
【kotaemon】洗練されたUIのオープンRAGシステム!論文PDFをアップロードして分かりやすく解説させてみた

\生成AIを活用して業務プロセスを自動化/
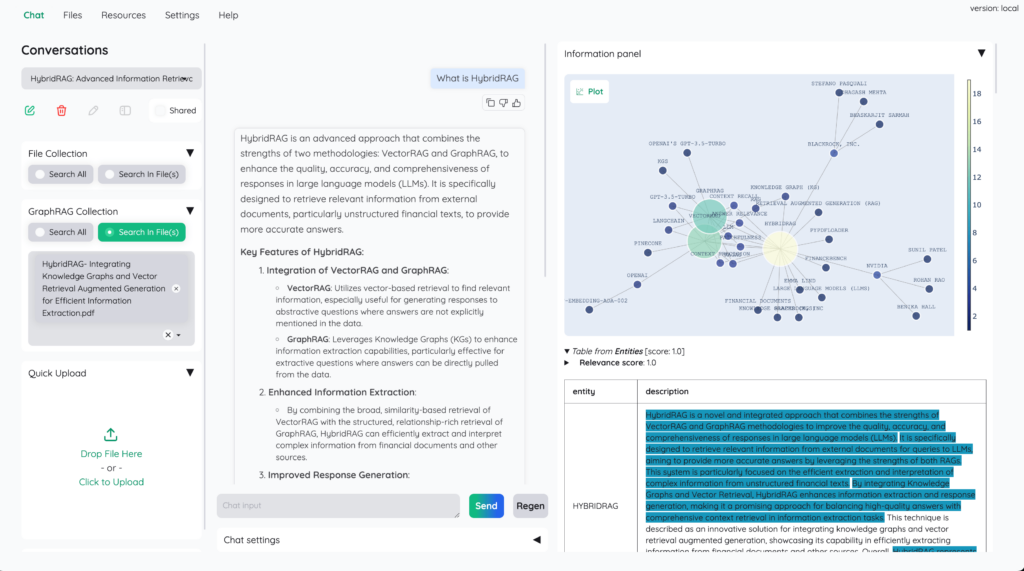
kotaemonの概要
Kotaemonaはドキュメントとチャットでやりとりができる、カスタマイズ可能なオープンソースのRAG UIです。開発者だけではなく、エンドユーザーについても念頭に置いて開発がされています。
開発したのは日本の会社のシナモンAIが開発しました。
RAGについて
生成AIの普及に伴い、大規模言語モデル(LLM)という言葉は馴染みになってきましたが、RAGという単語はまだ馴染みがない方も多いのではないでしょうか。
RAGはRetrieval-Augmented Generationの略で、自然言語処理で使われる技術の1種です。
RAGは特定の情報を提供するために、外部の情報源(例えばWebページやデータベース)から情報を検索して、それを使って答えを生成する手法。RAGは、質問応答システムや対話型AIなどで使用され、特に広範な知識を持つことが求められるタスクに効果的になります。
特に、RAGは最新の情報を検索して回答を生成するため、情報が古くなることを防ぎ、最新の情報を提供できます。また、モデル自体の知識に依存することがないため、必要な情報をリアルタイムで取り込むことができ、より幅広いトピックに対応できます。
kotaemonの主な機能
Kotaemonの主な機能はローカルLLMと一般的なAPIプロバイダーの両方をサポートするLLMおよび埋め込みモデルを整理します。これらの異なるLLMとAPIプロバイダーを1つの場所で管理および使用するための統合インターフェイスというものがkotaemonです。
Kotaemonではユーザーが使用するLLMやAPIを簡単に選択できるようになっており、ドロップダウンメニューから選択したり、設定ファイルで指定したりできます。
サポートしているAPIはOpenAIやAzureOpenAI、Cohereなどでollamaとllama-cpp-pythonを介したローカルLLMをサポート。これらのAPIプロバイダーに加えて、kotaemonはユーザーが独自のRAGパイプラインを構築するためのフレームワークを提供しています。
フレームワークを使用すると、開発者は他のAPIやローカルモデルを統合して、特定のニーズを満たすことができる可能性があります。
最高の検索品質を持つ
kotaemonはユーザーが任意のドキュメントをアップロードすることで、その内容に関する質疑応答をチャットで行うことができますが、それを実現するためには、ドキュメントの内容を間違えることなく検索できる必要があります。
