発揮します。
クエリの柔軟性
従来のRAGは、ユーザーからの質問を単なるキーワード列として扱いますが、GraphRAGでは構造化クエリも可能です。
たとえば、「X社とY社の資本関係は?」という問いに対し、グラフDB上で「資本関係」のエッジをたどるクエリを実行する、といった応答が可能です。これは、グラフデータだからこそできる柔軟性ともいえます。
以上の違いについてまとめると、GraphRAGは、「ベクトル検索中心のRAG」から「知識グラフ駆動のRAG」への進化版といえると思います。
データ同士のつながりを活用することで、より高度な検索と回答生成を実現しているのです。


GraphRAGの仕組み
GraphRAGの内部的な仕組みは、大きくインデックス作成とクエリ処理の2段階に分かれます。
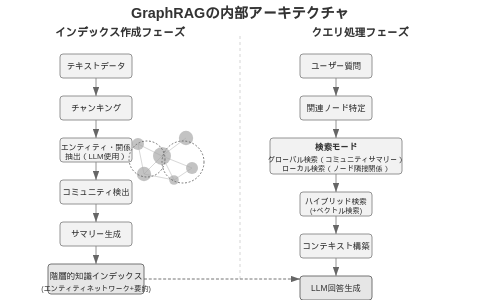
インデックス作成フェーズ
まず、入力となる大量のテキストデータを小さなチャンク単位に分割します。
各チャンクについて、LLMを用い、文中のエンティティやそれらの関係、重要な記述を抽出し、ノードとエッジからなる知識グラフを構築します。
さらにグラフ構造に対してコミュニティ検出を行い、互いに関連性の高いエンティティ群をグループ化します。
その上で、得られた各コミュニティごとに内容を要約したサマリー文を生成します。
以上のフローで、元の非構造テキストが「エンティティ同士のネットワーク+グループ要約」という階層的な知識インデックスに変換される仕組みになっています。
クエリ処理フェーズ
ユーザーから質問が来ると、まず、その質問内容に関連するグラフ上のノードやコミュニティを特定します。
GraphRAGには、質問に応じたいくつかの検索モードがあります。
例えば、データセット全体の傾向を問うような全体的な質問に対しては、コミュニティサマリーを活用した「グローバル検索」を行い、特定のエンティティに関する詳細な質問に対しては、そのノード周辺の隣接関係を辿る「ローカル検索」を行います。
加えて、必要に応じて従来型の全文検索やベクトル検索も組み合わせ、見落としのないようハイブリッドに関連コンテキストを取得します。
こうして集められたグラフ由来の関係情報・要約・テキスト片をすべてLLMのプロンプトに含めてやることで、モデルは質問の文脈や背後関係を踏まえた回答を生成できる仕組みになっています。
以上2つのフェーズについてまとめると、GraphRAGの仕組みの特徴は、「グラフで知識を構造化し、それをフル活用してLLMに賢く参照させる」ことにあります。
これにより、単に関連文章を寄せ集めるだけのRAGと比べ、情報同士の因果や全体像を把握したうえで回答を出すことが可能になっています。
GraphRAGができること
GraphRAGは、その特性から様々な分野・用途での活用が期待されています。
特に、データ同士の複雑な関係性を扱うタスクにおいて威力を発揮します。いくつか具体例を挙げてみましょう。
ソーシャルネットワーク分析
物間の関係性や影響力を分析する分野で、GraphRAGは、SNS上のユーザー同士のつながりを知識グラフとして統合し、誰がキーパーソンか、どのコミュニティが形成されているかといった洞察を得るのに役立ちます。
例えば、「AさんとBさんの共通の知人は?」といった質問に対し、GraphRAGならグラフ内の友人関係を辿って答えを導き出すことができます。
医療診断支援
ヘルスケア分野では、症状・疾患・治療法といった医療知識をグラフ化し、GraphRAGを用いて診断や治療の提案を行う研究が進んでいます。
ある症状から関連する疾患候補をリストアップし、それぞれに対する推奨治療を提示するといった用途です。
知識グラフを活用して医学知識を体系化することで、モデルが複雑な症例についても見落としなく推論できるようになります。
法律文書の分析
法律分野では、大量の判例や法令を扱うためにGraphRAGの活用が期待されています。
判例間の引用関係や法条の適用関係をグラフにまとめ、質問に関連する先例を自動で検索・提示するといったことが可能です。
例えば「○○に関する過去の判例は?」という問いに対し、GraphRAGは、知識グラフから関連判例をリトリーブし、要点をまとめて回答することができます。
人手では見逃しがちな関連判例もグラフ構造のおかげで網羅的に検索できる点が強みです。
科学研究データの解析
気候変動の要因分析や、生物学における遺伝子・タンパク質の相互作用ネットワーク解析など、多種多様な要素が絡み合うデータにもGraphRAGは有効です。
観測データをグラフでモデル化し、「要因Aが与える影響は?」などの質問に対して、関係パスをたどりながら回答を導き出します。
複雑な研究データから新たな発見を得る手法としても、GraphRAGは今後注目されるでしょう。
以上のように、GraphRAGは「つながり」が重視されるシーン全般で応用することができます。