デフォルトで、最高の検索品質を確保するために、フルテキスト検索とベクトル検索のハイブリッドリトリーバーと再ランキングを組み合わせたRAGパイプラインを備えています。
ハイブリッドリトリーバーは、フルテキスト検索とベクトル検索の両方のメリットを組み合わせたもので、フルテキスト検索では、ドキュメント内の単語やフレーズが検索クエリと完全に一致するかどうかを確認。
ベクトル検索では、ドキュメントと検索クエリが、意味を捉えるベクトル空間に埋め込まれます。これにより、kotaemonはクエリと完全に一致しない場合でも、クエリに関連するドキュメントを見つけることができます。
また、再ランキングは、リトリーバーによって返されたドキュメントのリストをさらに絞り込むプロセスです。再ランキングによって、別のモデルまたはアルゴリズムを使用して、各ドキュメントの関連性を評価し、最も関連性の高いドキュメントが最初に表示されるようにリストを並べ替えることが可能。
図表の質疑応答もサポート
kotaemonはテキストのみではなく、図や表を含む複数の内容に対しても質疑応答をサポートしています。図表の質疑応答により、ユーザーがテキストデータだけに限定されず、より複雑なドキュメントから情報を取得可能です。
さらに、kotaemonは複数のドキュメント解析方法をサポートしており、ユーザーはUI上で選択できます。この機能により、ユーザーはドキュメントのタイプや複雑さに最適な解析方法を選択し、より正確な回答を得ることができます。
これらの機能を組み合わせることで、kotaemonは図や表を含む多様なドキュメントから情報を抽出し、ユーザーの質問に包括的に答えることができます。ただし、どのように図や表を理解しているのかまでは明記されていません。
kotaemonのライセンス
kotaemonのライセンスはアパッチライセンス2.0です。そのため、基本的には商用利用や改変、私的使用などが可能なオープンソースライセンスになります。
使用条件としては、著作権表示とライセンスのコピーを維持すること、改変があればその通知を行う必要があります。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
なお、RAGについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

kotaemonの使い方
ここからは実際にkotaemonを使っていきます。
GitHubではDockerの使用が推奨されていますが、利用者が多いであろうgoogle colaboratoryで実装していきたいと思います。
kotaemonを動かすのに必要な動作環境
kotaemonを実行した時の環境は以下です。google colaboratoryで実装する場合にはランタイムをGPUに変更する必要があります。
kotaemonの実行ではそこまでGPUを使わないため、無料プランでも十分利用できます。
■Pythonのバージョン
Python 3.10以上
■使用ディスク量
34.2GB
■システムRAMの使用量
2.8GB
ngrokのtoken取得
kotaemonをgoogle colaboratoryで実行するためには、ngrokのtokenが必要になるので、実装する前にngrokのtokenを取得しておきます。
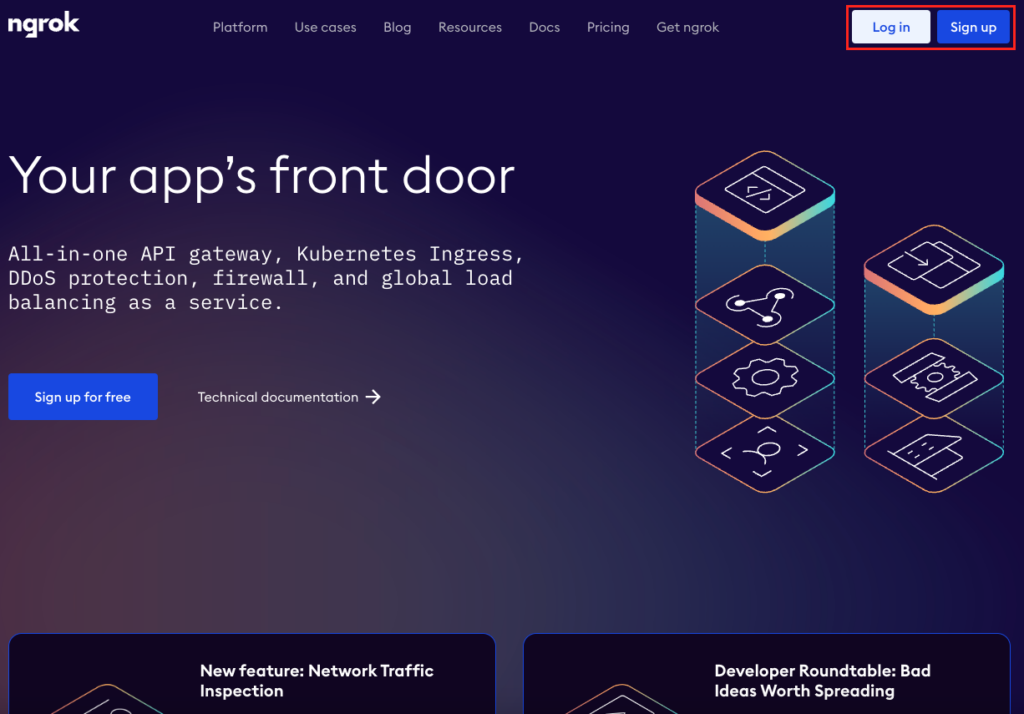
まだ登録していない方はsign upを、登録済みの方はログインをしましょう
初めての方でもGoogleアカウントさえあればGoogleアカウントでサインアップできるので、簡単に登録できます。
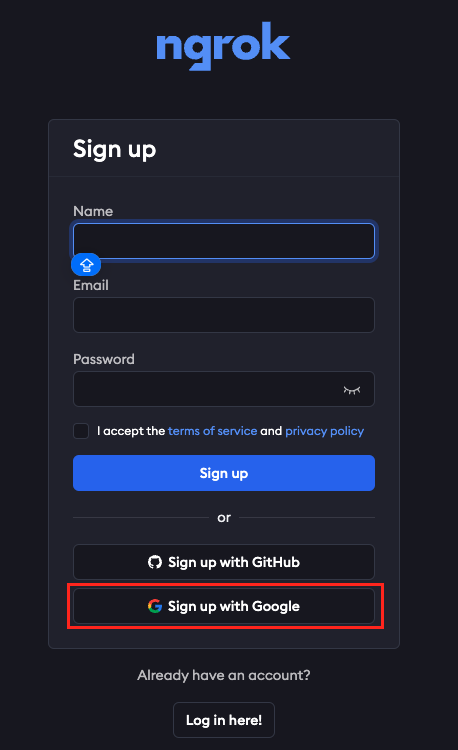
チェックボックスにチェックを入れたらacceptをクリックして、ユーザー登録を進めていきましょう。
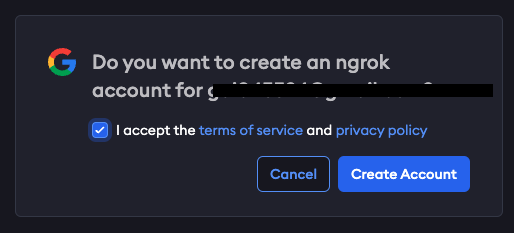
トップページに遷移したら「Authtokens」をクリック
Add Tunnel Authtokenをクリックして、tokenを作成します
DescriptionやOwnerはそのままでOKです
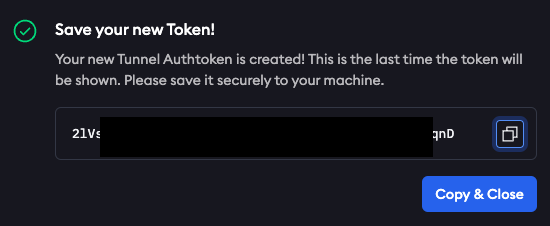
Saveを押すとtokenが現れるので、コピペしておきます。この一回しかコピペすることができないので、必ずコピペしておきましょう
あとは今回発行したtokenをgoogle colaboratoryのコードに入力すればOKです
kotaemonをgoogle colaboratoryで実装する
kotaemonを使うにはPython3.10以上の必要があるので、まずはPythonのバージョンを確認しておきましょう。
Pythonのバージョン確認と必要ライブラリのインストールはこちら
!python --version
# リポジトリのクローン
!git clone https://github.com/Cinnamon/kotaemon.git
%cd kotaemon
!pip install -e "libs/kotaemon[all]"
!pip install -e "libs/ktem"続いてOpenAIのAPIを設定します。
OpenAIのAPIの設定はこちら
import os
# OpenAI APIキーの設定例
os.environ['OPENAI_API_KEY'] = 'your_API_key'そして取得したngrokのtokenを設定します。