また、レコメンデーションなど、他にも幅広いユースケースが考えられます。従来のRAGでは十分な性能が得られなかった領域でも、GraphRAGによって新たな価値を引き出せる可能性があります。


GraphRAGを活用するメリット
GraphRAGを導入することで、以下のようなメリットが期待できます。
関連性の高い情報をもれなく検索できる
グラフ構造を用いることで、データ間のつながりを考慮した検索が可能となり、単純なキーワード一致やベクトル類似では見つけづらかった情報も捉えられます。
結果として、ユーザーの質問に対してより関連性の高いコンテキストが集まり、回答の正確性が向上します。
「文章の文脈」という抽象的な繋がりもグラフなら構造化できるため、モデルが必要とするヒントを最大限提供できるようになります。
文脈を理解した回答生成ができる
検索フェーズで得られたグラフ構造をもとに、LLMがより文脈に沿った回答を生成できます。
例えば、ある人物に関する質問なら、その人物が属する組織や交友関係といった背景知識を踏まえた説明を返すことが可能です。
単なるテキスト生成モデルでは難しい、一貫性と意味の通った回答が期待できる点は大きなメリットです。
異種データを統合して活用できる
知識グラフは異なるタイプ・ソースのデータを1つの構造でリンクできます。
GraphRAGはこの特性を活かし、異なるデータソース(たとえばニュース記事と論文とSNS投稿など)をまとめて扱い、それらの関係性を踏まえて回答に反映できます。
従来は、データごとに別個に検索・処理していたものを、グラフで統合することで包括的な知見の抽出が可能になります。
高度な質問への回答精度向上
GraphRAGのアプローチによって、特に、複雑な推論を要する質問や包括的な要約質問に対する精度向上も期待できます。
たとえば、とある実験(※1)では、数百万トークン規模のデータセットに対する「データ全体の主要テーマは何か?」といった問いにおいて、GraphRAGが従来のRAGを上回る網羅性・多様性のある回答を生成できたとされています。
このように、GraphRAGはこれまで難しかった高度なQ&Aにも新たな解決策をもたらしています。
以上のように、GraphRAGを活用すれば、回答の網羅性・正確性・文脈適合性が総合的に向上し、生成AIのビジネス活用範囲を一段と広げることができるでしょう。
GraphRAGのデメリット
一方で、GraphRAGの導入には注意すべき点や課題も存在します。主なデメリットとしては次のようなものが挙げられます。
設計と実装が複雑
GraphRAGは、検索コンポーネントに高度なグラフ処理を含むため、システム全体の構築難易度が上がります。
もともとRAG自体、検索エンジンと生成モデルの2つを組み合わせるため開発・メンテナンスが難しい技術です。
GraphRAGでは、さらにグラフデータベースの設計・運用や知識グラフ抽出のチューニングが必要となり、高度な専門知識と労力を要します。
実際、MicrosoftのGraphRAGリポジトリでも「提供されるコードはデモ用途であり公式サポートではない」と明言されており、現状では自前で相応の開発を行う必要があるでしょう。
動作コストと性能面の負荷
大規模な知識グラフを構築・検索するには、計算資源や時間がかかります。
インデックス構築にはLLMによる大量のテキスト解析が必要であり、その分のAPI利用コストや計算時間が発生します。
検索時も、グラフクエリ・全文検索・ベクトル検索の3種類を組み合わせれば当然ながら処理は増えます。また、リアルタイム性が要求される場面では、これだけ多段の処理を行うGraphRAGは応答時間が長くなる可能性があります。
したがってシステム規模によっては性能チューニングやスケーリングが課題となるでしょう。
知識グラフ精度への依存
GraphRAGの回答品質は、下地となる知識グラフの正確さに大きく左右されます。
グラフ構築時にLLMが誤ったエンティティや関係を抽出してしまうと、間違った繋がりに基づく誤答が出るリスクがあります。
また、データ更新時には再インデックスが必要になるなど運用負荷も考慮すべきです。知識グラフ自体が万能ではなく、適切にメンテナンスされなければ却って誤情報を増幅させてしまう点には注意が必要です。
以上のように、GraphRAGは強力な手法である一方で、導入には技術的ハードルとコストが伴います。プロジェクトの目的やリソースに応じて、メリットとデメリットを天秤にかけた上で採用を判断することが重要です。
実際に動かしてみた所感
GraphRAGでは、ユーザからの質問に対し「検索 → 推論 → 応答」の流れで回答を導きます。具体的な手順は次のとおりです。
- 質問受付
ユーザーがチャットボットなどに自然言語で質問します(例:「現在未解決のチケットは何件ありますか?」など) - グラフ検索(情報取得)
システムは質問を解析し、ナレッジグラフに対する問い合わせに変換します。LangChainのGraphCypherQAChainの場合、まず、GPT-4モデルが質問内容に基づいて適切なCypherクエリを自動生成します。
例えば、「未解決のチケットは何件あるか?」という質問に対しては、
MATCH (t:Task {status: ‘open’}) RETURN COUNT(t)
上記のようなクエリが生成され、Neo4j上で実行されます。これにより、グラフから必要なデータ(この例ではステータスが“open”のタスクの件数)が取得されます。 - LLM推論(回答生成)
続いて取得したデータを元に、別のLLM(GPT-3.5やGPT-4)が回答を作成します。データベースから得た事実(例:「未解決タスクの件数=5件」)がモデルに渡され、「現在未解決のチケットは5件あります」という自然な文章で回答が生成されます。 - 応答
最終的にユーザーへ回答が返されます。ユーザーは複雑なクエリ言語を意識せず、質問に対する直接の答えを得ることができます。
以下の画像は、「未解決のチケットは何件あるか?」という質問に対し、GraphRAGが内部で生成したCypherクエリとその実行結果、および最終的な回答です。
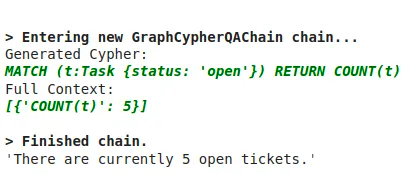
MATCH (t:Task {status: 'open'}) RETURN COUNT(t)というクエリが、自動生成・実行され、結果の件数「5」を受け取ってから、「There are currently 5 open tickets.(現在未解決のチケットは5件あります)」という回答が返されています。
このように検索と推論を組み合わせて処理するのが、GraphRAGの強みといえますね。
続いて、以下の画像は、「どのチームが最も多くの未完了タスクを抱えていますか?」と質問した場合の出力例で、生成されたCypherクエリが各チームの未解決タスクを数え上げ、TeamAが3件で最多であることがわかります。
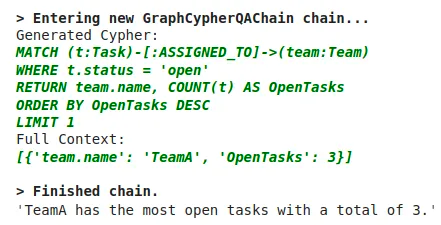
このように、グラフデータベース上で集計や関係探索を行い、その結果を自然な文章で返答してくれます。
これらの結果から、GraphRAGは「正確性」と「信頼性」の観点において、強みを持っていることがわかります。
- 正確性
- GraphRAGの回答はデータベースから取得した厳密な事実に基づくため、高い正確性があります。上記の例でも、グラフ上の「未解決タスク」が5件であれば回答も「5件」と正確に返されました。知識グラフ内の情報をそのまま利用するので、誤情報が混入しにくく、常に最新のデータに基づいた回答が期待できます。
- 信頼性
- 応答の信頼性は、主にクエリ生成の精度と基盤データの信頼性に依存します。上記の例でも、GPT-4を用いたことでクエリの誤りはなく、適切な結果が得られました。ただし、モデルが誤ったクエリを作るリスクはゼロではないため、必要に応じて出力を検証したり、システムメッセージでクエリ生成を誘導するなどの工夫が有用です。
よくある質問(FAQ)
GraphRAGについて、気になる点を3つFAQ形式でご紹介します。
以上、まとめると、GraphRAGは複雑な質問に強く、精度と透明性が高いが、高性能なLLMやグラフDBなど高度な導入要件が必要であることがお分かりいただけると思います。
まとめ
本記事では、GraphRAGの概要と技術的な仕組み、従来RAGとの違いなどについて解説しました。
GraphRAGは、ナレッジグラフを組み込むことで、生成AIの能力を拡張する最先端の技術です。
今後の展望として、GraphRAGのように構造化データとLLMを融合する手法はますます注目を集めるでしょう。
企業内のナレッジマネジメントや専門分野の大規模データ分析など、LLM単体では対応しきれない課題に対する有力なソリューションとなり得るからです。
その点、GraphRAGはまだ研究段階の色が濃いものの、オープンソースとして公開されたことでコミュニティ主導の改良も期待できます。
実務でGraphRAGを適用するにはまだまだ課題もありますが、データの関係性を活かすアプローチは今後のAI活用において欠かせないものになっていくでしょう。
ぜひこの機会に、GraphRAGのポイントを押さえ、次世代の高度なAIシステム構築に役立ててみてください。

最後に
いかがだったでしょうか?
GraphRAGのような高度な検索×生成手法が、すでに業務課題の解決手段として現実味を帯びてきています。RAGでは物足りない、ナレッジ活用を本気で考えたい——そんな企業の方にこそ、今こそ知っておいていただきたい内容です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