ngrokのインストールとtoken設定はこちら
!pip install pyngrok
!ngrok authtoken <your_ngrok_token>実際にngrokのtokenを入力する際には<>は削除してください。
これで準備はできたので、実際に実行しましょう。
kotaemonの実行はこちら
# Google Colabではセルを1つにまとめて実行します
import threading
import time
from pyngrok import ngrok
# 1. 別スレッドでアプリケーションを実行
def run_app():
get_ipython().system('python app.py')
thread = threading.Thread(target=run_app)
thread.start()
# 2. 少し待ってからngrokを起動してトンネルを開く
time.sleep(5) # サーバーが起動するまでの待機時間を調整
public_url = ngrok.connect(7860)
print(public_url)kotaemonの実行結果はこちら
[nltk_data] Downloading package punkt_tab to
[nltk_data] /usr/local/lib/python3.10/dist-
[nltk_data] packages/llama_index/core/_static/nltk_cache...
[nltk_data] Package punkt_tab is already up-to-date!
NgrokTunnel: "https://e05a-35-197-153-228.ngrok-free.app" -> "http://localhost:7860"URLが2つ出てきますが、最初の.ngrok-free.appにアクセスをします。
アクセスするとngrokの警告Webページが表示されますが、そのままVisit Siteをクリックすればkotaemonのログインページに移ります。
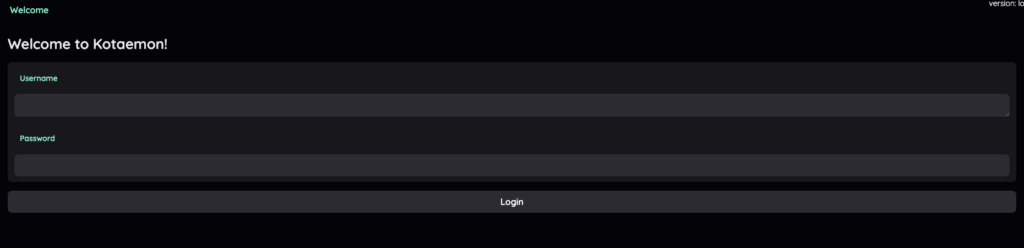
ユーザー名とパスワード名はどちらもadminです。入力した後、kotaemonにログインすることができます。
これでkotaemonを起動することができたので、実際に使ってみましょう。
kotaemonにLLMの論文を読み込ませてブログ記事を書けるか検証してみた
kotaemonはドキュメントに基づくQAを行うシステムですが、LLMを使ってドキュメントから文章を生成することも可能です。
そのため、ユーザーが任意のドキュメントをアップロードして、指示を与えれば正確なブログ記事を書くことができるのではないでしょうか?
ということで、実際に論文を読み込ませて実装していきます。
読み込ませる論文はこちらです
コードは上記で実装したものと一緒です。ただ、日本語で回答してもらう必要があるので、kotaemonの設定で日本語にしておきましょう。
まずはSettingsのタブを選択
次にReasoning Settingをクリック
languageでJapaneseを選択
そのまま少し下に下がってSave changesをクリックで日本語での回答になります。
与えた指示はこちら
Attention Is All You Needを参考に3000文字程度で起承転結をつけてブログ記事を書いてください。また、論文内で引用されている先行研究についても言及した記事にしてください。
実際に出力してくれたのがこちらです。
kotaemonに書いてもらった記事はこちら
# Attention Is All You Need: トランスフォーマーの革新とその影響
## 序章
近年、自然言語処理(NLP)の分野では、機械翻訳や言語モデリングなどのシーケンス変換タスクにおいて、リカレントニューラルネットワーク(RNN)やその派生モデルである長短期記憶(LSTM)やゲート付きリカレントユニット(GRU)が主流となっていました。しかし、これらのモデルはシーケンスの長さに依存した計算を行うため、並列化が難しく、特に長いシーケンスに対しては計算効率が低下するという課題がありました。
このような背景の中で、2017年に発表された「Attention Is All You Need」という論文は、NLPの世界に大きな変革をもたらしました。この論文では、トランスフォーマーと呼ばれる新しいモデルアーキテクチャが提案され、従来のリカレント構造を完全に排除し、注意機構(アテンションメカニズム)のみを用いることで、シーケンス変換タスクにおいて高い性能を発揮することが示されました。
## 起:トランスフォーマーの登場
トランスフォーマーは、エンコーダとデコーダのスタックから構成されるシンプルなアーキテクチャです。エンコーダは6つの同一の層から成り、それぞれの層はマルチヘッド自己注意機構と位置ごとの全結合フィードフォワードネットワークの2つのサブレイヤーで構成されています。デコーダも同様に6つの層から成り、エンコーダの出力に対するマルチヘッド注意機構を追加で持つ点が異なります。
トランスフォーマーの最大の特徴は、自己注意機構を用いることで、シーケンス内の異なる位置間の依存関係を効率的にモデル化できる点です。これにより、従来のリカレントモデルに比べて並列化が容易になり、計算効率が大幅に向上しました。
## 承:トランスフォーマーの性能
トランスフォーマーは、WMT 2014の英語からドイツ語への翻訳タスクで28.4 BLEUスコアを達成し、従来の最良モデルを2 BLEU以上上回る結果を示しました。また、英語からフランス語への翻訳タスクでは、8つのGPUを用いて3.5日間の訓練で41.8のBLEUスコアを達成し、従来の最良モデルを大幅に上回る結果を示しました。
さらに、トランスフォーマーは他のタスクにも適用可能であることが示されました。例えば、英語の構成解析タスクにおいても高い性能を発揮し、特に小規模なデータセットでの訓練においても優れた結果を示しました。
## 転:先行研究との比較
トランスフォーマーの登場以前には、リカレントニューラルネットワーク(RNN)やその派生モデルが主流でした。例えば、Bahdanauら(2014)は、ニューラル機械翻訳においてアテンション機構を導入し、翻訳品質を大幅に向上させました。また、Luongら(2015)は、マルチタスク学習を用いて翻訳性能をさらに向上させました。
一方で、トランスフォーマーはこれらのリカレント構造を完全に排除し、自己注意機構のみを用いることで、計算効率と性能の両方を大幅に向上させました。特に、従来のリカレントモデルが持つシーケンスの長さに依存した計算の制約を克服し、並列化を実現した点が大きな革新と言えます。
## 結:トランスフォーマーの未来
トランスフォーマーの登場により、NLPの分野は大きな進化を遂げました。現在では、トランスフォーマーを基盤としたモデルが多くのタスクで使用されており、その応用範囲はテキストの翻訳や生成にとどまらず、画像や音声、動画などの他のモダリティにも広がっています。
今後の研究では、トランスフォーマーをさらに改良し、大規模な入力や出力を効率的に処理するためのローカルな注意機構の導入や、生成プロセスの非シーケンシャル化などが期待されています。また、トランスフォーマーを用いた新しいアプリケーションの開発も進んでおり、その可能性は無限大です。
トランスフォーマーの登場は、NLPの世界に新たな可能性をもたらし、今後の研究と応用の方向性を大きく変えることでしょう。私たちは、この革新的なモデルの未来に大いに期待しています。今回は論文を1本しか読み込ませていませんが、複数の論文を読み込ませて、必要に応じてそれぞれの論文内容を参照するように指示を与えれば、複数の論文から1本のブログ記事を書いてくれるようになるかもしれません。
また、社内ドキュメントや過去の日報などを読み込ませて、社内日報を毎日書かせることも可能になるかもしれませんね。RAGの拡張性は計り知れないので、ぜひ色々試してみてください。
なお、GPT-4o超えの日本語レベルを持つ1000億パラメータLLMについて詳しく知りたい方は、下記の記事を合わせてご確認ください。



